一、总体设计
1、基础模型
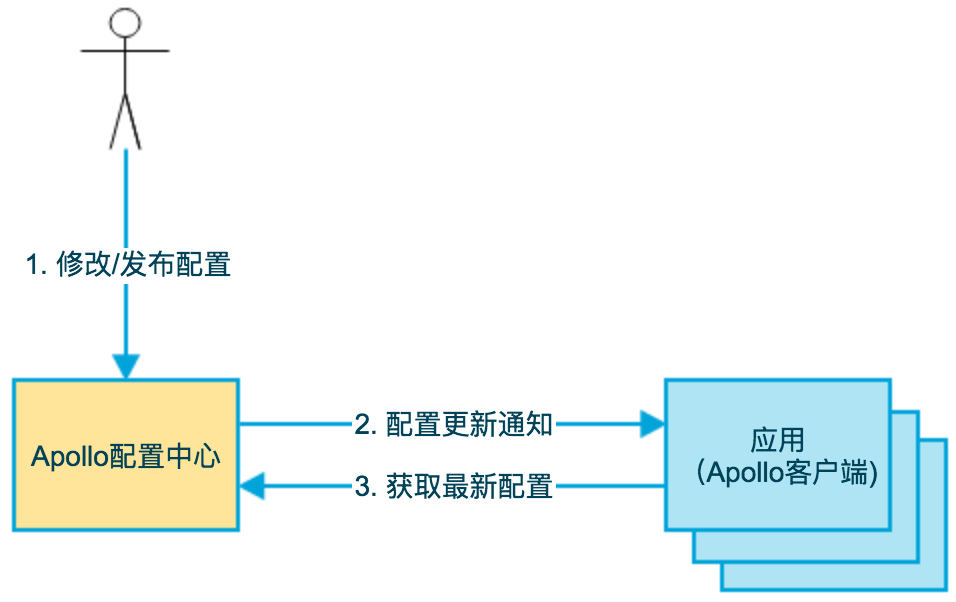
- 用户在配置中心对配置进行修改并发布
- 配置中心通知Apollo客户端有配置更新
- Apollo客户端从配置中心拉取最新的配置、更新本地配置并通知到应用
2、技术架构
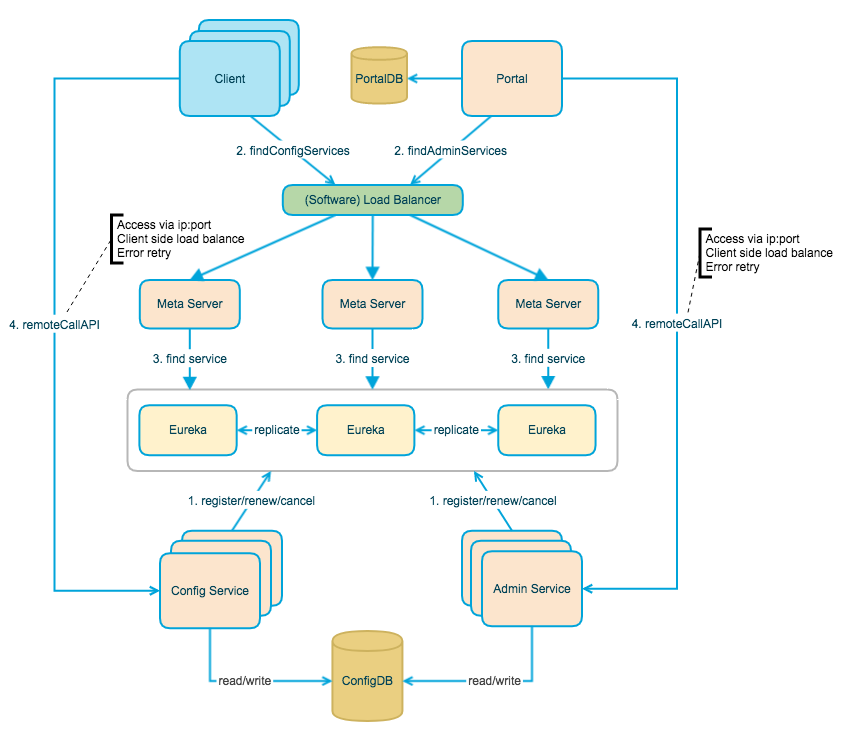 总体可分为7个模块,其中4个为核心功能模块,另外3个为服务发现相关模块。
总体可分为7个模块,其中4个为核心功能模块,另外3个为服务发现相关模块。
**
2.1、核心功能模块
Admin Service提供了配置的修改、发布等功能,服务对象为 Portal(管理界面)。Config Service提供了配置的读取、推送(基于Http long polling)等功能,服务对象为 Client。- 服务端使用Spring DeferredResult实现异步化,从而大大增加长连接数量
- 目前使用的tomcat embed默认配置是最多10000个连接(可以调整),使用了4C8G的虚拟机实测可以支撑10000个连接,所以满足需求(一个应用实例只会发起一个长连接)。
Portal配置管理界面。通过域名访问 Meta Server 获取 Admin Service 服务列表(IP+Port),而后直接通过IP+Port访问服务,同时在 Portal 侧会做load balance、错误重试。Client为应用获取配置,支持实时更新。通过域名访问 Meta Server 获取 Config Service 服务列表(IP+Port),而后直接通过IP+Port访问服务,同时在 Client 侧会做load balance、错误重试。
2.2、服务发现模块
Eureka用于服务发现和注册。为什么我们采用Eureka作为服务注册中心,而不是使用传统的zk、etcd呢?我大致总结了一下,有以下几方面的原因:- 它提供了完整的Service Registry和Service Discovery实现
- 首先是提供了完整的实现,并且也经受住了Netflix自己的生产环境考验,相对使用起来会比较省心。
- 和Spring Cloud无缝集成
- 我们的项目本身就使用了Spring Cloud和Spring Boot,同时Spring Cloud还有一套非常完善的开源代码来整合Eureka,所以使用起来非常方便。
- 另外,Eureka还支持在我们应用自身的容器中启动,也就是说我们的应用启动完之后,既充当了Eureka的角色,同时也是服务的提供者。这样就极大的提高了服务的可用性。
- 这一点是我们选择Eureka而不是zk、etcd等的主要原因,为了提高配置中心的可用性和降低部署复杂度,我们需要尽可能地减少外部依赖。
- Open Source
- 最后一点是开源,由于代码是开源的,所以非常便于我们了解它的实现原理和排查问题。
- 它提供了完整的Service Registry和Service Discovery实现
Meta Server的角色主要是为了封装服务发现的细节,对 Portal 和 Client 而言,永远通过一个Http接口获取 Admin Service 和 Config Service 的服务信息,而不需要关心背后实际的服务注册和发现组件。- Config Service 和Admin Service 都是多实例、无状态部署,所以需要将自己注册到 Eureka 中并保持心跳。
- Meta Server 从 Eureka 获取 Config Service 和 Admin Service 的服务信息,相当于是一个 Eureka Client。
NginxLB- 和域名系统配合,协助Portal访问MetaServer获取AdminService地址列表
- 和域名系统配合,协助Client访问MetaServer获取ConfigService地址列表
- 和域名系统配合,协助用户访问Portal进行配置管理
- 和域名系统配合,协助Portal访问MetaServer获取AdminService地址列表
备注:为了简化部署,我们实际上会把 Config Service、Eureka 和 Meta Server 三个逻辑角色部署在同一个JVM进程中。
二、服务端设计
1、配置发布后的实时推送设计
在配置中心中,一个重要的功能就是配置发布后实时推送到客户端。下面我们简要看一下这块是怎么设计实现的。
上图简要描述了配置发布的大致过程:
- 用户在 Portal 操作配置发布
- Portal 调用 Admin Service 的接口操作发布
- Admin Service发布配置后,发送
ReleaseMessage给各个 Config Service - Config Service 收到 ReleaseMessage 后,通知对应的客户端
1.1、发送ReleaseMessage的实现方式
Admin Service在配置发布后,需要通知所有的Config Service有配置发布,从而Config Service可以通知对应的客户端来拉取最新的配置。
从概念上来看,这是一个典型的消息使用场景,Admin Service作为producer发出消息,各个Config Service作为consumer消费消息。通过一个消息组件(Message Queue)就能很好的实现Admin Service和Config Service的解耦。在实现上,考虑到Apollo的实际使用场景,以及为了尽可能减少外部依赖,我们没有采用外部的消息中间件,而是通过数据库实现了一个简单的消息队列。
实现方式如下:
- Admin Service在配置发布后会往ReleaseMessage表插入一条消息记录,消息内容就是配置发布的AppId+Cluster+Namespace,参见
DatabaseMessageSender - Config Service有一个线程会每秒扫描一次ReleaseMessage表,看看是否有新的消息记录,参见
ReleaseMessageScanner - Config Service如果发现有新的消息记录,那么就会通知到所有的消息监听器(
ReleaseMessageListener),如NotificationControllerV2,消息监听器的注册过程参见ConfigServiceAutoConfiguration - NotificationControllerV2得到配置发布的AppId+Cluster+Namespace后,会通知对应的客户端

1.2、Config Service通知客户端的实现方式
上一节中简要描述了NotificationControllerV2是如何得知有配置发布的,那NotificationControllerV2在得知有配置发布后是如何通知到客户端的呢?
实现方式如下:
- 客户端会发起一个Http请求到Config Service的notifications/v2接口,也就是
NotificationControllerV2,参见RemoteConfigLongPollService - NotificationControllerV2不会立即返回结果,而是通过
Spring DeferredResult把请求挂起 - 如果在60秒内没有该客户端关心的配置发布,那么会返回Http状态码304给客户端
- 如果有该客户端关心的配置发布,NotificationControllerV2会调用DeferredResult的setResult方法,传入有配置变化的namespace信息,同时该请求会立即返回。客户端从返回的结果中获取到配置变化的namespace后,会立即请求Config Service获取该namespace的最新配置。
三、客户端设计
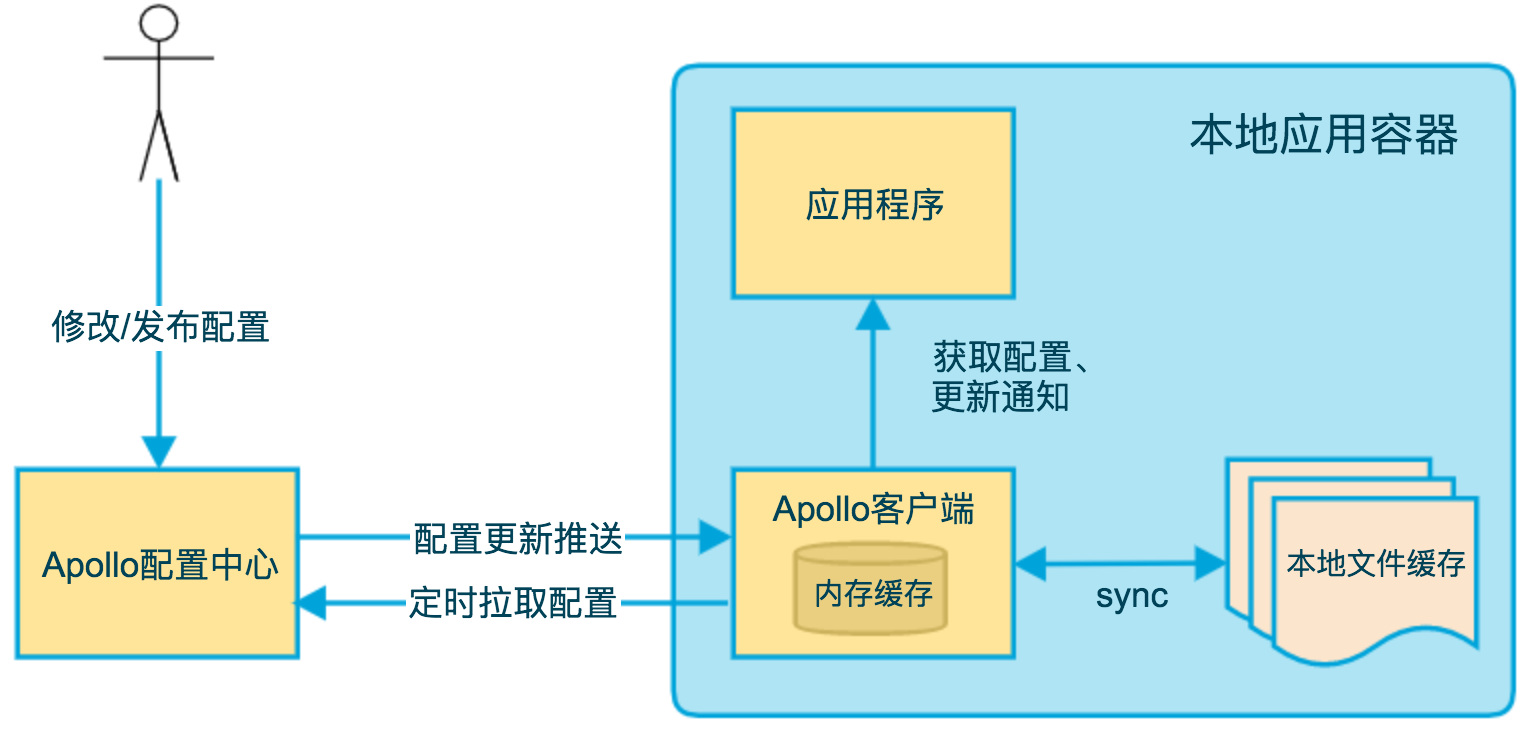
上图简要描述了Apollo客户端的实现原理:
- 客户端和服务端保持了一个长连接,从而能第一时间获得配置更新的推送。(通过Http Long Polling实现)
- 客户端还会定时从Apollo配置中心服务端拉取应用的最新配置。
- 这是一个fallback机制,为了防止推送机制失效导致配置不更新
- 客户端定时拉取会上报本地版本,所以一般情况下,对于定时拉取的操作,服务端都会返回304 - Not Modified
- 定时频率默认为每5分钟拉取一次,客户端也可以通过在运行时指定System Property: apollo.refreshInterval来覆盖,单位为分钟。
- 客户端从Apollo配置中心服务端获取到应用的最新配置后,会保存在内存中
- 客户端会把从服务端获取到的配置在本地文件系统缓存一份,用于容灾
- 在遇到服务不可用,或网络不通的时候,依然能从本地恢复配置
- 应用程序可以从Apollo客户端获取最新的配置、订阅配置更新通知
三、可用性考虑

若有收获,就点个赞吧
0 人点赞
