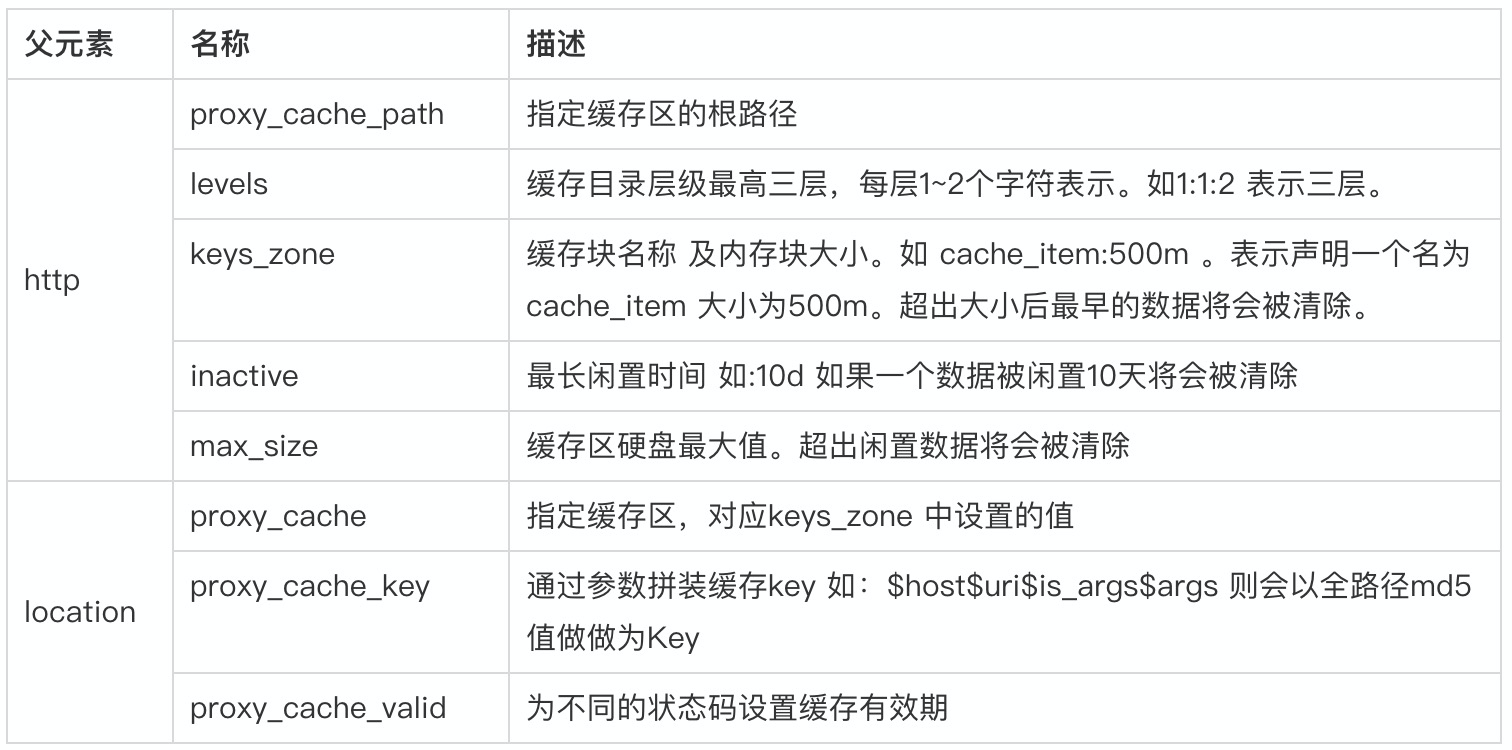
Nginx的系统结构
Nginx包含一个单一的master进程和多个worker进程。所有的这些进程都是单线程,并且设计为同时处理成千上万的连接。worker进程是处理连接的地方,它用于处理客户端请求。master进程负责读取配置文件、处理套接字。派生worker进程、打开日志文件等。总之,master进程是一个可以通过处理信号响应来管理请求的进程。
Nginx性能参数调优
常规参数讲解
进入/etc/nginx文件夹,编辑nginx.conf,可以看到下面的参数。
# nginx进程数,建议按照cpu数目来指定,一般跟cpu核数相同或为它的倍数。worker_processes 8;# 每个worker 进程的最大连接数worker_connections 1024#为每个进程分配cpu,上例中将8个进程分配到8个cpu,当然可以写多个,或者将一个进程分配到多个cpu。worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;# 作用于event的I/O多路复用模型use epoll;#收到新连接通知后接受尽可能多的连接,作用于eventmulti_accept on;
eopll接口作为poll接口的变体,在Linux内核2.5中被引入。相比select实现的多路复用I/O模型,epoll最大的好处在于它不会随着被监控描述符数目的增长而导致效率急速下降。
worker_process number;
每个worker进程都是单线程的进程,他们会调用各个模块以实现多种多样的功能。如果这些模块确认不会出现阻塞式的调用,那么,有多少CPU内核就应该配置多少个进程;反之,如果有可能出现阻塞式调用,那么配置稍微多一些的worker进程。
例如:如果业务方面会致使用户请求大量读取本地磁盘上的静态资源文件,而且服务器上的内存较小,以至于大部分的请求访问静态资源文件时都必须读取磁盘(磁头的寻址是缓慢的),而不是内存中的磁盘缓存,那么磁盘I/O的调用可能会阻塞住worker进程少量时间,进而导致服务整体性能下降。
每个worker进程的最大连接数
语法:worker_connections number;默认:worker_connections 1024
worker_cpu_affinity cpumask[cpumask……]
绑定Nginx worker进程到指定的CPU内核
为什么绑定worker进程到指定的CPU内核呢?假定每一个worker进程都是非常繁忙的,如果多个worker进程都在抢同一个CPU,那么这就会出现同步问题。反之,如果每一个worker进程都独享一个CPU,就在内核的调度上实现了完全的并发。
例如,如果有4颗CPU内核,就可以进行如下配置:
worker_processes 4;worker_cpu_affinity 1000 0100 0010 0001;
注意worker_cpu_affinity 配置仅对Linux操作系统有效。
查看当前机器cpu# 查看当前机器物理cpu数量cat /proc/cpuinfo|grep "physical id"|sort|uniq|wc -l# 1# 查看当前机器物理cpu核心数量cat /proc/cpuinfo|grep "cpu cores"|uniq#cpu cores : 2
Nginx worker进程优先设置
语法:worker_priority nice;默认:worker_priority 0;
优先级由静态优先级和内核根据进程执行情况所做的动态调整(目前只有±5的调整)共同决定。nice值是进程的静态优先级,他的取值范围是-20~+19,-20是最高优先级,+19是最低优先级。因此,如果用户希望Nginx占有更多的系统资源,那么可以把nice值配置的更小一些,但不建议比内核进程的nice值(通常为-5)还要小
Nginx worker进程可以打开的最大句柄描述符个数
语法:worker_rlimit_nofile limit;默认:空
更改worker进程的最大打开文件数限制。如果没设置的话,这个值为操作系统的限制。设置后你的操作系统和Nginx可以处理比”ulimit -a“更多的文件,所以把这个值设高,这样nginx就不会有“too many open files” 问题了
是否打开accept锁
语法:accept_mutex[on|off]默认:accept_mutext on;
accept_mutex是Nginx的负载均衡锁,当某一个worker进程建立的连接数量达到work_connections配置的最大连接数的7/8时,会大大地减小该worker进程试图建立新TCP连接的机会,accept锁默认是打开的,如果关闭它,那么建立TCP连接的耗时会更短,但worker进程之间的负载会非常不均衡,因此不建议关闭它。
使用accept锁后到真正建立连接之间的延迟时间
语法:accept_mutex_delay Nms;默认:accept_mutex_delay 500ms;
在使用accept锁后,同一时间只有一个worker进程能够取到accept锁。这个accept锁不是堵塞锁,如果取不到会立刻返回。如果只有1个worker进程试图取锁而没有取到,他至少要等待acept_mutex_delay定义的时间才能再次试图取锁。
Nginx高速缓存实战
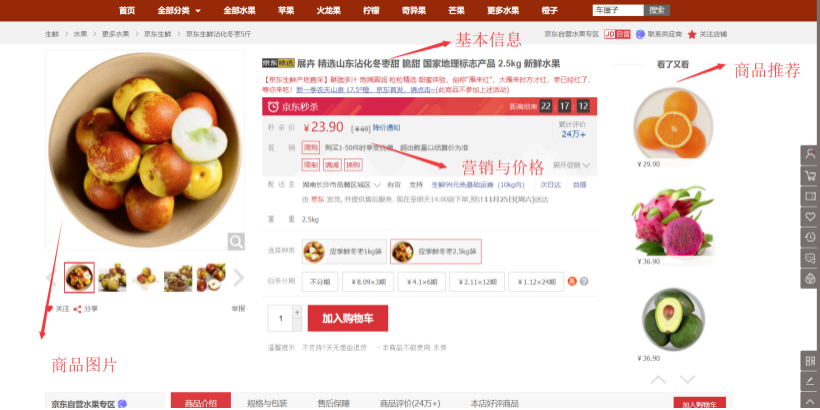
对于商品详情页涉及了如下主要服务:
- 商品详情页HTML页面渲染
- 价格服务
- 促销服务
- 库存状态/配送至服务
- 广告词服务
- 预售/秒杀服务
- 评价服务
- 试用服务
- 推荐服务
- 商品介绍服务
- 各品类相关的一些特殊服务
解决方案:
- 采用Ajax动态加载价格、广告、库存等服务
- 采用key value 缓存详情页主体html
方案架构

问题
当达到500QPS的时候很难继续压测上去。
分析原因
一个详情页html主体达平均150kb,那么在500QPS已接近千M局域网宽带极限。必须减少内网通信。
基于Nginx静态缓存的解决方案:

Nginx缓存配置
配置步骤
- 客户端、代理请求缓存
- 设置缓存空间,存储缓存文件
- 在location中使用缓存空间
- 打开文件的缓存配置
#客户端请求主体的缓冲区大小client_body_buffer_size 512k;#客户端请求头部的缓冲区大小,这个可以根据系统分页大小来设置client_header_buffer_size 4k;client_max_body_size 512k;large_client_header_buffers 2 8k;proxy_buffer_size 16k;proxy_buffers 4 64k;proxy_busy_buffers_size 128k;proxy_temp_file_write_size 128k;#指定在何种情况下一个失败的请求应该被发送到下一台后端服务器proxy_next_upstream http_502 http_504 http_404 error timeout invalid_header;#设置缓存空间,存储缓存文件proxy_cache_path /usr/local/nginx/cache levels=1:2 keys_zone=nginx-cache:20m max_size=50g inactive=168h;#在location中使用缓存空间,pathname是项目的目录,请自定义location /pathname {proxy_set_header X-Real-IP $remote_addr;proxy_cache nginx-cache;proxy_cache_valid 200 304 302 5d;proxy_cache_valid any 5d;proxy_cache_key '$host:$server_port$request_uri';add_header X-Cache '$upstream_cache_status from $host';proxy_set_header X-Real-IP $remote_addr;proxy_pass http://localhost/pathname;}#打开文件的缓存配置#为打开文件指定缓存,默认是没有启用的,max 指定缓存数量,建议和打开文件数一致,inactive 是指经过多长时间文件没被请求后删除缓存。open_file_cache max=65535 inactive=60s;#文件描述符一直是在缓存中打开的,如果有一个文件在inactive时间内一次没被使用,它将被移除。open_file_cache_min_uses 1;#指定多长时间检查一次缓存的有效信息。open_file_cache_valid 80s;
缓存参数详细说明
查看缓存目录
上述配置的结果,重启生效后,我们可以看到生成了很多缓存文件在缓存存储路径为:/usr/local/nginx/cache,levels=1:2代表缓存的目录结构为2级目录
如下图,缓存会在/usr/local/nginx/cache目录下生成,包含2级目录,在之下就是缓存文件,测试的时候可以到该目录下查看缓存文件是否生成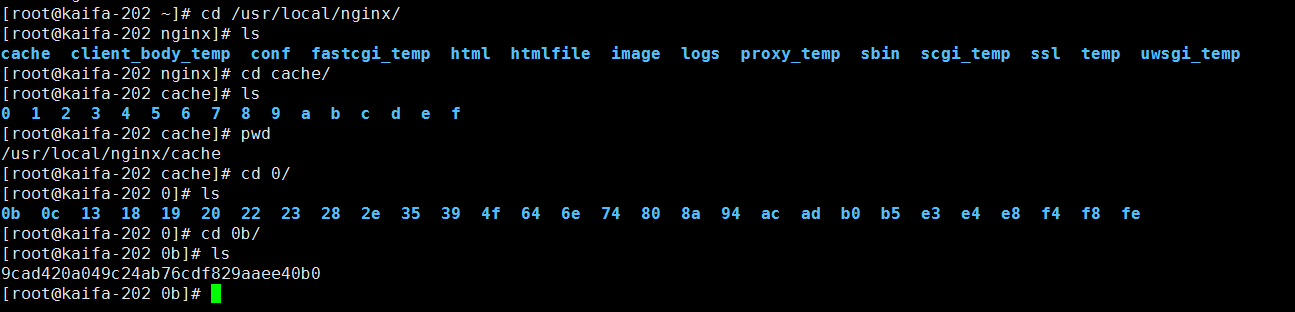
我们打开其中一个文件看看,会发现一些蹊跷,这里存储了请求头的信息。当我们处理一个HTTP请求的时候,他会先从这里读取。
缓存的清除
该功能可以采用第三方模块 ngx_cache_purge 实现。为nginx添加ngx_cache_purge模块
#下载ngx_cache_purge 模块包 ,这里nginx 版本为1.6.2 purge 对应2.0版wget http://labs.frickle.com/files/ngx_cache_purge-2.3.tar.gz#查看已安装模块./sbin/nginx -V#进入nginx安装包目录 重新安装 --add-module为模块解压的全路径./configure --prefix=/root/svr/nginx --with-http_stub_status_module --with-http_ssl_module --add-module=/root/svr/nginx/models/ngx_cache_purge-2.0#重新编译make#拷贝 安装目录/objs/nginx 文件用于替换原nginx 文件#检测查看安装是否成功nginx -t
清除配置
location ~ /clear(/.*) {#允许访问的IPallow 127.0.0.1;allow 192.168.0.193;#禁止访问的IPdeny all;#配置清除指定缓存区和路径(与proxy_cache_key一至)proxy_cache_purge cache_item '$host:$server_port$request_uri';}
配置好以后直接访问:
这里 192.168.0.193 域名设置为 www.test.com
# 访问生成缓存文件http://www.test.com/?a=1# 清除生成的缓存,如果指定缓存不存在 则会报404 错误。http://www.testcom/clear/?a=1
指定不缓存页面
配置语法

例子:
...# 判断当前路径是否是指定的路径if($request_uri ~ ^/(url3|login|register|password\/reset)) {#设置一个变量用来存储是否是需要缓存set $cookie_nocache 1;}location / {...proxy_no_cache $cookie $arg_nocache $arg_comment;...}...
缓存命中分析
在http header上增加命中显示
Nginx提供了$upstream_cache_status 这个变量来显示缓存的状态,我们可以在配置中添加一个http头来显示这一状态,达到类似squid的效果。
location / {proxy_redirect off;proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_connect_timeout 180;proxy_send_timeout 180;proxy_read_timeout 180;proxy_buffer_size 128k;proxy_buffers 4 128k;proxy_busy_buffers_size 128k;proxy_temp_file_write_size 128k;proxy_cache cache;proxy_cache_valid 200 304 1h;proxy_cache_valid 404 1m;proxy_cache_key '$host:$server_port$request_uri';add_header Nginx-Cache "$upstream_cache_status";proxy_pass http://backend;}
而通过curl或浏览器查看到的header如下:
HTTP/1.1 200 OKDate: Mon, 22 Apr 2013 02:10:02 GMTServer: nginxContent-Type: image/jpegContent-Length: 23560Last-Modified: Thu, 18 Apr 2013 11:05:43 GMTNginx-Cache: HITAccept-Ranges: bytesVary: User-Agent
$upstream_cache_status 包含以下几种状态
- MISS 未命中,请求被传送到后端
- HIT 缓存命中
- EXPIRED 缓存已过期,请求被传送带后端
- UPDATING 正在更新缓存,将使用旧的应答
- STALE 后端将得到过期的应答
Nginx cache命中率统计
既然nginx为我们提供了$upstream_cache_status 函数,自然可以将命中状态写入到日志中。具体可以如下定义日志格式
# crontab -l1 0 * * * /opt/<a href="http://www.test.com/" title="shell"target="_blank">shell</a>/nginx_cache_hit >> /usr/local/nginx/logs/hit
该脚本的内容为
#!/bin/bashLOG_FILE='/usr/local/nginx/logs/access.log.1'LAST_DAY=$(date +%F -d "-1 day")awk '{if($NF==""HIT"") hit++} END {printf "'$LAST_DAY': %d %d %.2f%n", hit,NR,hit/NR}' $LOG_FILE
Nginx其他优化措施
动静分离
将静态文件存储到/usr/share/nginx/html文件夹中,配置静态文件拦截规则。单个项目可以直接放在/usr/share/nginx/html根目录下,如果是多个项目,则要根据项目的根目录创建文件夹来保存静态文件。
配置拦截规则如下:
location ~ .*\.(eot|svg|ttf|woff|jpg|jpeg|gif|png|ico|cur|gz|svgz|mp4|ogg|ogv|webm) {#所有静态文件直接读取硬盘root /usr/share/nginx/html;expires 30d; #缓存30天}location ~ .*\.(js|css)?${#所有静态文件直接读取硬盘root /usr/share/nginx/html;expires 12h;}
结果:整个网站的访问速度都会减少,大部分内容都将从静态文件目录或硬盘中读取
连接超时
长时间占着连接资源不释放,最终会导致请求的堆积,Nginx处理请求效率大大降低。所以我们对连接的控制都要注意设置超时时间,通过超时机制自动回收资源,避免资源浪费
#客户端、服务端设置server_names_hash_bucket_size 128;server_names_hash_max_size 512;# 长连接超时配置keepalive_timeout 65;client_header_timeout 15s;client_body_timeout 15s;send_timeout 60s;#代理设置#与后端服务器建立连接的超时时间。注意这个一般不能大于75秒proxy_connect_timeout 30s;proxy_send_timeout 120s;#从后端服务器读取响应的超时proxy_read_timeout 120s;
GZIP压缩
在我们进行gzip打包压缩之前,最好将一些静态文件先进行压缩为min文件,请求的时候合并为同一文件。再通过gzip压缩后,你会发现网站加载又加速了。
#开启gzip,减少我们发送的数据量gzip on;#允许压缩的最小字节数gzip_min_length 1k;#4个单位为16k的内存作为压缩结果流缓存gzip_buffers 4 16k;#设置识别HTTP协议版本,默认是1.1gzip_http_version 1.1;#gzip压缩比,可在1~9中设置,1压缩比最小,速度最快,9压缩比最大,速度最慢,消耗CPUgzip_comp_level 4;#压缩的类型gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript;#给代理服务器用的,有的浏览器支持压缩,有的不支持,所以避免浪费不支持的也压缩,所以根据客户端的HTTP头来判断,是否需要压缩gzip_vary on;#禁用IE6以下的gzip压缩,IE6的某些版本对gzip的压缩支持很不好gzip_disable "MSIE [1-6].";
访问限流
我们构建网站是为了让用户访问他们,我们希望用于合法访问。所以不得不采取一些措施限制滥用访问的用户。这种滥用指的是从同一IP每秒到服务器请求的连接数。因为这可能是在同一时间内,世界各地的多台机器上的爬虫机器人多次尝试爬取网站的内容
#限制用户连接数来预防DOS攻击limit_conn_zone $binary_remote_addr zone=perip:10m;limit_conn_zone $server_name zone=perserver:10m;#限制同一客户端ip最大并发连接数limit_conn perip 2;#限制同一server最大并发连接数limit_conn perserver 20;#限制下载速度,根据自身服务器带宽配置limit_rate 300k;
搞数据传输配置
#开启文件的高效传输模式。tcp_nopush和tcp_nodelay可防止网络及磁盘i/o阻塞,提升nginx工作效率;sendfile on;#数据包不会马上传送出去,等到数据包最大时,一次性的传输出去,这样有助于解决网络堵塞。tcp_nopush on;#只要有数据包产生,不管大小多少,就尽快传输tcp_nodelay on;
内核参数的优化
编辑/etc/sysctl.conf文件,根据需要调整参数配置
#如果想把timewait降下了就要把tcp_max_tw_buckets值减小,默认是180000net.ipv4.tcp_max_tw_buckets = 5000#开启重用功能,允许将TIME-WAIT状态的sockets重新用于新的TCP连接net.ipv4.tcp_tw_reuse = 1#系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤儿连接将即刻被复位并打印出警告信息。这个限制仅仅是为了防止简单的DoS攻击net.ipv4.tcp_max_orphans = 262144#当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时。我们可以调短时间跨度net.ipv4.tcp_keepalive_time = 30
日志配置
日志文件对于我们日常运维至关重要,如果没有日志排查问题,你将很难判断异常的所在,要解决问题无异于大海捞针。日志的保存是必要的,不可缺少的,我们来看下怎么配置有利于排查问题?
- 关键字:其中关键字access_log,error_log不能改变
- error_log 错误日志级别:【debug | info | notice | warn | error | crit | alert | emerg】,级别越高记录的信息越少。不要配置info等级较低的级别,会带来大量的磁盘I/O消耗
error_log 生产场景一般是 warn | error | crit 这三个级别之一
#定义日志模板log_format 日志模板名称 日志格式;#访问日志access_log path format gzip[=level] [buffer=size] [flush=time];关键字 存放的路径 日志格式模板 gzip压缩,level指压缩级别 存放缓存日志的缓存大小 保存在缓存中的最长时间#错误日志error_log <FILE> <LEVEL>;关键字 日志文件 错误日志级别#示例log_format main '$remote_addr - $remote_user [$time_local] "$request"''$status $body_bytes_sent "$http_referer"''"$http_user_agent" "$http_x_forwarded_for"';

若有收获,就点个赞吧
0 人点赞
