1. 批量新增
1. MyBiats标签“foreach”
“foreach”的主要用在构建“in”条件中,它可以在SQL语句中进行迭代一个集合。“foreach”元素的属性主要有:“item”、“index”、“collection”、“open”、“separator”、“close”。“item”表示集合中每一个元素进行迭代时的别名,“index”指 定一个名字,用于表示在迭代过程中,每次迭代到的位置,“open”表示该语句以什么开始,“separator”表示在每次进行迭代之间以什么符号作为分隔 符,“close”表示以什么结束。
以下图例为批量新增100万行记录,单行和多行方式比较情况。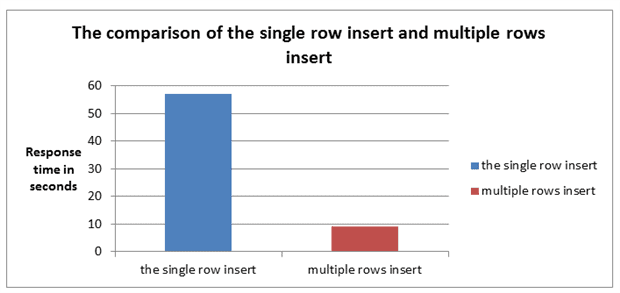
在使用“foreach”的时候最关键的也是最容易出错的就是“collection”属性,该属性是必须指定的,但是在不同情况 下,该属性的值是不一样的,主要有一下3种情况:
- 如果传入的是单参数且参数类型是一个List的时候,collection属性值为list。
- 如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array。
- 如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了。
具体用法如下(MyBatis示例):
<!-- Oracle示例(字段固定不变) --><insert id="insertBatch" parameterType="List">INSERT INTO TEST(c1,c2)<foreach collection="list" item="item" index="index" open="("close=")"separator="union all">SELECT #{item.c1} as a, #{item.c2} as b FROM DUAL</foreach></insert><!-- MySQL、DB2示例1(字段固定不变) --><insert id="insertBatch" >insert into TEST(c1,c2)values<foreach collection="list" item="item" index="index" separator=",">(#{item.c1},#{item.c2})</foreach></insert><!-- MySQL、DB2示例2(字段动态变化) --><insert id="insertBatch">insert into TEST<foreach collection="fields" item="field" open="(" close=")" separator=","><choose><when test="field == 'C1'">C1</when><when test="field == 'C2'">C2</when></choose></foreach>values<foreach collection ="values" item="val" index= "index" separator =","><trim prefix="(" suffix=")" suffixOverrides=","><if test=" val.c1 != null ">#{val.c1},</if><if test=" val.c2 != null ">#{val.c2},</if></trim></foreach ></insert>
2. MyBatis SQL执行器ExecutorType.BATCH
MyBatis内置的ExecutorType有3种,默认的是“simple”,该模式下它为每个语句的执行创建一个新的预处理语句,单条提交sql;而“batch”模式重复使用已经预处理的语句,并且批量执行所有更新语句,显然“batch”性能将更优; 但“batch”模式也有自己的问题,比如在“Insert”操作时,在事务没有提交之前,是没有办法获取到自增的“id”,这在某型情形下是不符合业务要求的。具体用法如下:
xxxMapper方式。
// 获取sqlsession,从spring注入原有的sqlSessionTemplate@Autowiredprivate SqlSessionTemplate sqlSessionTemplate;// 新获取一个模式为BATCH,自动提交为false的session// 如果自动提交设置为true,将无法控制提交的条数,改为最后统一提交,可能导致内存溢出SqlSession session = sqlSessionTemplate.getSqlSessionFactory().openSession(ExecutorType.BATCH,false);// 通过新的session获取mapperFooMapper fooMapper = session.getMapper(FooMapper.class);int size = 10000;try{for(int i = 0; i < size; i++) {Foo foo = new Foo();foo.setC1(String.valueOf(System.currentTimeMillis()));foo.setC2("c2-value");fooMapper.insert(foo);if(i % 1000 == 0 || i == size - 1) {// 手动每1000个一提交,提交后无法回滚session.commit();// 清理缓存,防止溢出session.clearCache();}}} catch (Exception e) {// 没有提交的数据可以回滚session.rollback();} finally{session.close();}
命名空间方式。
public void insertBatch(Map<String,Object> paramMap, List<Foo> list) throws Exception {// 新获取一个模式为BATCH,自动提交为false的session// 如果自动提交设置为true,将无法控制提交的条数,改为最后统一提交,可能导致内存溢出SqlSession session = sqlSessionTemplate.getSqlSessionFactory().openSession(ExecutorType.BATCH, false);try {if(null != list || list.size()>0){int lsize=list.size();for (int i = 0, n=list.size(); i < n; i++) {Foo _entity= list.get(i);_entity.setC1(String.valueOf(System.currentTimeMillis()));_entity.setC2("c2-value"String.valueOf(System.currentTimeMillis()));//session.insert("org.polaris.mapper.FooMapper.insertList",_entity);//session.update("org.polaris.mapper.FooMapper.updateBatchByPrimaryKeySelective",_entity);session.insert("${包类名}.${操作名}", _entity);if ((i>0 && i % 1000 == 0) || i == lsize - 1) {// 手动每1000个一提交,提交后无法回滚session.commit();// 清理缓存,防止溢出session.clearCache();}}}} catch (Exception e) {// 没有提交的数据可以回滚session.rollback();} finally {session.close();}}
2. 批量删除
MyBatis示例:
<delete id="deleteXXX" parameterType="java.util.List">DELETE FROM TESTWHERE id IN<foreach collection="ids" item="id" open="(" close=")" separator=",">#{id}</foreach></delete>
3. 批量更新
1. 通过参数${list}组装SQL
<update id="updateBatch" parameterType="java.util.List" ><foreach collection="list" item="item" index="index" open="" close="" separator=";">update TEST<set ><if test="item.c1 != null" >c1 = #{item.c1,jdbcType=VARCHAR},</if><if test="item.c2 != null" >c2 = #{item.c2,jdbcType=VARCHAR},</if></set>where id = #{item.id,jdbcType=BIGINT}</foreach></update>
2. 通过“case when”语句变相批量更新
<update id="updateBatch" parameterType="java.util.List" >update TEST<trim prefix="set" suffixOverrides=","><trim prefix="c1 =case" suffix="end,"><foreach collection="list" item="item" index="index"><if test="item.c1!=null">when id=#{item.id} then #{item.c1}</if></foreach></trim><trim prefix="c2 =case" suffix="end,"><foreach collection="list" item="item" index="index"><if test="item.c2!=null">when id=#{item.id} then #{item.c2}</if></foreach></trim></trim>where<foreach collection="list" separator="or" item="item" index="index" >id=#{item.id}</foreach></update>
3. 通过“DUPLICATE KEY UPDATE”/“MERGE INTO”批量更新
<insert id="updateBatch" parameterType="java.util.List">insert into TEST( id,c1, c2 )VALUES<foreach collection="list" item="item" index="index" separator=",">(#{item.id,jdbcType=BIGINT},#{item.c1,jdbcType=VARCHAR}, #{item.c2,jdbcType=VARCHAR})</foreach>ON DUPLICATE KEY UPDATEc1 = VALUES(c1),c2 = VALUES(c2)</insert>
4. 批量合并汇入/插入更新
1. Oracle(MERGE INTO)
SQL语法:
MERGE INTO table_name alias1USING (table|view|sub_query) alias2ON (join condition)WHEN MATCHED THENUPDATE table_nameSET col1 = col_val1,col2 = col_val2WHEN NOT MATCHED THENINSERT (column_list) VALUES (column_values);
MyBatis示例:
<update id="mergeinfo">merge into TEST ausing ( select #{id} as id, #{c1} as c1, #{c2} as c2 from dual ) bon (a.id = b.id)when not matched theninsert (c1,c2) values(#{c1},#{c2})when matched thenupdate set c1 = #{c1}where c2 = #{c2}</update>
2. DB2(MERGE INTO)
SQL示例:
# 支持多行记录操作MERGE INTO BASE.TEST AS t1USING TABLE (VALUES(?,?,?)) t2(id,c1,c2)ON t1.id=t2.idwhen matched thenupdate set t1.c1=t2.c1when not matched theninsert (id,c1,c2) values(t2.id,t2.c1,t2.c2);
3. MySQL(duplicate key update)
SQL示例:
# 支持多行记录操作-- 全部字段insert into TEST(id,c1,c2 ) select * from TMP on duplicate key update c1=values(c1),c2=values(c2);-- 部分字段insert into TEST(id,c1) select id,c1 from TMP on duplicate key update c1=values(c1);
5. 工具类
```java package org.polaris.dev.Executor;
import org.apache.ibatis.session.ExecutorType; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.mybatis.spring.SqlSessionTemplate; import org.polaris.dev.mapper.TgkhMapper; import org.polaris.dev.util.DataUtil; import org.polaris.dev.vo.Tgkh; import org.springframework.stereotype.Component; import javax.annotation.Resource; import java.util.ArrayList; import java.util.List; import java.util.function.BiConsumer; import static org.mybatis.spring.SqlSessionUtils.closeSqlSession;
/**
- @author polaris 450733605@qq.com
- @Description 启动mybatis的Batch模式的批量新增、更新
- @Date 2021-4-22 10:09
@Version 1.0.0 */ @Component public class MybatisBatchExecutor {
/**
- 每多少条记录拼接一次SQL
- 拼接SQL的最大数据量(即:每次accept时,容忍的list数据条数,如:foreach,接收list.size条记录,拼接为单条SQL)
- insert:支持把${batchCountToSQL}条数的数据使用foreach拼写成一个大SQL
- update:支持把${batchCountToSQL}条数的数据拼写成case when方式的大SQL
- merge:支持把${batchCountToSQL}条数的数据使用merge into语法或ON DUPLICATE KEY UPDATE语法拼写成一个大SQL
select:支持把${batchCountToSQL}条数的数据使用union all拼写成一个大SQL
*/ private static final int batchCountToSQL = 25;/**
每多少次批量执行一次提交 */ private static final int batchCountToSubmit = 100;
@Resource private SqlSessionTemplate sqlSessionTemplate;
/**
- 批量更新、新增
- @param dbList
- @param mapperClass
- @param func
- @param
@param
*/ public dbList, Class mapperClass, BiConsumer SqlSessionFactory sqlSessionFactory = sqlSessionTemplate.getSqlSessionFactory(); SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false); M modelMapper = sqlSession.getMapper(mapperClass); try {
if (total > batchCountToSQL) {// 多个批次情况for (int index = 0; index < total; ) {if (batchLastIndex > total) {// 最后一个批次,处理完成,结束循环体List<T> list = dbList.subList(index, total);func.accept(modelMapper, list);sqlSession.flushStatements();sqlSession.commit();break;} else {// 攒批,达到${batchCountToSubmit}次批量以后,提交List<T> list = dbList.subList(index, batchLastIndex);func.accept(modelMapper, list);if (batchLastIndexToSubmit++ >= batchCountToSubmit) {// 如果可以批量提交,则提交sqlSession.flushStatements();sqlSession.commit();batchLastIndexToSubmit = 0;}index = batchLastIndex; // 设置下一批下标batchLastIndex = index + (batchCountToSQL - 1);}}} else {// 不足一个批量时,直接提交func.accept(modelMapper, dbList);sqlSession.commit();}
} finally {
closeSqlSession(sqlSession, sqlSessionFactory);
} }
public static void main(String[] args) { MybatisBatchExecutor mybatisBatchExecutor = new MybatisBatchExecutor(); // 使用过程list赋值为实际数据 List
list=null; // 批量插入 mybatisBatchExecutor.insertOrUpdateBatch(list, TgkhMapper.class, (mapper, data)-> {
List<String> fields = DataUtil.getFieldsByColumnsName(data);mapper.batchInsertSample(data,fields);
});
// 批量Meger mybatisBatchExecutor.insertOrUpdateBatch(list, TgkhMapper.class, (mapper, data)-> {
List<String> fields = DataUtil.getFieldsByColumnsName(data);mapper.batchMergeSample(data,fields);
});
// 批量查询 List
bigList=new ArrayList<>(); mybatisBatchExecutor.insertOrUpdateBatch(list, TgkhMapper.class, (mapper, data)-> { List<Tgkh> primaryKeyList = mapper.findByPrimaryKey(data);bigList.addAll(primaryKeyList);
}); } }
<a name="cCfvG"></a># 6. 注意事项<a name="m0ovW"></a>## 1. 开启批量操作支持参数MySQL的JDBC连接的url中要加rewriteBatchedStatements参数,并保证5.1.13以上版本的驱动,才能实现高性能的批量插入。MySQL JDBC驱动在默认情况下会无视“executeBatch()”语句,把我们期望批量执行的一组sql语句拆散,一条一条地发给MySQL数据库,批量插入实际上是单条插入,直接造成较低的性能。只有把rewriteBatchedStatements参数置为true, 驱动才会帮你批量执行SQL。另外这个选项对“INSERT/UPDATE/DELETE”都有效。
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/testdb?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&rewriteBatchedStatements=true
添加这个参数后的执行速度比较(同一个表插入一万条数据时间近似值):JDBC BATCH 1.1秒左右 > Mybatis BATCH 2.2秒左右 > 拼接SQL 4.5秒左右。<a name="l5M1x"></a>## 2. “foreach”使用注意点foreach后有多个values(5000+)时PreparedStatement随之增长,包含了很多占位符,对于占位符和参数的映射尤其耗时。查阅相关[资料](https://www.red-gate.com/simple-talk/sql/performance/comparing-multiple-rows-insert-vs-single-row-insert-with-three-data-load-methods/)可知,values的增长与所需的解析时间,是呈指数型增长的。<br />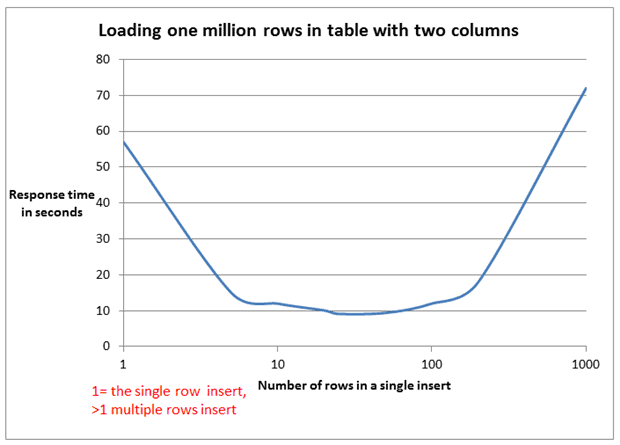<br />如果非要使用“foreach”的方式来进行批量插入的话,可以考虑减少一条“insert”语句中“values”的个数,最好能达到上面曲线的最底部的值,使速度最快。一般按经验来说,一次性插20~50行数量是比较合适的,时间消耗也能接受。<a name="oJjig"></a>## 3. 大SQL内容过大异常MySQL-5.x数据,插入或更新字段有大数据时(大于1M),会出现如下错误:“**Packet for query is too large (1117260 > 1048576). You can change this value on the server by setting the max_allowed_packet' variable.**”<br />问题分析:mysql默认加载的数据文件不超过1M,可以通过更改mysql的配置文件my.cnf(Linux,或windows的my.ini)来更改这一默认值,从而达到插入大数据的目的。<br />解决方案:调整MySQL系统参数“max_allowed_packet”。```sqlshow VARIABLES like '%max_allowed_packet%';SET GLOBAL max_allowed_packet=16*1024*1024;set @@max_allowed_packet=16*1024*1024;
参考
简书:批处理“rewriteBatchedStatements=true”
https://www.jianshu.com/p/0f4b7bc4d22c
CSDN:MyBatis批量插入几千条数据慎用foreach
https://blog.csdn.net/huanghanqian/article/details/83177178
https://www.red-gate.com/simple-talk/sql/performance/comparing-multiple-rows-insert-vs-single-row-insert-with-three-data-load-methods/
- 每多少条记录拼接一次SQL

若有收获,就点个赞吧
0 人点赞
