数据中台的构建,需要确保全局指标的业务口径一致,要把原先口径不一致的、重复的指标进行梳理,整合成一个统一的指标字典。而这项工作的前提,是要搞清楚这些指标的业务口径、数据来源和计算逻辑。而这些数据都是元数据。
如果没有这些元数据,就没法去梳理指标,更谈不上构建一个统一的指标体系。当看到一个数 700W,如果不知道这个数对应的指标是每日日活,就没办法理解这个数据的业务含义,也就无法去整合这些数据。所以必须要掌握元数据的管理,才能构建一个数据中台。
元数据包括哪些
把元数据划为三类:数据字典、数据血缘和数据特征。通过一个例子来理解这三类元数据。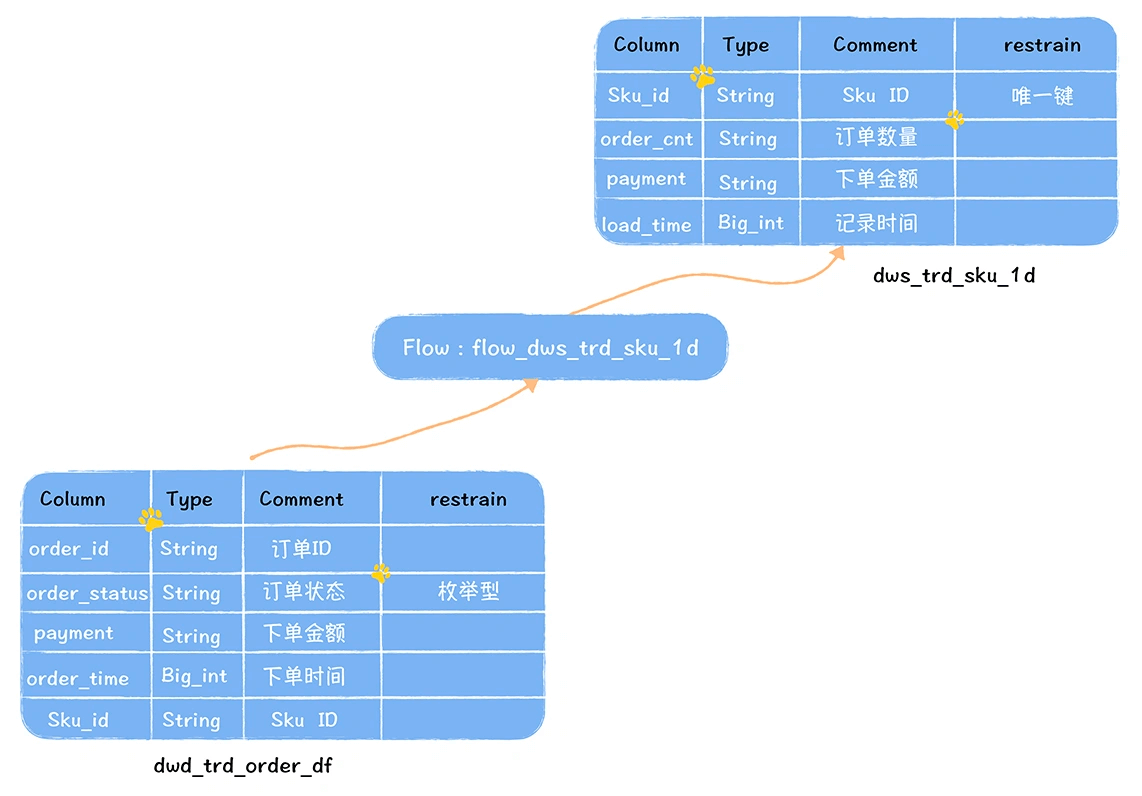
在这个图中,dwd_trd_order_df 是一张订单交易明细数据,任务 flow_dws_trd_sku_1d 读取这张表,按照 sku 粒度,计算每日 sku 的交易金额和订单数量,输出轻度汇总表 dws_trd_sku_1d。
数据字典描述的是数据的结构信息,我们以 dws_trd_sku_1d 为例,数据字典包括:
数据血缘是指一个表是直接通过哪些表加工而来,在上面的例子中,dws_trd_sku_1d 是通过 dwd_trd_order_df 的数据计算而来,所以,dwd_trd_order_df 是 dws_trd_sku_1d 的上游表。
数据血缘一般会帮我们做影响分析和故障溯源。比如说有一天,你的老板看到某个指标的数据违反常识,让你去排查这个指标计算是否正确,你首先需要找到这个指标所在的表,然后顺着这个表的上游表逐个去排查校验数据,才能找到异常数据的根源。
而数据特征主要是指数据的属性信息,我们以 dws_trd_sku_1d 为例:
元数据的种类非常多,为了管理这些元数据,必须要构建一个元数据中心。
业界元数据中心产品
业界的比较有影响力的产品:
开源的有 Netflix 的 Metacat、Apache Atlas;
商业化的产品有 Cloudera Navigator。
Metacat 多数据源集成型架构设计
关于Metacat,可以在 GitHub 上找到相关介绍,它关于多数据源的可扩展架构设计对于数据字典的管理很重要!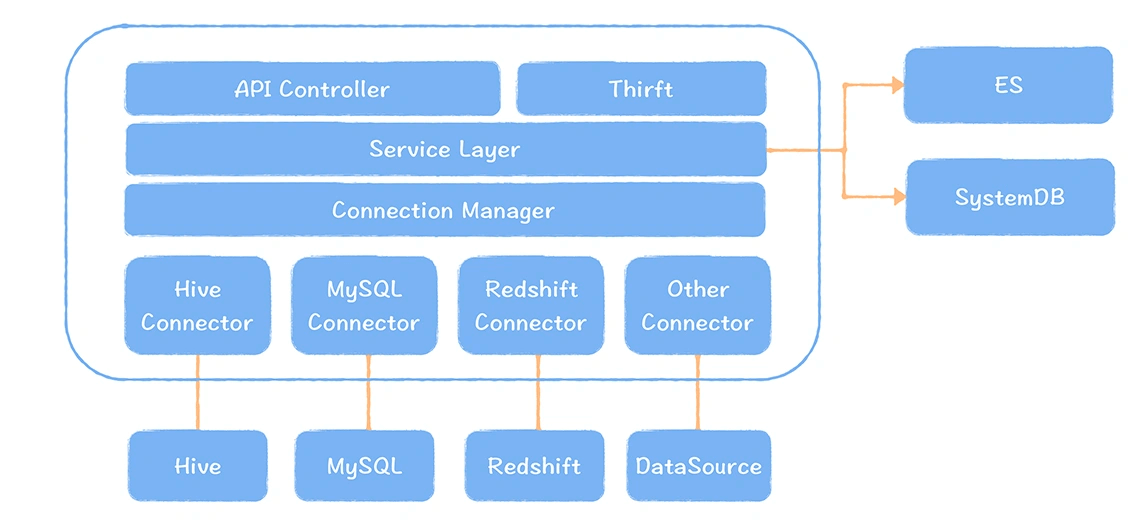
在一般的公司中,数据源类型非常多是很常见的现象,包括 Hive、MySQL、Oracle、Greenplum 等等。支持不同数据源,建立一个可扩展的、统一的元数据层是非常重要的,否则元数据是缺失的。
从上面 Metacat 的架构图中,可以看到Metacat 的设计非常巧妙,它并没有单独再保存一份元数据,而是采取直连数据源拉的方式,一方面它不存在保存两份元数据一致性的问题,另一方面,这种架构设计很轻量化,每个数据源只要实现一个连接实现类即可,扩展成本很低,我把这种设计叫做集成型设计。这种设计方式对于希望构建元数据中心的企业,是非常有借鉴意义的。
Apache Atlas 实时数据血缘采集
它为解决血缘采集的准确性和时效性难题提供了很多的解决思路。血缘采集,一般可以通过三种方式:
通过静态解析 SQL,获得输入表和输出表;
通过实时抓取正在执行的 SQL,解析执行计划,获取输入表和输出表;
通过任务日志解析的方式,获取执行后的 SQL 输入表和输出表。
第一种方式,面临准确性的问题,因为任务没有执行,这个 SQL 对不对都是一个问题。
第三种方式,血缘虽然是执行后产生的,可以确保是准确的,但是时效性比较差,通常要分析大量的任务日志数据。
第二种方式,是比较理想的实现方式,而 Atlas 就是这种实现。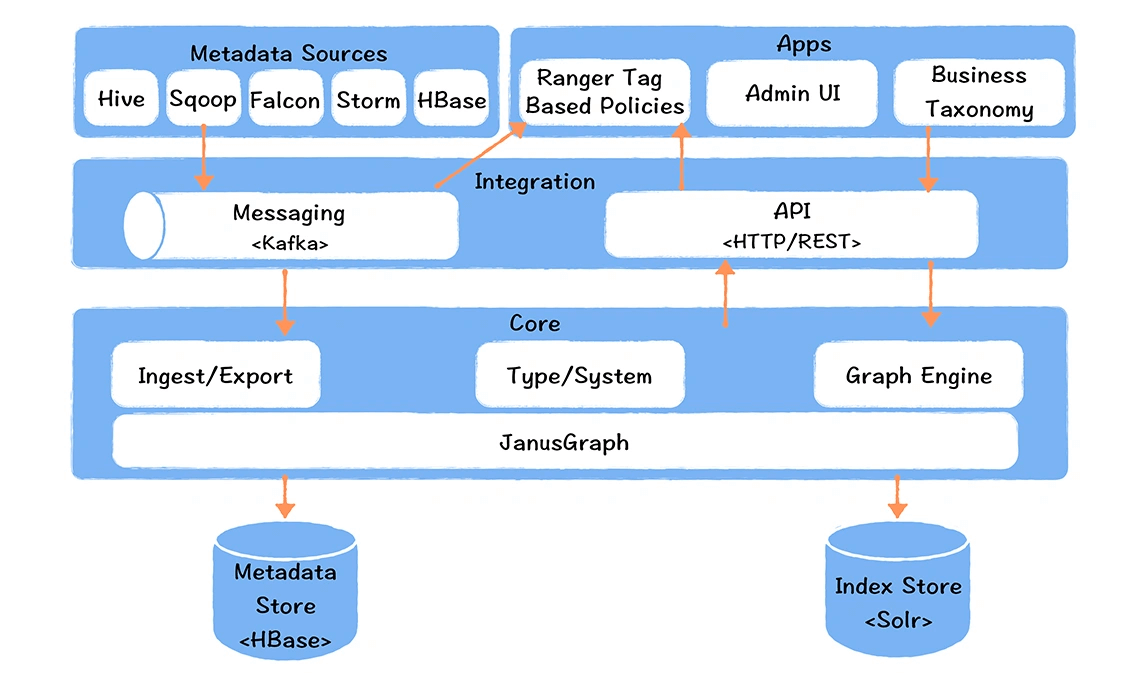
对于 Hive 计算引擎,Atlas 通过 Hook 方式,实时地捕捉任务执行计划,获取输入表和输出表,推送给 Kafka,由一个 Ingest 模块负责将血缘写入 JanusGraph 图数据库中。然后通过 API 的方式,基于图查询引擎,获取血缘关系。对于 Spark,Atlas 提供了 Listener 的实现方式,此外 Sqoop、Flink 也有对应的实现方式。
网易元数据中心设计
多业务线、多租户支持
电商、搜索、音乐是不同的业务线,同一个业务线内,也分为算法、数仓、风控等多个租户,所以元数据中心必须支持多业务线、多租户。
多数据源的支持
元数据中心必须要能够支持不同类型的数据源(比如 MySQL、Hive、Kudu 等),同时还要支持相同数据源的多个集群。为了规范化管理,还需要考虑将半结构化的 KV 也纳入元数据中心的管理(比如 Kafka、Redis、HBase 等)。这些系统本身并没有表结构元数据,所以需要能够在元数据中心里定义 Kafka 每个 Topic 的每条记录 JSON 中的格式,每个字段代表什么含义。
数据血缘
元数据中心需要支持数据血缘的实时采集和高性能的查询。同时,还必须支持字段级别的血缘。
元数据中心需要支持数据血缘的实时采集和高性能的查询。同时,还必须支持字段级别的血缘。什么是字段级别的血缘,举个例子:
insert overwrite table t2 select classid, count(userid) from t1 groupby classid;
t2 表是由 t1 表的数据计算来的,所以 t2 和 t1 是表血缘上下游关系,t2 的 classid 字段是由 t1 的 classid 字段产生的,count 字段是由 userid 经过按照 classid 字段聚合计算得到的,所以 t2 表的 classid 与 t1 的 classid 存在字段血缘,t2 表的 count 分别与 t1 表的 classid 和 userid 存在血缘关系。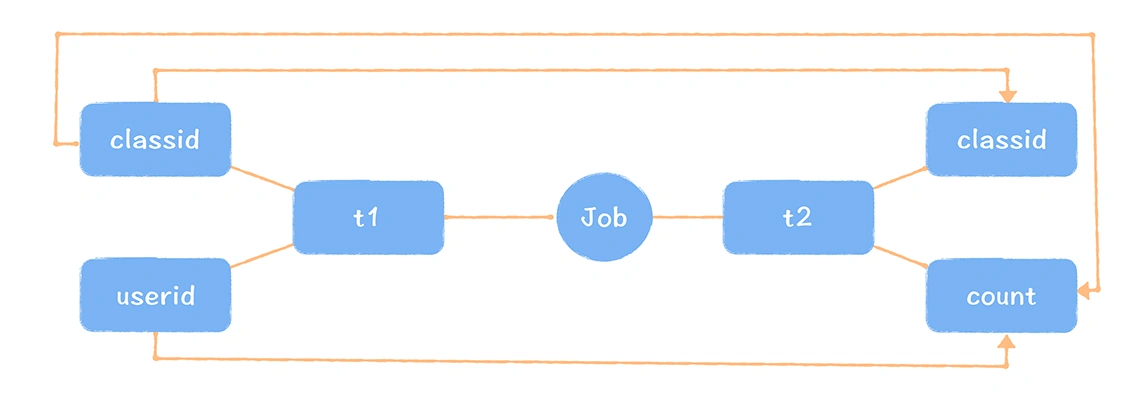
与大数据平台集成
元数据中心需要与 Ranger 集成,实现基于 tag 的权限管理方式。在元数据中心中可以为表定义一组标签,Ranger 可以基于这个标签,对拥有某一个标签的一组表按照相同的权限授权。这种方式大幅提高了权限管理的效率。比如,对于会员、交易、毛利、成本,可以设定表的敏感等级,然后根据敏感等级,设定不同的人有权限查看。另外,元数据中心作为基础元数据服务,包括自助取数分析系统,数据传输系统,数据服务,都应该基于元数据中心提供的统一接口获取元数据。
数据标签
元数据中心必须要支持对表和表中的字段打标签,通过丰富的不同类型的标签,可以完善数据中台数据的特征,比如指标可以作为一种类型的标签打在表上,主题域、分层信息都可以作为不同类型的标签关联到表。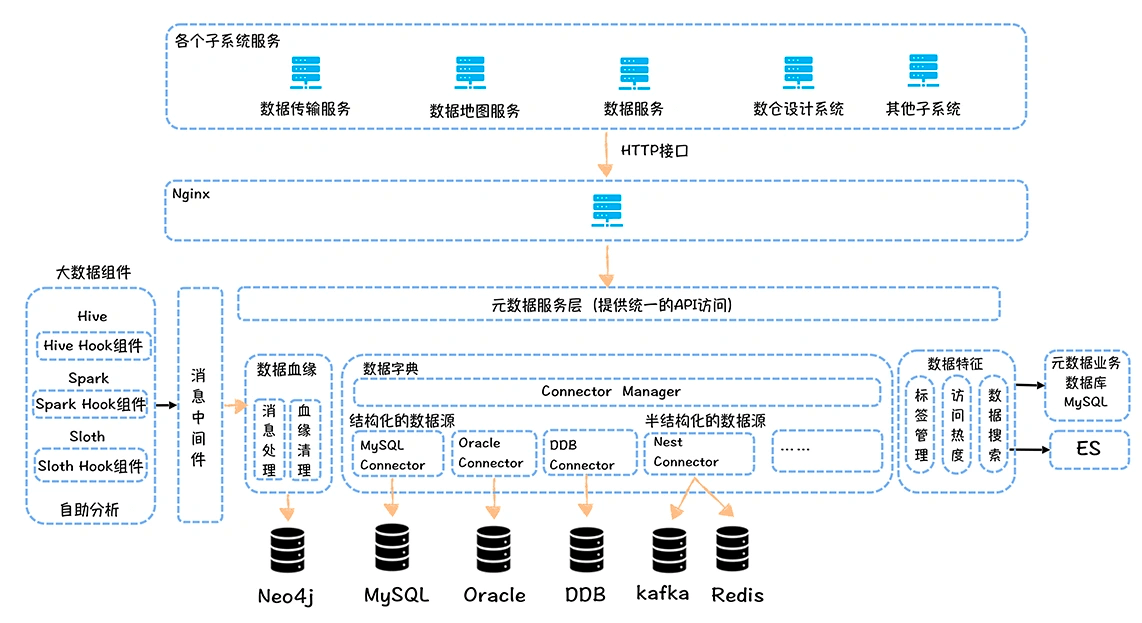
这个图按照功能模块分为数据血缘、数据字典和数据特征。
数据血缘由采集端、消息中间件、消费端以及血缘清理模块组成,基于 Hive Hook,Spark Listener,Flink Hook ,可以获取任务执行时输入表和输出表,推送给统一的消息中间件(Kafka),然后消费端负责将血缘关系沉淀到图数据库中。
图数据库选择 Neo4j,主要考虑是性能快、部署轻量化、依赖模块少,当然,开源的 Neo4j 没有高可用方案,并且不支持水平扩展,但是因为单个业务活跃的表规模基本也就在几万的规模,所以单机也够用,高可用可以通过双写的方式实现。血缘还有一个清理的模块,主要负责定时清理过期的血缘,一般我们把血缘的生命周期设置为 7 天。
数据字典部分,我们参考了 Metacat 实现,我们由一个统一的 Connector Mananger 负责管理到各个数据源的连接。对于 Hive、MySQL,元数据中心并不会保存系统元数据,而是直接连数据源实时获取。对于 Kafka、HBase、Redis 等 KV,我们在元数据中心里内置了一个元数据管理模块,可以在这个模块中定义 Value 的 schema 信息。数据特征主要是标签的管理以及数据的访问热度信息。
元数据中心内置了不同类型的标签,同时允许用户自定义扩展标签类型。指标、分层信息、主题域信息都是以标签的形式存储在元数据中心的系统库里,同时元数据中心允许用户基于标签类型和标签搜索表和字段。元数据中心统一对外提供了 API 访问接口,数据传输、数据地图、数据服务等其他的子系统都可以通过 API 接口获取元数据。
Ranger 可以基于元数据中心提供的 API 接口,获取标签对应的表,然后根据标签更新表对应的权限,实现基于标签的权限控制。
数据地图
元数据中心的界面数据地图是基于元数据中心构建的一站式企业数据资产目录,可以看作是元数据中心的界面。数据开发、分析师、数据运营、算法工程师可以在数据地图上完成数据的检索,解决了“不知道有哪些数据?”“到哪里找数据?”“如何准确的理解数据”的难题。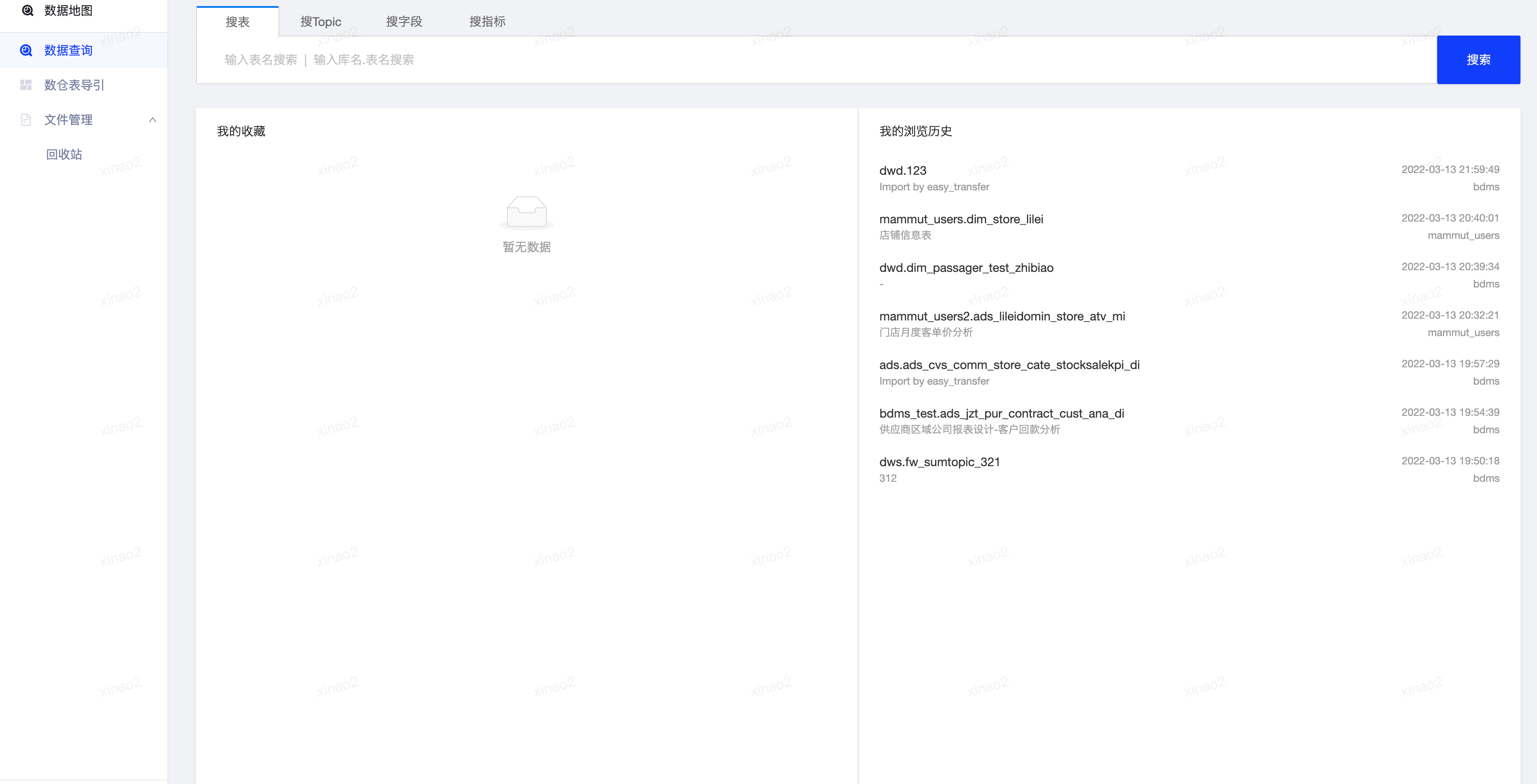
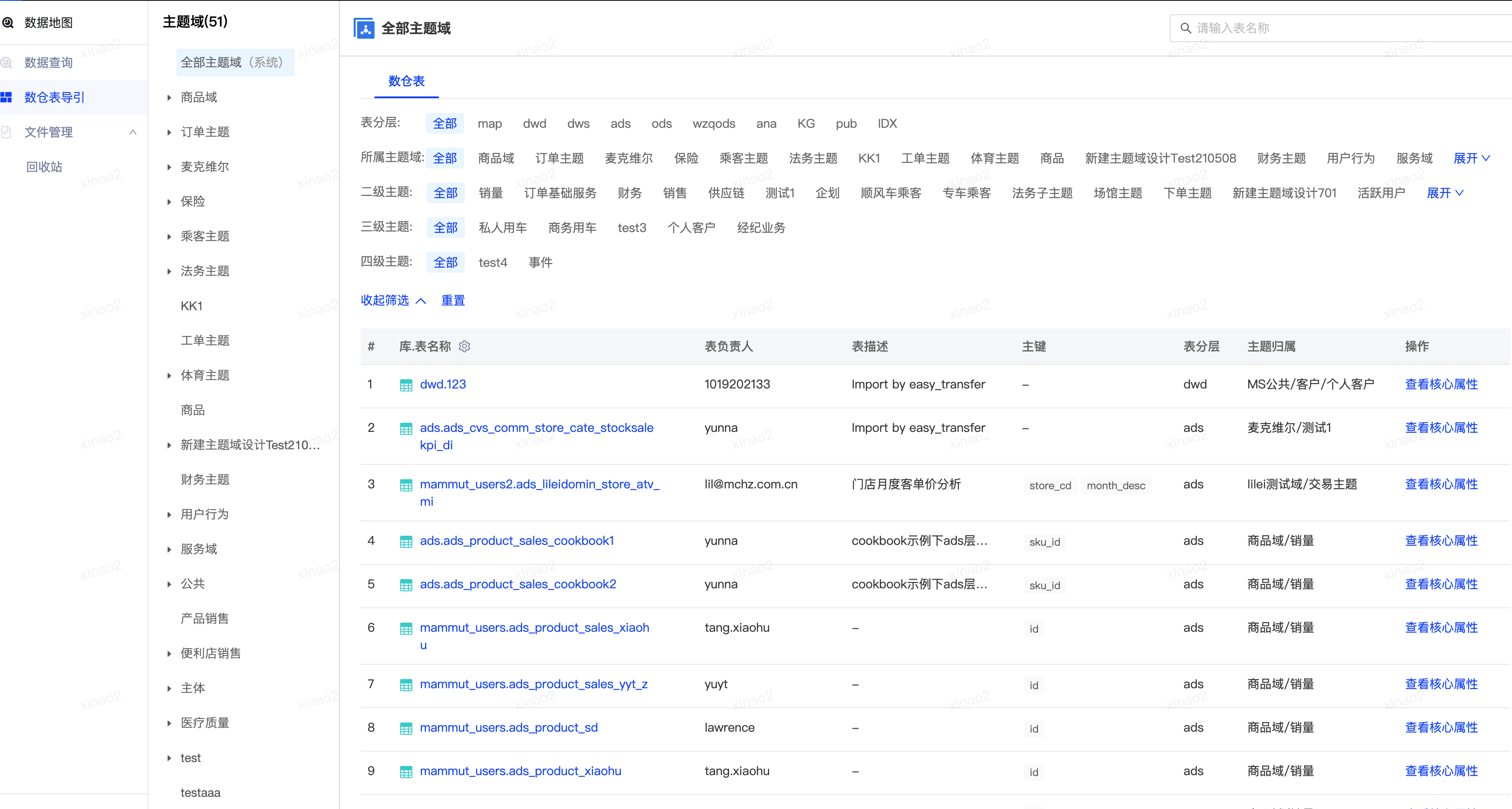
数据地图提供了多维度的检索功能,使用者可以按照表名、列名、注释、主题域、分层、指标进行检索,结果按照匹配相关度进行排序。考虑到数据中台中有一些表是数仓维护的表,有一些表数仓已经不再维护,在结果排序的时候,增加了数仓维护的表优先展示的规则。同时数据地图还提供了按照主题域、业务过程导览,可以帮助使用者快速了解当前有哪些表可以使用。
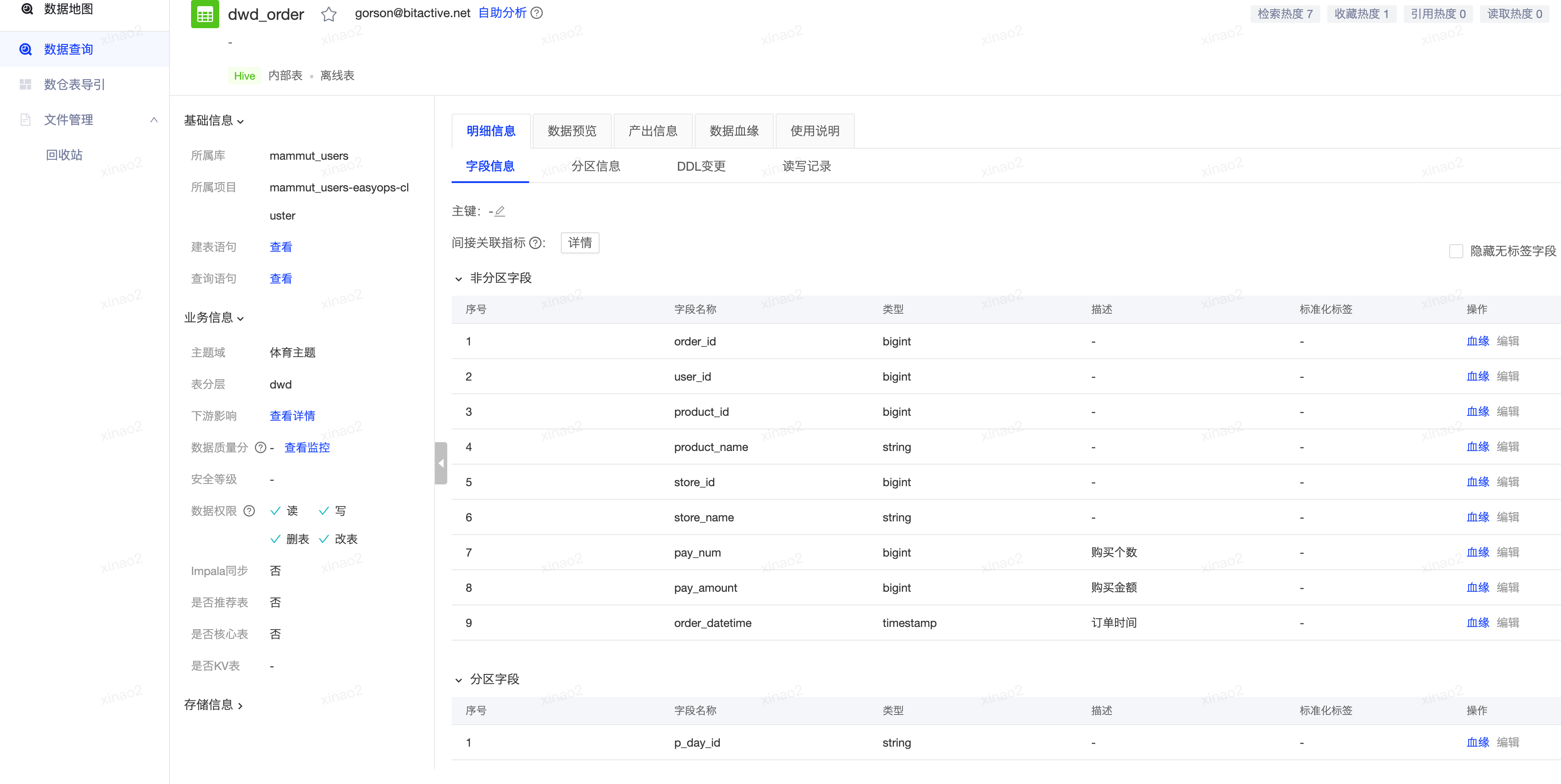
当使用者定位到某一个表打开时,会进入详情页,详情页中会展示表的基础信息,字段信息、分区信息、产出信息以及数据血缘。数据血缘可以帮助使用者了解这个表的来源和去向,这个表可能影响的下游应用和报表,这个表的数据来源。
数据地图同时还提供了数据预览的功能,考虑到安全性因素,只允许预览 10 条数据,用于判断数据是否符合使用者的预期。数据地图提供的收藏功能, 方便使用者快速找到自己经常使用的表。当数据开发、分析师、数据运营找到自己需要的表时,在数据地图上可以直接发起申请对该表的权限申请。数据地图对于提高数据发现的效率,实现非技术人员自助取数有重要作用。
总结
元数据中心设计上必须注意扩展性,能够支持多个数据源,所以宜采用集成型的设计方式。
数据血缘需要支持字段级别的血缘,否则会影响溯源的范围和准确性。
数据地图提供了一站式的数据发现服务,解决了检索数据,理解数据的“找数据的需求”。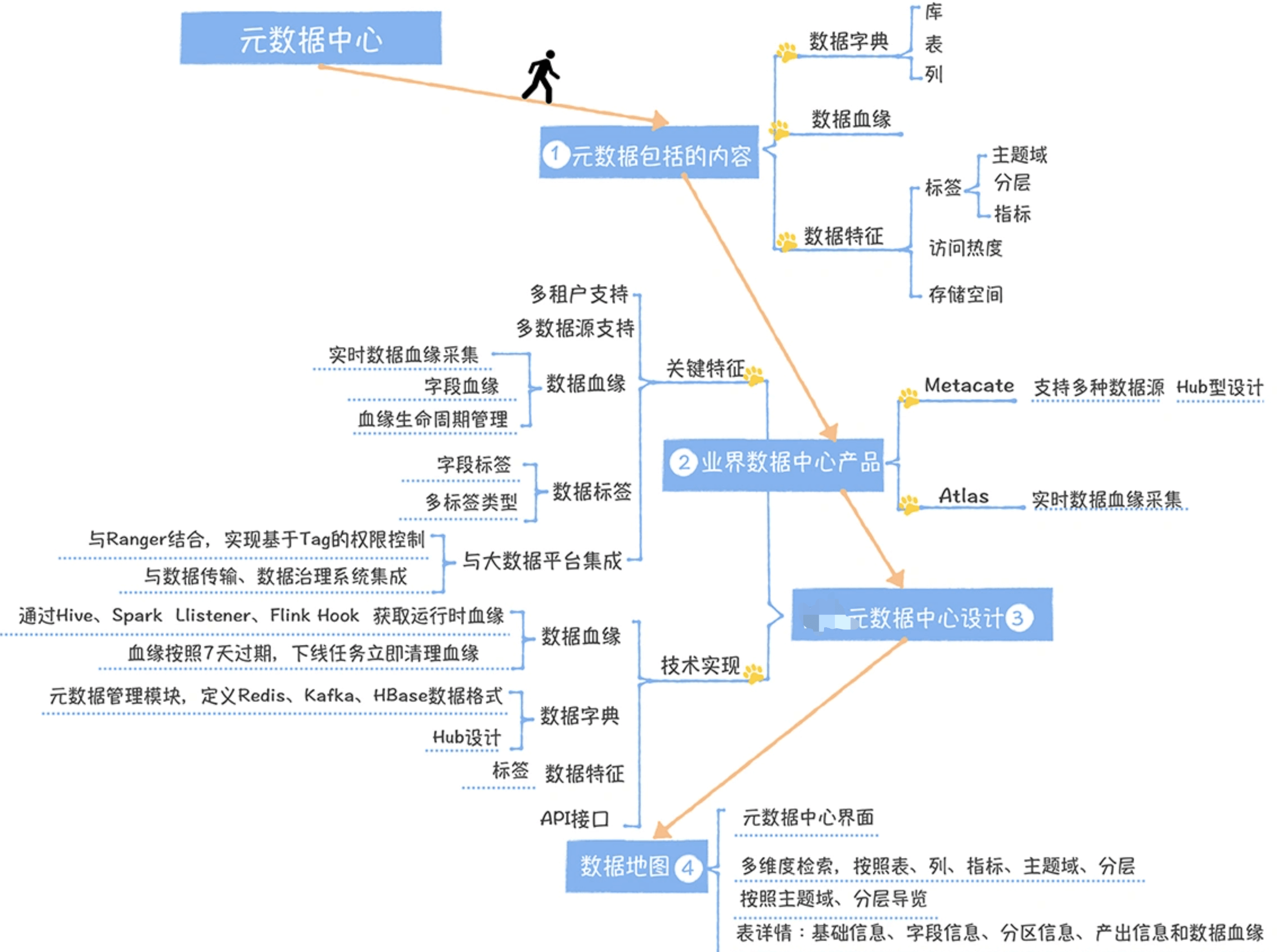

若有收获,就点个赞吧
0 人点赞
