{
网络层服务
数据报网络虚电路网络
网络互连与网络互连设备
网络层拥塞控制
internet网络层
路由算法与路由协议
}
网络层服务
网络层的核心任务: 将数据从源主机送达到目的主机。
网络层的主要功能:路由选择, 转发, 建立连接。
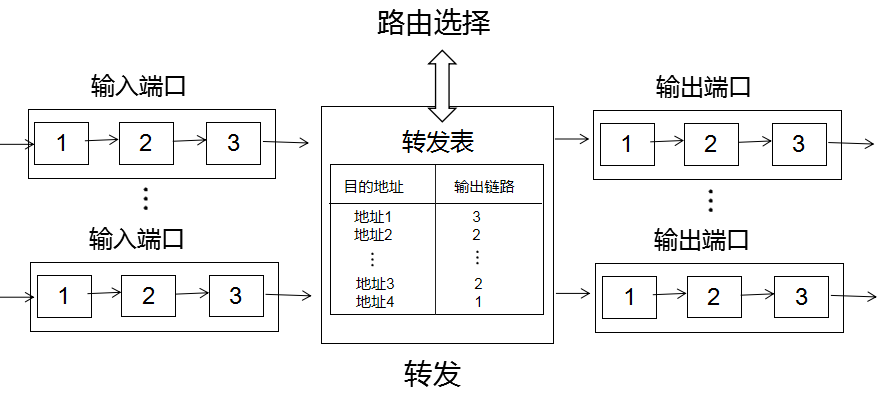
- 路由选择: 当分组从源主机流向目的主机时,必须通过某种方式决定分组经过的路由或路径, 计算分组所经过的路径的算法被称为路由选择算法, 或称路由算法。
- 转发: 当通过一条输入链路接收到一个分组后, 路由器需要决策通过那条输出链路将分组发送出去, 并将接口从输入接口转移到输出接口。
- 建立连接:网络层连接是从源主机到目的主机经过的一条路径,这条路径所经过的每个路由器等网络设备都要参与网络层连接的建立。
根据是否在网络层提供连接服务, 分组交换网络可以分为:
在网络层提供连接服务的虚电路(Virtual-Circuit, VC)网络;
在网络层提供无连接服务的数据报网络(datagram network);
数据报网络与虚电路网络;
数据报网络:按照目的主机地址进行路由选择的网络称为数据报网络。
源主机每要发送一个分组, 就为该分组加上目的主机地址,然后将该分组推进网络。
数据报网络中不维护连接状态信息, 但有转发状态信息。 每个路由器使用分组的目的主机地址来转发该分组。
虚电路网络:虚电路(virtual circuit,VC)是在源主机到目的主机的一条路径上建立的一条网络层逻辑连接,为区别于电路交换中的电路,称之为虚电路。
一条虚电路由3个要素构成:
- 从源主机到目的主机之间的一条路径(即一系列的链路和分组交换机)
- 该路径上的每条链路各有一个虚电路表识(VCID)
- 该路径上每台分组交换机的转发表中的记录虚电路表示的连续关系
| 项目 | 虚电路交换 | 数据报交换 |
|---|---|---|
| 是否建立连接 | 需要先建立连接 | 不需要建立连接 |
| 地址 | 每个分组含有一个段的虚电路号 | 每个分组包含源和目的分组的端地址 |
| 分组顺序 | 按序发送, 按需接收 | 按序发送, 不按需接收 |
| 路由选择 | 建立VC时需要路由连接,之后所有分组都沿此路由转发 | 对每个分组独立连接 |
| 典型网络 | X25,帧中继,ATM | 因特网 |
异构网络互连的基本策略:协议转换和构建虚拟互联网络。
协议转换:采用一类支持异构网络之间协议转换的网络中间设备,来实现异构网络之间数据分组的转换与转发。 例如:支持协议转换的网桥,交换机或者是多协议路由器和应用网关等。
构建虚拟互联网络:在异构网络基础上构建一个同构的虚拟互联网络。 例如:IP网络。Internet采用同构的网络层协议IP与网络寻址。
路由器:具有多个输入端口和多个输出端口的专用计算机,主要任务就是获取与维护路由信息以及转发分组。最典型的网络层设备。
路由器从功能体系结构角度:输入端口、交换结构、输出端口、路由处理器。
输入端口:查找,转发,到达分组 缓存排队功能。
交换结构:完成具体的转发工作,将输入端口的IP数据报交换到指定的输出端口。
主要包括:基于内存交换 基于总线交换 基于网络交换
基于内存交换:输入端口——内存、路由处理器——输出端口
基于总线交换:输入端口和输出端口连接在一条数据总线上。
无须路由处理器介入即可实现交换功能。 总线是独占式。
基于网络交换: 使用一个复杂的互联网络来实现交换结构。 克服单一、独占所带来的限制。 并行交换传输。
基于内存交换:性能最低,路由器价格最便宜
基于网络交换:性能最高,路由器价格昂贵
输出端口:缓存排队,从队列中取出分组进行数据链路层数据帧的封装,发送。
特点: 1、先到先服务(FCFS)调度策略; 2、按优先级调度、按IP数据报的服务类型(Tos)调度。
路由处理器: 1、执行命令 2、路由协议运行 3、路由计算以及路由表的更新和维护。
网络层拥塞控制
{
网络拥塞
流量感知路由
准入控制
流量调节
负载脱落
}
网络层拥塞:一种持续过载的网络状态。用户对网络资源(包括链路带宽、存储空间和处理器处理能力等)的总需求超过了网络固有的容量。
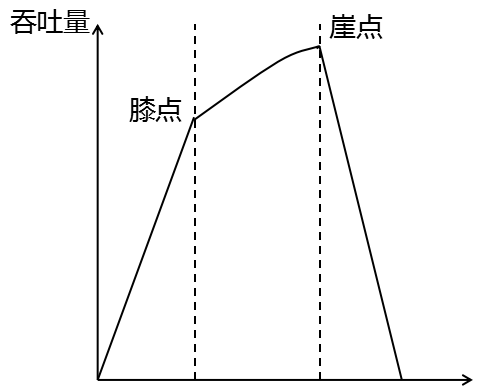
网络负载在膝点附近时,吞吐量和分组平均延迟达到理想的平衡,网络的使用效率最高。
发生拥塞的原因:
- 缓冲区容量有限
- 传输线路的带宽有限
- 网络结点的处理能力有限
- 网络中某些部分发生了故障
网络层常用的拥塞控制措施:
流量感知路由
准入控制
流量调节
负载脱落
流量感知路由: 网络经常被抽象为一张带权无向图,权值能够根据网络负载动态调整,则可以将网络流量引导到不同的链路上,均衡网络负载,从而延缓或避免拥塞的发生。
准入控制: 是对新建虚电路审核,如果新建立的虚电路会导致网络变得拥塞,那么网络拒绝建立该新虚电路。
流量调节:在网络拥塞时,可以通过调整发送方发送数据的速率来消除拥塞。
抑制分组:感知到拥塞的路由器选择一个被拥塞的数据报,给该数据报的源主机返回一个抑制分组。
背压:抑制分组在从拥塞结点到源结点的路径上的每一跳,都发挥抑制作用。
负载脱落:通过有选择地主动丢弃一些数据报,来减轻网络负载,从而缓解或消除拥塞。
Internet网络层
{
ipv4协议
动态主机配置协议
网络地址转换
ICMP
ipv6协议
}
Internet网络层主要协议:
1.网际协议(Internet protocol, IP);
2.路由协议
3.互联网控制路由协议(Internet control message protocol, ICMP)
IPv4协议
IP目前两个版本:IPv4和IPv6 IPv4协议:
Internet网络层最核心的协议。
定义了如何封装上层协议(如UDP、TCP等)的报文段;
定义了Internet网络层寻址(IP地址)以及如何转发IP数据报等内容;
IP数据报格式
| 版本4 | 首部长度4 | 区分服务8 | 数据报长度16 | |
|---|---|---|---|---|
| 标识16 | 标志3 | 片偏移量13 | ||
| 生存时间8 | 上层协议8 | 首部校验和16 | ||
| 源IP地址32 | ||||
| 目的IP地址32 | ||||
| 选项(可选,长度可变) | ||||
| 数据 |
1、版本号:4位,IPv4、IPv6。
2、首部长度:4位。20B
3、区分服务:在旧标准种称为服务类型(Type Of Service,TOS)字段 用来指示期望获得哪种类型的服务。
4、数据长度:16位,指出IP数据报的总字节数。
5、生存时间:8位, 表示IP数据报 在网络中可以通过的路由器数(或跳步数)。
6、上层协议:8位,指示该IP数据报封装的是哪个上层协议。 TCP:6 UDP:17
7、首部校验和:占16位,利用校验和实现对IP数据报首部的差错检测
8、源IP地址字段占32位,发出IP数据报的源主机的IP地址。
9、目的IP地址字段占32位,IP数据报的需要送达的主机的IP地址。
13、选项:长度可变。
14、数据字段,数据字段存放IP数据报所封装的传输层报文段。
15、标识:字段占16位,标识一个IP数据报
16、标志:标志位字段占3位,其结构如下:
DF禁止分片标志
DF=0,允许分片;
DF=1,禁止分片;
MF更多分片标志
MF=0,未被分片或分片的最后一片。
MF=1,一定是分片,且不是最后一个。
17、片偏移量: 以8B为单位。 表示一个IP数据报分片与原IP数据报数据的相对偏移量。
当该字段值为0时,且MF=1, 则表示这是一个IP分片,且是第一个分片
二、IP数据报分片
最大传输单元(Maximum Transmission Unit,MTU)
通过PingPlotter工具发送一个总长度为3400字节的IP数据报,通过MTU=1500字节的链路转发
| 片 | 总长度/字节 | 片偏移 | 标志 | 封装原IP数据报中的字节数 |
|---|---|---|---|---|
| 第1片 | 1500 | 0 | 1 | 0-1479(共1480字节) |
| 第2片 | 1500 | 185 | 1 | 1480-2959(共1480字节) |
| 第3片 | 440 | 370 | 0 | 2960-3379(共420字节) |
IPv4编址
IPv4地址的长度为32位,共有2^32个不同的IP地址,约为43亿个 .
IPv4地址的三种标记方式: 二进制标记法、点分十进制标记法 、十六进制标记法
IP地址分配
- 为每一个IP子网分配一个子网地址。
IP子网地址为: 203.1.1.0/24
/24: 24位前缀
IP子网的概念,将主机IP地址划分为两个部分:
1、前缀(Prefix),即网络部分(NetID)用于描述主机所归属的网络
2、后缀(Postfix),即主机部分(HostID)用于表示主机在网络中的唯一地址
分类地址划分:
| 类 | 前缀长度 | 前缀 | 首字节 |
|---|---|---|---|
| A | 8位 | 0xxxxxxx | 0-127 |
| B | 16位 | 10xxxxxx xxxxxxxxx | 128-191 |
| C | 24位 | 110xxxxx xxxxxxxxx xxxxxxxxx | 192-223 |
| D | 不可用 | 1110xxxx xxxxxxxxx xxxxxxxxx xxxxxxxxx | 224-239 |
| E | 不可用 | 1111xxxx xxxxxxxxx xxxxxxxxx xxxxxxxxx xxxxxxxxx | 240-255 |
分类寻址:
A、B、C类地址可以用于标识网络中的主机或路由器
D类地址作为组广播地址
E类是地址保留。
IP地址中用前缀中的后几位来表示网络地址个数,除去前缀外的位数是这类网络中的IP地址总数。
| 类 | 前缀中后 | 网路地址 | 每个类网**IP**地址总数 |
|---|---|---|---|
| A | 7位 | 个 | 个 |
| B | 14位 | 个 | 个 |
| C | 21位 | 个 | 个 |

特殊地址 :
| NetID | HostID | 作为IP数据报源地址 | 作为IP数据报目的地址 | 用途 |
|---|---|---|---|---|
| 全0 | 全0 | 可以 | 不可以 | 在本网范围内表示本机; 在路由表中用于表示默认路由 |
| 全0 | 特定值 | 可以 | 不可以 | 表示本网内某个特定主机 |
| 全1 | 全1 | 不可以 | 可以 | 本网广播地址 |
| 特定值 | 全0 | 不可以 | 不可以 | 网络地址,表示一个网络 |
| 特定值 | 全1 | 不可以 | 可以 | 直接广播地址,对特定网络上的所有主机进行广播 |
| 127 | 非全0或非全1的任何数 | 可以 | 可以 | 用于本地软件环回测试,称为环回地址 |
除去特殊IP地址外,还有一部分地址保留用于内部网络,称为私有地址。这部分地址可以在内网使用,但不能在公共互联网上使用。
| 私有地址类别 | 范围 |
|---|---|
| A类 | 10.0.0.0——10.255.255.255(或10.0.0.0/8) |
| B类 | 172.16.0.0——172.31.255.255(或172.16.0.0/12) |
| C类 | 192.168.0.0——192.168.255.255(或192.168.0.0/16) |
无类地址
在无类寻址方案中,不存在诸如分类寻址中的网络类别,网络前缀不再被设计为定长的8位、16位、24位,而变成可以是0-32位的任意值。 网络地址形式为a.b.c.d/x。这种地址形式称为无类域间路由(CIDR)。
子网划分
子网化就是指将一个较大的子网划分为多个较小子网的过程。
超网化是指将具有较长前缀的相对较小的子网合并为一个具有稍短前缀的相对较大的子网。超网化是子网化的逆过程。
子网掩码
子网掩码:32位。
对应网络前缀,全部为1;
其余位(主机部分),全部为0;
例如:子网213.111.0.0/24的子网掩码是: 255.255.255.0;
已知子网中某IP地址和子网掩码,就可以计算出一个子网的网络地址、广 播地址、IP地址总数和可分配的IP地址数量等。
1、子网掩码和主机地址按位与运算可以得出网络地址。
与运算:0&0=0; 0&1=0; 1&0=0; 1&1=1;
2、子网掩码的反码与主机地址按位或运算可得出直接广播地址。
反码:1——0;0——1;
或运算:0 || 0 = 0; 1 || 0 = 1; 0 || 1 = 1; 1 || 1 = 1;
练习题 假设某子网中的一个主机的IP地址是203.123.1.135,子网掩码是 255.255.255.192。
1. 那么该子网的子网地址是什么?
2. 直接广播地址是什么?
3. 该子网IP地址总数是多少?
4. 该子网的可分配IP地址数是多少?
:::success
求子网地址```bash
分步骤计算
1) 将IP地址和子网掩码换算为二进制,子网掩码连续全1的是网络地址,后面的是主机地址。
203.123.1.135 11001011.01110001.00000001.10000111 255.255.255.192 11111111.11111111.11111111.11000000 由子网掩码前26位为1,可知26位主机地址
2)IP地址和子网掩码进行与运算,结果是网络地址
203.123.1.135 11001011.01110001.00000001.10000111255.255.255.192 11111111.11111111.11111111.11000000
与运算:
11001011.01110001.00000001.10000000
结果为:203.123.1.128/26
求广播地址```bash将上面的网络地址中的网络地址部分不变,主机地址变为全1,结果就是广播地址。由子网掩码可知后,前24位作为网络地址,后8位作为主机地址子网掩码:255.255.255.192 11111111.11111111.11111111.11000000子网掩码反码: 00000000.00000000.00000000.00111111IP地址: 11001011.01110001.00000001.10000111与后8位进行或运算 10111111------------------------------------------------------------------------------------广播地址为: 203.123.1.191 11001011.01110001.00000001.10111111
求该子网IP地址总数``` 网络前缀有26位,故主机位有32-26=6位,即有2^6=64个IP地址总数
该子网的可分配IP地址总数```bash子网IP地址总数-子网地址-广播地址 = 64-2 = 62# 减去全1和全0
地址范围bash
该子网为203.123.1.128/26,其转化为二进制的后8位的
取值范围是 10000000 ~ 10111111
转化为十进制 128 ~ 191
去掉首尾两个不可用 129 ~ 190
故范围为: 203.123.1.129 ~ 203.123.1.190
:::
路由聚合:提高路由效率,减少路由表项数,将可以聚合在一起的子网聚合成一个大的子网。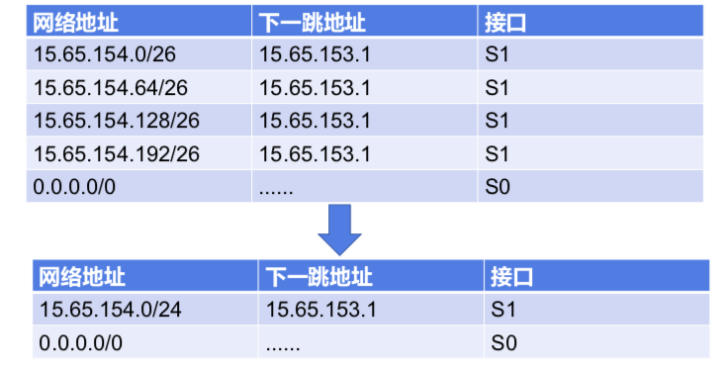
动态主机配置协议
Dynamic Host Configuration Protocol
当组织分配到一个网络地址块后,就可以为该组织内的主机和路由器接口分配IP地址。
静态分配:手动配置;
动态分配:动态主机配置协议(DHCP)来分配。
DHCP服务器端口号67
DHCP客户端口号68
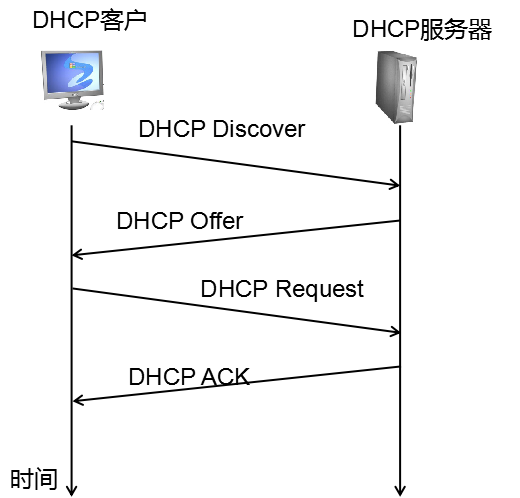
1、DHCP服务器发现:广播方式
2、DHCP服务器提供:广播方式
3、DHCP请求:广播方式
4、DHCP确认
网络地址转换
网络地址转换(NAT:Network address translation)
对于从内网出去,进入公共互联网的IP数据报,将其IP地址替换为NAT服务器拥有的合法的公共IP地址,同时替换源端口号,并将替换关系记录到NAT转换表中;
对于从公共互联网返回的IP数据报,依据其目的IP地址与目的端口号检索NAT转换表,并利用检索到的内部私有IP地址与对应的端口号替换目的IP地址和目的端口号,然后将IP数据报转发到内部网络。
ICMP
互联网控制报文协议(ICMP:Internet Control Messages Protocol):在主机或路由器间实现差错信息报告、信息探测。
ICMP报文:差错报告报文和询问报文
ICMP 报文格式:
| 类型8 | 代码8 | 校验和16 |
|---|---|---|
| 由ICMP报文的类型决定32 | ||
| ICMP的数据部分 |
ICMP差错报告报文有5种:终点不可达、源点抑制、时间超时、参数问题、路由重定向
ICMP询问报文:回声(echo)请求/应答、时间戳请求/应答
IPv6
IPv6数据报格式(基本首部)
| 版本4 | 流量类型8 | 流量标签20 |
|---|---|---|
| 有效载荷长度16 | 下个首部8 | 跳数限制8 |
| 源IP地址128 | ||
| 目的IP地址128 | ||
| 数据 |
IPv6地址:单播地址、组播地址、任播地址三类。
IPv6地址长度为128位,通常采用8组冒号分隔的十六进制数地址形式表示,例如: 5000:0000:00A1:0128:4500:0000:89CE:ABCD
IPV4到IPV6的迁移
(1)双协议栈,即支持IPV6的网络结点同时也支持IPv4,同时具备发送IPV4与IPV6数据报的能力。为了实现IPv4与IPv6共存采用双协议栈,其中通过DNS可以解决一个结点感知通信另一结点提供什么版本的网络层服务。
(2)隧道,可以很好地解决IPv6通信中经过IPv4路由器的问题,同时也不会出现信息丢失的问题
路由算法与路由协议
{
路由算法分类
链路路由选择算法
距离向量路由选择算法
层次化路由选择算法
Internet 路由选择协议
}
路由算法分类
将网络抽象为一张带权无向图G(N,E) N表示点的集合, E表示边的集合。
网络中的路由器抽象为图G的结点,连接两个路由器的网络链路抽象为G的边
网络链路的费用(比如带宽、时延等)抽象为G中的权值 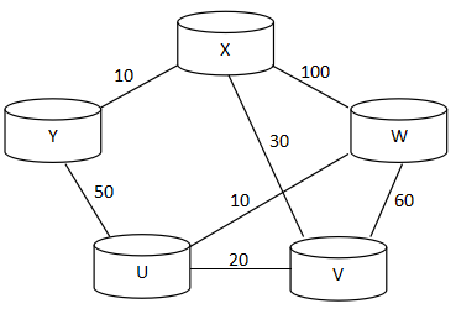
X , Y ,U, V, W 为路由器
连接的直线 为网络链路抽象为G的边
10,100,60 …..为G的权值
例:
网络链路的费用(比如带宽、时延等)抽象为G中的权值。 两个结点x和y之间边的权值(即直接链路费用),用c(x,y)来表示。 如果x,y之间存在边,c(x,y)=10 如果不存在边,c(x,u)=∞ 路径{x,y,u,v}的费用是: 80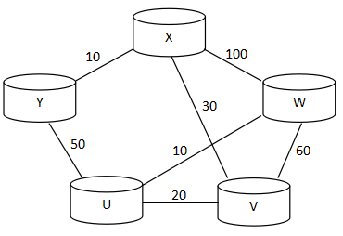
第一种分类:
全局式路由选择算法 需要根据网络的完整信息来计算最短路径 链路状态路由选择算法(LS算法)
分布式路由选择算法 结点不会(也不需要)尝试获取整个网络拓扑信息, 距离向量路由选择算(DV算法)
结点只需获知与其相连的链路的“费用”信息,
以及邻居结点通告的到达其他结点的最短距离(估计)信息,
经过不断的迭代计算,
最终获知经由哪个邻居可以具有到达目的结点的最短距离。
第二种分类:
静态 人工配置,网络变化时,不进行人工干预,就无法匹配。
动态 网络发生变化,自动计算最佳路由 (LS算法、DV算法)
第三种分类:
负载敏感的路由选择算法;负载迟钝的路由选择算法。
链路状态路由选择算法:
链路状态路由选择算法是利用Dijkstra算法求最短路径的;
| D(v) | 到本次迭代为止,源结点(计算结点)到目的结点v的当前路径距离 |
|---|---|
| P(v) | 到本次迭代为止,在源结点到目的结点v的当前路径上,结点v的前序结点 |
| c(x,y) | 结点x与结点y之间直接链路的费用,如果x和y之间没有之间链路相连,则(x,y)=∞ |
| S | 结点的集合,用于存储从源结点到该结点的最短路径已求出的结点集合,初始值只有源结点本身 |
P(v):到本次迭代为止,在源结点到目的结点v的当前路径上,结点v的前序结点。 如果路径上只有两个结点,则该值就是最后一个结点。
| 循环 | S | 每轮选择的结点 | D[y],P[y] | D[u],P[u] | D[v],P[v] | D[w],P[w] |
|---|---|---|---|---|---|---|
| 初始化 | x | - | 10,x | ∞ | 30,x | 100,x |
| 1 | xy | y | 60, y | 30,x | 100,x | |
| 2 | xyv | v | 50, v | 90, v | ||
| 3 | xyvu | u | 60,u | |||
| 4 | xyvuw | w |
路由器x上的转发表
| 目的 | 链路 |
|---|---|
| y | (x,y) |
| u | (u,v) |
| v | (x,v) |
| w | (w,u) |
(路由器x上的转发表只存放下一跳路由器,而不是最终路由器。)
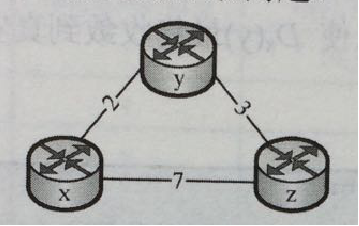
真题演练 设网络拓扑如图所示。请利用Dijkstra最短路径算法计算结点x到网络中所有结点的最短路径,填写题表中序号处的内容。 注:如果某个结点在选择下一跳结点时,有多个结点的最短路径相同,则选择结点编号小的结点作为下一跳结点。例如,如果结点x到结点y和结点z的路径代价相同,而且都是x到所有下一跳结点中的最短路径,则选择x为y的下一跳结点。
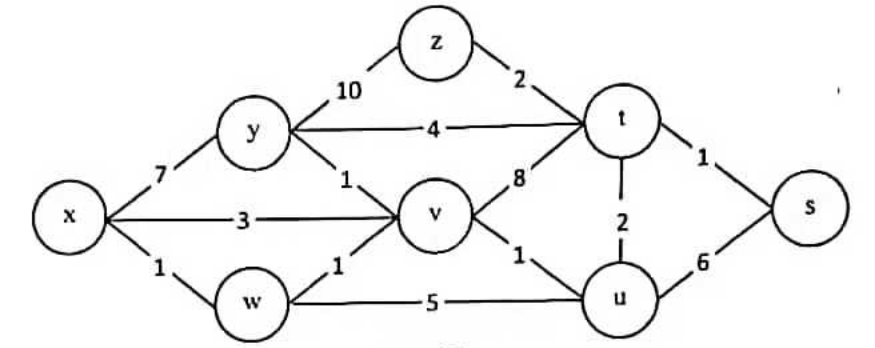
| 目的 | 下一跳 | 代价 |
|---|---|---|
| s | (1) | (2) |
| t | (3) | (4) |
| u | (5) | (6) |
| v | (7) | (8) |
| w | w | 1 |
| y | (9) | (10) |
| z | (11) | (12) |
| 循环 | S | 每轮选择的结点 | D[y]P[y] | D[z]P[z] | D[w]P[w] | D[v]P[v] |
D[t]P[t] |
D[u]P[u] |
D[s]P[s] |
|---|---|---|---|---|---|---|---|---|---|
| 初 | {x} | - | 7,y | ∞ | 1,w | 3,v | ∞ | ∞ | ∞ |
| 1 | {x,w} | w | 7,y | ∞ | 2,w | ∞ | 6,w | ∞ | |
| 2 | {x,w,v} | v | 3,v | ∞ | 10,v | 3,v | ∞ | ||
| 3 | {x,w,v,u} | u | 3,v | ∞ | 5,u | 9,u | |||
| 4 | {x,w,v,y} | y | 13,y | 10,v | 3,v | ∞ | |||
| 5 | {x,w,v,u,t} | t | 7,t | 6,t | |||||
| 6 | {x,w,v,u,t,s} | s | 7,t | ||||||
| 7 | {x,w,v,u,t,z} | z | |||||||
| 目的 | 下一跳 | 代价 |
|---|---|---|
| s | (1) | (2) |
| t | (3) | (4) |
| u | (5) | (6) |
| v | (7) | (8) |
| w | w | 1 |
| y | (9) | (10) |
| z | (11) | (12) |
| 目的 | 下一跳 | 代价 |
|---|---|---|
| s | w | 6 |
| t | w | 5 |
| u | w | 3 |
| v | w | 2 |
| w | w | 1 |
| y | w | 3 |
| z | w | 7 |
距离向量路由选择算法
距离向量路由选择算法的基础是Bellman-Ford方程(简称B-F方程)。
令dx(y)表示结点x到结点y的路径的最低费用(即广义最短距离),根据B-F方程,有以下公式:
dx(y) = min {c(x,v)+dv(y)} ; v∈ {x的邻居}
dx(z) =min {c(x,z)+dz(z) , c(x,y)+dy(z)}
dx(z) =min {c(x,z)+dz(z) , c(x,y)+dy(z)}
=min {7+0,2+3}
=min {7,5}
=5
所以得到结点x到结点z的最短路径是{x,y,z} 网络中每个结点x,估计自己到网络中所有结点y的最短距离,记为Dx(y),称为结点x的距离向量。
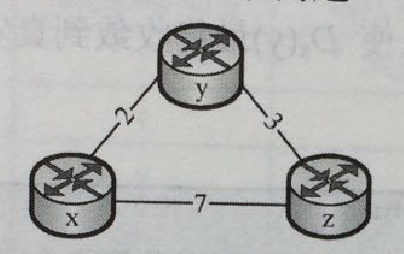
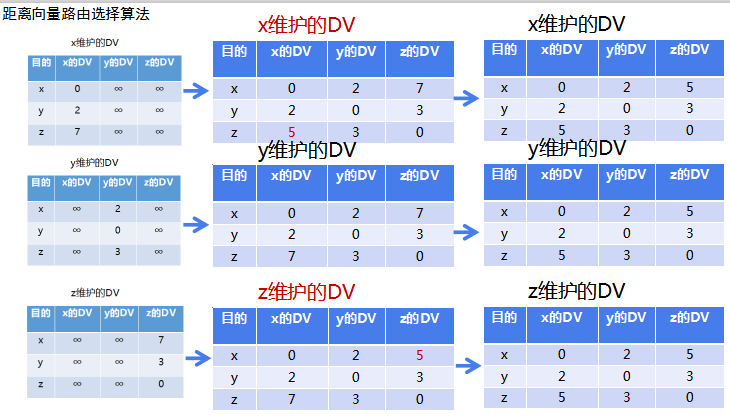
距离向量路由选择算法过程
1、x,y,z结点先初始化,得到初始化向量DV;
2、邻居结点进行第一次DV交换。x的距离向量(0,2,7)变为(0,2,5),z的距离向量(7,3,0)变为(5,3,0),结点y未发生改变。结点x和z需要把新的距离向量通告给邻居,y不需要通告。
3、x,y,z分别收到了新的通告,再次基于B-F方程,计算最短距离。均为发生改变,各结点均收敛。
LS算法:需要全网广播链路状态分组。
DV算法:需要在邻居路由器之间交换距离向量。
层次化路由选择
自治系统(autonomous system,AS):大规模的互联网按组织边界、管理边界、网络技术边界或功能划分为多个自治系统,每个自治系统由一组运行相同路由协议和路由选择算法的路由器组成。
网关路由器:每个自治系统都存在至少一个与其他路由器互连的路由器。
层次化路由选择:实现大规模网络路由选择最有效、可行的解决方案。
层次化路由选择原理:
将大规模互联网的路由划分为两层:自治系统内路由选择和自治系统间路由选择。
在这种网络中,路由器转发表由自治系统内路由选择协议和自治系统间路由选择协议共同设置。
自治系统内路由选择协议:计算到达自治系统内到达目的网络的路由。
自治系统间路由选择协议:负责与其他自治系统的网络可达性信息,交换给其所在自治系统内的其他路由器,这些路由器进一步将这些路由信息存储到转发表。
Internet路由选择协议
Internet路由:层次化路由选择。
一、Internet自治系统内路由选择协议称为内部网关协议(IGP) Interior Gateway Protocol
典型的IGP协议:路由信息协议(Routing Information Protocol,RIP)
开放最短路径优先协议(Open Shortest Path First,OSPF)
二、Internet自治系统间路由选择协议称为外部网关协议(EGP) Exterior Gateway Protocol
典型的EGP协议:边界网关协议(Border Gateway Protocol,BGP)
RIP:广泛使用,基于距离向量路由选择算法的IGP。
RIP报文:封装进UDP数据报。
RIP特性:
第一、在度量路径时采用的是跳数。
第二、RIP的费用定义在源路由器和目的子网之间。
第三、RIP被限制的网络直径不超过15跳的自治系统内使用。
路由器B上的转发表
| 目的子网 | 下一跳路由器 | 到目的子网的跳数 |
|---|---|---|
| w | A | 2 |
| x | - | 1 |
| y | C | 2 |
| z | C | 10 |
| … | … | … |
来自路由器A的RIP通告
| 目的子网 | 下一跳路由器 | 到目的子网的跳数 |
|---|---|---|
| w | - | 1 |
| x | - | 1 |
| z | F | 3 |
| … | … | … |
路由器B根据路由器A的RIP通告更新后的转发表
| 目的子网 | 下一跳路由器 | 到目的子网的跳数 |
|---|---|---|
| w | A | 2 |
| x | - | 1 |
| y | C | 2 |
| z | A | 4 |
| … | … | … |
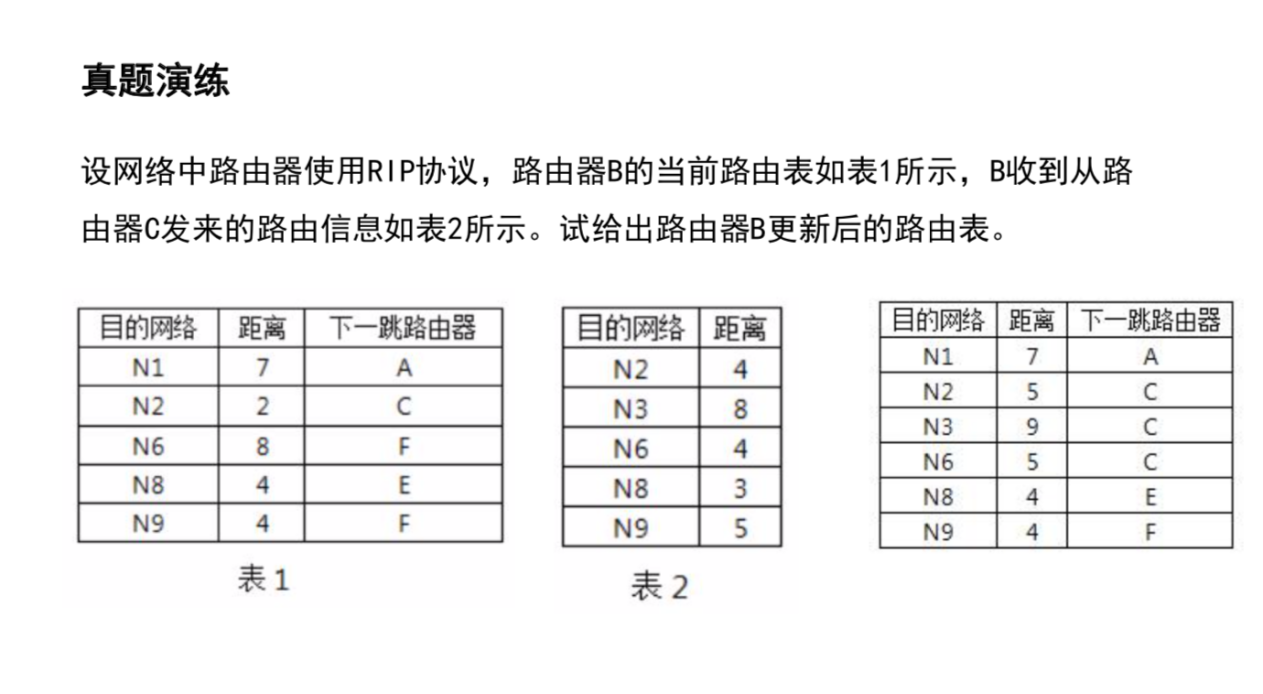
OSPF:较大规模的AS。链路状态选择算法。直接封装在IP数据报传输。
优点: 安全、支持多条相同费用路径 、支持区别化费用度量 、支持单播路由与多播路由、分层路由
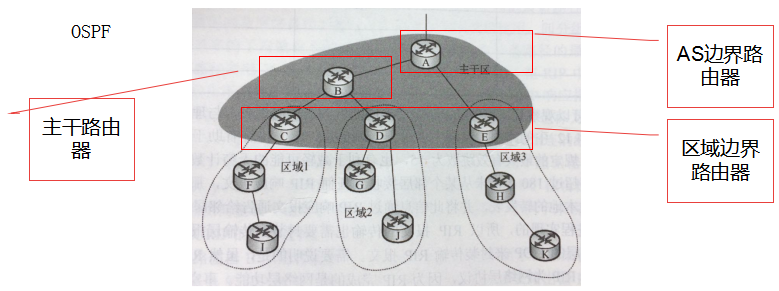
BGP:实现跨自治系统的路由信息交换。典型版本是BGP4。
BGP应用进程实现的,传输层使用TCP。 每个AS可以通过BGP实现如下功能:
1)从相邻AS获取某子网的可达性信息
2)向本AS内部的所有路由器传播跨AS的某子网可达性信息
3)基于某子网可达性信息和AS路由策略,决定到达该子网的最佳路由
BGP主要有4种报文:
1)OPEN(打开)报文,用来与BGP对等方建立BGP会话
2)UPDATE(更新)报文,用来通告某一路由可达性信息,或者撤销已有路由
3)KEEPALIVE(保活)报文,用于对打开报文的确认,或周期性地证实会话的有效
4)NOTIFICATION(通知)报文,用来通告差错
| 协议名称 | 封装 | 适用范围 |
|---|---|---|
| RIP | UDP数据报 | 较小AS内 |
| OSPF | IP数据报 | 大规模AS内 |
| BGP | TCP | 跨AS |

若有收获,就点个赞吧
0 人点赞
