Gradient-Based Learning Applied to Document Recognition``
论文总结(部分)
传统的模式识别算法把特征提取和特征分类人为分成两个独立的步骤;
实验表明,不去人为分割这款两个步骤,而是建立一个完整的网络去训练效果更好
同时使用了15000、30000、60000数据集进行测试,根据结果提出假设:即使使用LeNet-5这样的专门架构,更多的训练数据也可以提高准确性。为了证明这一假设:通过随机扭曲方式在60000个数据的基础上生成了540000个扭曲数据,当使用畸变数据进行训练时,测试错误率从无畸变时的0.95%下降到0.8%。在没有变形的情况下使用相同的训练参数。训练的总时长保持不变(20次,每次60000个模式)。有趣的是,在这20次测试中,网络只能有效地看到每个样本两次

经验表明,梯度学习似乎并不需要过分担心局部极小解的陷阱。并指出不会轻易陷入局部极小解的一个重要原因,模型的复杂度远远高于实际需要,因此,在高维空间优化模型,可能不会轻易陷入低维空间的局部极小解。举个例子来讲,如果函数 y = f ( x )存在局部极小值,当 x定义域由实数集扩展到复数集后,很可能存在单调下降的路径直通全局最小值,从而绕过实数域上的局部极小值。因此,提升模型复杂度有可能避免过早陷入局部极小解。
LeNet-5模型
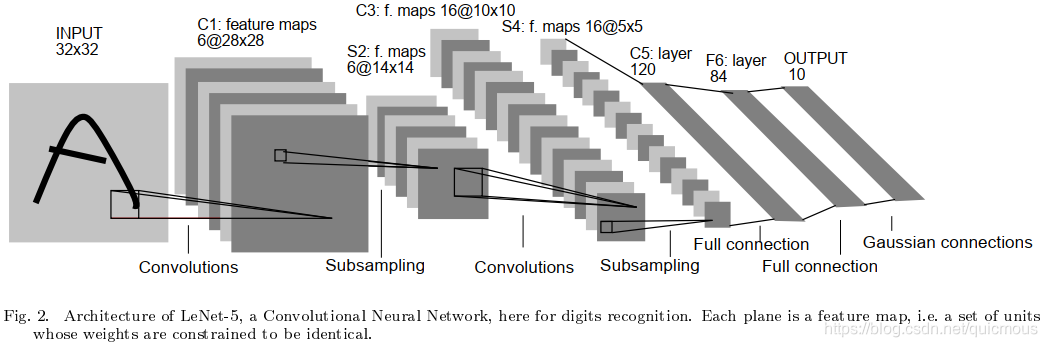
LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
理解卷积和子采样
卷积过程
用一个可训练的滤波器fx去卷积一个输入的图像(第一阶段是输入的图像,后面的阶段就是卷积特征map),然后加一个偏置bx,得到卷积层Cx
子采样过程
邻域四个像素求和变为一个像素,然后通过标量W加权,再增加偏置b,然后通过一个sigmoid激活函数,产生一个缩小四倍的特征映射图Sx+1
各层参数详解
INPUT层(输入层)
C1层(卷积层)
输入图片:32 * 32
卷积核大小:5 * 5
卷积核种类:6
输出feature map大小:28 * 28 (32 - 5 + 1)
神经元数量:28 28 6
可训练参数:(5 5 + 1) 6(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器)
连接数:(55+1)62828=122304
有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
S2层(池化层/下采样层)
输入:28*28
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:6
输出featureMap大小:14*14(28/2)
神经元数量:14146
可训练参数:2*6(和的权+偏置)
连接数:(22+1)61414
共有2x6=12个训练参数,但是有5x14x14x6=5880个连接。
C3层(卷积层)
输入:S2中所有6个或者几个特征map组合
卷积核大小:5*5
卷积核种类:16
输出featureMap大小:10*10 (14-5+1)=10
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合。
可训练参数:6(355+1)+6(455+1)+3(455+1)+1(655+1) (参见S2到C3的不完全卷积层图)
S4层(池化层/下采样层)
输入:10*10
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:16
输出featureMap大小:5*5(10/2)
神经元数量:5516=400
可训练参数:2*16=32(和的权+偏置)
C5层(卷积层)
输入:S4层的全部16个单元特征map(与s4全相连)
卷积核大小:5*5
卷积核种类:120
输出featureMap大小:1*1(5-5+1)
F6层(全连接层)
输入:c5 120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出
输出:84个节点
可训练参数:84*(120+1)=10164
6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164
Output层(全连接层)
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i
采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是: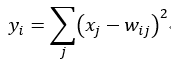
上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接。
S2到C3的不完全卷积层
按照一般的想法,C3应该采用6通道的卷积核;实际上,LeNet-5采用了更灵活的通道配置,防止出现重复的卷积核,提升卷积核的多样性,同时减少卷积核的参数数量;这种不对称的组合连接的方式也有利于提取多种组合特征。
C3图层是一个卷积图层,有16个要素图。每个要素地图中的每个单元都连接到S2要素地图子集内相同位置的几个5x5邻域。表1显示了由每个C3要素图组合的一组S2要素图。为什么不将每个S2要素地图与每个C3要素地图连接起来呢?原因有两个。首先,非完全连接方案将连接数保持在合理的范围内。更重要的是,它迫使网络打破对称。不同的特征映射被迫提取不同的(希望是互补的)特征,因为它们得到不同的输入集。表1中连接方案的基本原理如下。前六个C3要素地图从S2三个要素地图的每个相邻子集获取输入。接下来的六个从四个连续子集中获取输入。接下来的三个从不连续的四个子集获取输入。最后一个从所有S2要素地图中获取输入。图层C3有1516个可训练参数和151600个连接。

卷积神经网络CNN
模型结构图
四个部分:
- 输入层:Input Layer
- 卷积层:Convolutional Layer
- 池化层:Pooling Layer
- 输出层:(全连接层 + Softmax Layer)

卷积
使用卷积层(Convolutional Layers)的神经网络,基于卷积的数学运算;
卷积层由一组滤波器组成,滤波器可以看成是一个二维数字矩,如下是一个33的滤波器(索伯滤波器):
其卷积操作用处:用输出图像中更亮的像素表示原始图像中存在的边缘;
索伯滤波器是边缘检测器,使用索伯滤波器来处理下图得到的结果如右图:
通常,卷积有助于我们找到特定的局部图像特征(如边缘),用在后面的网络中;例如手写数字分类问题,比如发现数字1,可以通过使用边缘检测发现图像上两个突出的垂直边缘;
卷积运算分为三种:full卷积、same卷积和valid卷积;这三种运算的不同点在于:对*卷积核移动范围的不同限制。
full卷积
从filter和image刚相交开始做卷积,不足的部分设0。例如:滑动步长为1,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:(N1+N2-1) x (N1+N2-1)。运动范围如图所示:
same卷积
same模式是最常见的模式,是指经过卷积的特征图和原图的size保持不变;但是也不代表完全不变,跟卷积核的step也有一定的关系,通常step为1:如下图:滑动步长为1,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:N1xN1 
same卷积位置计算表:
valid卷积
当filter全部在image里面的时候,进行卷积运算,例如:滑动步长为S,图片大小为N1xN1,卷积核大小为N2xN2,卷积后图像大小:(N1-N2)/S+1 x (N1-N2)/S+1,运动范围如图所示:
填充
使用33的滤波器处理44的图像,最终会输出一个22的图像(4-3+1)
通常,我们希望输出图像与输入图像的大小相同。因此需要在图像周围添加零,让我们可以在更多位置叠加过滤器。3x3滤波器需要在边缘多填充1个像素。*这种方式称为“相同填充”,因为输入和输出具有相同的大小。而不使用任何填充称为“有效”填充
池化
池化操作是对卷积得到的结果进行进一步的处理;
图像中的相邻像素倾向于具有相似的值,因此通常卷积层相邻的输出像素也具有相似的值。这意味着,卷积层输出中包含的大部分信息都是冗余的;
如果我们使用边缘检测滤波器并在某个位置找到强边缘,那么我们也可能会在距离这个像素1个偏移的位置找到相对较强的边缘。但是它们都一样是边缘,我们并没有找到任何新东西
池化层解决了这个问题,这个网络层所做的就是通过减小输入的大小降低输出值的数量
池化一般通过简单的最大值、平均值或者随机值操作完成,通常常用的就是最大值池化和平均值池化,下面主要介绍这两个池化;
same最大值池化
4行4列的张量x和2行3列的掩码,原始数据如下:
进行step为1的same最大值池化详细过程如下:

same平均值池化
valid最大值池化
4行4列的张量x和2行3列的掩码,原始数据如下:
进行step为1的valid最大值池化详细过程如下:
valid平均值池化
same池化和valid池化的区别
不同之处在于same池化的掩码可能会再张量外移动的情况,而valid池化的掩码只会在张量内进行移动;
参考博客
Gradient-Base Learning Applied to Document Recognition
LeNet-5的深入解析
Jack Cui - LeNet-5详解
知乎 - 如何理解卷积神经网络(CNN)中的卷积和池化?
三种卷积运算的介绍
两种池化运算的介绍

若有收获,就点个赞吧
0 人点赞
