索引
目的

有序数组
- 按某个字段顺序递增
- 优势
- 支持范围检索
- 不足
- 对修改不友好, 如果在中间进行插入,后面的所有位置都需要移动
- 适用于静态存储引擎,比如要保存2019年话费记录

二叉搜索树
- 每个节点的左儿子小于父节点,父节点又小于右儿子
- 优势
- 查询成本可控,最大为树高
- 不足
- 查询成本都被平均了,导致整体比较慢,如果树高比较高,查询速度就慢

N叉搜索树
- N叉中的N取决于数据块的大小,是改良的二叉搜索树
- 也叫B+树,平衡树
- 每一个索引在InnoDB里面对应一棵B+树
- InnoDB的一个整数字段索引为例,这个N差不多为1200,当树高为4时就可以存储1200的3次方即17亿个值
- 由于树根的数据块总是在内存中,第二层也有很大概率在内存,所以只需要最多3次IO就可以拿到数据

引擎对比
- InnoDB
- 主键索引的叶子中不存指针,而是直接存储数据
- 辅助键索引叶子上存储对应的主键ID,通过辅助键索引查询时需要回表走主键索引
- 表即主键,主键即表
- 支持行锁和事务
- MyISAM
- 主键索引和辅助键索引查询速度一致

索引分类
- 主键索引
- 也称聚簇索引
- cluster index
- 辅助索引
- 也称二级索引
- secondary index
- PK和UK都会触发引擎创建默认索引
- 普通索引比唯一索引多做了一次内存搜索和判断,性能相差微乎其微,但对唯一索引的修改不会走ChangeBuffer会导致更新操作性能下降
- 前缀索引

索引维护
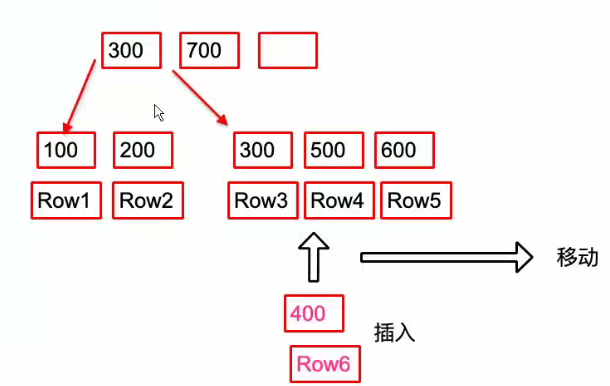
- 为了维护索引的有序性,在插入新值时需要必要的维护
- 如果要插入的值影响了后面的值向后移动,如果数据页满导致产生2个数据页就是页分裂,导致性能下降
-
优化方案
自增主键
- 为了避免页分裂,开发规范上要求建表时必须要加一个自增主键列 NOT NULL PRIMARY KEY AUTO_INCREMENT
- 因为在辅助索引上也会存储主键ID,所以尽量把主键用比较小的数据结构存储,整型4字节,长整8字节
- 索引覆盖
- 要查询的字段尽量都有索引,避免回表
- 尽量少些select * ,需要哪些字段查询哪些字段,索引哪些字段
- 必要时可以联合索引
- 最左前缀
- 联合索引实际是把两个字段拼起来形成一个字符串,然后按此排序
- 所以如果要走联合索引的搜索,必须要从左到右依次命中,如果左边的无法命中则不能走联合索引
索引下推
-
ChangeBuffer
对非唯一字段的修改可以直接在ChangeBuffer中进行,减少IO操作
- 修改操作是日志先行,防止突然崩溃
- ChangeBuffer存入磁盘的条件
- 达到max_size
- 数据库关闭shutdown时
- ChangeBuffer优化器会做merge
- 对唯一字段的修改为了防止冲突不走ChangeBuffer
- show variables like ‘%change_buffer%’;
explain select * from cityex; // 查看执行计划
select name from t3 where card_id=4 union select name from t3 where card_id >= 5; // 会去重 select name from t3 where card_id=4 union all select name from t3 where card_id >= 5; // 不会去重
select CountryCode,sum(Population) from City group by CountryCode; // 分组查询默认用临时表和排序 select CountryCode,sum(Population) from City group by CountryCode order by null; // 去掉执行计划里的filesort // 如果给CountryCode加上索引,也会去掉执行计划里的临时表,但会回表查询Population // 如果给CountryCode和Population加上联合索引,不仅去掉执行计划里的临时表,也会直接使用索引查询,不用回表
create table t1 like t2; // 只拷贝t2的表结构创建t1表,包括索引等 create table t1 as select * from t2; // 只拷贝t2的表数据到t1表,没有对应的索引等
<a name="nti7p"></a>## 事务可重读```sql// session1select count(*) from t3; // 6begin;delete from t3 where id=6;commit;select count(*) from t3; // 5// session2select count(*) from t3; // 6begin;select count(*) from t3; // begin开始时count是多少,不管是否被其他线程删除了行数,在commit之前都不变
秒杀计数
- redis方案始终存在时间差导致数据不一致问题
- 可以使用一个一致性表来保存计数,只有一行记录即数量

count()性能
- count(主键ID):引擎会遍历整张表,把每一行的ID都取出来,返回给server层,server拿到ID后去空后累加
- count(1):引擎会遍历整张表,但不取值,server层对于每行进行累加
- count(字段): 如果字段可以null,则取值后去空累加,如果not null,读取每一行累加
- count(*):引擎专门做了优化,也不取值,server层对于每行累加
结论:
公司规范不推荐使用join,需要的话要在应用程序中做,不要在数据库中做
- 大小不同的两个表,要用小表做驱动表以减小时间复杂度,即要做全表扫描的表,在执行计划中的第一个
- 通常驱动表是由MySQL的统计信息自动选择的,如果非要人为指定需要使用 straight_join指定驱动表 ```sql select from t1,t2 where t1.a=t2.a; // 两者等价 select from t1 join t2 on t1.a=t2.a;
select * from t2 straight_join t1 on t1.a=t2.a;
<a name="KqIm3"></a>
## 优化
- 驱动表只能做全表扫描,所以要用小表
- 被驱动表要做检索,所以要对检索的字段加索引
- 小表选择
- 如果两个表中的连接项的字段中只有一个有索引,那么他就做被驱动表,没有索引的做驱动表
- 如果两个字段都有索引,那么行数少的做驱动表
- 小表的选择也要考虑filtered的行数,如果行数一致也要考虑列数,列数少的是小表
<a name="493WA"></a>
## 算法
- INLJ(Index NestedLoopJoin)索引嵌套循环连接,即被驱动表对应的字段有索引
- SNLJ(Simple NestedLoopJoin)被驱动表没有对应字段的索引,被驱动表也做了全表扫描,效率最低
- BNL(BlockNestedLoop)在执行计划中表示Usinig join buffer
- 把驱动表放入join buffer中,在内存中计算
- 如果驱动表比join buffer大,一次放不下,需要分块计算,形成BNL
- 也意味着两个表中连接字段都没有索引
<a name="nQfQY"></a>
## 多表连接
- 尽量减少多表连接
- 多表连接优化原则
- 尽量使用BKA算法
- 整体思路就是尽量让每次参与join的驱动表的RS越小越好
<a name="xgUHo"></a>
## 外连接
<a name="rrzyT"></a>
### 左外连接
```sql
select * from a left join b on (a.f1 = b.f1) and (a.f2 = b.f2); // 左边的a表列全部显示在左边,右边和左边相等的先显示,不相等的显示为NULL
右外连接
select * from a right join b on (a.f1 = b.f1) and (a.f2 = b.f2); // 右边的b表列全部显示,右边和左边相等的先显示,不相等的显示为NULL
执行计划
UsingWhere
- 表示在内存中进行过滤
-
filtered
表示执行计划中rows行的过滤百分比
- 有索引的列的估值是准确的
没有索引的列,在UsingWhere时,当是等值查询时返回固定值10,当是范围查询时返回固定值33.33
应急预案
短连接风暴
短连接
- 连接到数据库后,执行很少的SQL语句就断开,下次需要再建连接
- 风险:一旦数据库处理的慢一些,连接数就暴涨
- 连接池
- 长连接提供复用
- 短连接风暴就发生在连接池中的连接都被占用后又有新的连接请求,这时的连接都是短连接
解决方案
- 下策
- 调大max_connections
- show variables like ‘%max_connections%’
- set global max_connections=200
- 处理掉占着连接但不工作的线程
- show processlist; 显示处理的线程
- select * from information_schema.innodb_trx\G; 显示处理的事务
- kill
; 显示的连接ID并且不在事务中的ID
- 线程设置wait_timeout参数
- show variables like ‘%wait_timeout%’;
- 可以设置在10min中内
- 跳过用户名密码验证
- 下策
紧急创建索引
- 从库先加索引
- 生效后主从切换
- query rewrite
- 改写线上业务写的sql
- 安装 mysql -uuser -ppass < mysql/share/install_rewriter.sql
- show variables like ‘rewriter_enabled’;
- 在query_rewrite库中的rewrite_rules表中增加自己的改写sql行记录
- CALL query_rewrite.flush_rewrite_rules();
- 如何事前避免慢查询
- 上线前,long_query_time=0; 开启慢查询
- 回归测试
- 找出慢查询日志中Rows_examined字段异常的语句进行整改

QPS激增
- 原因
- 应用程序bug
- 业务bug
解决方案
全局锁
- 只有一条语句会加全局锁FTWRL
- flush tables with read lock;unlock tables;
- 之后数据库处于只读状态,所有更新语句被阻塞,commit和rollback也被阻塞
- 早期实现全库数据备份的命令,目前不推荐使用
- 表级锁
- 表锁
- 读锁 lock table TableName read; unlock tables;
- 写锁 lock table TableName write; unlock tables;
- 老的引擎为了做事务而做的语法,目前不推荐使用
- MDL元数据锁
- 目的:保证读写的正确性
- 特点:不需要显示使用,在访问一个表的时候会被自动加上
- 分类:
- MDL读锁:增、删、改、查,读锁是共享锁
- MDL写锁:对表结构做变更,写锁是互斥锁,一旦有了写锁后,后面的锁都被阻塞,为了防止大量堵塞,可以给ALTER语句加上 NOWAIT 或 WAIT N 超时
- 表锁
-
读写分类
对数据进行增删改查时要对表加读锁(共享锁),防止对表结构进行修改,所有线程都只能读不能改
对表结构进行变更时要对表加写锁(独占锁),加上了写锁也会阻塞所有的增删改查,只有当前线程可读写
排序优化
排序原理
磁盘中数据读取到内存
- 内存中数据在sortBuffer中排序成块
-
优化
order by 后面的字段要有索引
- select 的字段要有索引
-
统计信息
方式
采样统计
- 默认会选择N个数据页,统计这些页上的不同值,得到一个平均值,然后成一这个索引的页面数,得到索引的基数
- 当变更的数据行数超过 1 / M 时,会触发重新做一次索引统计
手动收集
innodb_stats_persistent
- on
- 表示统计信息会持久化存储
- N=20,M=10
- off
- 表示统计信息只会存储在内存
- N=8,M=16
- on
- show variables like ‘innodb_stats_persistent’;

若有收获,就点个赞吧
0 人点赞
