资源模型与资源管理
资源模型
- Pod是最小调度单位
- 所有跟调度和资源管理相关的属性都是Pod对象的字段
- 最重要的就是CPU和内存配置
- CPU资源
- 是可压缩资源 compressibleResource,特点是资源不足时,Pod只会饥饿,不会退出
- 设置CPU的单位是CPU的个数,比如cpu=1,当然具体1个CPU在宿主机上如何解释,是1个CPU核心还是1个vCPU,还是1个CPU的超线程Hyperthread,完全取决于宿主机CPU的实现方式,k8s只能保证Pod能够使用1个CPU的计算能力
- 还可将CPU限额设置为分数,比如500m,就是500millicpu,即0.5个CPU
- 推荐使用500m,这是内部通用的CPU表示方式
- 内存资源
- 是不可压缩资源incompressibleResource,特点是资源不足时,Pod会OOM而被内核杀掉
- 单位是bytes,支持使用Ei、Pi、Ti、Gi、Mi、Ki(E、P、T、G、M、K)的方式作为bytes的值
- 1Mi = 1024 1024 ; 1M = 1000 1000 ```yaml
- CPU资源
apiVersion: v1 kind: Pod metadata: name: frontend spec: containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD value: “password” resources: requests: memory: “64Mi” cpu: “250m” limits: memory: “128Mi” cpu: “500m”
- name: wp
image: wordpress
resources:
requests:
limits:memory: "64Mi"cpu: "250m"
```memory: "128Mi" cpu: "500m"
- QoS模型
- Guaranteed
- pod里的每一个容器都同时设置了requests和limits,并且两者相等
- pod仅设置了limits没有设置requests的时候,k8s会自动为它设置与limits相同的requests值
- pod创建后,它的qosClass字段就被设置为Guaranteed
- DaemonSet的Pod应该都设置为此类型,否则一旦被驱逐,又在当前宿主机重建,失去回收的意义 ```yaml
- Guaranteed
apiVersion: v1 kind: Pod metadata: name: qos-demo namespace: qos-example spec: containers:
name: qos-demo-ctr image: nginx resources: limits:
memory: "200Mi" cpu: "700m"requests:
memory: "200Mi" cpu: "700m"```
- Burstable
- pod不满足Guaranteed条件,但至少有一个容器设置了requests ```yaml
- Burstable
apiVersion: v1 kind: Pod metadata: name: qos-demo-2 namespace: qos-example spec: containers:
name: qos-demo-2-ctr image: nginx resources: limits
memory: "200Mi"requests:
memory: "100Mi"```
- BestEffort
- pod即没有设置requests,也没有设置limits ```yaml
- BestEffort
apiVersion: v1 kind: Pod metadata: name: qos-demo-3 namespace: qos-example spec: containers:
- name: qos-demo-3-ctr image: nginx ```
- QoS模型作用
自定义配置
kubelet —eviction-hard=imagefs.available<10%,memory.available<500Mi,nodefs.available<5%,nodefs.inodesFree<5% —eviction-soft=imagefs.available<30%,nodefs.available<10% —eviction-soft-grace-period=imagefs.available=2m,nodefs.available=2m —eviction-max-pod-grace-period=600
- Eviction两种模式
- Soft
- 允许为Eviction过程设置一段“优雅时间”
- Hard
- Eviction在阈值到达后立刻开始
- 当宿主机的Eviction阈值达到后,就会进入MemoryPressure或DiskPressure状态,防止新的Pod调度进来
- 当Eviction发生的时候,kubelet就会根据QoS挑选Pod进行驱逐
- 首先驱逐BestEffort类别的Pod
- 其次驱逐Burstable类别,并且发生“饥饿”的资源使用量已经超出requests的Pod
- 最后驱逐Guaranteed类别,并且只在资源使用量超过limits限制或宿主机处于MemoryPressure状态时才会驱逐Guaranteed类别的Pod
- 当然对于同类别的Pod,还会有优先级进一步排序
<a name="rOJnS"></a>
## 资源管理
- requests
- 在kube-scheduler调度时,按照requests值进行计算,通过cpu.shares完成CPU时间按比例分配
- requests.cpu=250m相当于cgroups的cpu.shares的值设置为250 / 1000 * 1024
- 没有设置requests.cpu时,cpu.shares的值默认为1024,即requests.cpu默认为1000m
- limits
- 在设置cgroups限制时,kubelet会按照limits值进行设置
- 指定了limits.cpu=500m后相当于cgroups的cpu.cfs_quota_us的值设置为 500 /1000 * 1024
- cpu.cfs_period_us的值始终是100ms,这样就设置了这个容器只能用到 CPU的 50%
- 指定了limits.memory=128Mi后相当于cgroups的memory.limit_in_bytes设置 128 * 1024 * 1024
- cpuset
- 使用cpuset把容器绑定到某个CPU和核上,避免使用cpushare共享的CPU
- 绑定后大大减少cs,性能会得到显著提升
- 生产环境部署在线应用类型的Pod时非常常用的方式
- 实现方式
- Pod必须是Guaranteed的QoS类型
- 将Pod的CPU资源的requests和limits设置为同一个相等的整数值,pod就会独占对应数量的CPU核
```yaml
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "200Mi"
cpu: "2"
默认调度器
defaultScheduler
- kube-scheduler
- 主要职责就是为一个新创建的Pod,寻找一个最合适的节点Node
- 从集群所有节点中,根据调度算法挑选出所有可以运行该Pod的Node
- 从第一步的结果中,再根据调度算法挑选一个最合适的节点作为最终结果
- 调度过程
- 首先调用Predicate的调度算法筛选Node
- 再调用Priority的调度算法打分
- 最终的调度结果就是得分最高的那个Node
- 调度成功的标志就是将它的spec.nodeName字段填上调度结果的Node名字
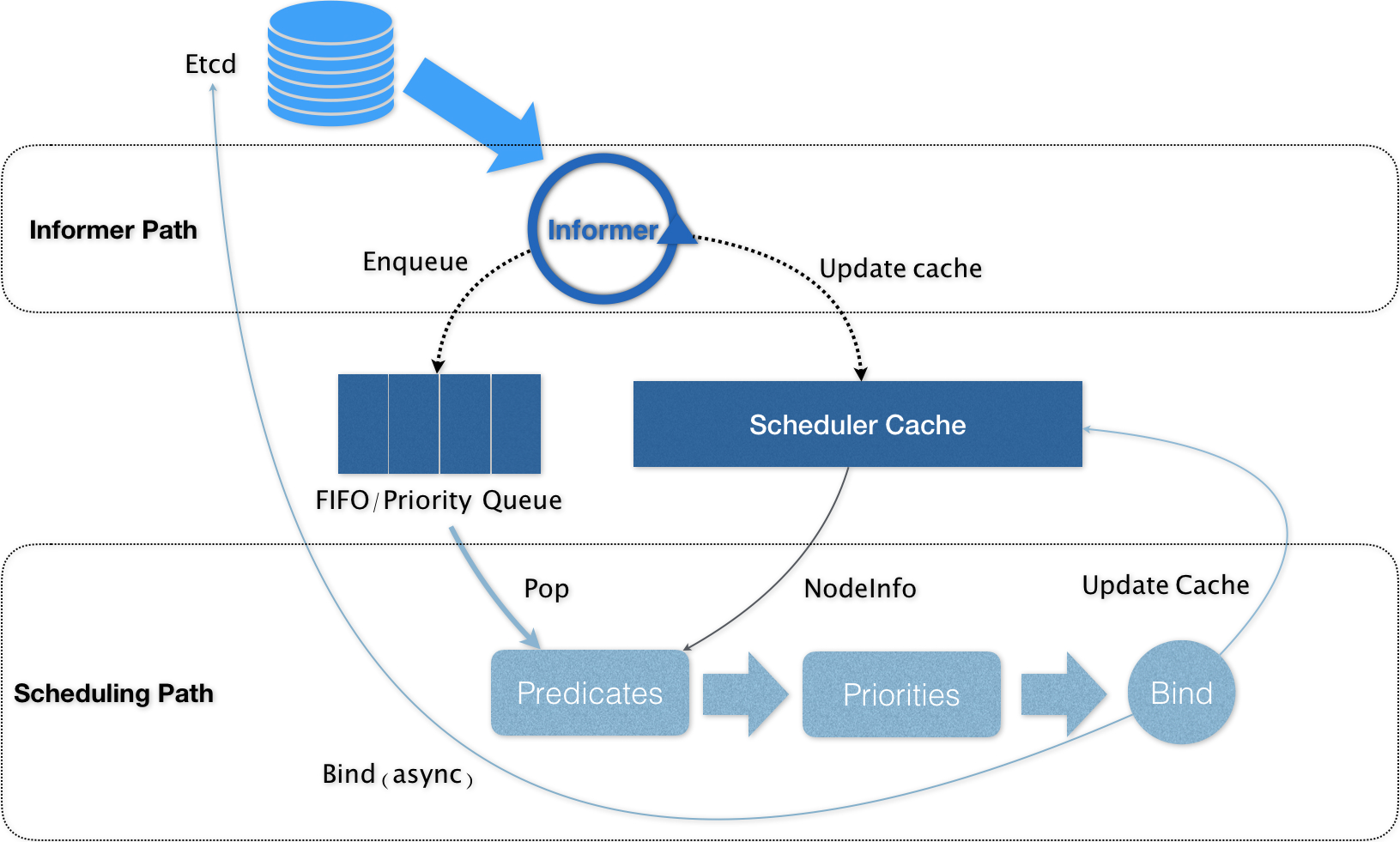
- 工作原理
- 核心是两个相互独立的控制循环
- InformerPath
- 启动一系列Informer,watch Etcd中的Pod、Node、Service等对象的变化
- 当一个待调度的Pod被创建出来后,调度器就会通过Pod Informer的Handler 将这个Pod添加调度队列
- 默认情况下调度队列是一个PriorityQueue(优先级队列)
- 默认调度器还要负责对调度器缓存 SchedulerCache 进行更新,Cache保证算法效率,但也要更新
- SchedulingPath(调度器负责调度的主循环)
- 不断从调度队列出队一个Pod
- 调用Predicates算法进行过滤,得到一组可以运行的Node列表
- 调用Priority算法进行打分,从0到10,得分最高的Node作为结果
- 把结果写入Pod.nodeName字段完成Bind
- 为了不在关键调度路径里远程访问APIServer,默认调度器在Bind阶段只会更新SchedulerCache里的Pod和Node信息,这种基于乐观假设的API更新方式被称作 Assume
- Assume后调度器才会创建一个goroutine来异步向APIServer更新Pod完成真正的Bind,如果失败了也没关系,等SchedulerCache同步之后一切就会恢复正常
- 基于乐观绑定的Assume的设计,一个新的Pod在某个节点上运行起来之前,该节点的kubelet还会通过Admit的操作来再次验证该Pod确实能够运行在该节点
- Admit操作就是把一组GeneralPredicates的、最基本的调度算法(资源是否可用,端口是否冲突)等再执行一遍,作为kubelet端的二次确认
- InformerPath
- 除了Cache化和乐观绑定Assume,默认调度器还有一个重要的设计就是无锁化
- predicates算法阶段会以节点为粒度并发执行
- priorities算法会以MapReduce方式并行计算然后汇总
- 所有并发的路径上,调度器都会避免设置任何全局的竞争资源,从而避免使用锁
- 只有在对调度队列和SchedulerCache进行操作时才会需要锁
- 核心是两个相互独立的控制循环
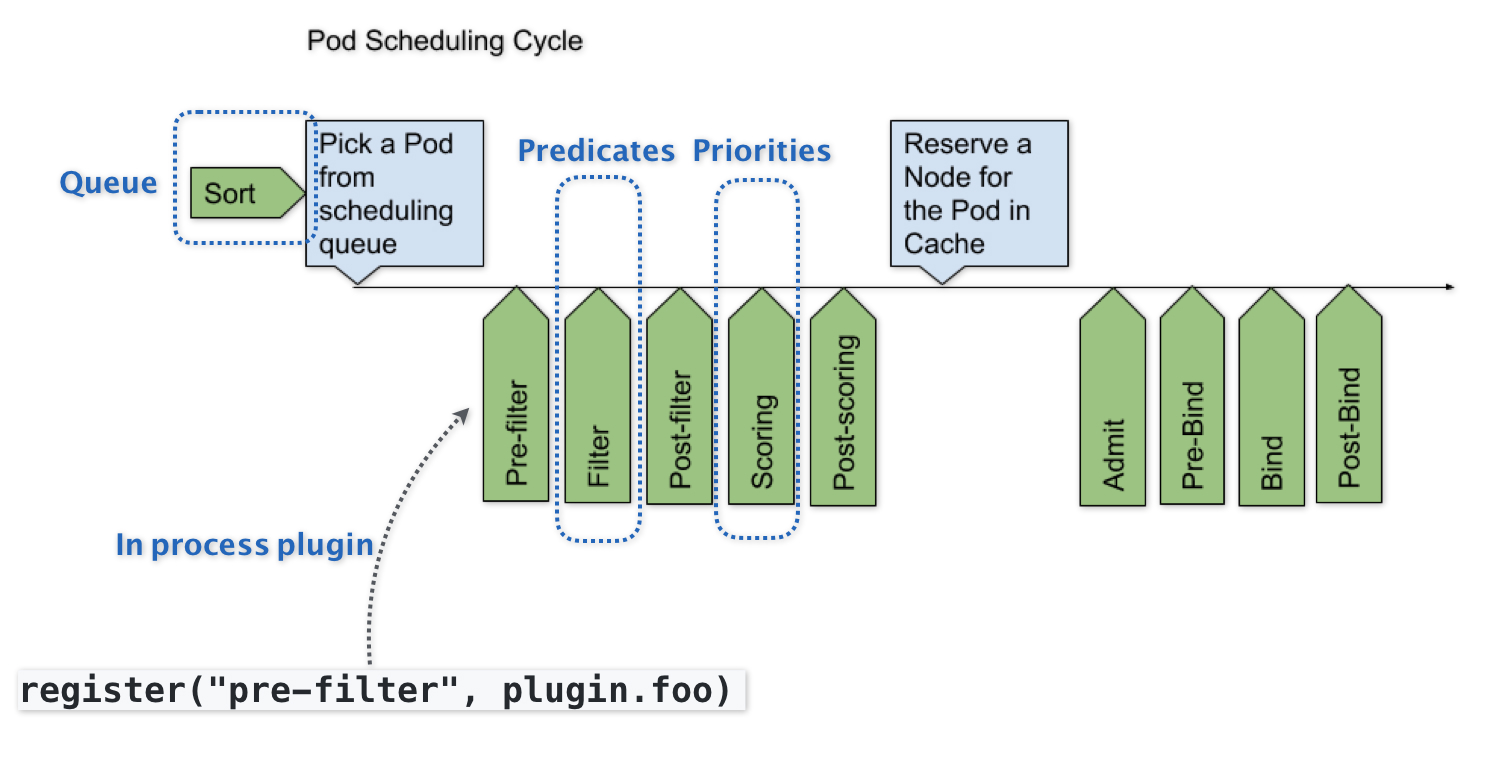
可扩展性设计
- SchedulerFramework在生命周期的各个关键点上,为用户暴露出可进行扩展和实现的接口,从而实现自定义
- 可插拔式的逻辑都是标准的Go语言插件机制(Go plugin机制),需要在编译时把插件编译进去
- 实现自定义的kube-scheduler
默认调度策略
Predicates
- 可以理解为Filter
- 按照调度策略,从当前集群的所有节点,过滤出符合条件的节点,都可以运行待调度的Pod
- 具体执行时,调度器会同时启动16个goroutine,并发为所有node计算predicates,最后返回一个列表
- 默认调度策略分四种
- GeneralPredicates
- 负责最基础的调度策略
- PodFitsResources计算的就是宿主机CPU和内存是否够用,把除了CPU和内存之外的资源统一用名叫ExtendedResource的KV格式的扩展字段来描述
- PodFitsHost检查宿主机的名字是否跟Pod的spec.nodeName一致
- PodFitsHostPorts检查Pod申请的主机端口spec.nodePort是否有冲突
- PodMatchNodeSelector检查的是Pod的nodeSelector或nodeAffinity指定的节点是否匹配待考察节点
- GeneralPredicates也会被其他组件直接调用,就是因为它是最基本的过滤条件
- Node在启动Pod前会进行Admit也会调用GeneralPredicates ```yaml
- GeneralPredicates
apiVersion: v1 kind: Pod metadata: name: extended-resource-demo spec: containers:
name: extended-resource-demo-ctr image: nginx resources: requests:
alpha.kubernetes.io/nvidia-gpu: 2 # 声明使用2个NVIDIA类型的GPUlimits:
alpha.kubernetes.io/nvidia-gpu: 2```
- Volume相关的过滤规则
- 跟容器持久化Volume相关的调度策略
- NoDiskConflict检查的是多个Pod声明挂载的PV是否有冲突
- MaxPDVolumeCountPredicate检查的是一个节点上某种类型的PV是不是已经超过了一定数目
- VolumeZonePredicates检查PV的Zone标签是否与待考察节点的Zone标签匹配
- VolumeBindingPredicate检查该Pod对应的PV的nodeAffinity是否跟节点标签匹配
- 宿主机相关的过滤规则
- 主要考察待调度Pod是否满足Node本身的某些条件
- PodToleratesNodeTaints,只有toleration与node的Taint字段匹配时才能调度
- NodeMemoryPressurePredicate检查当前节点的内存是否已经不够用
- Pod相关的过滤规则
- 与GeneralPredicates大多数是重合的
- 比较特殊的是PodAffinityPredicate是检查待调度Pod与Node上的已有Pod之间的affinity和anti-affinity
- PodAffinityPredicate是有作用域的,通过topologyKey指定 ```yaml
- Volume相关的过滤规则
apiVersion: v1 kind: Pod metadata: name: with-pod-antiaffinity spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: # 调度时检查,已经运行的变化后忽略
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2 # 不希望跟任何携带了security=S2的Pod存在于同一个Node上
topologyKey: kubernetes.io/hostname # 作用域
containers:
- 完成了预选后,priorities就是为节点打分(0-10),得分最高的节点就是最后被Pod绑定的节点
- 打分规则
- LeastRequestedPriority,最常用的打分规则,实际上实在选择空闲资源最多的宿主机 ```yaml
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2
- BalancedResourceAllocation 选择调度完成后所有节点里各种资源分配最均衡的节点,避免一个节点上CPU被大量分配,Memory大量剩余
```yaml
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10
# 每种资源的Fraction = Pod请求的资源 / 节点上的可用资源
# variance算法计算两种资源Fraction之间的距离,最后选择资源Fraction差距最小的节点
- 调度策略可以由kube-scheduler指定的配置文件或CM配置哪些开启,哪些关闭
- 可为Priorities设置权重,控制调度器的调度行为
调度器再执行调度算法之前可能先将集群的信息初步计算一遍,然后缓存起来,提高效率
调度器的优先级与抢占机制
-
Priority优先级
PriorityClass对象
- k8s规定 优先级是一个32bit的整数,最大值不超过10亿,并且值越大代表优先级越高
- 超过10亿的值被保留下来分配给系统Pod使用,保证系统Pod不会被用户抢占掉
- globalDefault
- 被设置为true的话就意味着这个PriorityClass的值会成为系统的默认值
- 被设置为false表示只希望使用该PriorityClass的Pod有此优先级
- 没有声明使用PriorityClass的Pod默认的优先级就是0
- 优先级的值会被设置的Pod.spec.priority字段
- 高优先级的Pod在调度队列里会比低优先级的Pod提前出队,尽早完成调度过程 ```yaml
apiVersion: scheduling.k8s.io/v1beta1 kind: PriorityClass metadata: name: high-priority value: 1000000 globalDefault: false description: “This priority class should be used for high priority service pods only.”
```yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
Preemption抢占机制
- 当一个高优先级的Pod调度失败时,调度器的抢占能力就会被触发
- 调度器就会试图从当前集群里寻找一个节点,使得当这个节点上一个或者多个低优先级Pod被删除后,待调度的高优先级的Pod可以被调度进来,实现抢占
- 待调度的高优先级的Pod是抢占者 Preemptor
- 调度器只会将抢占者的spec.nominatedNodeName字段设置为被抢占的Node的名字
- 抢占者会重新进入下一个调度周期,在新的周期里决定是否要运行在被抢占的节点上
- 调度器只会通过标准的DELETE API来删除被抢占的Pod,有一个优雅退出的时间,默认30s
- 在抢占者等待被调度的过程中,如果有其他更高优先级的Pod也要抢占同一个节点,调度器会清空原抢占者的spec.nominatedNodeName字段,允许更高优先级的Preemptor执行抢占,本身也有机会抢占其他节点
- 原理
- 发生的原因一定是一个高优先级的Pod调度失败
- 这个Pod就是抢占者Preemptor,被抢占的Pod是牺牲者 victims
- 实现抢占算法的设计就是在调度队列里使用了两个不同的队列
- activeQ 存放下一个调度周期需要调度的对象
- unschedulableQ 专门存放调度失败的Pod
- 调度失败后抢占者就被放进unschedulableQ里,这次失败事就会触发调度器为抢占者寻找牺牲者的流程
- 调度器检查这次失败事件的原因,来确认是否可以通过抢占来解决
- 如果抢占可以解决问题就把自己缓存的所有节点的信息复制一份,然后使用这个信息模拟抢占过程
- 模拟抢占过程结束后找到最佳结果(尽量减少抢占对整个系统的影响)包括Node和Pod
- 接下来进行抢占,分三步
- 检查牺牲者列表,清理这些Pod携带的nominatedNodeName字段
- 把抢占者的nominatedNodeName字段设置为被抢占Node的名字,这一步就会更新unschedulableQ里的Pod,而其更新后,调度器会自动把这个Pod移动到activeQ里,重新做人
- 调度器开启一个goroutine,同步地删除牺牲者
因为有抢占的存在,在一个正常的调度过程中,有特殊情况需要处理
硬件加速需求需要提供
- GPU设备,比如/dev/nvidia0
- GPU驱动,比如/usr/local/nvidia/*
- CRI
- 容器启动时可以指定Device参数来设置为GPU设备
- 驱动目录可以通过Volume挂载进去
- API对象
- ExtendedResource,是k8s为用户设置的一种对自定义资源的支持 ```yaml
apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers:
- name: cuda-vector-add
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
- Node对象
- 必须向APIServer上报资源信息
- 为了能在Status字段里添加自定义资源的数据,必须使用PATCH API对Node更新
- PATCH API可以使用curl命令发起,如下所示
apiVersion: v1 kind: Node metadata: name: node-1 … Status: Capacity: cpu: 2 memory: 2049008Ki
```shell
# 启动 Kubernetes 的客户端 proxy,这样你就可以直接使用 curl 来跟 Kubernetes 的API Server 进行交互了
$ kubectl proxy
# 执行 PACTH 操作
$ curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/nvidia.com/gpu", "value": "1"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
apiVersion: v1
kind: Node
...
Status:
Capacity:
cpu: 2
memory: 2049008Ki
nvidia.com/gpu: 1
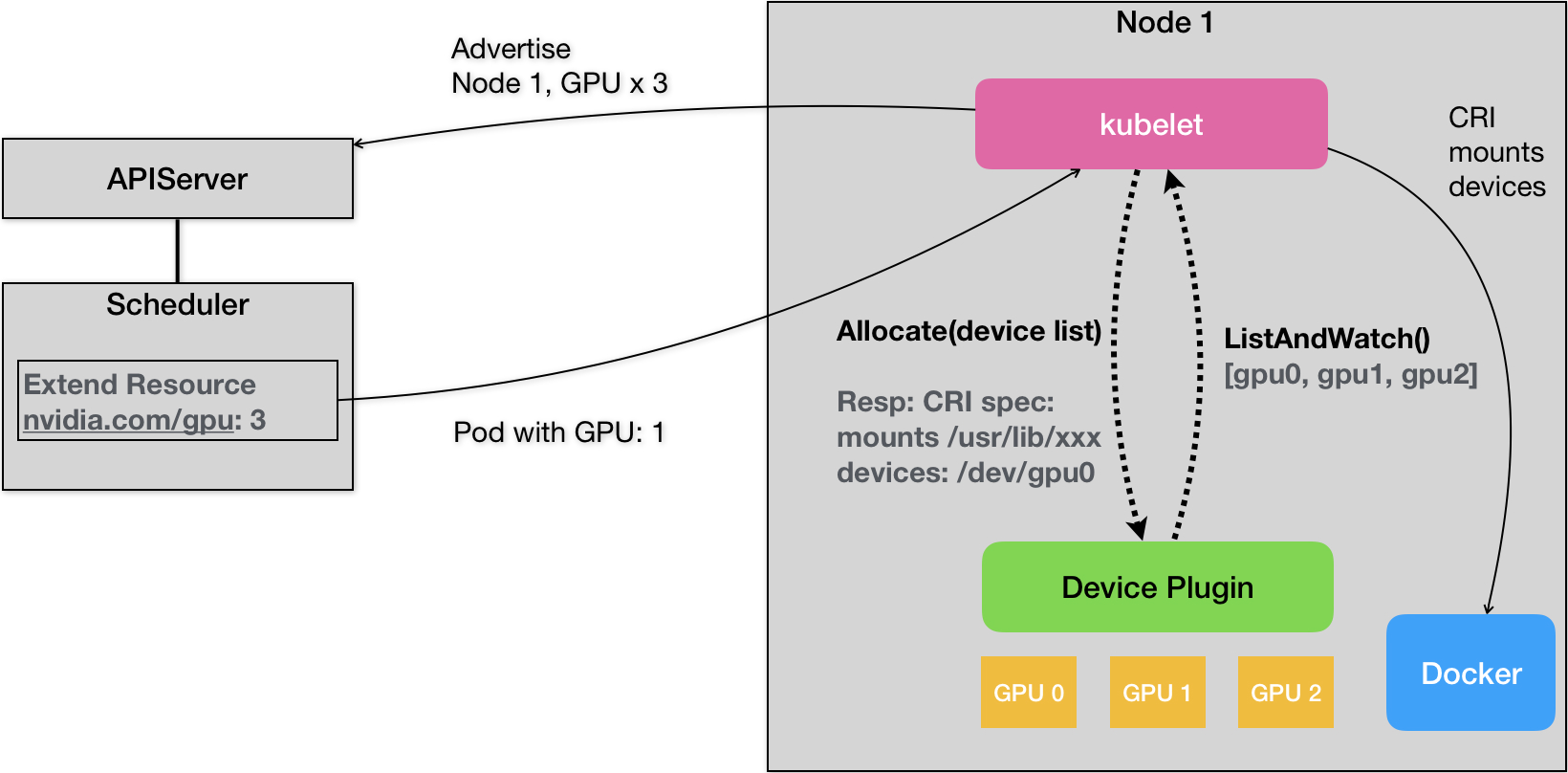
DevicePlugin
- 机制
- 每一种硬件设备,都需要对应的DevicePlugin管理
- DP通过gRPC方式同kubelet连接起来
- DP通过ListAndWatch的API定期向kubelet汇报Device信息(GPU的ID列表)
- kubelet拿到信息后向APIServer发送心跳(以ER的方式,加上对应的数量比如nvidia.com/gpu=3)
- 当一个Pod想要使用一个GPU时,在Podlimits字段进行声明 nvidia.com/gpu=1
- 调度器从缓存里寻找GPU数量满足条件的Node,然后将缓存里的GPU数量减1,完成Pod与Node绑定
- 这个调度成功的Pod信息就会被对应的kubelet拿来进行容器操作,发现需要1个GPU时,kubelet就会从自己持有的GPU列表里分配一个GPU,kubelet向本机的DP发起一个Allocate(),参数就是设备ID列表
- DP收到请求后找到对应的设备路径和驱动目录返回给kubelet
- kubelet把这些信息追加在创建该容器所对应的CRI请求当中,这样这个CRI发给docker后,创建出来的容器就包含这个设备和对应的驱动目录

若有收获,就点个赞吧
0 人点赞
