
学习资源整理
Deep_Residual_Learning_For_Image_Recognition.pdf
Identity_Mappings_In_Deep_Residual.pdf
Reducing_the_dimensionality_of_data_with_neural_networks.pdf
kaiming 介绍 ResNet视频 - 知乎
作者源代码
内容整理
两大经典问题
经验表明,网络深度有着至关重要的影响,深层网络可以读取出图片的低层、中层和高层特征
网络深度达到一定程度时,会带来两个经典问题:
- (vanishing/exploding gradients)梯度消失/爆炸
- (degradation)退化问题
Vanishing/Exploding Gradients

上图是一个四层的全连接网络,假设每一层的输出为fi(x),f表示激活函数;那么可以得到:
忽略偏置项,则简单记为:
应用基于梯度下降策略的反向传播算法对训练参数进行更新,根据链式法则,最终每一层的参数更新变成了一长串的链式求导相乘,以下图的反向传播为例:
可以推导出C关于b1的导数为:
假设我们激活函数采用sigmoid,对于sigmoid激活函数,其导数最大值为1/4.而我们初始化的权值绝对值通常都小于1,因此 ,所以通过上面的的链式求导,层数越多,求导的结果就越小,最终导致梯度消失的情况出现
,所以通过上面的的链式求导,层数越多,求导的结果就越小,最终导致梯度消失的情况出现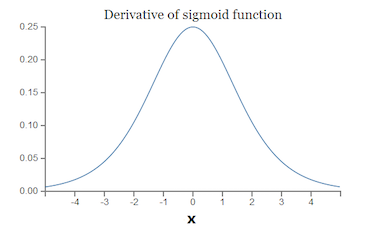
同理,如果我们采用的激活函数最终计算的 ,层数越多,求导的结果就越大,最后呈指数增长,导致梯度爆炸的情况出现
,层数越多,求导的结果就越大,最后呈指数增长,导致梯度爆炸的情况出现
Degradation
模型退化可以简单理解为在模型的每层中只有少量隐藏单元对不同的输入改变它们的激活值,而大部分隐藏单元对不同输入都是相同反应
模型退化后的train error 和 test error 都很高
解决方案
Vanishing/Exploding Gradient
预训练加微调
Hinton在2006年发表的论文介绍的一种方法
Reducing_the_dimensionality_of_data_with_neural_networks.pdf
Hinton为了解决梯度的问题,提出采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)
梯度剪切、正则
梯度剪切是针对梯度爆炸问题提出的,其思想是:设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,就强制限制在这个范围之内,从而防止梯度爆炸
梯度正则化也是针对梯度爆炸问题提出的,首先了解下范数norm,对于向量α,他的Lp范数为:
可以看常用的三个范数:
- L0范数:向量中非0的元素的个数
- L1范数:向量中各个元素绝对值之和
- L2范数:向量各元素的平方和然后求平方根
在pytorch中,通过优化器的weight_decay参数可以指定权重衰减的策略,如adadelta优化器默认采用的weight_decay就是L2正则化
L2正则在神经网络中的使用,就是在损失函数后面再加上一个正则项:
 是样本大小 ,
是样本大小 ,  是正则项系数(一般取1e-5),系数1/2是为了方便求导后的结果计算;下面开始计算梯度:
是正则项系数(一般取1e-5),系数1/2是为了方便求导后的结果计算;下面开始计算梯度:
w通过BP进行参数更新后得到如下公式:

学习率 一般取1e-3,通过公式可以看到w参数的更新取决于两个部分:
一般取1e-3,通过公式可以看到w参数的更新取决于两个部分:
- 衰减的权重

- 梯度

通过正则化,对w的值进行衰减,从而使w变小,解决梯度爆炸问题
ReLU、LeakReLU、ElU等激活函数替代Sigmoid
以ReLU函数为例,其表达式为:
原图像及导数图像为下图:
可以看到ReLU的导数在正数部分是恒等于1的,因此可以有效的规避梯度消失和梯度爆炸的问题
ReLU的缺点在于:
- 负数部分恒为0,会导致一些神经元无法激活
- 输出不是以0为中心的
LeakReLU函数时为了解决ReLU的第二个缺点,其数学表达式为:max(k∗x,x);其中的k是leak系数,一般选择0.01或者0.02,下图为k取0.2时的图像:
ELU同样是Wie了解决ReLU的第二个缺点,其表达式为:
其原图像以及导数图像为:
ELU相对于LeakReLU函数来说, 计算耗费的时间更长
Batch Normalization
相关介绍论文:Accelerating_Deep_Network_Training_by_Reducing_Internal_Covariate_Shift.pdf
反向传播中,经过每一层的梯度都会乘以该层的权重: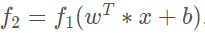
那么在反向传播中,反向求导为:
因此可以看出,x的大小也会影响梯度值,Batch Normalization就是通过对每一层的输出规范为均值和方差一致的方法,消除了x带来的放大缩小的影响,进而解决梯度消失和爆炸的问题
后续深入参见文章:
深度学习:Batch Normalization 学习笔记
残差结构
LSTM
长短期记忆网络:long-short term memory networks
没了解
Degradation
残差结构
残差网络(Deep-Residual-Learning-For-Image-Recognition)
残差结构

两类残差块
左侧残差块用于ResNet-34,右侧残差块用于ResNet-50/101/152
右侧残差块在论文中称为“Deeper Bottleneck Architectures”,分为三个层:
- 1*1卷积,用于降维,减少了计算
- 3*3卷积,用于计算
- 1*1卷积,用于升维,还原维度
两类残差块的代码实现(pytorch):
import torchimport torch.nn as nnimport torch.nn.functional as F# 用于ResNet18和34的残差块,用的是2个3x3的卷积class BasicBlock(nn.Module):expansion = 1def __init__(self, in_planes, planes, stride=1):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3,stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.shortcut = nn.Sequential()# 经过处理后的x要与x的维度相同(尺寸和深度)# 如果不相同,需要添加卷积+BN来变换为同一维度if stride != 1 or in_planes != self.expansion*planes:self.shortcut = nn.Sequential(nn.Conv2d(in_planes, self.expansion*planes,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion*planes))def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x)out = F.relu(out)return out# 用于ResNet50,101和152的残差块,用的是1x1+3x3+1x1的卷积class Bottleneck(nn.Module):# 前面1x1和3x3卷积的filter个数相等,最后1x1卷积是其expansion倍expansion = 4def __init__(self, in_planes, planes, stride=1):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,stride=stride, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.conv3 = nn.Conv2d(planes, self.expansion*planes,kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(self.expansion*planes)self.shortcut = nn.Sequential()if stride != 1 or in_planes != self.expansion*planes:self.shortcut = nn.Sequential(nn.Conv2d(in_planes, self.expansion*planes,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion*planes))def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = F.relu(self.bn2(self.conv2(out)))out = self.bn3(self.conv3(out))out += self.shortcut(x)out = F.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, num_blocks, num_classes=10):super(ResNet, self).__init__()self.in_planes = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=3,stride=1, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(64)self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)self.linear = nn.Linear(512*block.expansion, num_classes)def _make_layer(self, block, planes, num_blocks, stride):strides = [stride] + [1]*(num_blocks-1)layers = []for stride in strides:layers.append(block(self.in_planes, planes, stride))self.in_planes = planes * block.expansionreturn nn.Sequential(*layers)def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = self.layer1(out)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = F.avg_pool2d(out, 4)out = out.view(out.size(0), -1)out = self.linear(out)return outdef ResNet18():return ResNet(BasicBlock, [2,2,2,2])def ResNet34():return ResNet(BasicBlock, [3,4,6,3])def ResNet50():return ResNet(Bottleneck, [3,4,6,3])def ResNet101():return ResNet(Bottleneck, [3,4,23,3])def ResNet152():return ResNet(Bottleneck, [3,8,36,3])def test():net = ResNet18()y = net(torch.randn(1,3,32,32))print(y.size())# test()
残差网络(Identity-Mapping-in-Deep-Residual)
残差概念
残差和误差是非常容易混淆的两个概念:
- 误差是衡量观测值和真实值之间的差距
-
残差块
残差网络是由一系列残差块组成的,残差快结构如下图所示,其中weight在卷积网络中表示卷积操作,addition表示单位加操作:

上图残差块的表示公式为:
残差块分成两个部分: 直接映射:h(xl),对应上图左侧
- 残差:F(xl, wl),对应上图右侧,一般由两个或者三个卷积操作构成
在卷积网络中,Xl可能和X(l+1)的Feature Map数量不一样,这时候就需要使用11的卷积进行升维或者降维,如下图:
这时候,残差块的表达式就变为:
其中,h(xl) = W’l x,其中W’l是11卷积操作(**经验表明,11的卷积对模型性能的提升有限,所以一般在升维或者降维时才会使用**)
该版本的残差块称为resnet_v1,对应的keras代码如下:
def res_block_v1(x, input_filter, output_filter):res_x = Conv2D(kernel_size=(3,3), filters=output_filter, strides=1, padding='same')(x)res_x = BatchNormalization()(res_x)res_x = Activation('relu')(res_x)res_x = Conv2D(kernel_size=(3,3), filters=output_filter, strides=1, padding='same')(res_x)res_x = BatchNormalization()(res_x)if input_filter == output_filter:identity = xelse: #需要升维或者降维identity = Conv2D(kernel_size=(1,1), filters=output_filter, strides=1, padding='same')(x)x = keras.layers.add([identity, res_x])output = Activation('relu')(x)return output
残差网络的搭建
分为两步:
- 使用VGG公式搭建Plain VGG网络
- 在Plain VGG的卷积网络之间插入 Identity Mapping
搭建代码:
def resnet_v1(x):x = Conv2D(kernel_size=(3,3), filters=16, strides=1, padding='same', activation='relu')(x)x = res_block_v1(x, 16, 16)x = res_block_v1(x, 16, 32)x = Flatten()(x)outputs = Dense(10, activation='softmax', kernel_initializer='he_normal')(x)return outputs
残差网络原理
直接映射
残差块的一个更通用的表达方式为:

现在不考虑升维或降维的情况,那么在这里,h(.)是直接映射,f(.)是激活函数,一般采用ReLU;首先,提出两个假设:
- h(.)是直接映射
- f(.)是直接映射
这时候残差块就可以表示为:
对于更深的层L,其与l层的关系可以表示为:
公式6反映了残差网络的两个属性:
- L层可以表示为任意一个比它浅的l层和他们之间的残差部分之和;
 ,L是各个残差块特征的单位累和,MLP是特征矩阵的累积
,L是各个残差块特征的单位累和,MLP是特征矩阵的累积
根据BP的链式求导法则,损失函数 关于xl的梯度可以表示为:
关于xl的梯度可以表示为:
公式7又反映了残差网络的两个属性:
- 在整个训练过程中,
 不可能一直为-1,因此可以说在残差网络中不会出现梯度消失的问题
不可能一直为-1,因此可以说在残差网络中不会出现梯度消失的问题  表示L层的梯度可以直接传递到任何一个比它浅的层
表示L层的梯度可以直接传递到任何一个比它浅的层
最终得出结论:当残差块满足上面两个假设时,信息可以非常畅通的在高层和底层之间相互传导,说明这两个假设是让残差网络可以训练深度模型的充分条件
对于假设1,采用反证法,假设 ,那么这时候,残差块可以表示为:
,那么这时候,残差块可以表示为:
对于更深的L层,表示为:
现在只考虑公式的左半部分 ,损失函数对xl求偏微分得:
,损失函数对xl求偏微分得:
公式10得到两个结论:
- 当
 时,很有可能发生梯度爆炸
时,很有可能发生梯度爆炸 - 当
 时,很有可能发生梯度消失问题
时,很有可能发生梯度消失问题
因此,想要规避梯度消失/爆炸问题,就需要将其值设置为1
而对于其他不影响梯度的h(.),例如LSTM中的门机制(图中c和d)、Dropout(图中f)以及用于升降维的1*1卷积(图中e)也许会有效果:
各模型在CiFar10数据集上的表现如图:
可以看出,直接映射的效果是最好的。从而可以得出结论,假设1成立,即:

激活函数的位置
将最开始的残差块详细展开为下图a,其余几个是在此基础上的变异:
在前述已经得知了“直接映射是最好的选择”,所以这里我们希望构造一种结构能够满足直接映射,即定义一个新的残差结构 ,满足公式:
,满足公式:
该公式反映到网络里即将激活函数移到残差部分去使用,即上图c。这种在卷积之后使用激活函数的方法叫:post-activation,通过调整ReLU和BN的位置得到了几个变种,即d和e,在Cifar10数据集上的实验结构如下图:
实验结果表明:将激活函数移动到残差部分可以提高模型的精度
该网络称为:resnet_v2,keras实现代码如下:
def res_block_v2(x, input_filter, output_filter):res_x = BatchNormalization()(x)res_x = Activation('relu')(res_x)res_x = Conv2D(kernel_size=(3,3), filters=output_filter, strides=1, padding='same')(res_x)res_x = BatchNormalization()(res_x)res_x = Activation('relu')(res_x)res_x = Conv2D(kernel_size=(3,3), filters=output_filter, strides=1, padding='same')(res_x)if input_filter == output_filter:identity = xelse: #需要升维或者降维identity = Conv2D(kernel_size=(1,1), filters=output_filter, strides=1, padding='same')(x)output= keras.layers.add([identity, res_x])return outputdef resnet_v2(x):x = Conv2D(kernel_size=(3,3), filters=16 , strides=1, padding='same', activation='relu')(x)x = res_block_v2(x, 16, 16)x = res_block_v2(x, 16, 32)x = BatchNormalization()(x)y = Flatten()(x)outputs = Dense(10, activation='softmax', kernel_initializer='he_normal')(y)return outputs
代码相关下载
ResNet-50
ResNet-101
ResNet-152
resnet-1k-layers.lua

若有收获,就点个赞吧
0 人点赞
