概述
- 分布式协调服务开源框架
- 解决分布式集群中应用系统一致性问题
-
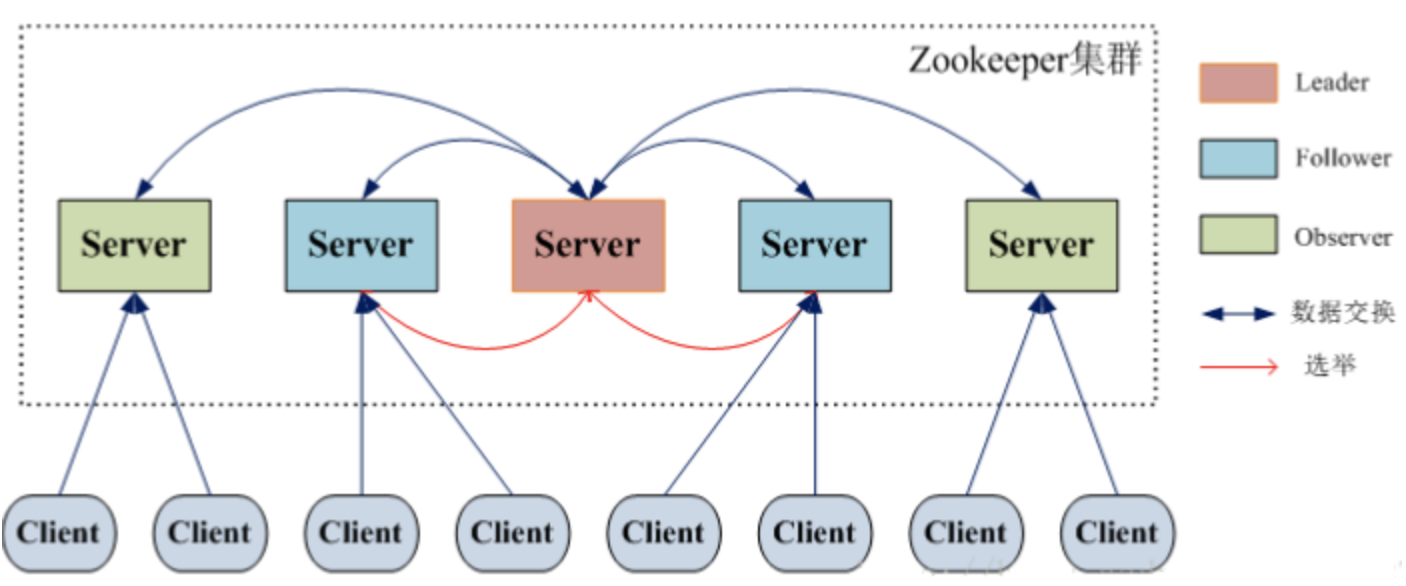
架构图
Leader
- 集群的核心,事务请求的唯一调度和处理者
- 事务的写操作都统一由leader处理,leader决定顺序、执行的动作
- Follower
- 跟随者角色,同步leader状态
- 非事务请求可以独立处理,事务请求转发给leader
- 参与leader选举投票
- Observer
- 观察者角色,观察集群最新状态,并同步到本地
- 非事务请求可以独立处理,事务请求转发给leader
- 不参与选举投票
特性
- 全局数据一致性,任意节点在任意时间看到的数据都是一致的
- 可靠性
- 顺序性
原子性,数据要么全部更新成功,要么全部更新失败,不存在中间状态
分布式系统优势
可靠性,单个或几个系统的故障不会影响整体服务
-
应用场景
命名服务
- 配置管理
-
基础
层次命名空间
zookeeper的节点称为znode
- 每个znode用/分割
znode兼具目录和文件的特性
持久节点
- 创建该特定znode的客户端断开连接后,此znode依然存在
- 默认就是持久节点
- 临时节点
- 客户端断开连接后会自动删除
- 不允许有子节点
顺序节点
监视
- 客户端收到服务器集群的更改通知
- 客户端读取特定的znode时设置watches,znode有任何更改时都会通知客户端
- 更改通知只会触发1次
会话
LOOKING:寻找leader的状态,需要进入选举流程
- LEADING:领导者状态
- FOLLOWING:跟随者状态,leader已经选举出来
-
事务ID
zk在状态变更时都接收一个ZXID
- ZXID是一个64位的数字
-
选举
保证分布式数据一致性的关键就是leader 的选举
- 集群启动时初选举
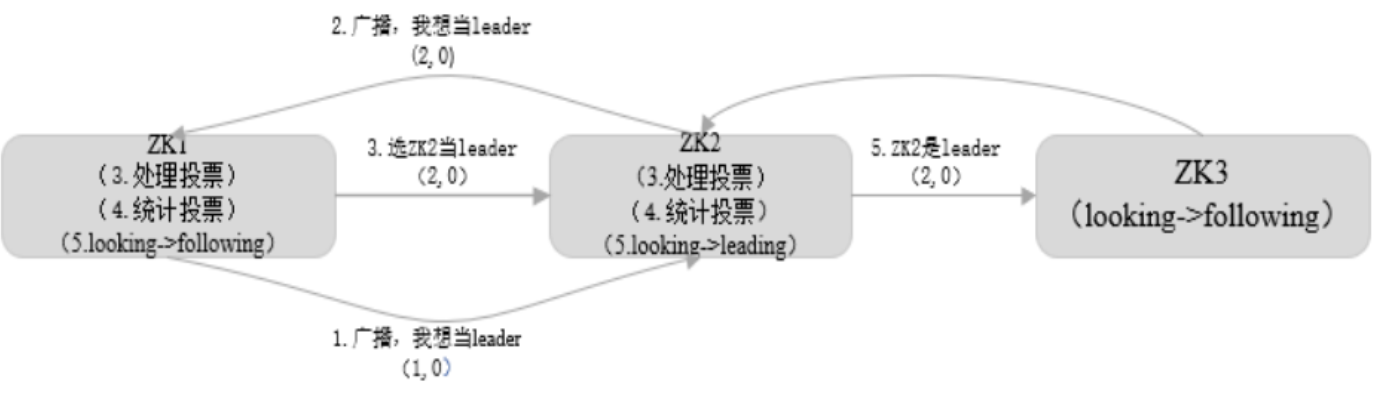
- 在集群初始化阶段,当有一台服务器 ZK1 启动时,其单独无法进行和完成 Leader 选举
- 当第二台服务器 ZK2 启动时,此时两台机器可以相互通信,每台机器都试图找到 Leader,于是进入 Leader 选举过程。选举过程开始,过程如下:
- 每个Server发出一个投票。由于是初始情况,ZK1 和 ZK2 都会将自己作为 Leader 服务器来进行投票,每次投票会包含所推举的服务器的 myid 和 ZXID,使用(myid, ZXID)来表示,此时 ZK1 的投票为(1, 0),ZK2 的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
- 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自 LOOKING 状态的服务器。
- 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行比较,规则如下:
- 优先检查 ZXID。ZXID 比较大的服务器优先作为 Leader。
- 如果 ZXID 相同,那么就比较 myid。myid 较大的服务器作为Leader服务器。
- 对于 ZK1 而言,它的投票是(1, 0),接收 ZK2 的投票为(2, 0),首先会比较两者的 ZXID,均为 0,再比较 myid,此时 ZK2 的 myid 最大,于是 ZK2 胜。ZK1 更新自己的投票为(2, 0),并将投票重新发送给 ZK2。
- 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于 ZK1、ZK2 而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出 ZK2 作为Leader。
- 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为 FOLLOWING,如果是 Leader,就变更为 LEADING
- 当新的 Zookeeper 节点 ZK3 启动时,发现已经有 Leader 了,不再选举,直接将直接的状态从 LOOKING 改为 FOLLOWING。
- 集群运行中重选举

- 在 Zookeeper 运行期间,如果 Leader 节点挂了,那么整个 Zookeeper 集群将暂停对外服务,进入新一轮Leader选举。
- 假设正在运行的有 ZK1、ZK2、ZK3 三台服务器,当前 Leader 是 ZK2,若某一时刻 Leader 挂了,此时便开始 Leader 选举。选举过程如下所示
- 变更状态。Leader 挂后,余下的非 Observer 服务器都会讲自己的服务器状态变更为 LOOKING,然后开始进入 Leader 选举过程。
- 每个Server会发出一个投票。在运行期间,每个服务器上的 ZXID 可能不同,此时假定 ZK1 的 ZXID 为 124,ZK3 的 ZXID 为 123;在第一轮投票中,ZK1 和 ZK3 都会投自己,产生投票(1, 124),(3, 123),然后各自将投票发送给集群中所有机器。
- 接收来自各个服务器的投票。与启动时过程相同。
- 处理投票。与启动时过程相同,由于 ZK1 事务 ID 大,ZK1 将会成为 Leader。
- 统计投票。与启动时过程相同。
- 改变服务器的状态。与启动时过程相同。
试用
安装
```shell ➜ ~ java -version openjdk version “1.8.0_252” OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_252-b09) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.252-b09, mixed mode)
➜ apache-zookeeper-3.6.2-bin mkdir data ➜ apache-zookeeper-3.6.2-bin pwd /Users/prief/Desktop/java/zk/apache-zookeeper-3.6.2-bin
➜ apache-zookeeper-3.6.2-bin vi conf/zoo.cfg ➜ apache-zookeeper-3.6.2-bin cat conf/zoo.cfg tickTime = 2000 dataDir = /Users/prief/Desktop/java/zk/apache-zookeeper-3.6.2-bin/data clientPort = 2181 initLimit = 5 syncLimit = 2
➜ apache-zookeeper-3.6.2-bin bin/zkServer.sh start /usr/bin/java ZooKeeper JMX enabled by default Using config: /Users/prief/Desktop/java/zk/apache-zookeeper-3.6.2-bin/bin/../conf/zoo.cfg Starting zookeeper … STARTED
➜ apache-zookeeper-3.6.2-bin bin/zkServer.sh stop /usr/bin/java ZooKeeper JMX enabled by default Using config: /Users/prief/Desktop/java/zk/apache-zookeeper-3.6.2-bin/bin/../conf/zoo.cfg Stopping zookeeper … STOPPED
<a name="SIvE2"></a>## CLI- 创建znode- -s 顺序节点- -e 临时节点,连接断开临时节点自动删除- 默认持久节点- 获取数据- 监视znode变化- 设置数据- 创建znode子节点- 列出znode子节点- 检查状态- 移除/删除znode```shell➜ apache-zookeeper-3.6.2-bin bin/zkCli.sh/usr/bin/javaConnecting to localhost:2181................................................Welcome to ZooKeeper!................................WATCHER::WatchedEvent state:SyncConnected type: None path:null[zk: localhost:2181(CONNECTED) 0]create [-s] [-e] [-c] [-t ttl] path [data] [acl] 如果没有数据默认nullget [-s] [-w] path 监视/path数据变更set [-s] [-v version] path datals [-s] [-w] [-R] pathstat [-w] path 返回path元数据,包含时间戳、版本、ACL、数据长度、子节点等delete [-v version] pathdeleteall path [-b batch size]

若有收获,就点个赞吧
0 人点赞
