0.参考资料
1.概述
- 运用共享技术有效地支持大量细粒度的对象。—《设计模式》GoF
- 享元模式(Flyweight Pattern) 也叫 蝇量模式: 运用共享技术有效地支持大量细粒度的对象
- 常用于系统底层开发,解决系统的性能问题。像数据库连接池,里面都是创建好的连接对象,在这些连接对象中有我们需要的则直接拿来用,避免重新创建,如果没有我们需要的,则创建一个
- 享元模式能够解决重复对象的内存浪费的问题,当系统中有大量相似对象,需要缓冲池时。不需总是创建新对象,可以从缓冲池里拿。这样可以降低系统内存,同时提高效率
- 享元模式经典的应用场景就是池技术了,String常量池、数据库连接池、缓冲池等等都是享元模式的应用,享元模式是池技术的重要实现方式
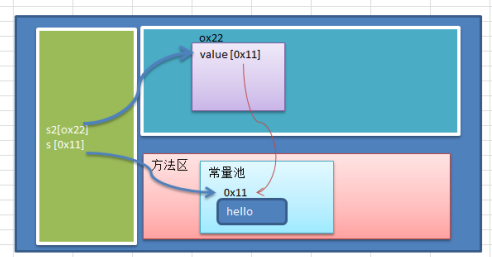
1.1动机
- 在软件系统采用纯粹对象方案的问题在于大量细粒度的对象会很快充斥在系统中,从而带来很高的**运行时**代价一主要指内存需求方面的代价。- 如何在避免大量细粒度对象问题的同时,让外部客户程序仍然能够透明地使用面向对象的方式来进行操作?
1.2结构
- 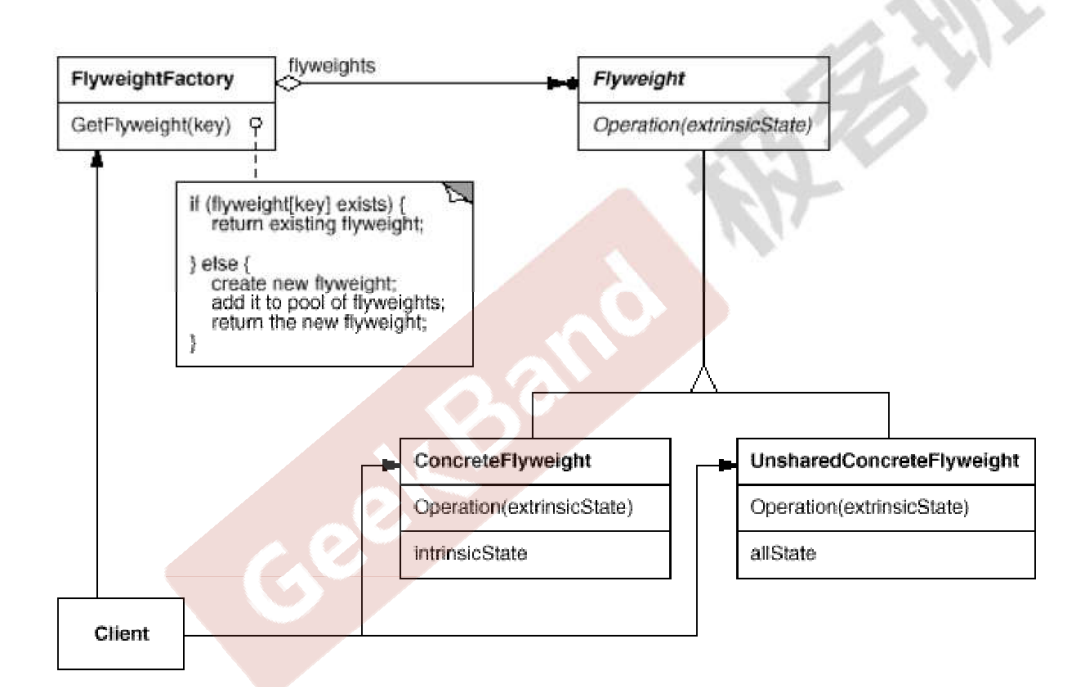- - 说明- FlyWeight: 抽象的享元基类, 同时定义出对象的外部状态和内部状态(后面介绍) 的接口或实现- ConcreteFlyWeight: 是具体的享元角色,是具体的产品类,实现抽象角色定义相关业务- UnSharedConcreteFlyWeight: 是不可共享的角色,一般不会出现在享元工厂- **FlyWeightFactory: 享元工厂** 用于构建一个池容器(集合),同时提供从池中获取对象的方法
1.3内部状态和外部状态
- 享元模式提出了两个要求:细粒度和共享对象。这里就涉及到内部状态和外部状态了,即将对象的信息分为两个部分:内部状态和外部状态- 内部状态: 指对象共享出来的信息,存储在享元对象内部且不会随环境的改变而改变- 外部状态: 指对象得以依赖的一个标记,是随环境改变而改变的、不可共享的状态。- 举例:围棋理论上有361个空位可以放棋子,每盘棋都有可能有两三百个棋子对象产生,因为内存空间有限,一台服务器很难支持更多的玩家玩围棋游戏,如果用享元模式来处理棋子,那么棋子对象就可以减少到只有两个实例,这样就很好的解决了对象的开销问题
2.要点总结
宏观架构
1. 面向对象很好地解决了抽象性的问题,但是作为一个运行在机器中的程序实体我们需要考虑对象的代价问题。Flyweight主要解决面向对象的代价问题, 一般不触及面向对象的抽象性问题。1. Flyweight采用**对象共享**的做法来降低系统中对象的个数,从而降低细粒度对象给系统带来的内存压力。在具体实现方面,要注意对象状态的处理。1. 对象的数量太大从而导致对象内存开销加大 -- 什么样的数量才算大?这需要我们仔细的根据具体应用情况进行评估,而不能凭空臆断。
微观代码
1. 在享元模式这样理解,“享”就表示共享,“元”表示对象1. 系统中有大量对象,这些对象**消耗大量内存,并且对象的状态大部分可以外部化**时,我们就可以考虑选用享元模式1. 用唯一标识码判断,如果在内存中有,则返回这个唯一标识码所标识的对象,用HashMap/HashTable存储1. 享元模式大大减少了对象的创建,降低了程序内存的占用,提高效率1. 享元模式提高了系统的复杂度。需要分离出内部状态和外部状态,而外**部状态具有固化特性**,不应该随着内部状态的改变而改变1. 使用享元模式时,注意划分内部状态和外部状态,并且需要有一个工厂类加以控制。1. 享元模式经典的应用场景是需要缓冲池的场景,比如 String常量池、数据库连接池
3.案例
需求
- 小型的外包项目,给客户A做一个产品展示网站,客户A的朋友感觉效果不错,也希望做这样的产品展示网站,但是要求都有些不同:- 有客户要求以新闻的形式发布- 有客户人要求以博客的形式发布- 有客户希望以微信公众号的形式发布
设计
- 直接复制粘贴一份,然后根据客户不同要求,进行定制修改- 给每个网站租用一个空间- 
分析
1. 需要的网站结构相似度很高,而且都不是高访问量网站,如果分成多个虚拟空间来处理,相当于一个相同网站的实例对象很多,造成服务器的资源浪费1. 解决思路:整合到一个网站中,共享其相关的代码和数据,对于硬盘、内存、CPU、数据库空间等服务器资源都可以达成共享,减少服务器资源1. 对于代码来说,由于是一份实例,维护和扩展都更加容易
4.使用模式
方案
类图
- 
代码
- 网站类: 基类 + 实现类
@Data@AllArgsConstructor@NoArgsConstructorpublic abstract class AbstWebType {// 共享的部分, 内部状态String webTypeName;/*** @description: 聚合 "User" 这个外部状态. 实际开发中每种类型的外部状态操作上可能非常繁杂. 所以应留给子类实现*/abstract void use(User user);}public class ConcreteWebType extends AbstWebType{public ConcreteWebType(String webTypeName){this.webTypeName = webTypeName;}@Overridevoid use(User user) {System.out.println("用户: " + user.getUserName() + " 正在浏览;浏览途径: " + this.webTypeName);}}
- 外部状态类: User
// 外部状态, 变动的@Data@AllArgsConstructorpublic class User {String userName;}
- **工厂类**
public class WebTypeFactory {// 模拟对象池private Map<String, AbstWebType> pool = new HashMap<>();public AbstWebType getWebTypeByName(String webTypeName){if ( !pool.containsKey(webTypeName) ){// 若没有当前类型, 则创建.// 实际开发中, 创建一种类型是很复杂的. 案例只是为了满足 返回值的需要.pool.put(webTypeName, new ConcreteWebType(webTypeName));}return pool.get(webTypeName);}public int getCount(){return pool.size();}}
- 测试
public class Client {public static void main(String[] args) {// 工厂类WebTypeFactory factory = new WebTypeFactory();// 发布类型两种AbstWebType web1 = factory.getWebTypeByName("[博客]");AbstWebType web2 = factory.getWebTypeByName("[公众号]");System.out.println(factory.getCount()); // 2AbstWebType web1_A = factory.getWebTypeByName("[博客]");System.out.println(factory.getCount());// 3web1.use(new User("博客读者1"));web2.use(new User("公众号读者1"));web2.use(new User("公众号读者2"));web2.use(new User("公众号读者3"));// 测试对象是否为同一个System.out.println(web1 == web1_A); // true}}
22用户: 博客读者1 正在浏览;浏览途径: [博客]用户: 公众号读者1 正在浏览;浏览途径: [公众号]用户: 公众号读者2 正在浏览;浏览途径: [公众号]用户: 公众号读者3 正在浏览;浏览途径: [公众号]true
5.经典使用
- 常量池中的String, 和各种其它池技术
5.1JDK中Integer的底层缓冲池
说明
- 

若有收获,就点个赞吧
0 人点赞
