1、详细步骤
1、client执行系统调用connect()发送syn(初始序列号为seq=x,随机生成)至server以请求建立一个连接,此时连接状态变为SYN_SEND,并等待server的SYN+ACK。
如果client在一段时间后没有收到server返回的SYN+ACK,则重新发送,重新发送的次数默认是5次(参数tcp_syn_retries)。
第一次超时重传是在 1 秒后,第二次超时重传是在 2 秒,第三次超时重传是在 4 秒后,第四次超时重传是在 8 秒后,第五次是在超时重传 16 秒后。每次超时的时间是上一次的 2 倍。当第五次超时重传后,会继续等待 32 秒,如果仍然服务端没有回应 ACK,客户端就会终止三次握手,连接被放弃。
| tcp_syn_retries | timeout |
|---|---|
| 1 | min(so_sndtimeo,3s) |
| 2 | min(so_sndtimeo,7s) |
| 3 | min(so_sndtimeo,15s) |
| 4 | min(so_sndtimeo,31s) |
| 5 | min(so_sndtimeo,63s) |
所以,总耗时是 1+2+4+8+16+32=63 秒,大约 1 分钟左右。
根据网络的稳定性和目标服务器的繁忙程度修改 SYN 的重传次数,内网情况下,可以适当调低重试次数,尽快把错误暴露给应用程序。建议改为3.
2、server收到client发来的syn后,server状态就会由listen()变为SYN-RCVD。
进入SYN-RCVD状态后,开始检查syns queue半连接队列是否达到阈值。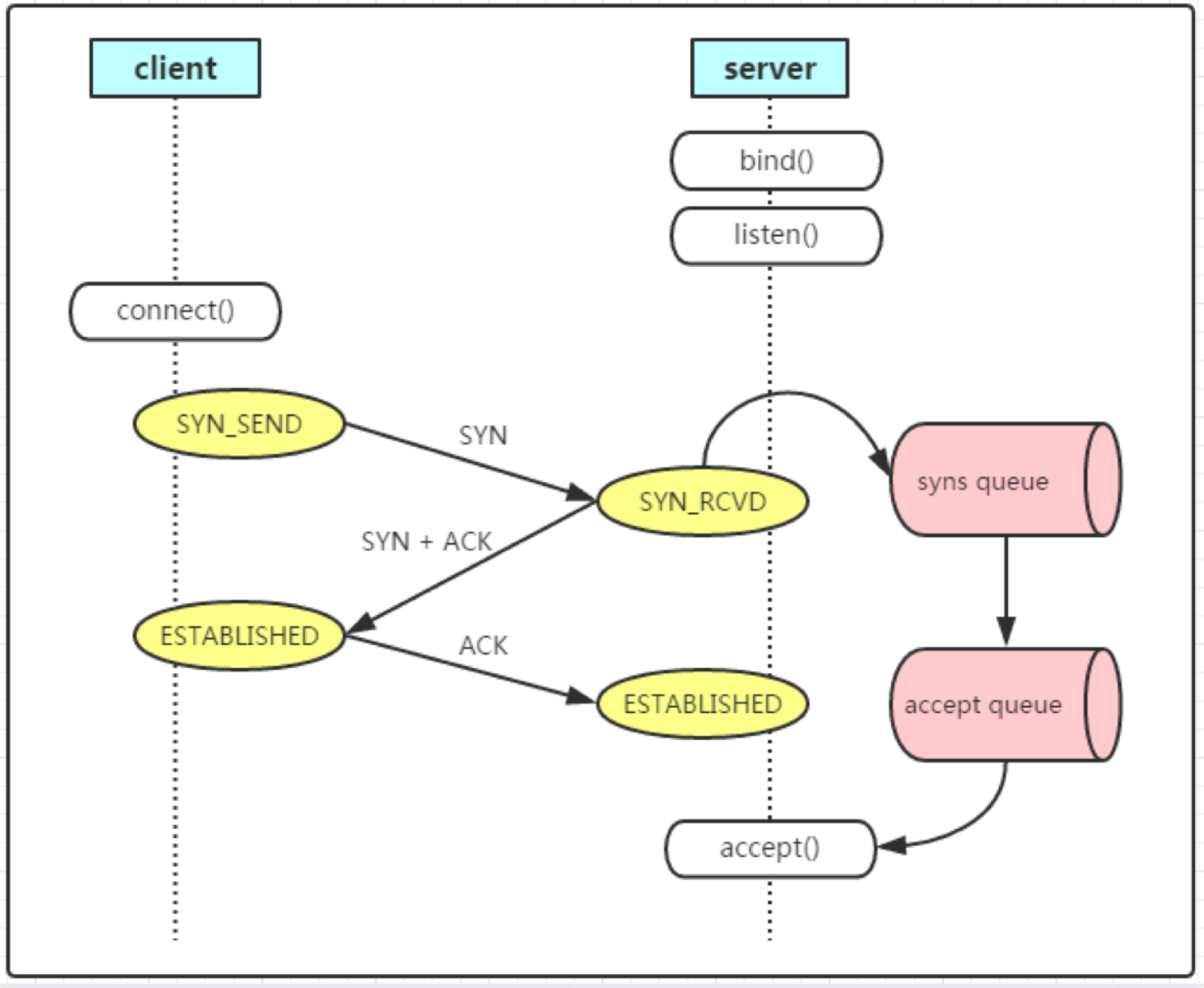
这个阈值取决于min(backlog, net.core.somaxconn, net.ipv4.tcp_max_syn_backlog)。
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp_max_syn_backlog. When syncookies are enabled there is no logical maximum length and this setting is ignored. See tcp(7) for more information. If the backlog argument is greater than the value in /proc/sys/net/core/somaxconn, then it is silently truncated to that value; the default value in this file is 128. In kernels before 2.4.25, this limit was a hard coded value, SOMAXCONN, with the value 128.
其中的backlog是在socket创建的时候传入的,这个值取决于处理请求的后端是什么web服务。一般这个值都web服务都有一个默认值。这里的backlog同时指定了 socket 的 syn queue 与 accept queue 大小。
int listen(int sockfd, int backlog)
如果是nginx,backlog参数默认是511;你可以在nginx配置文件的server块下修改下它
backlog=number
sets thebacklogparameter in thelisten()call that limits the maximum length for the queue of pending connections. By default,backlogis set to -1 on FreeBSD, DragonFly BSD, and macOS, and to **511 **on other platforms.
参见nginx官网:ngx_http_core_module
tomcat和apache也是511
- PHP的Backlog是128
- Java默认的Backlog是50
net.core.somaxconn是系统级别的一个端口能监听的最大连接数。 它的默认值只有128.
一般来说你应该提高通过修改内核参数来提高它。注意别只是修改虚拟机上的,docker容器里面的值也应该修改。因为这个值是按网络命名空间来注册的。
建议/proc/sys/inet/ipv4/tcp_max_syn_backlog 和 /proc/sys/net/core/somaxconn 调整为2048以上
The “net/core” subsys is registered per network namespace. And the initial value for somaxconn is set to 128.
/ Maximum queue length specifiable by listen. /
#define SOMAXCONN 128
如果半连接队列中的syn达到了计算出来的阈值,则丢弃此syn,并将 ListenDrops 计数器 +1。
ListenDrops 数量可通过netstat -s或netstat -az查看。
$ netstat -s | grep -E 'overflow|drop'12178939 times the listen queue of a socket overflowed12247395 SYNs to LISTEN sockets dropped
$ nstat -az | grep -E 'TcpExtListenOverflows|TcpExtListenDrops'TcpExtListenOverflows 12178939 0.0TcpExtListenDrops 12247395 0.0
如果内核启用了 syncookies,即 net.ipv4.tcp_syncookies=1时, syn queue半连接队列的大小没有限制。
也就是说当syn queue 满了,此时server 还是可以继续接收 SYN 包并回复 SYN+ACK 给 client,只是不会存入 syn queue 了。因为会利用一套巧妙的 syncookies 算法机制生成隐藏信息写入响应的 SYN+ACK 包中,等 client 回 ACK 时,server 再利用 syncookies 算法校验报文,校验通过后三次握手就顺利完成了。所以如果启用了 syncookies,syn queue 的逻辑大小是没有限制的。
syncookies 通常都是启用了的,所以一般不用担心 syn queue 满了导致丢包。syncookies 是为了防止 SYN Flood 攻击,攻击原理就是 client 不断发 SYN 包但不回最后的 ACK,填满 server 的 syn queue 从而无法建立新连接,导致 server 拒绝服务。
如何检测 SYN 攻击 服务器上有大量的半连接状态,且源IP地址是随机的 netstat -na TCP | grep SYN_RECV
减轻SYN flood的办法 SYN攻击不能完全被阻止,除非将TCP协议重新设计。1、缩短超时(SYN Timeout)时间
2、增加最大半连接数
3、无效连接的监视释放: 监视系统的半开连接和不活动连接,当达到一定阈值时拆除这些连接,从而释放系统资源。这种方法对于所有的连接一视同仁,而且由于SYN Flood造成的半开连接数量很大,正常连接请求也被淹没在其中被这种方式误释放掉,因此这种方法属于入门级的SYN Flood方法。4、延缓TCB(ransmission Control Block)分配 消耗服务器资源主要是因为当SYN数据报文一到达,系统立即分配TCB,从而占用了资源。而SYN Flood由于很难建立起正常连接,因此,当正常连接建立起来后再分配TCB则可以有效地减轻服务器资源的消耗。
常见的方法是使用Syn Cache和Syn Cookie技术。
5、Syn Cache 在收到一个SYN报文时,在一个专用HASH表中保存这种半连接信息,直到收到正确的回应ACK报文再分配TCB。这个开销远小于TCB的开销。当然还需要保存序列号。
6、Syn Cookie Syn Cookie技术则完全不使用任何存储资源,这种方法比较巧妙,它使用一种特殊的算法生成Sequence Number,这种算法考虑到了对方的IP、端口、己方IP、端口的固定信息,以及对方无法知道而己方比较固定的一些信息,如MSS、时间等,在收到对方 的ACK报文后,重新计算一遍,看其是否与对方回应报文中的(Sequence Number-1)相同,从而决定是否分配TCB资源。
7、使用SYN Proxy防火墙 一种方式是防止墙dqywb连接的有效性后,防火墙才会向内部服务器发起SYN请求。防火墙代服务器发出的SYN ACK包使用的序列号为c, 而真正的服务器回应的序列号为c’, 这样,在每个数据报文经过防火墙的时候进行序列号的修改。 另一种方式是防火墙确定了连接的安全后,会发出一个safe reset命令,client会进行重新连接,这时出现的syn报文会直接放行。这样不需要修改序列号了。但是,client需要发起两次握手过程,因此建立连接的时间将会延长。
4.3 及其之前版本的内核,syn queue 的大小计算方式跟现在新版内核这里还不一样,详细请参考 commit ef547f2ac16b
如果队列没有达到阈值,则将这个连接放入这个半连接队列,只要进入队列,就同时向client发送ACK+SYN(seq=y,y为随机生成,ACK=x+1,1是回复报文的大小)。并等待client回复一个ACK。
与客户端重传SYN类似,如果服务端一直没有没有收到客户端的ACK确认,这个时候这个连接既没建立起来,也不能算失败。这就需要一个超时时间让Server将这个连接断开,否则这个连接就会一直占用Server的SYN连接队列中的一个位置,大量这样的连接就会将Server的SYN连接队列耗尽,让正常的连接无法得到处理。
服务器端重新发送ACK+SYN的次数默认是5(tcp_synack_retries)。重试的间隔时间从1s开始,下次的重试间隔时间是前一次的双倍,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s, 总共31s, 称为指数退避,第5次发出后还要等32s才知道第5次也超时了,因此如果在1s + 2s + 4s+ 8s+ 16s + 32s = 63s后还没有收到cleint的ACK回复,server会断开这个连接。
由于SYN超时需要63秒,那么就给攻击者一个攻击服务器的机会,攻击者在短时间内发送大量的SYN包给Server(俗称 SYN flood 攻击),用于耗尽Server的SYN队列。对于应对SYN 过多的问题,linux提供了几个TCP参数:tcp_syncookies、tcp_synack_retries、tcp_max_syn_backlog、tcp_abort_on_overflow 来调整应对。

3、client接收到server发过来的syn+ack,此时client单方面认为连接进入ESTABLISHED状态。同时向server发送ACK。
server接收后,检查accept queue全连接队列是否达到阈值。
取决于min(backlog,** **net.core.somaxconn)。
如上所述,这里的backlog与syn queue半连接队列的backlog一样,都是在socket创建的时候传入的。
如果没满则进入队列,server由SYN_RECV变为ESTABLISHED状态,之后就等待应用程序调用accept()来对请求进行处理,拿走全连接队列中的请求。
如果进程不能及时地调用 accept 函数,就会造成 accept 队列溢出。此时则按照tcp_abort_on_overflow的指示进行。
如果tcp_abort_on_overflow的值是默认值0,那么server会丢掉client 发过来的ack,并将 ListenOverflows 和 ListenDrops 计数器 +1。此时客户端会显示read timeout。
对于低版本内核,当 accept queue 满了,并不会完全丢弃 SYN 包,而是对 SYN 限速。把内核源码切到 3.10 版本,看 net/ipv4/tcp_ipv4.c 中 tcp_v4_conn_request 函数: / Accept backlog is full. If we have already queued enough
of warm entries in syn queue, drop request. It is better than
clogging syn queue with openreqs with exponentially increasing
timeout.
*/
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
} 其中 inet_csk_reqsk_queue_young(sk) > 1 的条件实际就是用于限速,仿佛在对 client 说: 哥们,你慢点!我的 accept queue 都满了,即便咱们握手成功,连接也可能放不进去呀。
如何验证 accept queue 满了呢?可以在容器的 netns 中执行 ss -lnt 看下:(netstat -tn 看到的 Recv-Q 跟全连接半连接没有关系)
$ ss -lntState Recv-Q Send-Q Local Address:Port Peer Address:PortLISTEN 129 128 *:80 *:*
server丢弃的ack数量,也就是全连接队列的溢出数据可以你通过 netstat -as查看:
通过这条命令我们可以看到当前 netns 中监听 tcp 80 端口的 socket,Send-Q 为 128,Recv-Q 为 129。
什么意思呢?通过调研得知:
- 对于 LISTEN 状态,Send-Q 表示 accept queue 的最大限制大小,Recv-Q 表示其实际大小。
- 对于 ESTABELISHED 状态,Send-Q 和 Recv-Q 分别表示发送和接收数据包的 buffer。
所以,看这里输出结果可以得知 accept queue 满了,当 Recv-Q 的值比 Send-Q 大 1 时表明 accept queue 溢出了,如果再收到 SYN 包就会丢弃掉。
导致 accept queue 满的原因一般都是因为进程调用 accept() 太慢了,导致大量连接不能被及时 “拿走”。
那么什么情况下进程调用 accept() 会很慢呢?猜测可能是进程连接负载高,处理不过来。
而负载高不仅可能是 CPU 繁忙导致,还可能是 IO 慢导致,当文件 IO 慢时就会有很多 IO WAIT,在 IO WAIT 时虽然 CPU 不怎么干活,但也会占据 CPU 时间片,影响 CPU 干其它活。
最终进一步定位发现是 nginx pod 挂载的 nfs 服务对应的 nfs server 负载较高,导致 IO 延时较大,从而使 nginx 调用 accept() 变慢,accept queue 溢出,使得大量代理静态图片文件的请求被丢弃,也就导致很多图片加载不出来。
如果tcp_abort_on_overflow的值是1,server发送一个reset包给client,表示废掉这个握手过程和这个连接(本来在server端这个连接就还没建立起来)。客户端异常会显示connection reset by peer。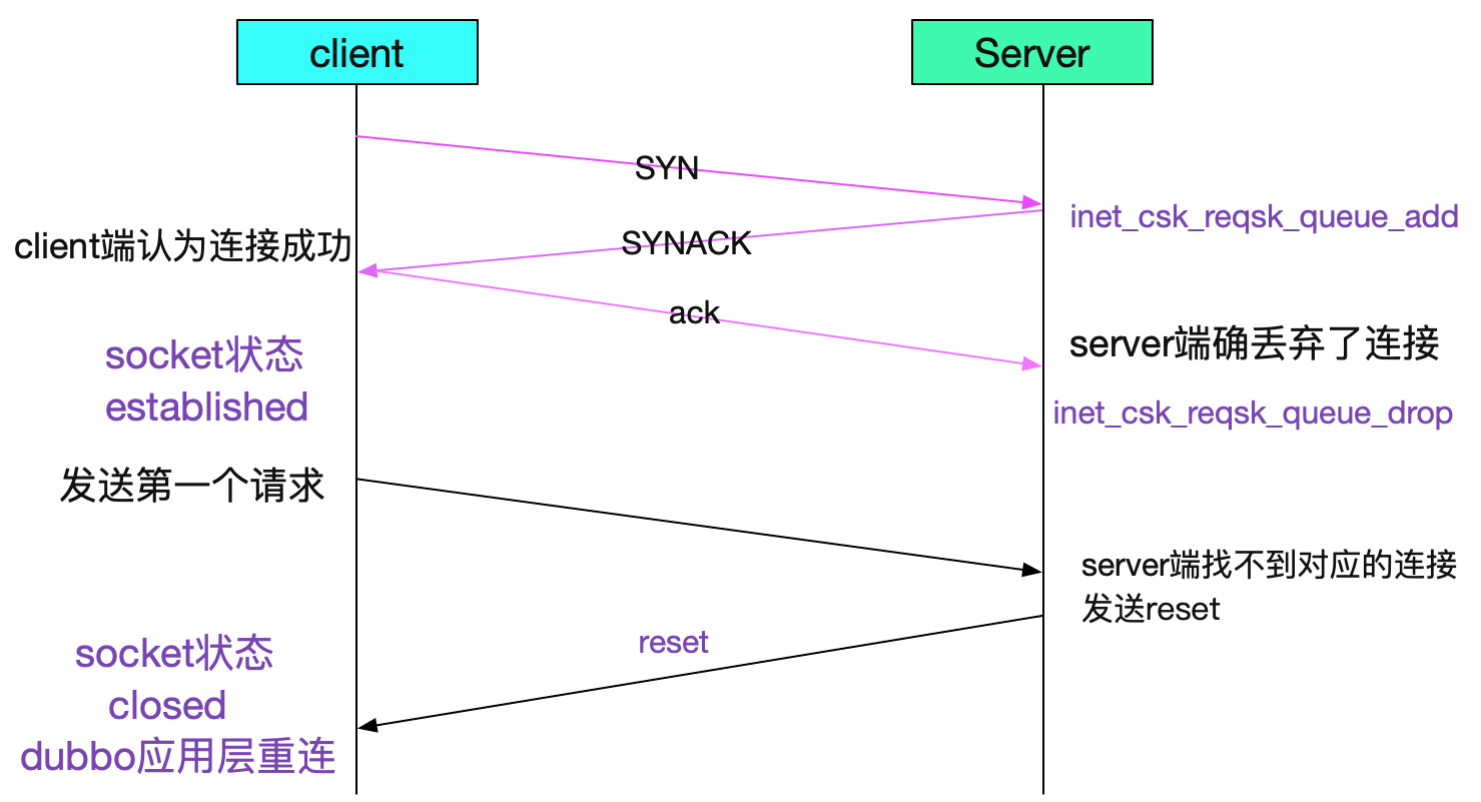
tcp_abort_on_overflow为什么默认是0
客户端状态变化路径:SYN_SENT ->ESTABLISHED
服务端状态变化路径:LISTEN->SYN_RECV ->ESTABLISHED
两次可以吗?
在谢希仁著《计算机网络》第四版中讲“三次握手”的目的是“为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误”。在另一部经典的《计算机网络》一书中讲“三次握手”的目的是为了解决“网络中存在延迟的重复分组”的问题。这两种不用的表述其实阐明的是同一个问题。<br /> <br />某个网络有多条路径,客户端请求建立连接的第一个包跑到一条延迟严重的路径上了,所以迟迟没有到达服务器。因此,客户端只能当作这个请求丢失了,不得不再请求一次。由于第二个请求走了正确的路径,所以很快完成工作并关闭了连接。对于客户端来说,事情似乎已经结束了。没想到它的第一个请求经过跋山涉水,还是到达了服务器。服务器并不知道这是一个旧的无效请求,所以按照惯例回复了。假如 TCP 只要求两次握手,那么服务器发出确认后,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。
采用“三次握手”的办法可以防止上述现象发生。client收到服务器的回复时,因为自己并没有要建立连接,因此就不会向server的回复发出确认。server由于收不到确认,就就明白了client并没有要求建立连接。 这样就可以防止server一直等待,浪费资源。
四次可以吗?
可以,没必要。
三次是交换初始序列号所需要的最少发包次数。
TCP作为一种可靠传输控制协议,其核心思想:既要保证数据可靠传输,又要提高传输的效率,而用三次恰恰可以满足以上两方面的需求!
TCP可靠传输的精髓:TCP连接的一方A,由操作系统动态随机选取一个32位长的序列号(Initial Sequence Number),假设A的初始序列号为1000,以该序列号为原点,对自己将要发送的每个字节的数据进行编号,1001,1002,1003…,并把自己的初始序列号ISN告诉B,让B有一个思想准备,什么样编号的数据是合法的,什么编号是非法的,比如编号900就是非法的,同时B还可以对A每一个编号的字节数据进行确认。如果A收到B确认编号为2001,则意味着字节编号为1001-2000,共1000个字节已经安全到达。
同理B也是类似的操作,假设B的初始序列号ISN为2000,以该序列号为原点,对自己将要发送的每个字节的数据进行编号,2001,2002,2003…,并把自己的初始序列号ISN告诉A,以便A可以确认B发送的每一个字节。如果B收到A确认编号为4001,则意味着字节编号为2001-4000,共2000个字节已经安全到达。
一句话概括,TCP连接握手,握的是啥?
通信双方数据原点的序列号!
以此核心思想我们来分析二、三、四次握手的过程。
A <———-> B
四次握手的过程:
1.1 A 发送同步信号SYN + A’s Initial sequence number
1.2 B 确认收到A的同步信号,并记录 A’s ISN 到本地,命名 B’s ACK sequence number
1.3 B发送同步信号SYN + B’s Initial sequence number
1.4 A确认收到B的同步信号,并记录 B’s ISN 到本地,命名 A’s ACK sequence number
很显然1.2和1.3 这两个步骤可以合并,只需要三次握手,可以提高连接的速度与效率。
二次握手的过程:
2.1 A 发送同步信号SYN + A’s Initial sequence number
2.2 B发送同步信号SYN + B’s Initial sequence number + B’s ACK sequence number
这里有一个问题,A与B就A的初始序列号达成了一致,这里是1000。但是B无法知道A是否已经接收到自己的同步信号,如果这个同步信号丢失了,A和B就B的初始序列号将无法达成一致。
于是TCP的设计者将SYN这个同步标志位SYN设计成占用一个字节的编号(FIN标志位也是),既然是一个字节的数据,按照TCP对有数据的TCP segment 必须确认的原则,所以在这里A必须给B一个确认,以确认A已经接收到B的同步信号。
有童鞋会说,如果A发给B的确认丢了,该如何?
A会超时重传这个ACK吗?不会!TCP不会为没有数据的ACK超时重传。
那该如何是好?B如果没有收到A的ACK,会超时重传自己的SYN同步信号,一直到收到A的ACK为止。
—————————-
补充阅读:
第一个包,即A发给B的SYN 中途被丢,没有到达B
A会周期性超时重传,直到收到B的确认
第二个包,即B发给A的SYN +ACK 中途被丢,没有到达A
B会周期性超时重传,直到收到A的确认
第三个包,即A发给B的ACK 中途被丢,没有到达B
A发完ACK,单方面认为TCP为 Established状态,而B显然认为TCP为Active状态:
a. 假定此时双方都没有数据发送,B会周期性超时重传,直到收到A的确认,收到之后B的TCP 连接也为 Established状态,双向可以发包。
b. 假定此时A有数据发送,B收到A的 Data + ACK,自然会切换为established 状态,并接受A的 Data。
c. 假定B有数据发送,数据发送不了,会一直周期性超时重传SYN + ACK,直到收到A的确认才可以发送数据。
要弄清TCP建立连接需要几次交互才行,我们需要弄清建立连接进行初始化的目标是什么。TCP进行握手初始化一个连接的目标是:分配资源、初始化序列号(通知peer对端我的初始序列号是多少),知道初始化连接的目标,那么要达成这个目标的过程就简单了,握手过程可以简化为下面的四次交互:
1 ) clien 端首先发送一个 SYN 包告诉 Server 端我的初始序列号是 X。
2 ) Server 端收到 SYN 包后回复给 client 一个 ACK 确认包,告诉 client 说我收到了。
3 ) 接着 Server 端也需要告诉 client 端自己的初始序列号,于是 Server 也发送一个 SYN 包告诉 client 我的初始序列号是Y。
4 ) Client 收到后,回复 Server 一个 ACK 确认包说我知道了。
整个过程4次交互即可完成初始化,但是,细心的同学会发现两个问题:
1. Server发送SYN包是作为发起连接的SYN包,还是作为响应发起者的SYN包呢?怎么区分?比较容易引起混淆
2.Server的ACK确认包和接下来的SYN包可以合成一个SYN ACK包一起发送的,没必要分别单独发送,这样省了一次交互同时也解决了问题1. 这样TCP建立一个连接,三次握手在进行最少次交互的情况下完成了Peer两端的资源分配和初始化序列号的交换。
大部分情况下建立连接需要三次握手,也不一定都是三次,有可能出现四次握手来建立连接的。如下图,当Peer两端同时发起SYN来建立连接的时候,就出现了四次握手来建立连接(对于有些TCP/IP的实现,可能不支持这种同时打开的情况)。
为什么要在建立tcp连接时初始化序列号?如果双方在建立tcp连接时使用相同的序号又会有什么问题?
序列号用来确保数据的合法性。
由于A和B之间的一个tcp连接通常是由A和B的2个ip地址,2个端口号构成的四元组,因此当A出现了故障把这个tcp连接断开了,之后再以相同的四元组建立新的tcp连接(也就是说A和B两次建立tcp连接都是使用了相同的ip地址和端口),就会出现数据乱序的问题。
换句话说,只要A发送了一个tcp报文段,且这个tcp报文段的四元组和序号,和之前的tcp连接(四元组和序号)相同的话,就会被B确认。这其实反映了tcp的一些缺点,如果被一些恶意攻击者加以利用tcp的这种缺点:选择合适的序号,ip地址和端口的话,就能伪造出一个tcp报文段,从而打断正常的tcp连接。但是初始化序号的方式(通过算法来随机生成序号)就会使序号难以猜出,也就不容易利用这种缺点来进行一些恶意攻击行为。
通过上面所述我们知道,如果A和B之间发送数据每次都使用相同序号的话可能会引发一系列的问题,但是使用不同序号的话,那么B在接收到这个序号为1的tcp报文时,发现这个tcp报文的序号不在新tcp连接的接收范围内时会把这个tcp报文丢弃掉,也就避免了数据乱序的问题。
因此我们可以明白,客户端和服务端双方在建立tcp连接并初始化序列号,那么上面所说的这些情况从一开始就可以避免。另外,tcp在初始化序列号的过程也是比较复杂的,一般来说,这个序号的范围是0 — 231−1 2^{31} - 12
31−1之间,而且序号的生成也是随机的,通常是一个很大的数值,也就是说每个tcp连接使用的序号也是不一样的。
TCP 连接的初始化序列号能否固定
如果初始化序列号(缩写为ISN:Inital Sequence Number)可以固定,我们来看看会出现什么问题。假设ISN固定是1,Client和Server建立好一条TCP连接后,Client连续给Server发了10个包,这10个包不知怎么被链路上的路由器缓存了(路由器会毫无先兆地缓存或者丢弃任何的数据包),这个时候碰巧Client挂掉了,然后Client用同样的端口号重新连上Server,Client又连续给Server发了几个包,假设这个时候Client的序列号变成了5。接着,之前被路由器缓存的10个数据包全部被路由到Server端了,Server给Client回复确认号10,这个时候,Client整个都不好了,这是什么情况?我的序列号才到5,你怎么给我的确认号是10了,整个都乱了。
RFC793中,建议ISN和一个假的时钟绑在一起,这个时钟会在每4微秒对ISN做加一操作,直到超过2^32,又从0开始,这需要4小时才会产生ISN的回绕问题,这几乎可以保证每个新连接的ISN不会和旧的连接的ISN产生冲突。这种递增方式的ISN,很容易让攻击者猜测到TCP连接的ISN,现在的实现大多是在一个基准值的基础上进行随机的。
如何绕过三次握手?
三次握手建立连接造成的后果就是,HTTP 请求必须在一个 RTT(从客户端到服务器一个往返的时间)后才能发送。
在 Linux 3.7 内核版本之后,提供了 TCP Fast Open 功能,这个功能可以减少 TCP 连接建立的时延。TFO可以绕过三次握手,使得 HTTP 请求减少 1 个 RTT 的时间。
tcp_fastopen功能由/proc/sys/net/ipv4/tcp_fastopen控制
- 0 关闭
- 1 作为客户端使用 Fast Open 功能
- 2 作为服务端使用 Fast Open 功能
- 3 无论作为客户端还是服务器,都可以使用 Fast Open 功能
TCP keep-alive
KeepAlive通过定时发送探测包来探测连接的对端是否存活,
常见的几种使用场景:
- 检测挂掉的连接(导致连接挂掉的原因很多,如服务停止、网络波动、宕机、应用重启等)
- 防止因为网络不活动而断连(使用NAT代理或者防火墙的时候,经常会出现这种问题)
与业务层心跳检测区别
- TCP自带的KeepAlive使用简单,发送的数据包相比应用层心跳检测包更小,仅提供检测连接功能
- 应用层心跳包不依赖于传输层协议,无论传输层协议是TCP还是UDP都可以用
- 应用层心跳包可以定制,可以应对更复杂的情况或传输一些额外信息
- KeepAlive仅代表连接保持着,而心跳包往往还代表客户端可正常工作
与Http中Keep-Alive区别
- HTTP协议的Keep-Alive意图在于连接复用,同一个连接上串行方式传递请求-响应数据
- TCP的KeepAlive机制意图在于保活、心跳,检测连接错误
KeepAlive默认关闭,相关内核参数(默认值)
net.ipv4.tcp_keepalive_time=7200net.ipv4.tcp_keepalive_intvl=75net.ipv4.tcp_keepalive_probes=9
参考
https://cloud.tencent.com/developer/article/1004327
https://cloud.tencent.com/developer/article/1645688

若有收获,就点个赞吧
0 人点赞
