一、健康检查(TTL)分类
健康检查可以分为一下两大类:
客户端健康检查**
客户端通过自己上报心跳 💗 来维持其生命健康,同时服务端会定时回查心跳信息,若发现心跳超时,则会将客户端设置为不健康或下线。
服务端健康检查**
服务端主动发起探测,对客户端进行验活。服务端检测又可细分为传输层检测和应用层检测。
传输层检测最常见的方式是 TCP 端口探测和 HTTP 接口返回码探测,这两种探测方式因为其协议的通用性可以支持绝大多数的健康检查场景。
应用层检测常见实现方式为Ping、HTTP请求、Redis请求、MySQL命令、用户自定义。在其他一些特殊的场景中,可能还需要执行特殊的接口才能判断服务是否可用。例如部署了数据库的主备,数据库的主备可能会在某些情况下切换,由于需要保证当前访问的库是主库,此时的健康检查接口就是一个检查数据库是否是主库的 MYSQL 命令了。
从实现复杂性来说,服务端探测肯定是要更加复杂的,因为需要服务端根据注册服务配置的健康检查方式,去执行相应的接口,判断相应的返回结果,并做好重试机制和线程池的管理。这与客户端探测,只需要等待心跳,然后刷新 TTL 是不一样的。同时服务端健康检查无法摘除不健康实例,这意味着只要注册过的服务实例,如果不调用接口主动注销,这些服务实例都需要去维持健康检查的探测任务,而客户端则可以随时摘除不健康实例,减轻服务端的压力。
二、Nacos 健康检查实现方式
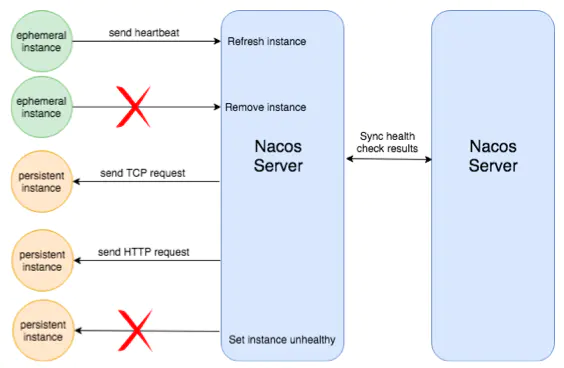
Nacos 同时支持客户端健康检查与服务端的健康检查,同一个服务可以依据AP/CP模式在两者之间进行切换。
- 临时实例:通过心跳上报来确认健康状态。如果实例心跳上报一直正常,但是接口本身存在异常,nacos目前是检测不出来的。
- 持久化实例:服务端主动检测,支持传输层(TCP)和应用层(如 HTTP、MySQL、用户自定义)的监控检查,默认为TCP。
1、心跳检测
Nacos 目前支持临时实例使用心跳上报方式维持活性。Client 默认每隔 5 秒发送一次心跳,Server 收到心跳后会更新上一次心跳时间。若连续 15 秒没有收到心跳,则将实例设置为不健康。若连续 30 秒没收到心跳,那么将这个临时实例进行摘除。
2、传输层(TCP)检测
3、应用层(HTTP)的检测


若有收获,就点个赞吧
0 人点赞
