浅谈容器网络
网络栈
- 容器能看到的网络栈实际是被隔离在自己的NetworkNamespace当中
- 网络栈要素,构成了进程发起和响应网络请求的基本环境
- 网卡 NetworkInterface
- 回环设备 LoopbackDevice
- 路由表 RoutingTable
- 防火墙 iptables
- 容器可以直接使用宿主机的网络栈(-net=host),不开启NetworkNamespace,性能好但可能引起资源冲突,比如端口被占用
- 大多数情况容器都希望使用自己的NetworkNamespace的网络栈即拥有自己的IP地址和端口 ```shell
$ docker run –d –net=host —name nginx-host nginx
<a name="svAU2"></a>## 网络互通- 实现两台主机之间的通信,最直接的办法就是用一根网线连接起来- 实现多台主机之间的通信,需要用网线连接在一台交换机上- Linux中起到虚拟交换机作用的网络设备就是网桥Bridge- Bridge是一个工作在数据链路层DataLink上的设备,主要功能是根据MAC地址学习来将数据包转发到网桥的不同端口上- docker项目会默认在宿主机上创建一个docker0的网桥,凡是连接到docker0网桥的容器都可以相互通信<a name="qFBIG"></a>## VethPair- 容器连接到docker0网桥的虚拟设备- 特点- 被创建出来后,总是以两张虚拟网卡VethPeer形式成对出现- 从其中一个网卡发出的数据包,可以直接出现在对应的另一张网卡上- 哪怕这两个网卡出现在不同的NetworkNamespace- 有以上特点所以VethPair常常被用作连接不同NetworkNamespace的“网线”- 通常容器里的eth0和宿主机上的vethXXX就是一对VethPair- 宿主机上的vehtXXX都被插到宿主机的docker0网桥上,所以同一个宿主机里的容器默认就网络互通```shell$ docker run –d --name nginx-1 nginx# 在宿主机上$ docker exec -it nginx-1 /bin/bash# 在容器里root@2b3c181aecf1:/# ifconfigeth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 172.17.0.2 netmask 255.255.0.0 broadcast 0.0.0.0inet6 fe80::42:acff:fe11:2 prefixlen 64 scopeid 0x20<link>ether 02:42:ac:11:00:02 txqueuelen 0 (Ethernet)RX packets 364 bytes 8137175 (7.7 MiB)RX errors 0 dropped 0 overruns 0 frame 0TX packets 281 bytes 21161 (20.6 KiB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536inet 127.0.0.1 netmask 255.0.0.0inet6 ::1 prefixlen 128 scopeid 0x10<host>loop txqueuelen 1000 (Local Loopback)RX packets 0 bytes 0 (0.0 B)RX errors 0 dropped 0 overruns 0 frame 0TX packets 0 bytes 0 (0.0 B)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0$ routeKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Ifacedefault 172.17.0.1 0.0.0.0 UG 0 0 0 eth0172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0# 在宿主机上$ ifconfig...docker0 Link encap:Ethernet HWaddr 02:42:d8:e4:df:c1inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0inet6 addr: fe80::42:d8ff:fee4:dfc1/64 Scope:LinkUP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1RX packets:309 errors:0 dropped:0 overruns:0 frame:0TX packets:372 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:0RX bytes:18944 (18.9 KB) TX bytes:8137789 (8.1 MB)veth9c02e56 Link encap:Ethernet HWaddr 52:81:0b:24:3d:dainet6 addr: fe80::5081:bff:fe24:3dda/64 Scope:LinkUP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1RX packets:288 errors:0 dropped:0 overruns:0 frame:0TX packets:371 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:0RX bytes:21608 (21.6 KB) TX bytes:8137719 (8.1 MB)$ brctl showbridge name bridge id STP enabled interfacesdocker0 8000.0242d8e4dfc1 no veth9c02e56$ docker run –d --name nginx-2 nginx$ brctl showbridge name bridge id STP enabled interfacesdocker0 8000.0242d8e4dfc1 no veth9c02e56vethb4963f3
- 同一个宿主机上不同容器nginx-1中访问nginx-2容器网络的流程
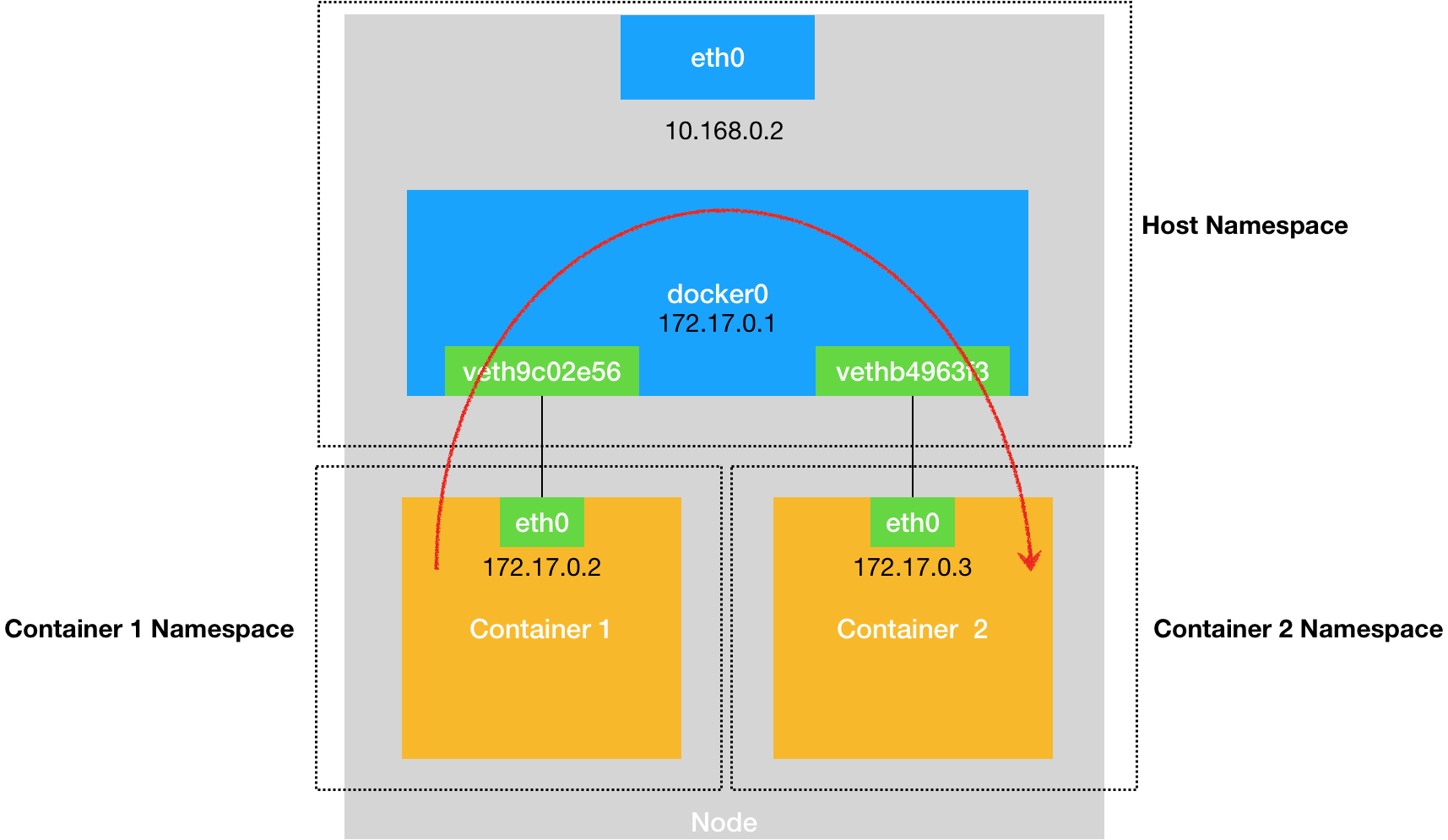
- ping 172.17.0.3
- 发现目标IP匹配到第二条路由规则
- 第二条路由规则的网关是0.0.0.0表示是一条直联规则,不用走网关,直接从eth0网卡出去通过二层网络发往目的主机
- 走二层网络就需要目的主机的MAC地址,所以nginx-1容器发起ARP请求来获得目的主机的MAC
- nginx-1容器里的VethPair的一端发起请求,另一端被连在宿主机的docker0网桥上
- 虚拟网卡连在网桥上就会被剥夺调用网络栈处理数据包的资格,从而降级成为一个端口
- 而这个端口的唯一作用就是接收流入的数据包然后全权交给docker0网桥
- docker0网桥扮演二层交换机的角色,把ARP请求转发到其他虚拟网卡上
- 这样同样插在docker0网桥的nginx-2的容器就收到了这个请求并响应给nginx-1
- nginx-1拿到响应的MAC地址后就可以把数据包发送出去
- 数据包直接出现在对应的另一端,同时也转给docker0网桥
- docker0网桥通过学习过来的CAM表(通过MAC地址学习维护的端口和MAC地址的对应表)里查到对应的端口为nginx-2对应的VethPair的一端,然后直接发往这个端口
- nginx-2容器里的一端也就收到了这个数据包
- 可以打开iptables的TRACE功能查看数据包的传输过程 ```shell
在宿主机上执行
$ iptables -t raw -A OUTPUT -p icmp -j TRACE $ iptables -t raw -A PREROUTING -p icmp -j TRACE
$ tail -f /var/log/syslog #查看数据包传输
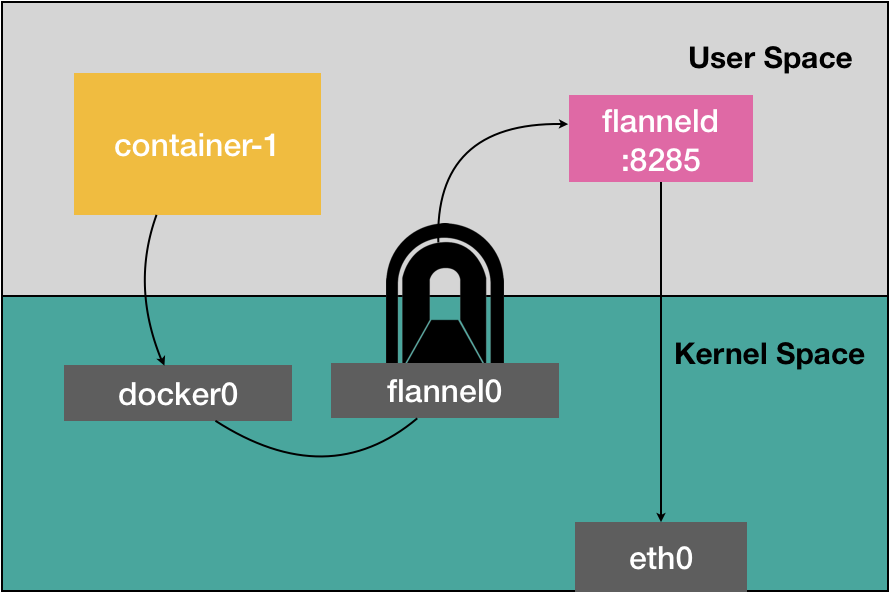
<a name="dHgsn"></a>## 容器网络原理<a name="t63eo"></a>### 同一宿主机容器间通信- 默认情况下,被限制在NetworkNamespace里的容器进程,实际是通过VethPair设备+宿主机网桥的方式实现了容器间的通信<a name="mxG0G"></a>### 宿主机访问容器- 在宿主机上访问容器里的网络时也是根据路由规则到达docker0网桥后被转发进容器的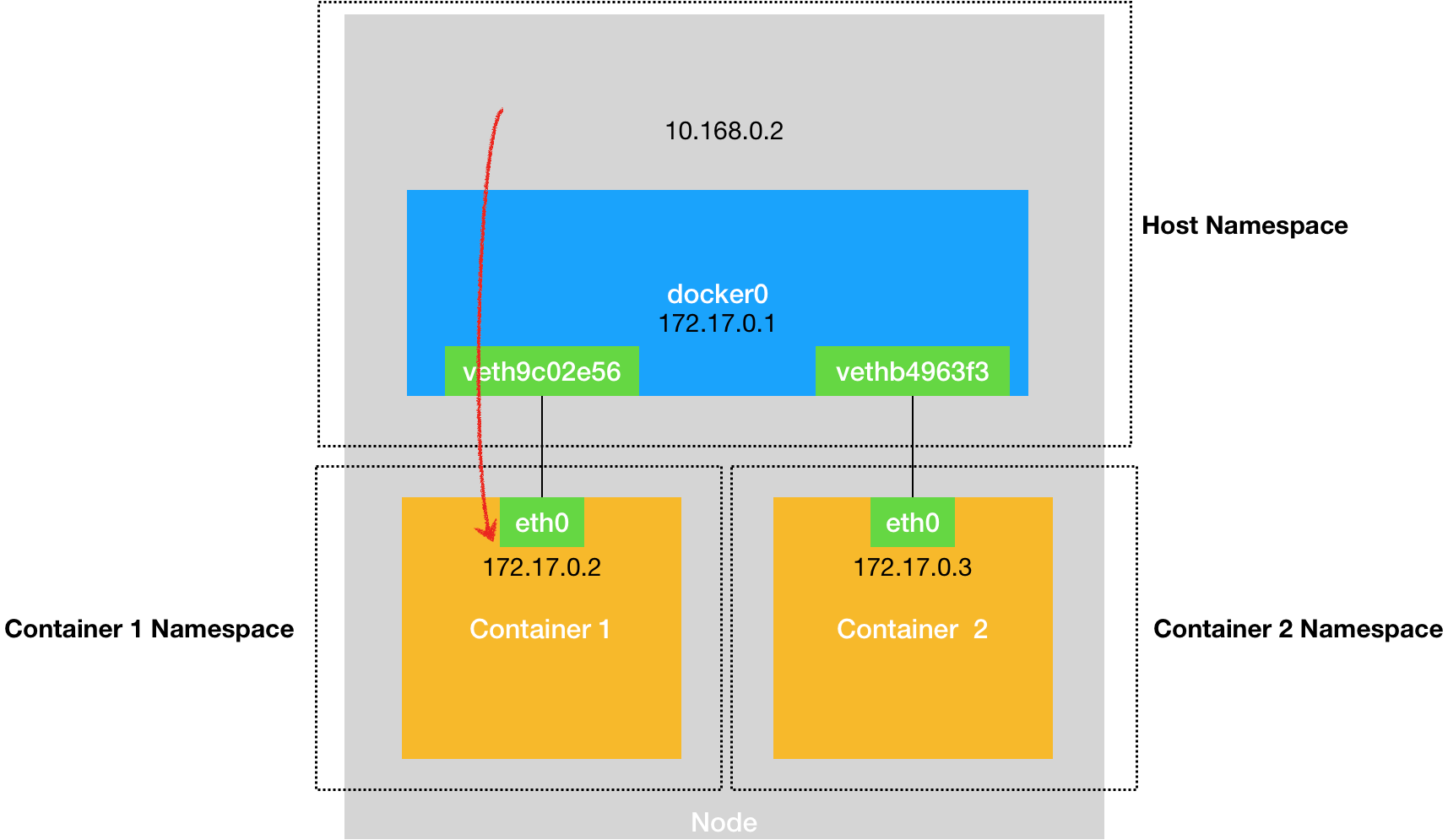<a name="PEPWI"></a>### 容器访问另一个宿主机- 当容器试图访问另一个宿主机时,数据包也经过docker0网桥出现在宿主机上然后根据宿主机的路由规则(10.168.0.0/24 via eth0)对另一个宿主机的访问就交由当前宿主机的eth0网卡处理<a name="v4vU8"></a>### 容器访问另一个宿主机上的容器- 容器访问另一个宿主机上的容器时,默认情况下两个宿主机上的docker0网桥没有任何联系,所以默认情况下跨主的容器不能通信,但可以在整个集群中创建一个公用的网桥就可以实现跨主通信- 核心是在已有的宿主机网络上,通过软件再构建一个覆盖在已有宿主机网络之上的,可以把所有容器联通在一起的虚拟网络即 OverlayNetwork- 这个OverlayNetwork本身可以由每台宿主机上的一个特殊网桥共同组成,可以实现Container1访问Container3时可以由Node1的特殊网桥转发到Node2的网桥再转发给Container3- 也可以不用特殊网桥,仅仅通过某种方式配置宿主机的路由表即可实现正确的转发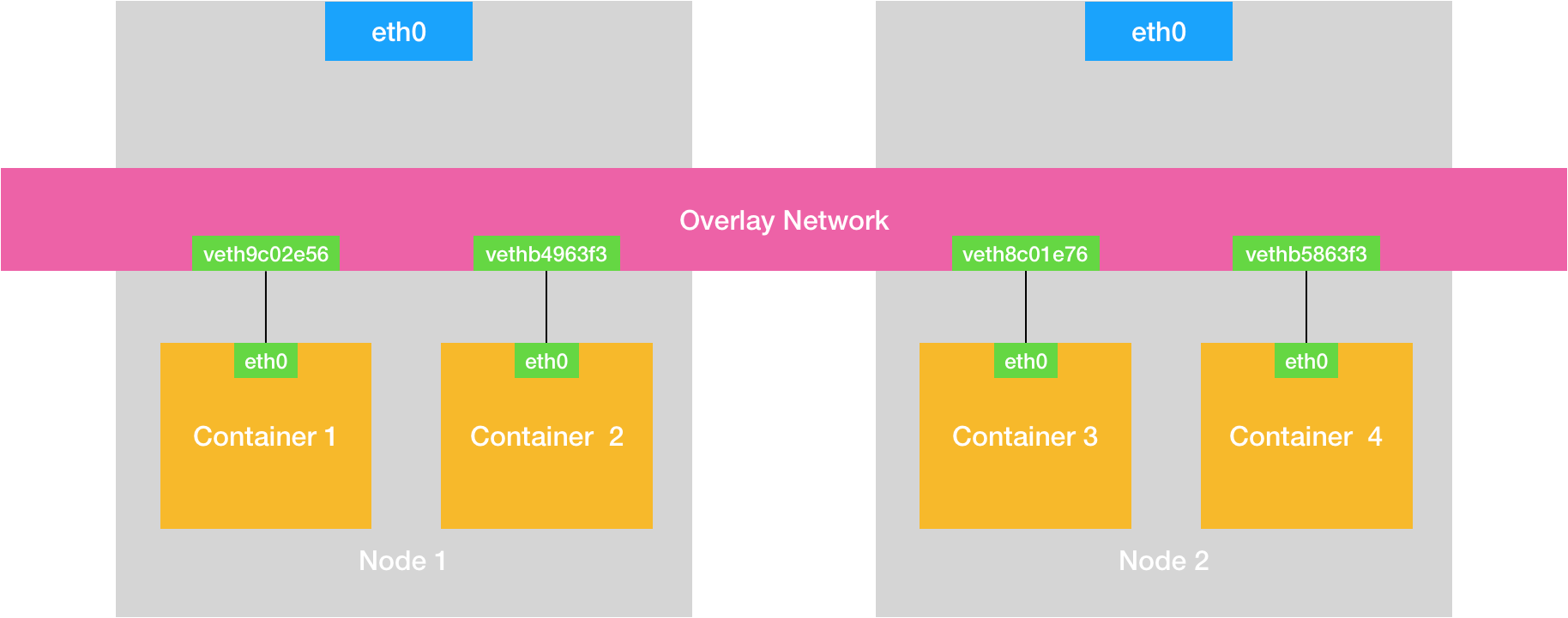<a name="fDnSC"></a>## 网络排查套路- 如果容器访问不通外网1. 首先docker0网桥是否ping通1. 然后查看跟docker0和vethXXX设备相关的iptables规则是否有异常<a name="SSs67"></a># 容器跨主机网络<a name="gfah6"></a>## TUN设备- Tunnel设备- Linux中TUN设备是一种工作在三层(NetworkLayer)的虚拟设备- 功能非常简单就是在操作系统内核和用户应用程序之间传递IP包(内核态与用户态相互转换)<a name="Hzust"></a>## Flannel- CoreOS主推的容器网络解决方案- Flannel只是一个网络框架,真正提供网络功能的是其后端实现,目前支持以下三种实现- VXLAN(由不同宿主机上的VTEP设备flannel.1组成的虚拟二层网络)- host-gw- UDP(最先实现,最易理解,但性能最差,已被废弃)- 特点- 用户的容器都连接在docker0网桥上- 网络插件在宿主机上创建一个特殊的设备- UDP模式的创建的是TUN设备- VXLAN模式的创建的是VTEP设备- docker0与这个设备之间通过IP转发(路由表)进行协作- 网络插件要做的就是通过某种方法,把不同宿主机上的特殊设备连通,达到容器跨主机通信的目的- Subnet子网- flannel管理的容器网络中,一台宿主机上的所有容器都属于该宿主机被分配的一个子网- 子网与宿主机的对应关系保存在etcd中- 根据目标pod IP可以查到对应的子网,进而反查到对应的宿主机IP```shell$ etcdctl ls /coreos.com/network/subnets/coreos.com/network/subnets/100.96.1.0-24/coreos.com/network/subnets/100.96.2.0-24/coreos.com/network/subnets/100.96.3.0-24$ etcdctl get /coreos.com/network/subnets/100.96.2.0-24{"PublicIP":"10.168.0.3"}
UDP
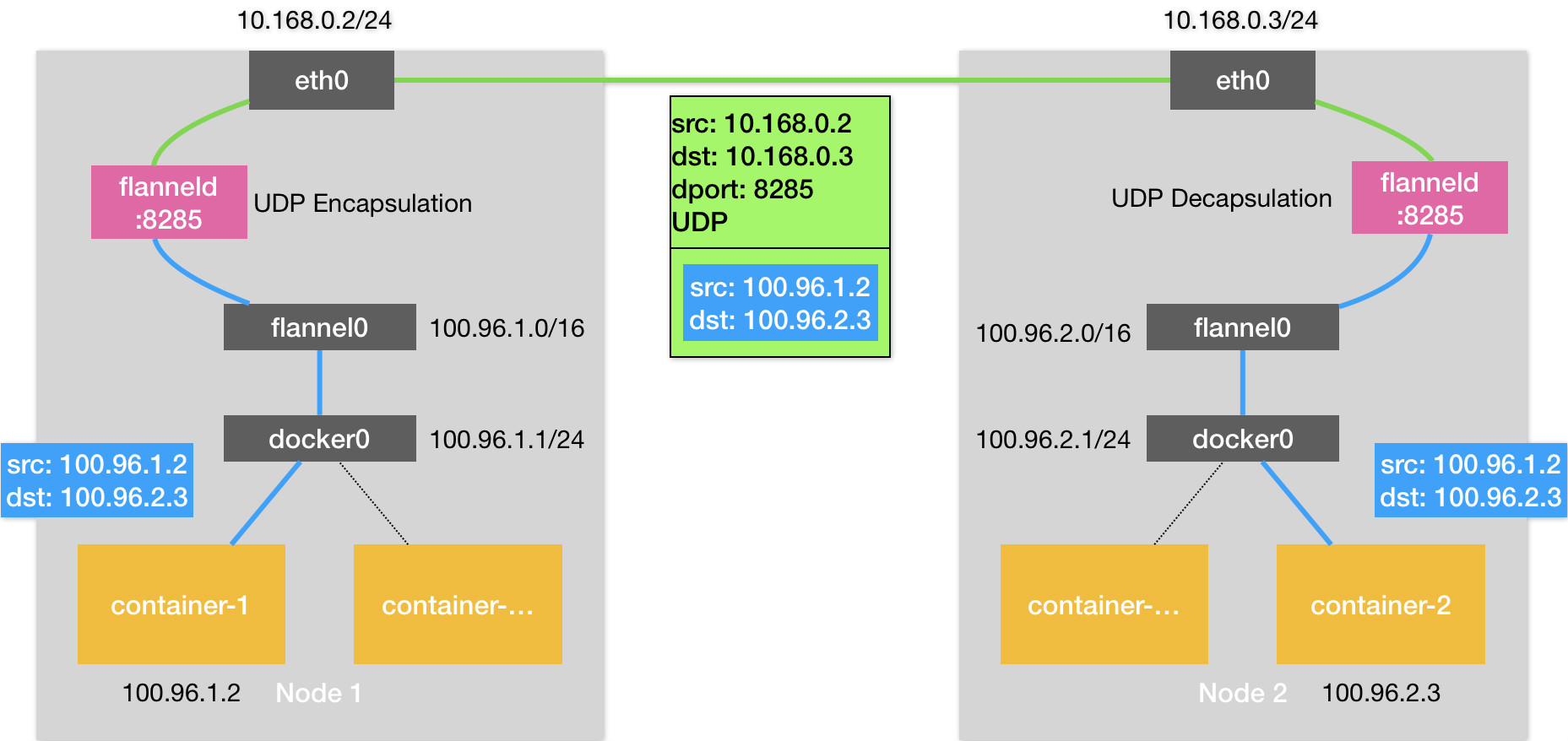
- 提供的是一个三层的Overlay网络
- node上都启动了flanneld 进程监听8285的udp端口
- 创建了一个TUN设备
- 首先对发出端的IP包进行UDP封装,接收端解析拿到原始的IP包,进而转发给对应的容器
- 好比flannel在不同宿主机的容器间打通了一条隧道,使容器间可相互通信,而不必关心容器和宿主机的分布
性能问题
VirtualExtensibleLAN虚拟可扩展局域网
- 是Linux内核本身就支持的网络虚拟化技术,可以完全在内核态处理封装和解封装的工作,通过相似的隧道机制构建出OverlayNetwork
- 创建了一个VTEP设备
- 设计思想
- 在现有的三层网络之上,覆盖一层虚拟的、由内核VXLAN模块负责维护的二层网络
- 使得连接在这个二层网络的主机(宿主机或容器)可以像在同一个LAN里自由通信
- 通过VTEP(VXLAN Tunnel End Point 虚拟隧道端点)实现隧道,类似UDP中的flanneld进程,不过其封装和解封装的对象是二层数据帧(Ethernet Frame),并且都是在内核中完成
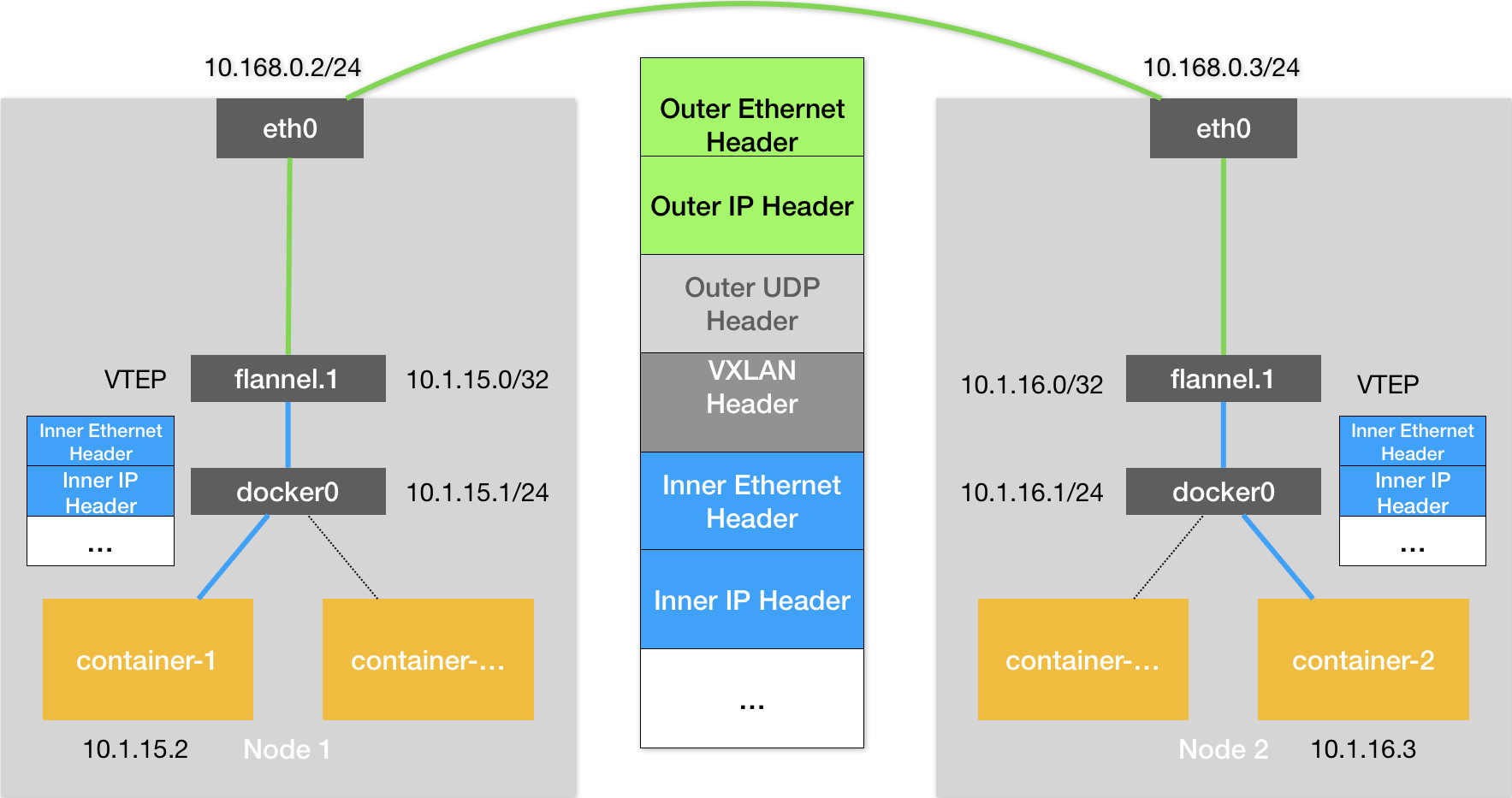
- 实现细节
- 每个宿主机的flanneld进程负责维护VTEP设备信息并共享给加入flannel网络的所有节点,并加入路由表
- VTEP设备之间要组成一个虚拟的二层网络,通过二层数据帧进行通信,就需要MAC地址
- 通过IP地址查询VETP设备的MAC地址就是ARP(AddressResolutionProtocol)表的功能
- ARP表的信息也是flanneld进程在节点启动时负责收集并共享所有节点,不依赖L3MISS事件和ARP学习,而会在每台节点启动时把它的VTEP设备对应的ARP记录直接下放到其他每台宿主机上
- 有了目的VTEP设备的MAC地址,Linux内核就可以开始二层封包工作了,二层帧格式如下
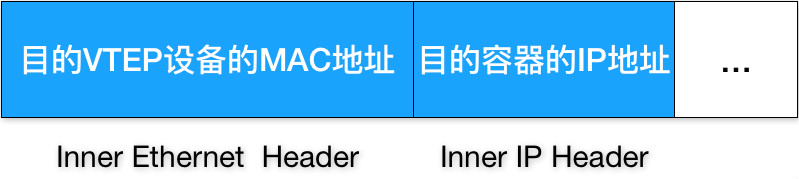
- 这个内部数据帧对于宿主机网络来说没有意义,不能在宿主机网络传输,还需要把这个InnerEthernetFrame进一步封装成宿主机网络的一个普通的数据帧以便通过宿主机eth0网卡传输
- 为了实现OuterEthernetFrame,linux内核对在InnerEthernetFrame前面加上一个特殊的VXLAN头用来表示这个“乘客”实际上是一个VXLAN要使用的数据帧
- 这个VXLAN头里有一个重要的标志叫做VNI,是VTEP设备识别某个数据帧是不是归自己处理的重要标识
- 在Flannel中VNI的默认值是1,这也是为何宿主机的VTEP设备都叫flannel.1的原因,这里的1就是VNI的值
- 然后Linux内核会把这个数据帧封装进一个UDP包里发送出去,宿主机看来只是两个flannel.1的设备进行了一个UDP的数据交换
- 为了把UDP包发送给正确的宿主机,flannel.1设备要扮演一个网桥的角色,在二层网络进行UDP包的转发,linux内核里“网桥”设备进行转发的依据来自FDB(ForwardingDatabase)的转发数据库
- 这个flannel.1网桥对应的FDB信息也是由flanneld进程负责维护,可以通过bridge fdb查看,从而获取对应宿主机的IP
- 接下来就是一个正常的、宿主机网络上的封包工作,完成后就可以通过flannel.1设备把数据帧从宿主机的eth0网卡发送出去,发到目的宿主机的eth0网卡
- 目的宿主机内核网络栈发现这个数据帧里有VXLAN Header并且VNI=1,就对其拆包后拿到内部数据帧,交给flannel.1设备,flannel.1设备进一步拆包,取出原始IP包发给对应容器

# 在Node 1上查看其他子网的网关和路由$ route -nKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Iface...10.1.16.0 10.1.16.0 255.255.255.0 UG 0 0 0 flannel.1# 在Node 1上查看 Node2的 MAC地址$ ip neigh show dev flannel.110.1.16.0 lladdr 5e:f8:4f:00:e3:37 PERMANENT# 在Node 1上,使用“目的VTEP设备”的MAC地址进行查询$ bridge fdb show flannel.1 | grep 5e:f8:4f:00:e3:375e:f8:4f:00:e3:37 dev flannel.1 dst 10.168.0.3 self permanent #发往目的MAC的数据帧应该通过flannel.1设备发往IP地址为10.168.0.3的主机
k8s网络模型和CNI网络插件
k8s网络模型
- 通过CNI维护一个单独的网桥CNI网桥,代替docker0,在宿主机上默认的名字就是cni0

- k8s为flannel分配的子网
- kubeadm init —pod-network-cidr=10.244.0.0/16
- 也可以在部署完后在kube-controller-manager的配置文件修改
- CNI网桥只接管CNI插件负责的、k8s创建的Pod,docker run起来的还是会接入docker0网桥,容器的IP地址还是属于docker0网桥的172.17.0.0/16网段
- k8s项目没有使用docker的网络模型CNM,并不希望也不具备配置docker0网桥的能力
- 与k8s如何配置Pod,也就是Infra容器NetworkNamespace密切相关
网络模型
CNI的设计思想就是k8s在启动Infra容器,hold住这个Pod的NetworkNamespace后直接调用CNI网络插件,为这个Infra容器的NetworkNamespace配置符合预期的网络栈
部署
有一个步骤是安装kubernetes-cni包,它的目的就是在宿主机上安装CNI插件所需的基础可执行文件到/opt/cni/bin,主要分三类
- Main插件,用来创建具体网络设备的二进制文件
- bridge
- ipvlan
- loopback
- macvlan
- ptp(VethPair设备)
- vlan
- IPAM(IP Address Management)插件,负责分配IP地址的二进制文件
- dhcp 向dhcp服务器发起请求
- host-local 会使用预置的IP地址段来分配
- CNI社区维护的内置CNI插件
- flannel
- tuning 通过sysctl调整网络设备参数的二进制文件
- portmap 通过iptables配置端口映射的二进制文件
- bandwidth 使用TokenBucketFilter(TBF)来进行限流的二进制文件 ```shell
- Main插件,用来创建具体网络设备的二进制文件
$ ls -al /opt/cni/bin/ total 73088 -rwxr-xr-x 1 root root 3890407 Aug 17 2017 bridge -rwxr-xr-x 1 root root 9921982 Aug 17 2017 dhcp -rwxr-xr-x 1 root root 2814104 Aug 17 2017 flannel -rwxr-xr-x 1 root root 2991965 Aug 17 2017 host-local -rwxr-xr-x 1 root root 3475802 Aug 17 2017 ipvlan -rwxr-xr-x 1 root root 3026388 Aug 17 2017 loopback -rwxr-xr-x 1 root root 3520724 Aug 17 2017 macvlan -rwxr-xr-x 1 root root 3470464 Aug 17 2017 portmap -rwxr-xr-x 1 root root 3877986 Aug 17 2017 ptp -rwxr-xr-x 1 root root 2605279 Aug 17 2017 sample -rwxr-xr-x 1 root root 2808402 Aug 17 2017 tuning -rwxr-xr-x 1 root root 3475750 Aug 17 2017 vlan
- 要实现一个给k8s用的容器网络方案,其实需要做两部分工作
- 实现这个网络方案本身,主要就是flanneld进程要做的工作
- 实现该网络方案对应的CNI插件,主要是配置Infra容器里的网络栈,并连接到CNI网桥
- 宿主机上安装flanneld,启动后在每个宿主机上生成它对应的CNI配置文件,从而告诉k8s这个集群要使用flannel,以下是CNI配置文件内容
```shell
$ cat /etc/cni/net.d/10-flannel.conflist
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
- k8s中,处理网络相关的逻辑并不会在kubelet主干代码里,而是在CRI实现里完成,对于docker项目就是dockershim
dockershim加载上述CNI配置文件,并把plugins里的第一个插件设置为默认插件,并依次完成插件调用
CNI工作原理
kubelet组件需要创建Pod时,第一个创建的一定是Infra容器
- dockershim调用DockerAPI创建并启动Infra容器
- 然后执行SetUpPod方法,为CNI插件准备参数,调用CNI插件为Infra容器配置网络
- 参数一:dockershim设置的一组CNI环境变量
- 最重要的是CNI_COMMAND=ADD|DEL
- 这两个操作就是CNI插件唯一需要实现的两个方法
- ADD就是把容器添加到CNI网络
- 容器里网卡的名字eth0(CNI_IFNAME)
- Pod的NetworkNamespace文件的路径(CNI_NETNS)
- 容器的ID(CNI_CONTAINERID)
- DEL就是把容器从CNI网络移除掉
- 还有一个CNI_ARGS的参数,CRI的实现比如dockershim可以以KV的格式传递自定义参数
- 参数二:dockershim从CNI配置文件里加载的、默认插件的配置信息
- 这个配置信息在CNI中被叫做NetworkConfiguration
- dockershim会把NetworkConfiguration以JSON数据的格式通过stdin传递给CNI插件
- 参数一:dockershim设置的一组CNI环境变量
- 拿到参数后dockershim调用CNI插件对NetworkConfiguration进行补充并保存在/var/lib/cni/flannel后(方便删除)调用具体的delegate的插件将容器加入CNI网络
- CNI bridge插件会在宿主机上检查CNI网桥是否存在,如果没有则创建 ```shell
在宿主机上
$ ip link add cni0 type bridge $ ip link set cni0 up
- CNI bridge插件会通过Infra容器的NetworkNamespace文件进入到这个NS里面,创建一对VethPair设备,然后把VethPair的一端移动到宿主机上,相当于在容器里执行如下命令
```shell
#在容器里
# 创建一对Veth Pair设备。其中一个叫作eth0,另一个叫作vethb4963f3
$ ip link add eth0 type veth peer name vethb4963f3
# 启动eth0设备
$ ip link set eth0 up
# 将Veth Pair设备的另一端(也就是vethb4963f3设备)放到宿主机(也就是Host Namespace)里
$ ip link set vethb4963f3 netns $HOST_NS
# 通过Host Namespace,启动宿主机上的vethb4963f3设备
$ ip netns exec $HOST_NS ip link set vethb4963f3 up
- CNI bridge插件可以把宿主机上的VethPair设备连接在CNI网桥上并为其设置HairpinMode发夹模式取消网桥设备默认的不允许一个数据包从一个端口进来后再从这个端口出去的限制,相当于执行 ```shell
在宿主机上
$ ip link set vethb4963f3 master cni0
- 开启HairpinMode主要用在容器需要通过NAT的方式“自己访问自己”的场景下
- docker run -p 8080:80
- 宿主机通过iptables 设置了DNAT规则,把宿主机的8080经docker0网桥转发到容器的80
- 如果在容器里面访问宿主机的8080,则容器里的IP包经过VethPair和docker0网桥到宿主机后又回到容器里
- 所以要开启HairpinMode,来让集群里的pod通过自己的service访问到自己
- 接下来CNI bridge插件会调用CNI ipam插件从 ipam.subnet字段规定的网段里为容器分配一个可用的IP并把这个IP添加到容器里的eth0网卡上,并设置默认路由,相当于
```shell
# 在容器里
$ ip addr add 10.244.0.2/24 dev eth0
$ ip route add default via 10.244.0.1 dev eth0
- 最后 CNI bridge插件会为CNI网桥添加IP地址 ```shell
在宿主机上
$ ip addr add 10.244.0.1/24 dev cni0
- 执行完上述操作后,CNI插件会把容器的IP等信息返回给dockershim,然后被kubelet添加到Pod的Status字段
<a name="RPDAU"></a>
# k8s三层网络方案
- 纯三层的网络方案典型例子
- Flannel的host-gw模式,推荐在公有云的环境
- Calico,推荐在私有部署的环境(网络比较复杂)
- 三层网络方案在宿主机上的路由规则比较多,冲突概率很大,问题排查比较困难
<a name="xIVwh"></a>
## Flannel的host-gw模式
<a name="ZGwfj"></a>
### 原理
- 将每个FlannelSubnet子网的下一跳,设置成了该子网对应宿主机的IP地址,即这台主机会充当主机上的容器的网关即host-gw
- Flannel子网和主机信息都是保存在Etcd中,flanneld只需要WATCH这些数据的变化实时更新路由表即可
- 这种模式容器通信的过程免除了额外的封包/解包的性能损耗,实际测试host-gw性能损失大约的10%,而其他基于VXLAN隧道的方案都要损失20%-30%
- 能正常工作的核心在于IP包封装二层帧的时候采用了下一跳的MAC地址,就会经过二层网络到达目的宿主机,所以此模式必须要求集群宿主机之间的二层是连通的

<a name="vyeha"></a>
### 详述
- 假设Infra-container-1要访问Infra-container-2
- Flannel使用了host-gw模式后,flanneld会在宿主机创建路由规则如下
```shell
$ ip route
...
10.244.1.0/24 via 10.168.0.3 dev eth0
# 表示目的IP地址属于10.244.1.0/24网段的IP包应该经过本机的eth0设备发出去,下一跳next-hop是10.168.0.3
- IP包从网络层进入链路层封装成帧的时候,使用下一跳对应的MAC地址,数据帧就从Node1到达Node2
Node2看到目的IP是Infra-container-2的IP,根据Node2上的路由表进入cni0网桥进入容器2
Calico
和Flannel的host-gw模式基本一致,Calico也会在每台宿主机上添加一个路由规则 ```shell
<目的容器IP地址段> via <网关的IP地址> dev eth0
- 不同于Flannel通过etcd和宿主机上的flanneld来维护路由信息的做法,Calico项目使用了一个“重型武器”BGP来自动地在整个集群中分发路由信息
- Calico不会在宿主机上创建任何网桥设备
- Calico同Flannel的host-gw模式一样,都需要集群的宿主机是二层连通的,如果不在同一个子网,二层不通就需要打开IPIP模式,但性能会因为增加了虚拟设备进行封包和解包而下降
- 实际使用时,如非硬性要求,建议将宿主机节点放在同一个子网里,避免IPIP模式
<a name="mle76"></a>
### BGP
- BorderGatewayProtocol边界网关协议,是一个内核原生就支持的、专门用在大规模数据中心里维护不同的“自治系统AS(AutonomousSystem)”之间的路由信息、无中心的路由协议
- 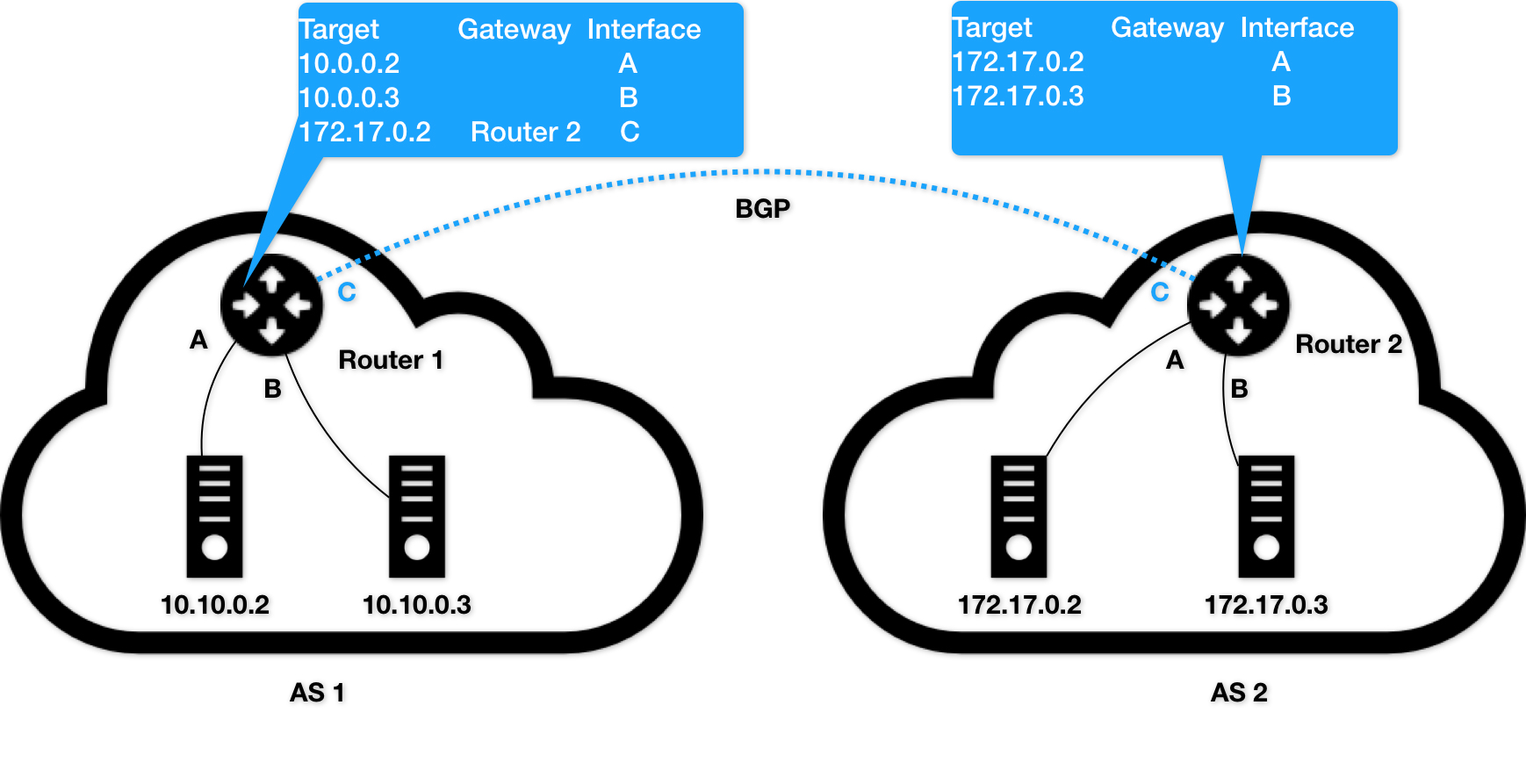
- 自治系统指的是一个组织管辖下的所有IP网络和路由器的全体,可以想像成一个小公司里所有的主机和路由器
- 正常情况下,自治系统之间不会有任何来往
- 但如果两个自治系统里的主机要通过IP地址进行通信,就必须使用路由器把这两个自治系统连接起来,路由器上配置对应的规则,像这样负责把自治系统连接在一起的路由器就是边界网关
- 边界网关和普通路由器不同之处在于他的路由表里拥有其他自治系统里的主机路由信息
- BGP会在每个边界网关上都运行一个小程序,将各自的路由表信息通过TCP传输给其他边界网关,其他网关上的小程序则分析数据将需要的添加到自己的路由表中,适合大规模的、复杂的网络环境
- BGP是大规模网络中实现节点路由信息共享的一种协议
<a name="sxDLz"></a>
### 架构
- Calico的CNI插件
- Felix,是一个DaemonSet,负责在宿主机上插入路由规则(内核的FIB转发信息库),维护Calico所需的网络设备工作,维护下一跳的路由规则
- BIRD,就是BGP的客户端,专门负责在集群里分发路由规则信息
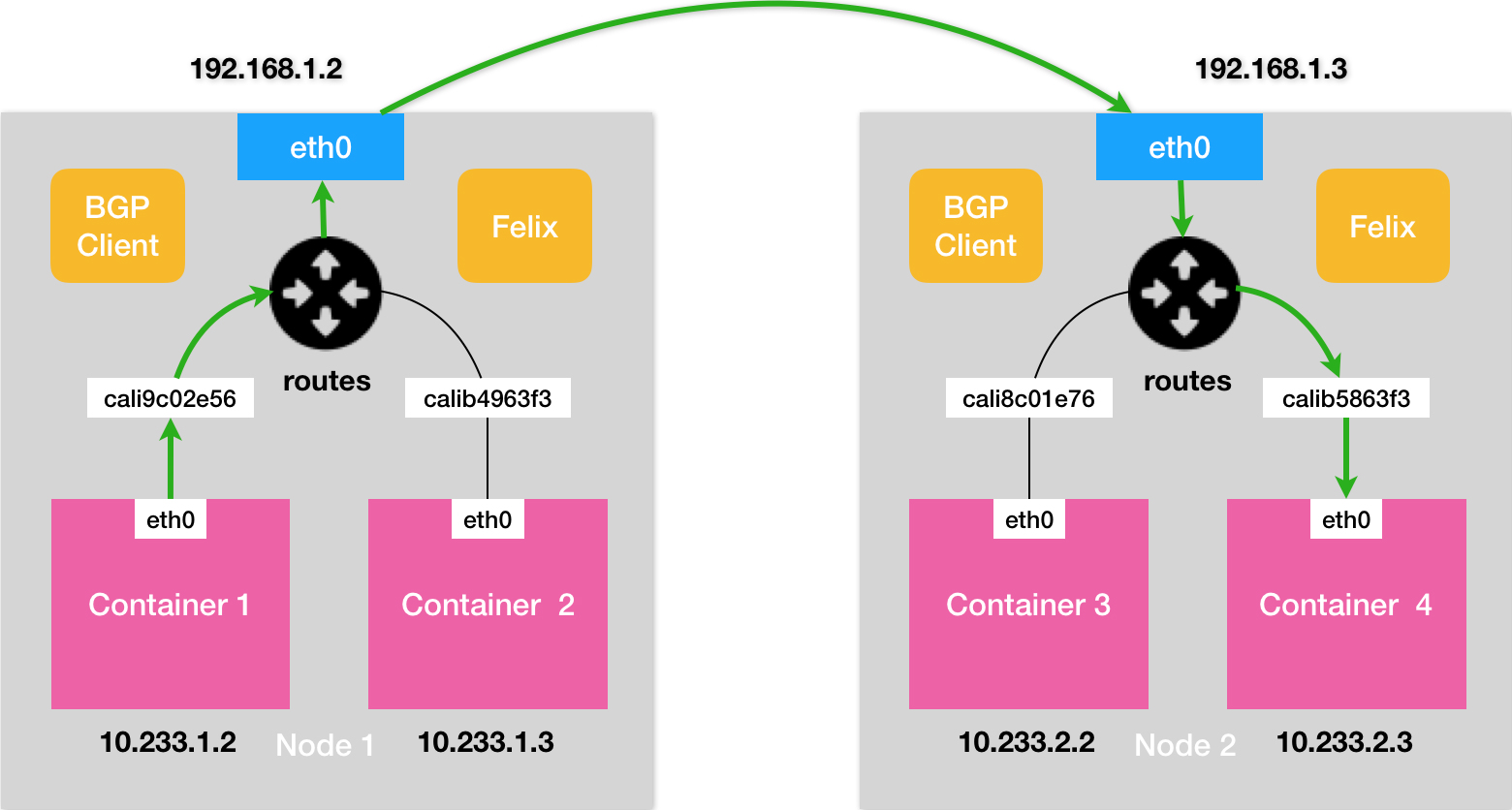
```shell
# BGP协议消息
[BGP消息]
我是宿主机192.168.1.3
10.233.2.0/24网段的容器都在我这里
这些容器的下一跳地址是我
模式
- NodeToNodeMesh
- 集群中的每一个节点都是边界路由,他们共同组成了一个全连通的网络,相互之间通过BGP协议交换路由规则
- 这些节点被称为BGP Peer
- 但随着节点数量增加,每个节点都要和其他所有节点通信,带来了指数递增的网络压力
- 一般用于少于100个节点的集群里
- RouteReflector
- Calico指定一个或几个专门的节点,来负责跟所有节点建立BGP连接从而学习全局的路由规则
- 其他节点只需要跟这几个专门的节点交换路由信息从而同步整个集群的路由信息
- 这些专门的节点就是RouteReflector节点,扮演“中间代理”的角色,从而把BGP连接规模控制在N的数量级上
- IPIP
- 宿主机的IP是连通的即三层是通的,但二层网络不在同一个子网,没办法通过二层网络把IP包发送到下一跳,所以需要打开IPIP模式

- IPIP模式下,Felix进程在Node1上添加的路由规则稍有不同,如下所示 ```shell
10.233.2.0/24 via 192.168.2.2 tunl0
- 负责将IP包发出去的设备从eth0变成了 tunl0(不是Flannel UDP模式的 TUN0)
- 这个tunl0设备是一个IP隧道设备( IP tunnel)
- 在上面的例子中,IP包进入IP隧道设备后会被内核的IPIP驱动接管,驱动会将这个IP包直接再封装在一个宿主机网络的IP包中,如下所示
- 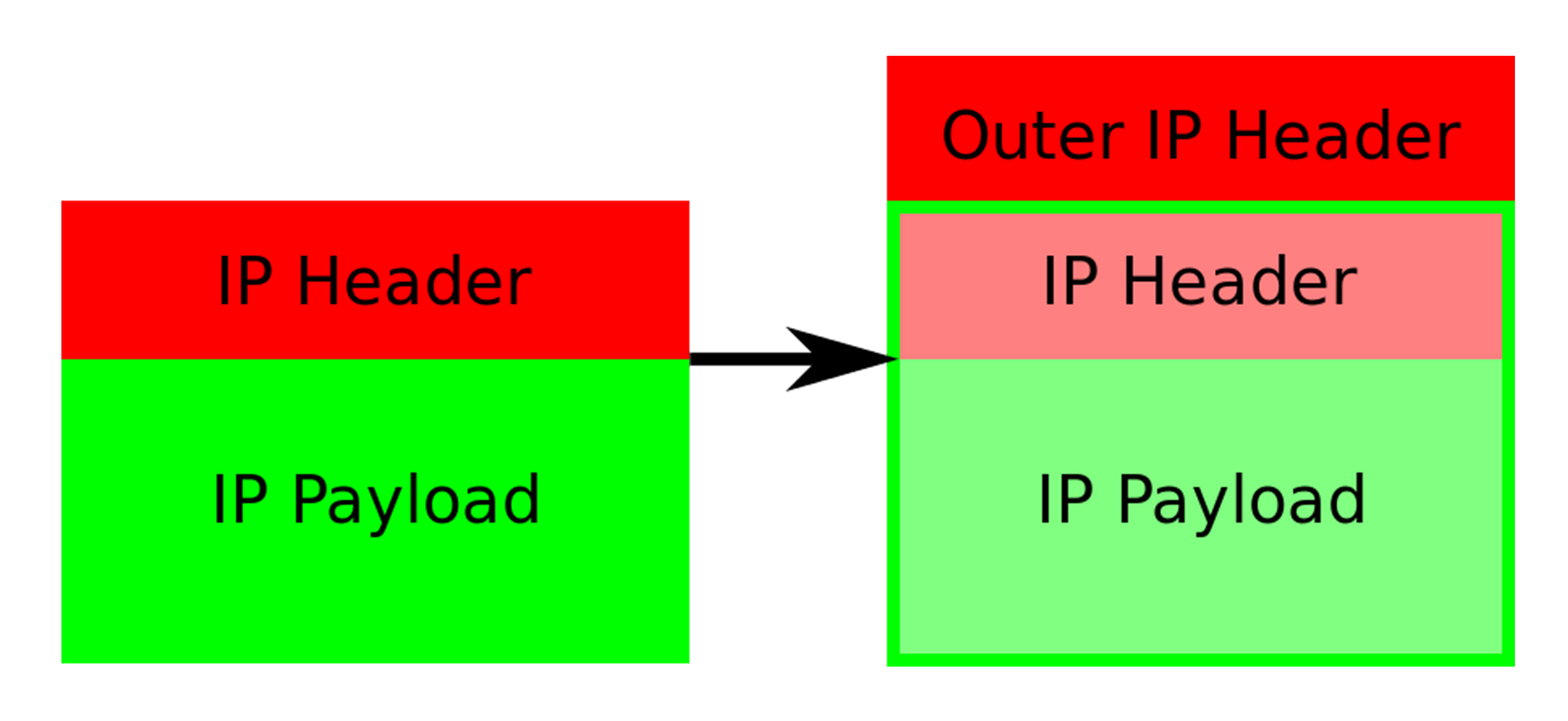
- 经过封装后的新的IP包的目的地址就是原IP包下一跳地址即Node2的IP地址,原IP包本身会被直接封装成新IP包的Payload,从而把原来从容器到Node2的IP包,伪装成一个从Node1到Node2的IP包
- 宿主机之间使用了路由器配置了三层转发,所以IP包从Node1经路由器跳到了Node2
- Node2上的网络栈使用IPIP驱动解包,从而拿到原始的IP包,原始IP包经过路由规则和VethPair设备到达容器内部
- 使用IPIP模式,集群的网络性能因为额外的封包/解包工作而下降,IPIP模式和VXLAN模式大致相当
<a name="wY2QW"></a>
### 宿主机网关设置为BGPPeer
- 背景
- 公有云的宿主机网关,不会允许用户干预和设置
- 大多数公有云的环境,宿主机本身是二层连通的
- 私有部署的情况下,宿主机属于不同子网VLAN反而比较常见,这时要想办法把宿主机网关加入BGP Mesh里避免使用IPIP
- 方案(推荐方案二)
- 一、所有宿主机都跟宿主机网关建立BGP Peer关系
- Calico要求宿主机网关必须支持DynamicNeighbors的BGP配置,给路由器配置一个网段,路由器根据网段里的主机自动建立BGP Peer关系
- 常规的路由器BGP配置只支持静态的配置
- 二、使用一个或多个独立组件负责搜集整个集群里的路由信息,然后通过BGP协议同步给网关(RouteReflector)
- 网关的BGP Peer个数是有限并且固定的
- 可以直接把独立组件配置成路由器的BGP Peer,无需DynamicNeighbors的支持
- 这些独立组件的工作原理只需要WATCH Etcd里的宿主机和对应网段的变化信息,然后把这些信息通过BGP协议分发给网关即可
<a name="4bW9k"></a>
# soft multi-tenancy
- k8s中只有soft multi-tenancy
- k8s的网络模型和大多数容器网络的实现,既不保证二层网络的互通,也不保证其隔离
- 在底层设计上更倾向假设你已经有了一套完整的物理基础设施,然后在其之上提供“弱多租户”的能力
<a name="o4ukE"></a>
## NetworkPolicy
- k8s中,网络隔离是靠NetworkPolicy对象完成的
- k8s中,Pod默认都是允许所有AcceptAll,即Pod可以接收来自任何发送方的请求或向任何接收方发送请求
- 一旦被NetworkPolicy选中,Pod就会进入拒绝所有DenyAll的状态,既不允许被外界访问,也不允许访问外界
- NetworkPolicy的规则其实就是白名单,配置在宿主机上的一系列iptables规则
```yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector: # 如果留空 {} ,则应用于当前ns下的所有Pod
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
CNI插件
- 如果NetworkPolicy要产生作用,必须要CNI插件的支持
- CNI插件维护着一个NetworkPolicyController,通过控制循环方式对NetworkPolicy对象的增删改查作出响应,在宿主机上完成iptables规则的配置工作
目前已经实现了NetworkPolicy的网络插件包括Calico、Weave和kube-router,但不包括Flannel
IPTables
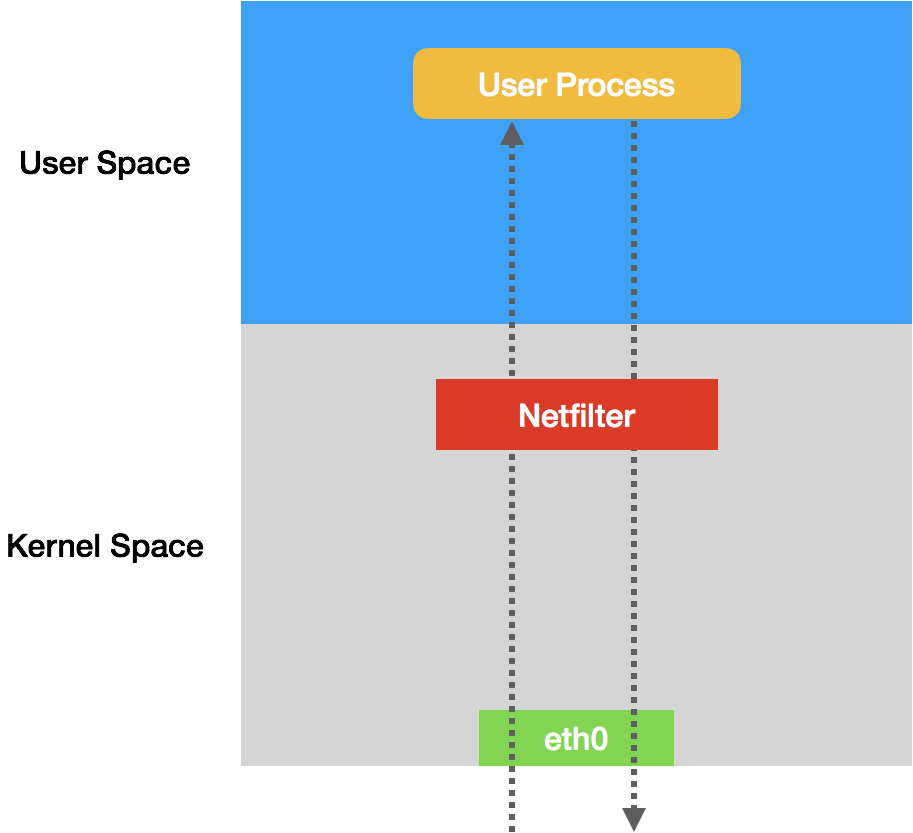
是一个操作Linux内核Netfilter子系统的“界面”
- Netfilter子系统的作用就是内核里挡在网卡和用户态进程之间的一道防火墙,工作在三层,示意图如下
- 按照检查点(内核网络栈的Hook)的定义顺序依次匹配检查,形成链,链的工作原理如下图
- 进来的流量首先经过PREROUTING,后有两种情况
- 第一种,继续在本机处理,IP包继续向上层协议栈流动,经过INPUT检查点结束Input path,到达传输层
- 第二种,被转发到其他目的地,不进入传输层,继续由网络层进入ForwardPath,经FORWARD后到达POSTROUTING
- 用户进程处理完毕后通过本机发出返回的IP包,这时候进入了OutputPath
- IP包还是会经过宿主机的路由表进行路由
- 路由结束后进入OUTPUT检查点
- 然后进入POSTROUTING检查点
- 每一个检查点还会有很多表,按顺序执行几个不同的检查动作,比如
- nat
- filter
- raw
- mangle
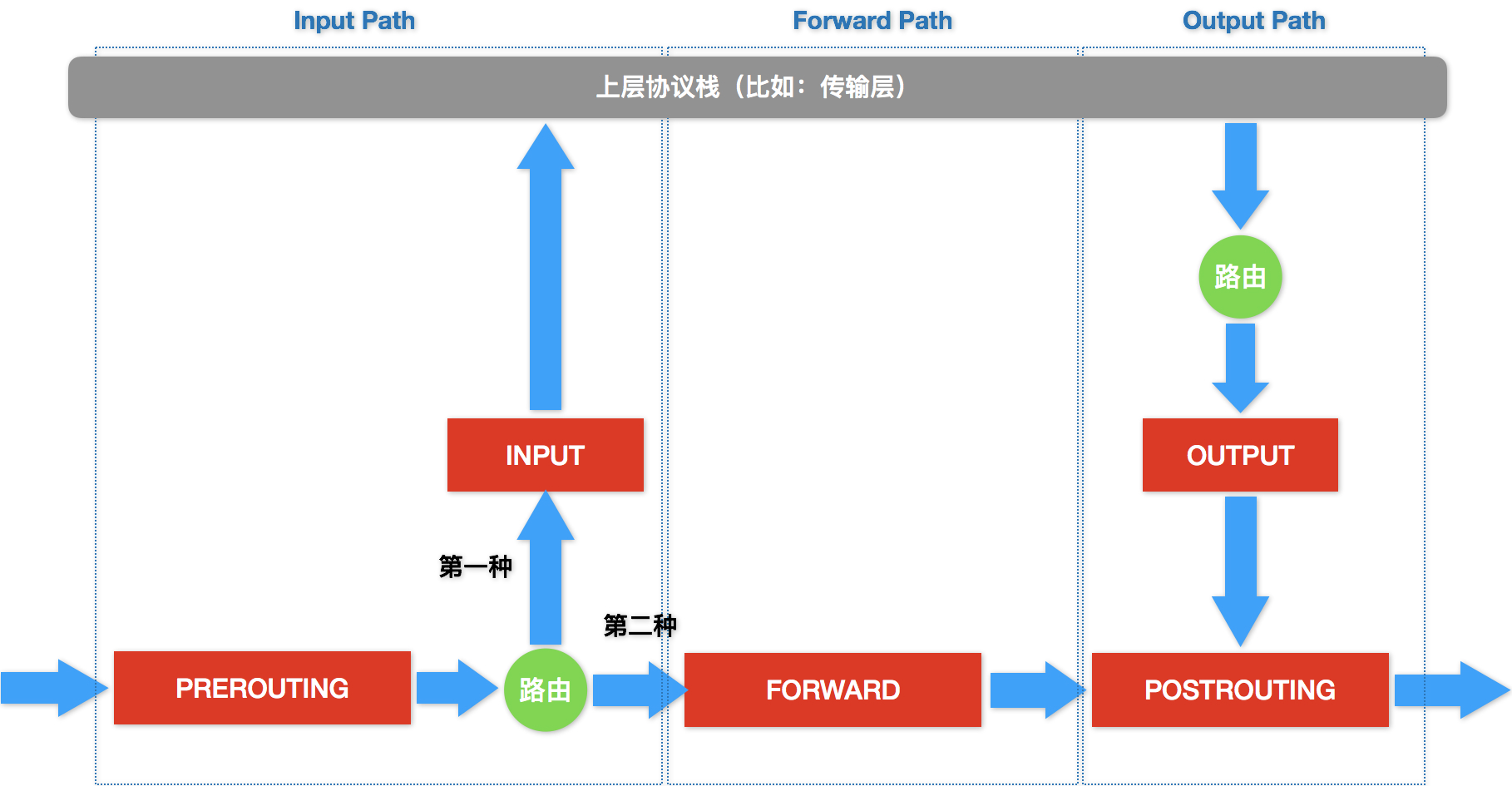
- 在有网桥参与的情况下,链路层也会有相应的检查点,这些二层的检查点对应的操作界面叫ebtables
- 所以数据包在内核的netfilter子系统中完整的流动如下图
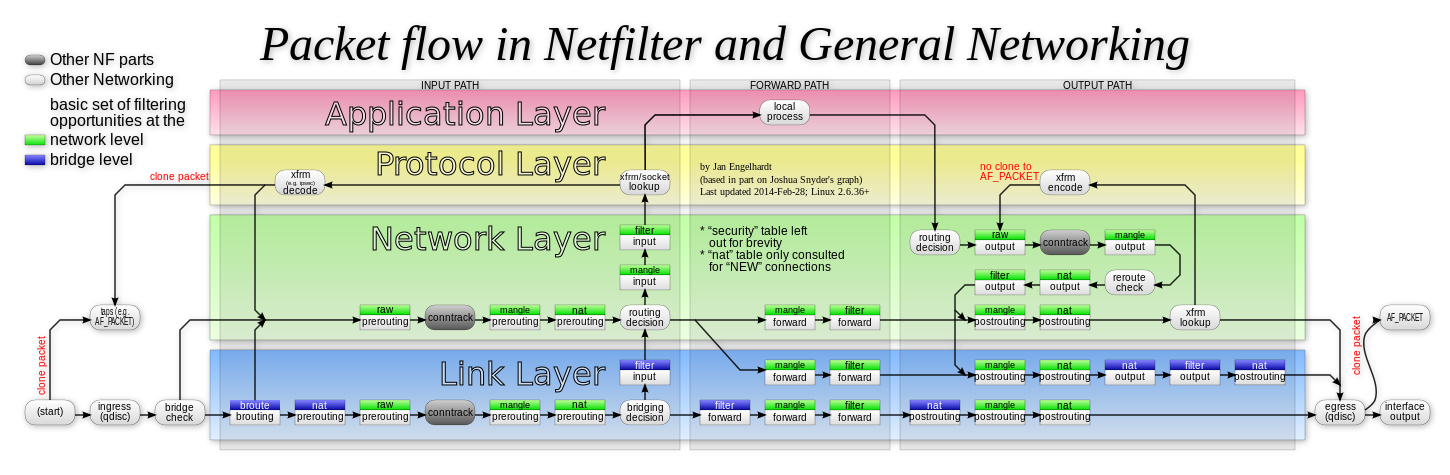
隔离原理
- 通过NetworkPolicy对象在宿主机上生成iptables 规则 ```yaml
apiVersion: extensions/v1beta1 kind: NetworkPolicy metadata: name: test-network-policy namespace: default spec: podSelector: matchLabels: role: db ingress:
- from:
- namespaceSelector:
matchLabels:
project: myproject - podSelector:
matchLabels:
ports:role: frontend- protocol: tcp
port: 6379
- protocol: tcp
port: 6379
- namespaceSelector:
matchLabels:
for dstIP := range 所有被networkpolicy.spec.podSelector选中的Pod的IP地址 for srcIP := range 所有被ingress.from.podSelector选中的Pod的IP地址 for port, protocol := range ingress.ports { iptables -A KUBE-NWPLCY-CHAIN -s $srcIP -d $dstIP -p $protocol -m $protocol —dport $port -j ACCEPT } } }
- 设置好隔离规则后,插件还需要想办法对被隔离的Pod访问请求都转发到这个KUBE-NWPLCY-CHAIN上去匹配,并且如果匹配不通过则拒绝请求,所以需要配置两组iptables规则
- 第一组规则,负责拦截对被隔离Pod的访问请求,都跳到第二组规则上
- 第一条FORWARD链拦截的是一种特殊情况:同一台宿主机上容器间通过CNI网桥进行通信的流入数据包
- 第二条FORWARD链拦截的就是容器跨主通信,这时流入容器的数据包都是FORWARD来的
```shell
for pod := range 该Node上的所有Pod {
if pod是networkpolicy.spec.podSelector选中的 {
iptables -A FORWARD -d $podIP -m physdev --physdev-is-bridged -j KUBE-POD-SPECIFIC-FW-CHAIN
iptables -A FORWARD -d $podIP -j KUBE-POD-SPECIFIC-FW-CHAIN
...
}
}
- 第二组规则,KUBE-POD-SPECIFIC-FW-CHAIN,作出允许或拒绝的判断,类似如下
- 把IP包转发给前面定义的KUBE-NWPLCY-CHAIN去匹配,匹配成功则通过
- 匹配失败的则来到第二条规则上被REJECT,实现隔离
```shell
iptables -A KUBE-POD-SPECIFIC-FW-CHAIN -j KUBE-NWPLCY-CHAIN iptables -A KUBE-POD-SPECIFIC-FW-CHAIN -j REJECT —reject-with icmp-port-unreachable
<a name="86MfD"></a>
# Service/DNS/服务发现
<a name="IeS4c"></a>
## Service
- 目的
- Pod的IP不是固定不变的
- 一组Pod实例之间有负载均衡的需求
- 定义
- 被selector选中的Pods被称为Service的endpoints
- 只有处于ready的Pod才会出现在ep中,如果Pod出现问题则会自动被剔除
- 通过Service的VIP可以访问它所代理的Pod
- 工作原理
- 由kube-proxy组件和iptables共同实现的
- 当Service对象被提交给集群,kube-proxy就通过Service的Informer感知到其创建,从而在宿主机上创建对应的iptables规则(可以通过iptables-save查看)
- kube-proxy监听Pod的变化事件在宿主机上维护对应的iptables规则
- kube-proxy还支持一种IPVS模式,来解决大量iptables规则的维护带来的复杂性和低效率
- 当Service创建后,kube-proxy在宿主机上创建一个虚拟网卡kube-ipvs0,并为其分配service的VIP
- 接下来kube-proxy会调用linux的IPVS模块为这个VIP设置对应的后端和负载策略,通过ipvsadm看
- 相比iptables规则,IPVS在内核中的实现也是基于Netfilter子系统的NAT模式,所以在转发这个层面上性能和iptables一致,但不需要在宿主机为每个Pod维护iptables规则,而是把这些规则放到了内核态,从而提高了效率
- IPVS只是负责负载均衡和代理的功能,一个service完整的流程所需要的包过滤,SNAT等的操作还是需要iptables完成,不过这些辅助性的规则数量有限,不会随Pod数量增加而增加
- 所以大规模集群里推荐kube-proxy使用-proxy-mode=ipvs 提升网络性能
```shell
# ip addr
...
73:kube-ipvs0:<BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 1a:ce:f5:5f:c1:4d brd ff:ff:ff:ff:ff:ff
inet 10.0.1.175/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:80 rr
-> 10.244.3.6:9376 Masq 1 0 0
-> 10.244.1.7:9376 Masq 1 0 0
-> 10.244.2.3:9376 Masq 1 0 0
apiVersion: v1
kind: Service
metadata:
name: hostnames
spec:
selector:
app: hostnames
ports:
- name: default
protocol: TCP
port: 80
targetPort: 9376
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hostnames
spec:
selector:
matchLabels:
app: hostnames
replicas: 3
template:
metadata:
labels:
app: hostnames
spec:
containers:
- name: hostnames
image: k8s.gcr.io/serve_hostname
ports:
- containerPort: 9376
protocol: TCP
$ kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.0.5:9376,10.244.0.6:9376,10.244.0.7:9376
$ kubectl get svc hostnames
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hostnames ClusterIP 10.0.1.175 <none> 80/TCP 5s
$ curl 10.0.1.175:80
hostnames-0uton
$ curl 10.0.1.175:80
hostnames-yp2kp
$ curl 10.0.1.175:80
hostnames-bvc05
DNS
- k8s中,service和pod都会被分配对应的DNS A记录
- Service类型
- ClusterIP(Type=ClusterIP)
. .svc.cluster.local - DNS解析到VIP
- Pod被自动分配的A记录的格式是
. .pod.cluster.local - DNS解析到PodIP
- HeadlessService(ClusterIP=None)
. .svc.cluster.local - DNS解析到所有被代理的Pod的IP的集合,如果客户端无法解析这个集合,默认取第一个
- Pod被自动分配的A记录的格式
- pod本身没有声明hostname和subdomain字段:
. . .svc.cluster.local,DNS解析到PodIP - pod本身声明了hostname和subdomain字段:
. . .svc.cluster.local, DNS解析到PodIP,比如下面的Pod就可以用busybox-1.default-subdomain.default.svc.cluster.local访问
- pod本身没有声明hostname和subdomain字段:
- HeadlessService提供的就是Pod的稳定的DNS名字(Pod名字和SVC名字拼接出来) ```yaml
- ClusterIP(Type=ClusterIP)
apiVersion: v1 kind: Service metadata: name: default-subdomain spec: selector: name: busybox clusterIP: None ports:
- name: foo port: 1234 targetPort: 1234
apiVersion: v1 kind: Pod metadata: name: busybox1 labels: name: busybox spec: hostname: busybox-1 subdomain: default-subdomain containers:
- image: busybox command:
- 代码 ```yaml
apiVersion: v1 kind: Service metadata: name: my-nginx labels: run: my-nginx spec: type: NodePort ports:
- nodePort: 8080 # service的8080端口代理pod的80 targetPort: 80 protocol: TCP name: http
- nodePort: 443 # service的443端口代理pod的443 protocol: TCP name: https selector: run: my-nginx ```
- 如果不显示声明nodePort,k8s会分配一个随机端口(3000-32767)来设置代理
- 随机端口的区间也可通过kube-apiserver的 service-node-port-range参数进行设置
- 工作原理也是通过iptables规则/ipvs规则进行代理设置
- 在NodePort方式下,k8s会在IP包离开宿主机发往目的Pod时,对这个IP包做一个SNAT,如下所示
- 这条规则设置在POSTROUTING后
- 将这个IP包的源地址改成了宿主机上的CNI网桥地址或宿主机IP
- 这个SNAT只需要对Service转发的IP包进行,不能影响普通的IP包
- 判断的依据就是看该IP包是否有0x4000的标志,这个标志是在IP包被执行DNAT之前被打上去的 ```
-A KUBE-POSTROUTING -m comment —comment “kubernetes service traffic requiring SNAT” -m mark —mark 0x4000/0x4000 -j MASQUERADE
- 为什么要做SNAT
- client通过Node2的IP和端口访问服务,可能被转发到Node1上的Pod
- 所以如果不做SNAT,Node1上的Pod处理完毕后如果直接回复给client可能会出错,因为client是从Node2发出的请求,却接收到了Node1的回复
client
\ ^
\ \
v \
node 1 <—- node 2 | ^ SNAT | | —-> v | endpoint
- 做完SNAT后Pod只能看到这个请求来自Node2,并不知道真正的ClientIP
- 对于Pod需要明确知道请求源地址的场景需要将Service.spec.externalTrafficPolicy设置为local,来保证Pod能获取到真正ClientIP
- 设置为local后其实是iptables规则只负责将ip包转发给运行在当前宿主机上的Pod,如果不在当前宿主机,请求就被DROP,例如用node2的IP访问就会失败
client
^ / \
/ / \
/ v X
node 1 node 2 ^ | | | | v endpoint
<a name="7mgzu"></a>
### LoadBalancerService
- 适用于公有云上的k8s服务
- 公有云服务都使用了CloudProvider的转接层,来跟云本身的API对接,当LB类型的service被提交后,就会调用CloudProvider在公有云上创建一个负载均衡服务,并代理选中的PodIP
- 代码
```yaml
---
kind: Service
apiVersion: v1
metadata:
name: example-service
spec:
ports:
- port: 8765
targetPort: 9376
selector:
app: example
type: LoadBalancer
ExternalName
- k8s1.7后支持的新特性
- 就是把
. .svc.cluster.local做了个CNAME指向了已存在的域名 - 代码 ```yaml
kind: Service apiVersion: v1 metadata: name: my-service spec: type: ExternalName externalName: my.database.example.com
<a name="EVbrp"></a>
### ExternalIP
- 为Service分配公有IP地址
- 要求ExternalIP必须至少能路由到一个k8s节点
```yaml
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
externalIPs:
- 80.11.12.10
Service调试
- service问题可以分析在宿主机上的iptables规则/ipvs规则得到解决
- 区分是service本身问题还是DNS问题,有效的方法就是检查k8s自己的master节点的ServiceDNS是否正常,如果上述返回值有问题就需要检查kube-dns的状态和日志,否则检查Service的定义 ```shell
在一个Pod里执行
$ nslookup kubernetes.default Server: 10.0.0.10 Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
- service没办法通过ClusterIP访问到的时候,首先检查是否有ep
- Pod没有ready不会出现在ep
- ep正常就需要确认kube-proxy是否在运行
- 如果kube-proxy正常就需要查看iptables规则
- iptables模式的service对应的规则包括如下
- KUBE-SERVICES或KUBE-NODEPORTS规则对应的Service入口链,这个规则与VIP和Service端口对应
- KUBE-SEP-(hash)规则对应的DNAT链,与EP对应
- KUBE-SVC-(hash)规则对应的负载均衡链,数目与EP数目一致
- 如果是NodePort模式的话,还有POSTROUTING处的SNAT链
```shell
$ kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.0.5:9376,10.244.0.6:9376,10.244.0.7:9376
- Pod没办法通过Service访问自己
- kubelet的hairpin-mode没有被正确设置
- 一般设置为hairpin-veth或promiscuous-bridge
```shell
hairpin-veth 模式下应该看到CNI网桥对应的veth设备都设置为1
$ for d in /sys/devices/virtual/net/cni0/brif/veth*/hairpin_mode; do echo “$d = $(cat $d)”; done /sys/devices/virtual/net/cni0/brif/veth4bfbfe74/hairpin_mode = 1 /sys/devices/virtual/net/cni0/brif/vethfc2a18c5/hairpin_mode = 1
promiscuous-bridge模式下看到CNI网桥的混杂模式 (PROMISC)已开启
$ ifconfig cni0 |grep PROMISC UP BROADCAST RUNNING PROMISC MULTICAST MTU:1460 Metric:1
<a name="vqWJ4"></a>
# Service与Ingress
- LoadBalancerService都会调用CloudProvider创建service对应的lb,service越多lb就比较浪费成本也高
- 全局的,为代理不同后端Service而设置的负载均衡服务就是Ingress,可以理解为Service的Service
<a name="TWTpL"></a>
## Ingress
- Ingress就是k8s对反向代理的一种抽象
- 目前ingress只能工作在7层,service只能工作在4层
- 实际使用中需要部署IngressController(nginx/haproxy/envoy/traefik等)来实现Ingress的代理功能
- IngressController根据Ingress里的内容生成对应的配置文件
- 并使用配置文件启动对应的服务
- 持续监听Ingress对象和被代理的后端Service的变化来自动更新服务
- 如果请求没有匹配到任何一个IngressRule
- 默认返回404
- 可以通过Pod的启动命令加上default-backend-service=nginx-default-backend指定兜底的service
- 然后部署一个自定义的404Pod返回自定义404页面
```yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: cafe-ingress
spec:
tls:
- hosts:
- cafe.example.com
secretName: cafe-secret
rules:
- host: cafe.example.com # IngressRule,key是host,值必须是一个标准的域名格式(FullyQualifiedDomainName)的字符串,不能是IP
http:
paths:
- path: /tea
backend:
serviceName: tea-svc
servicePort: 80
- path: /coffee
backend:
serviceName: coffee-svc
servicePort: 80
kind: ConfigMap
apiVersion: v1
metadata:
name: nginx-configuration
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
template:
metadata:
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
annotations:
...
spec:
serviceAccountName: nginx-ingress-serviceaccount
containers:
- name: nginx-ingress-controller
image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.20.0
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
- --publish-service=$(POD_NAMESPACE)/ingress-nginx
- --annotations-prefix=nginx.ingress.kubernetes.io
securityContext:
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
# www-data -> 33
runAsUser: 33
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
- name: http
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
FQDN
- 链接👉FQDN

若有收获,就点个赞吧
0 人点赞
