监控基础
7大作用
- 实时采集监控数据
- 硬件
- 操作系统
- 中间件
- 应用程序
- 实时反馈监控状态
- 数据多维度统计、可视化展示
- 体现监控对象状态是否正常
- 预知故障和告警
- 辅助定位故障
- 辅助性能调优
- 慢SQL
- 响应时间
- 辅助容量规划
-
使用监控系统
了解监控对象的工作原理
- 确定监控对象的指标
- 定义合理的报警阈值和等级
-
监控对象和指标
硬件监控
- 电源状态
- 机器温度
- 风扇状态
- raid状态
- 服务器基础监控
- CPU状态
- 内存状态
- 磁盘状态
- 网络状态
- 数据库监控
- 数据库连接数
- QPS
- TPS
- 缓存命中率
- 主从延时
- 锁状态
- 慢查询
- 中间件
- nginx
- 活跃连接数
- 等待连接数
- 丢弃连接数
- 请求量
- 耗时
- 5xx错误率
- tomcat
- 最大线程数
- 当前线程数
- 请求量
- 耗时
- 堆内存使用
- GC次数和耗时
- 缓存
- 成功连接数
- 阻塞连接数
- 已使用内存
- 内存碎片率
- 缓存命中率
- 消息队列
- 连接数
- 队列数
- 生产速率
- 消费速率
- 消息堆积量
- nginx
- 应用监控
- 数据采集
- 日志埋点(logstash、filebeat)
- JMX标准接口输出
- RESTfulAPI
- 命令行
- 统一SDK
- 数据传输
- TCP/UDP
- HTTP
- pull模式
- push模式
- 数据存储
- RDBMS
- 时序数据库
- HBase
- 数据展示
- 图形化展示
- 监控告警
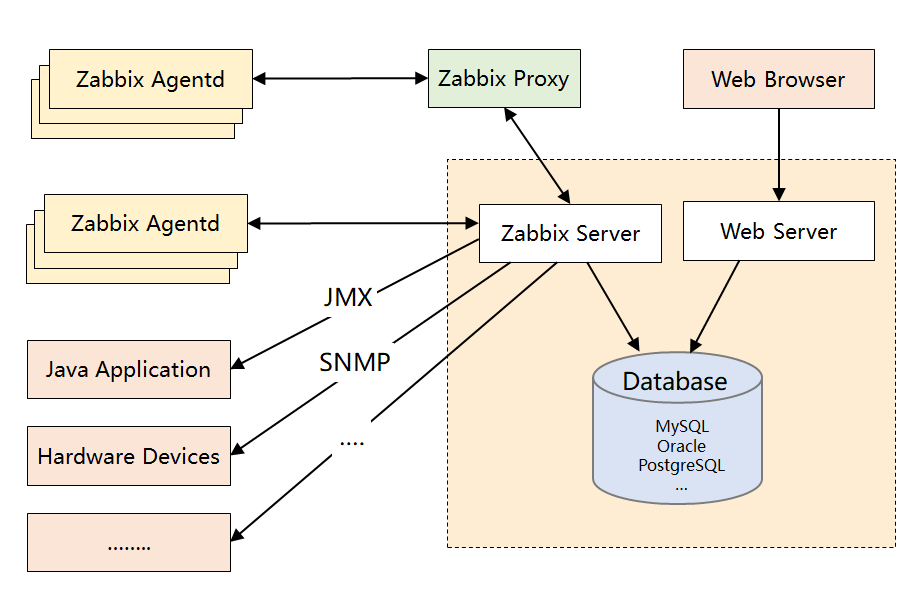
- server
- 核心组件
- 支持接收Agent、Proxy发送的数据
- 也支持JMX、SNMP协议直接采集
- 负责数据的汇总存储、告警出发
- agentd
- 部署在被监控主机上
- 采集数据并发送给proxy或server
- 可以手动部署也可以自动发现机制被识别
- 支持Push/Pull两种模式
- proxy
- 可选组件,在被监控机器比较多的情况下,减轻Server的压力
- Database
- 存储配置信息以及采集到的数据
- 支持RDBMS
- 支持时序数据库
- WebServer
- GUI
- 提供监控数据的展示及告警配置
优势
- 开源、产品成熟
- 采集方式丰富
- 较强的扩展性
-
不足
规模大了之后容易产生性能瓶颈
- 对应用层监控支持有限
- 数据模型不强大,不支持tag、多维度聚合等
-
Open-Falcon
架构
小米出品,国内流行,基于Zabbix转型自研
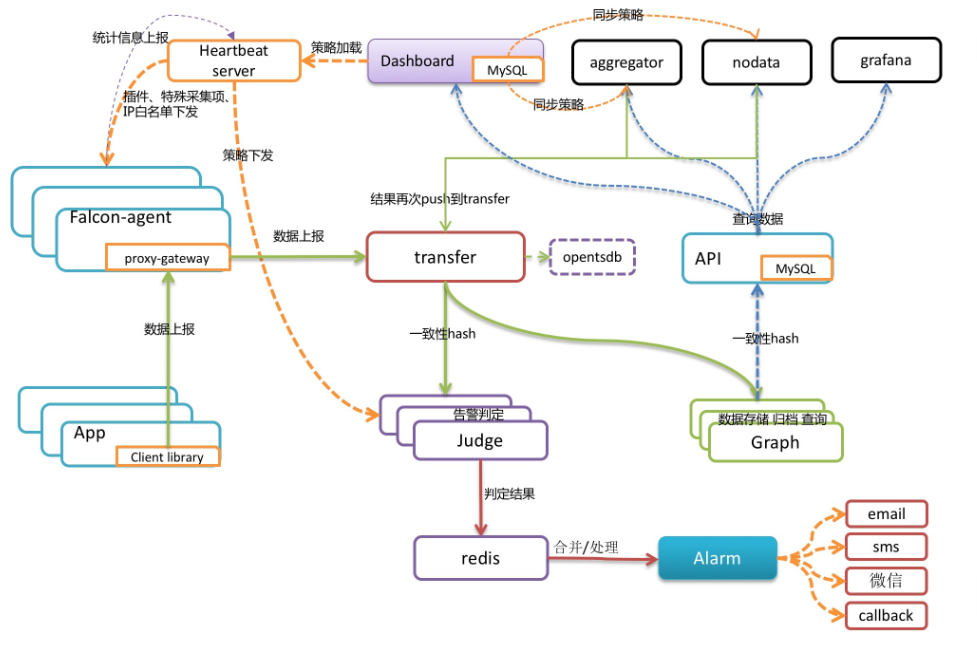
Falcon-agent
- 自动采集单机200多个基础指标,无需配置
- 支持用户自定义plugin扩展
- 自主push数据
- Transfer
- 数据分发组件
- 接收客户端发送的数据,分别发送给Graph和Judge
- Graph
- 数据存储组件
- 通过缓存、分批写入磁盘方式进行优化
- Judge和Alarm
- Judge判断是否要产生告警事件
- Alarm组件对告警事件进行收敛处理后进行推送给消息通道
API
自动采集能力,无需server上配置,这一点可以秒杀zabbix
- 强大的存储能力,通过一致性hash进行数据分片
- 灵活的数据模型,数据模型中引入了tag,支持多维度聚合
- 插件统一管理,通过heartbeatServer分发给agent,减轻了使用者维护成本
个性化监控支持,基于Proxy-gateway,个性化监控集成方便
不足
社区不活跃,版本更新慢
- UI不够友好
- 安装比较复杂
Prometheus
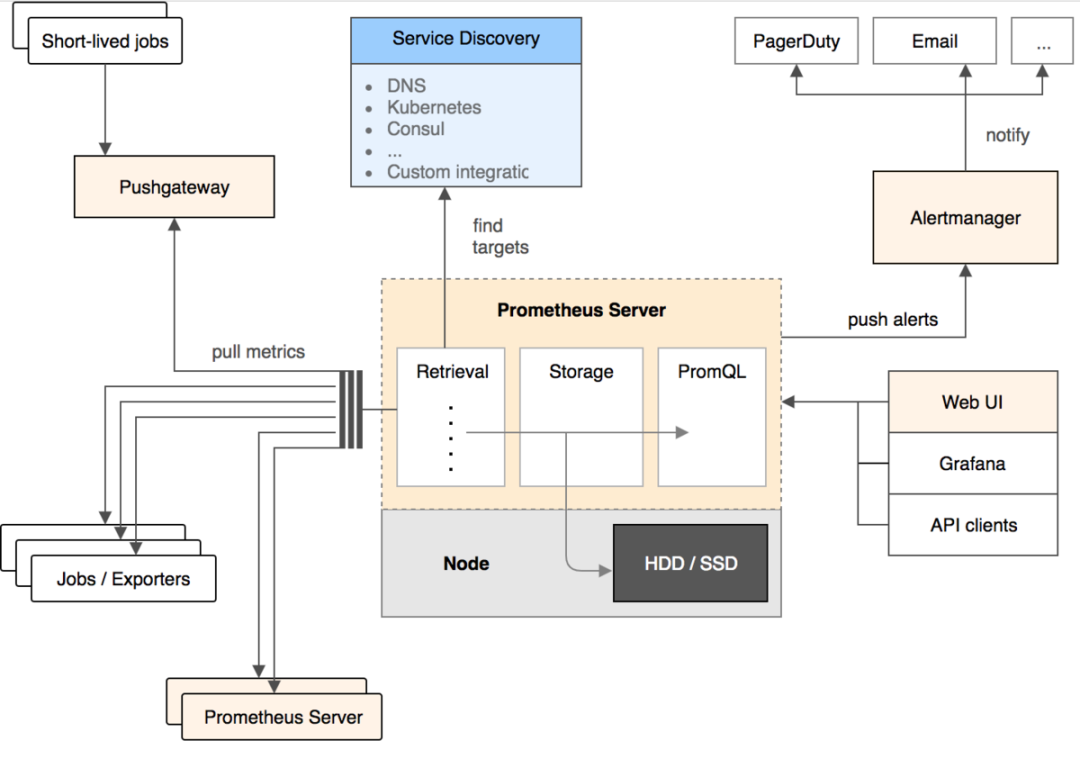
架构
- server
- 用于收集、存储监控数据
- 支持静态配置和通过ServiceDiscovery动态发现来管理监控目标
- 保存数据并提供PromQL进行查询和分析
- Exporter
- 类似于agent
- 基于pull模式采集数据
- 通过HTTP服务的形式暴露数据
- 可自定义clientLibrary自定义实现
- pushGateway
- 防止server来pull数据之前short-lived jobs就已经执行完毕
- job可以采用push 的方式将数据主动上报给pushServer缓存起来
- AlertManager
- 告警产生时,server将告警信息推给AlertManager
- 将告警信息发送给接收方
- WebUI
- 可查询监控指标
- 通常接入Grafana,创建仪表盘及查看指标
优势

若有收获,就点个赞吧
0 人点赞
