并发
控制
- 系统变量 max_connections 设置并发连接数
- 国外通常设置在最大300
-
监控
系统变量Connections用于监控曾经试图连接实例的连接数,不管是否密码正确
- 系统变量Max_used_connections用于监控曾经达到过的最大并发连接数 ```sql show global status like ‘connections’; show global status like ‘Threads_connected’; # 实时连接数 show global status like ‘Threads_running’; # 真正执行的线程数,running/block的状态,sleep的不算 show variables like ‘innodb_thread_concurrency’; # 真正并发数,最大128,0表示不限制 select * from information_schema.innodb_lock_waits; #查看锁等待
<a name="iXeoW"></a>## 内存池化- ptmalloc 默认的,效率比较低- tcmalloc- jemalloc<a name="vFYGs"></a>## innodbBufferPool原理- 存储引擎内存模型之缓冲池- 在LRU中设置了midpoint,默认情况下数据插入在LRU列表的5/8处,可以由参数innodb_old_blocks_pct控制,默认为37- midpoint之前称之为new sublist(young)热点数据,之后称之为old sublist(old)- 防止SQL语句将热点数据刷出LRU链表,造成再次访问磁盘- 为了再次防止数据被刷出,设置参数innodb_old_blocks_time,表示页读取到mid后需要等待多久才会被加入到热端,单位ms<a name="S9Wkl"></a>## innodbBufferPool监控```sqlshow engine innodb status \G;
flush list(脏数据的页) 和 database pages 一样长时容易引起mysql hang住,数据库不能读写
redo日志监控
redo日志落盘通过log thread专门进行
- 脏数据落盘,redo日志要落盘
- commit后,redo日志要落盘
- 每秒落盘
- redo日志达到1/2空间时落盘
- 设置
- show variables like ‘innodb_log_file%’
- innodb_log_file_size 推荐1G
- innodb_log_files_in_group 推荐4
- 如果4个log_file都写满了,要重新覆盖第一个日志文件,如果日志文件里都是脏数据,即不能被覆盖,就会引起mysql hang住,此时数据库只能读,不能写
监控 show engine innodb status \G; LOG下的 LSN - LCA(LastCheckpointAt)要小于redo日志总和,否则就是上面的hang住,两个的差值就是 checkpointAge
终极性能问题
io性能
show variables like 'innodb_io_capacity'; // 一定要修改为磁盘实际IO能力,机械硬盘2000-5000,SSD20000-30000
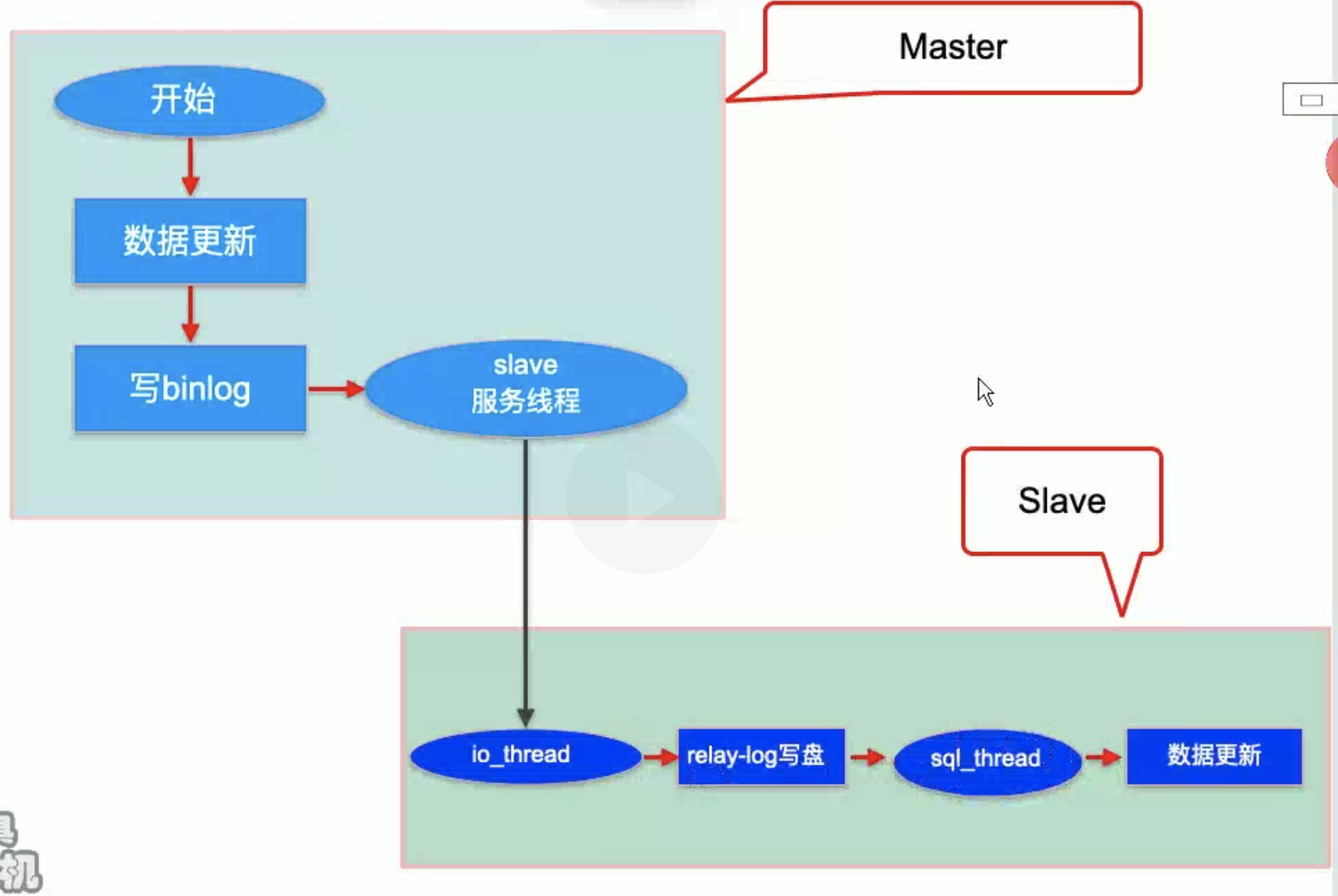
主从复制
主库复制
MySQLReplication问题
- 主库写完数据直接返回应用层
- 如果此时主库宕机,从库切换为主库,之前的提交可能还没有同步过来,造成数据不一致
- MySQLSemisyncReplication
- 半同步
- 从库enqueue后主库才返回应用层成功
- 不做到slave commit之后是为了保证性能
- 一般一主三从,其中一个从库配置半同步即可 ```sql show plugins; INSTALL PLUGIN rpl semi_sync_master SONAME ‘semisync_master.so’; // 主库插件, INSTALL PLUGIN rpl semi_sync_slave SONAME ‘semisync_slave.so’; // 从库插件,为了主库切换为从库时使用 show plugins;
show variables like ‘%semi%’;
SET global rpl_semi_sync_master_wait_point=”AFTER_SYNC”; // 等待点默认要如此设置
SET global rpl_semi_sync_master_enabled=1; // 只在主库开启
SET global rpl_semi_sync_slave_enabled=1; // 只在从库开启 stop slave io_thread; start slave io_thread;
show variables like ‘%semi%’;
- MySQLGroupReplication- MGR<a name="a84UX"></a>## 并行复制- 其中最关键的就是master开始后的数据更新是多线程并发的, 而slave的sql_thread应用时是单线程的- 解决方案就是mysql官方的并行复制```sql// masterbinlog_order_commits(以队列顺序提交)// slaveslave-parallel-type=LOGICAL_CLOCK(同一个逻辑时钟内的事务可以并行复制)slave-parallel-workers=16slave_pending_jobs_size_max=2147483648 (队列中pending事件所占用的最大内存,默认16M)slave_preserve_commit_order=1(以队列顺序提交)

若有收获,就点个赞吧
0 人点赞
