1)TensorFlow Lite 的介绍
它是由 Google 开发在移动设备和 IoT 设备上部署机器学习模型推理的轻量端侧推理架构。同时 TensorFlow Lite 又一款基于开源的同时可以支持 Qualcomm Soc - Hexagon DSP 的深度学习推理框架。Android 在 8.1 之后的版本都加入了 NN API 的模块,此模块的使用是调用 Hexagon DSP 的过程来完成整个神经网络的推理加速。 如果,未选择 NN API 实现神经网络的推理,默认情况下是使用 CPU 来执行推理的。
2)TensorFlow Lite 的流程框架
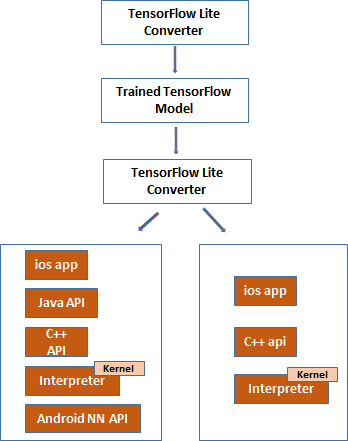
图-1 TensorFlow Lite 的流程框架
- TensorFlow 的训练框架在训练后得到的有效文件有:Model 和 CHECKPOINRTS。其中,Model 就是常见的 GraphDef File,GraphDef File 由 二进制的 pb 格式的文件以及可阅读的 pbtxt 文件。其次,Checkpoints 就是有 checkpoint file 组成,它是来自 TensorFlow Graph 里的序列化的变量、记录了不同点的变量的值。
- 有 TensorFlow 生成的 Model 和 Checkpoint 组合可以生成 Frozen Graph。此过程是一个冷冻的过程,可以把每一个变量都转化位常量,而且这些常量来自于 checkpoint。 此过程如图-2所示:
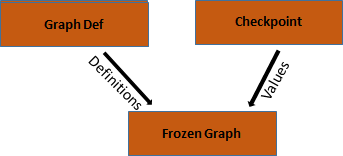
3)TensorFlow Lite 的模型生成
- TFLite 的生成过程如下:
Frozen Graph **=》Toco Tool =》** TFLite File
TFLite 的生成过程的源码:
with tf.Session ( ) as sess:<br /> tflite_model = tf.contrib.lite.toco_convert(sess.graph_def, [img],[out])<br /> open("converteds_model.tflite","wb").write(tflite_model)<br />
注意,TFLite 的生成过程是依靠 TensorFlow 下的 Toco 的工具完成 TFLite 的 model 的转换的。但是,需要注意的是 TensorFlow Lite 不能满足所有的 TensorFlow 的算子,因为 TensorFlow Lite 对于某些 TensorFlow 的算子还未在 TensorFlow Lite 完成开发(更多关于算子支持的内容参见:TensorFlow Lite 的 Ops 的支持 )。
4)TensorFlow Lite 的推理部署:
获取 TensorFlow Lite 的 TFLite 的模型,其中下载链接:TFLite Model Zoo
- 模型包含的内容:tflite 格式的 model 文件,以及可能包含的 lable.txt 的标签文件
- android 的推理过程需要把 tflite 的模型加载到 android 设备里,因此需要在 build.gradle 文件中加入如下内容作为依赖项:

- 引入模型后需要设置,TensorFlow Lite 的解释器来装载和运行模型,android 下是如何执行的呢?相关的实现细节引入 import org.tensorflow.lite.Interpreter
- 那么 model 到底存储在什么地方呢?android 下的 assets 是存储的一种方法,具体 android 下的实现如下所示:

- 实例化,解释器装载模型的方式,如下所示:

- android 在展示运用的时候,如何从设备 camera 获取数据? 完整的 android 获取数据的代码流程如下:
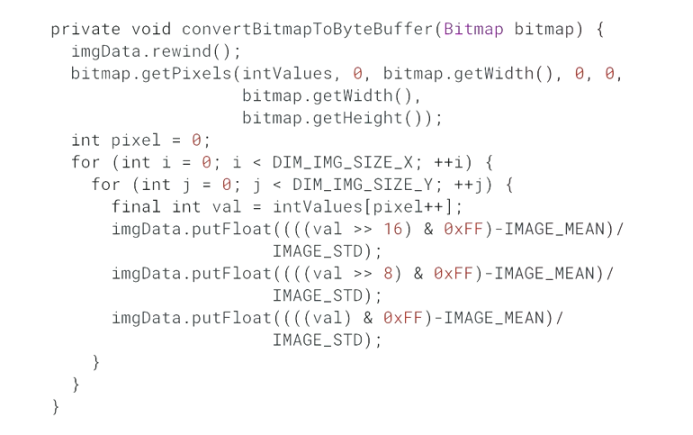
注意,camera 在获取数据的时候把数据转换成了 bitmap, 然后 bitmap 再转换成 Byte Buffer。 这些 Byte Buffer 是可以被 tflite 的模型所认知的。同时,byte buffer 也就是最终的 image data
5) TensorFlow Lite 的深度解析
Tensorflow 的端侧部署的流程如下所示:
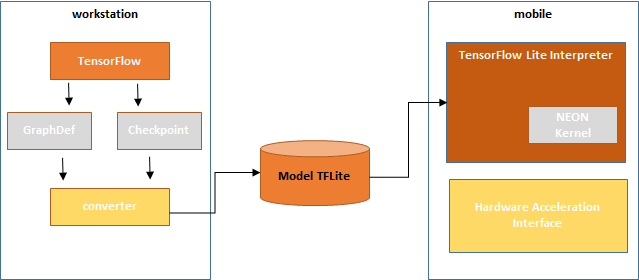
- TensorFlow Lite的源码链接:TensorFlow Lite Original Source Code
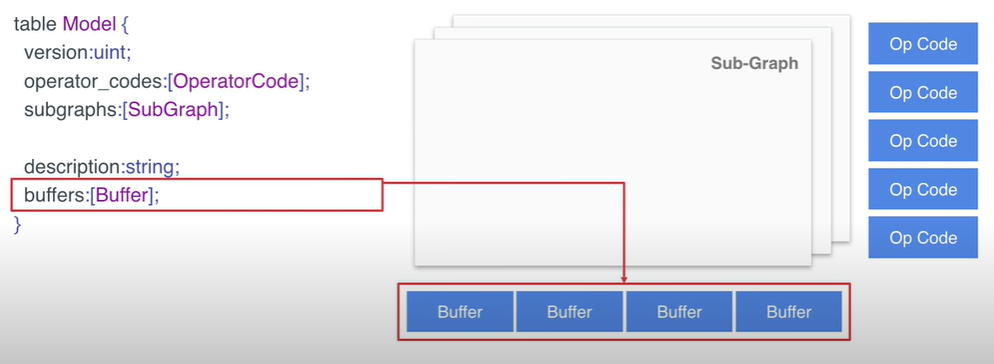
- TensorFlow Lite 的 model 结构体的深度解析,model 的结构体内容如下:
table Model {
version:unit;
oprator_codes:[OperatorCode];
subgraphs:[SubGraph];
description:string;
buffers:[Buffer];
}
- 其中,model 结构体中的 operator_codes 定义模型中用到的算子。
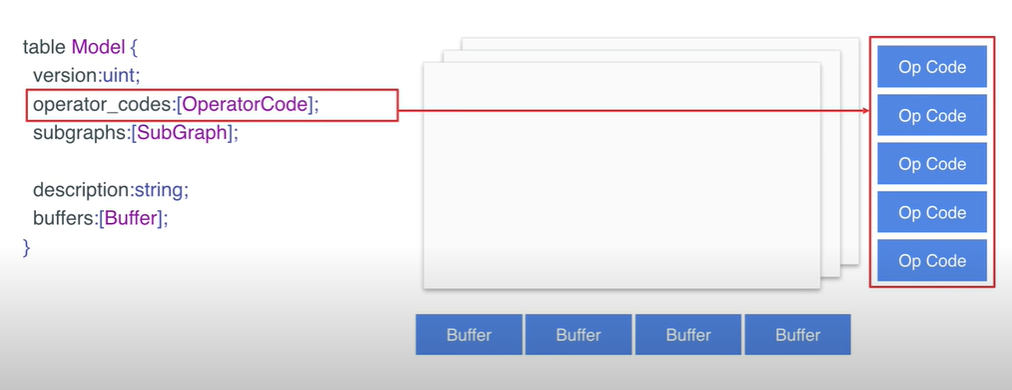
- subgraphs 结构体中定义了各个子图,其中第一个子图是模型中的主图
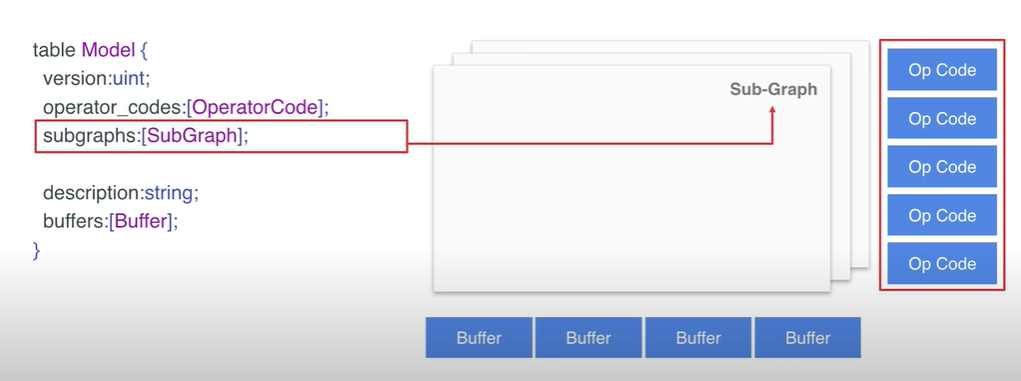
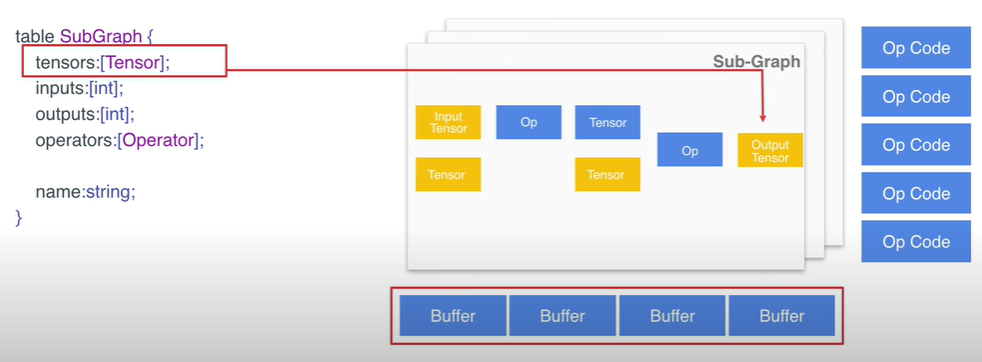
- Sub-Graph 是Model 里的重要的结构体, 它定义了图的具体结构,其中 Sub-Graph 下的 tensors 它是定义了子图中的各个tensor;
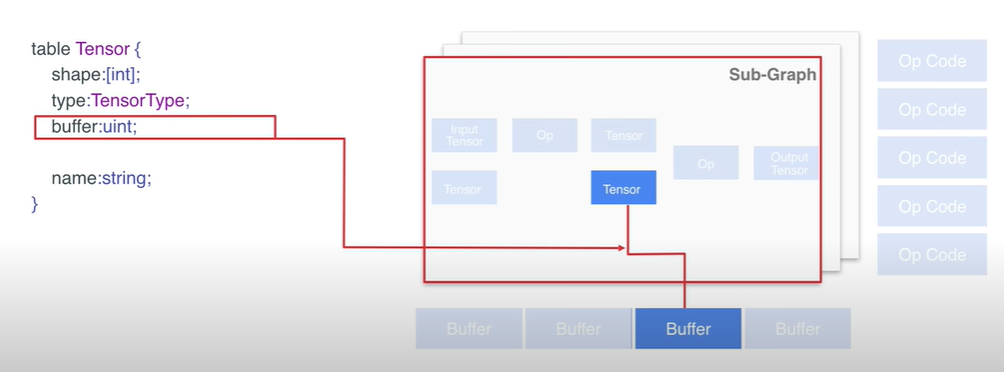
- Tensor 结构体包含了维度信息(shape),数据类型(type),buffer 位置。其中 buffer 通过 index values 指出了此 Tensor 用了哪个 buffer。
- 同时,Sub-Graph 下的 inputs 和 outputs 是通过 index values 的形式定义了哪些 tensor 负责输入和输出信息;
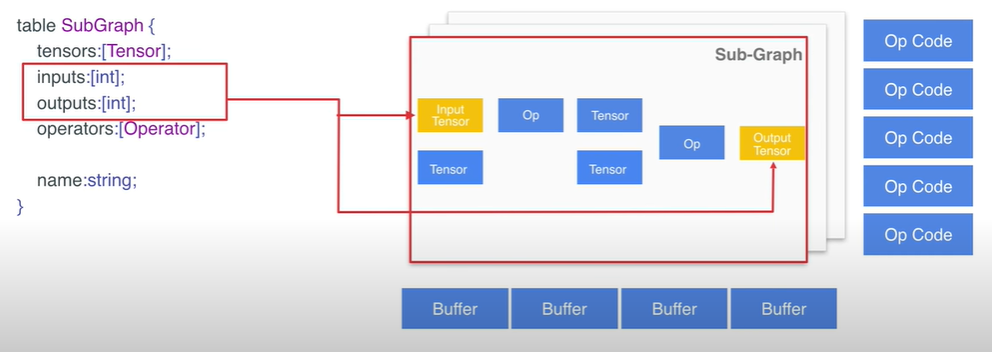
- 然而,Sub-Graph 里包含的 operator 定义了子图中的各个算子;
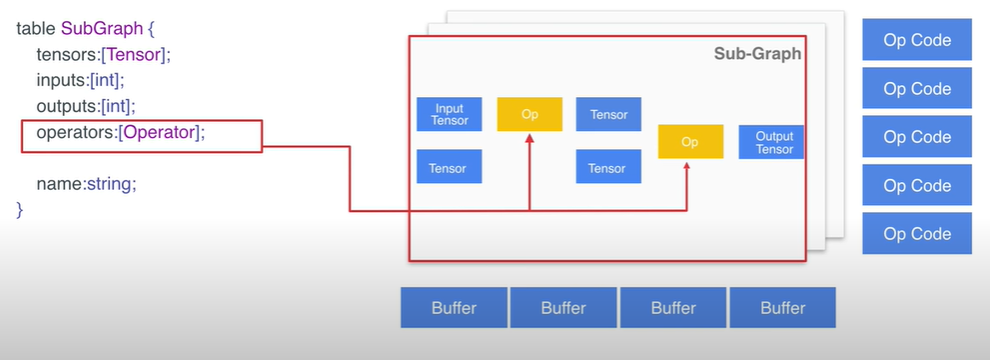
- operator 结构体信息是怎样的呢?如下是关于 operator 结构的信息展示,同时它也定义了图的结构:

- operator 中的 opcode_index 是通过 index value 的形式指明了该 operator 所对应的具体的算子
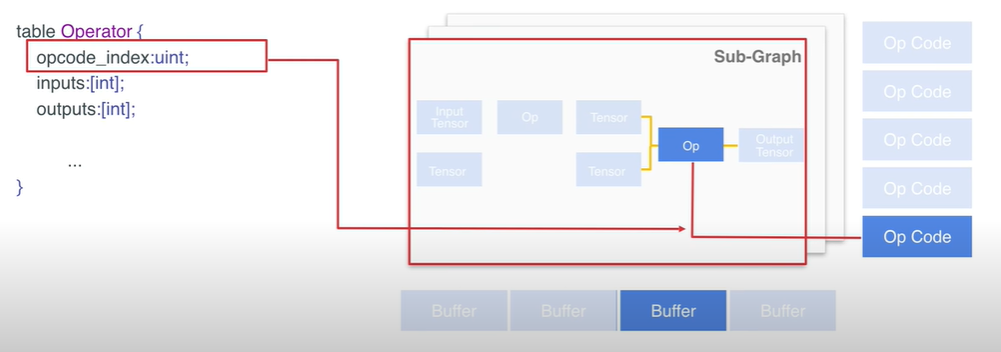
- operator 中的 inputs 和 outputs 是 tensors 的 index values 指明了该 operator 的输入和输出,这样可以把数据流以 flatten buffer 的形式表达出来
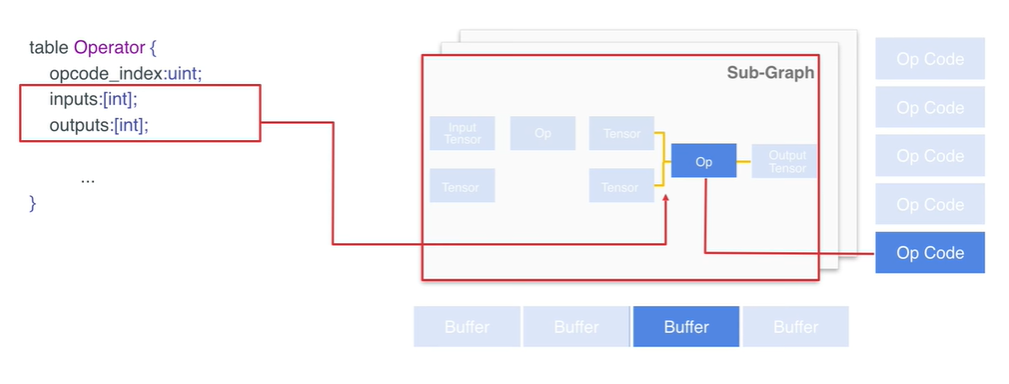
buffers 是数据的存储区域,其中主要存储了模型的权重信息。
- TensorFlow interpreter 的深度解析,以 sub-graph 为例:
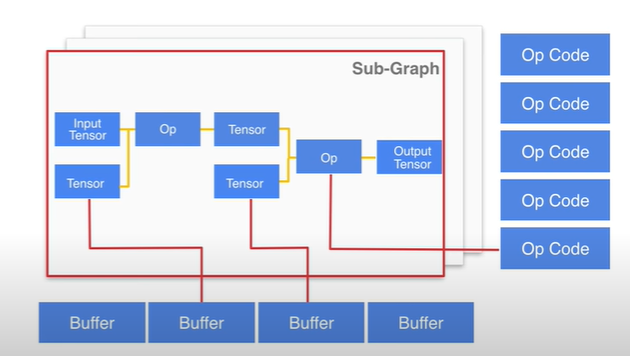
其中,sub-graph的主要的数据结构有以下结构,Tensor,Operator,还有 buffer。 那么完整的 TensorFlow Lite Interperter 是什么样的流程呢?以下如图所示,展示了完整的 TensorFlow Lite 的 interperter 的过程。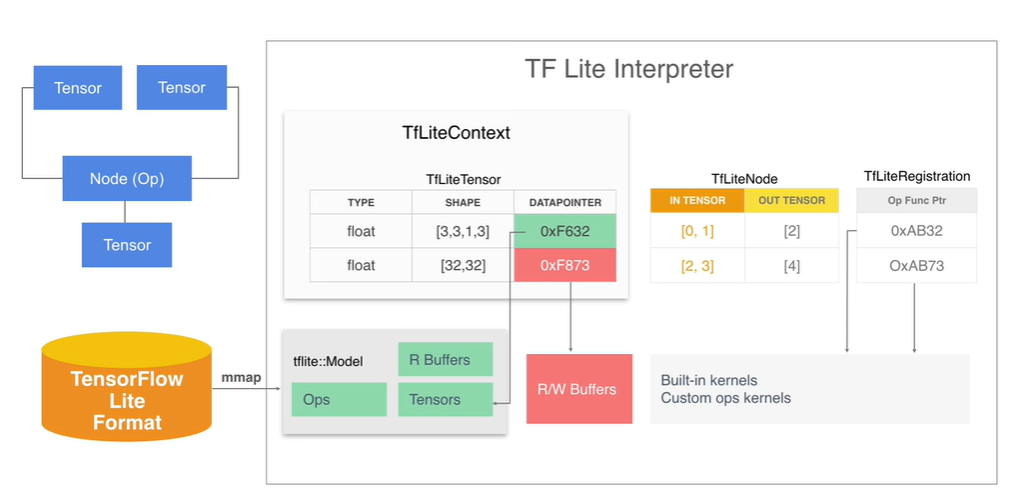
图示,TensoFlow Lite Interpreter 完整流程
- 数据流图可以用边和节点来表示,边就是Tensor、然后在节点 Node 对应的 Tensor 进行一定的操作得到输出即另一个 Tensor 。
- 那么如何实现 interpreter 中的数据流图的实现呢?首先需要将 model 文件通过 mmap 内存映射加载到内存中,这样在内存里有了 Tensor Operator 以及 buffer 的内容。 model 中的 buffer 是只读的通常用于记入 weight 的信息,为了表示那些数值可变的 Tensor, 我们额外分配了可写的 buffer 区域。
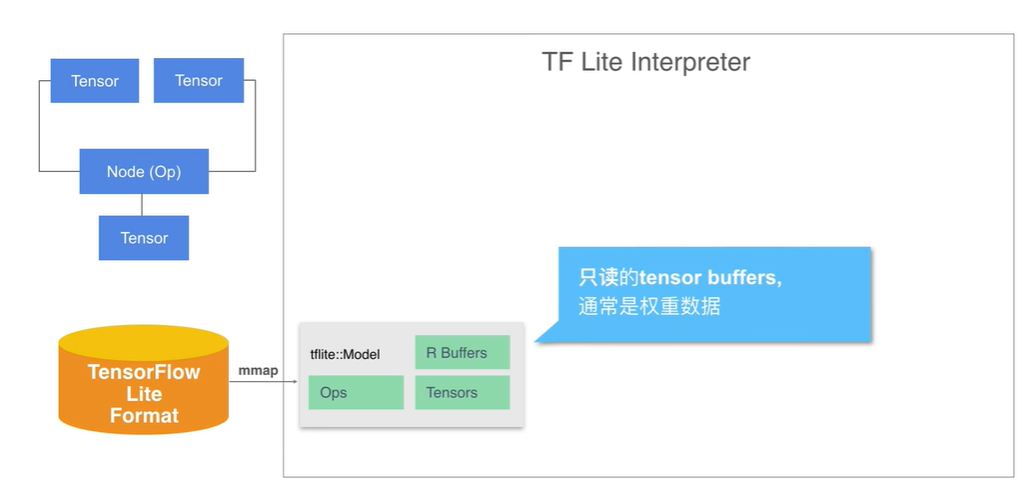
图示:Tensor buffer 只读区域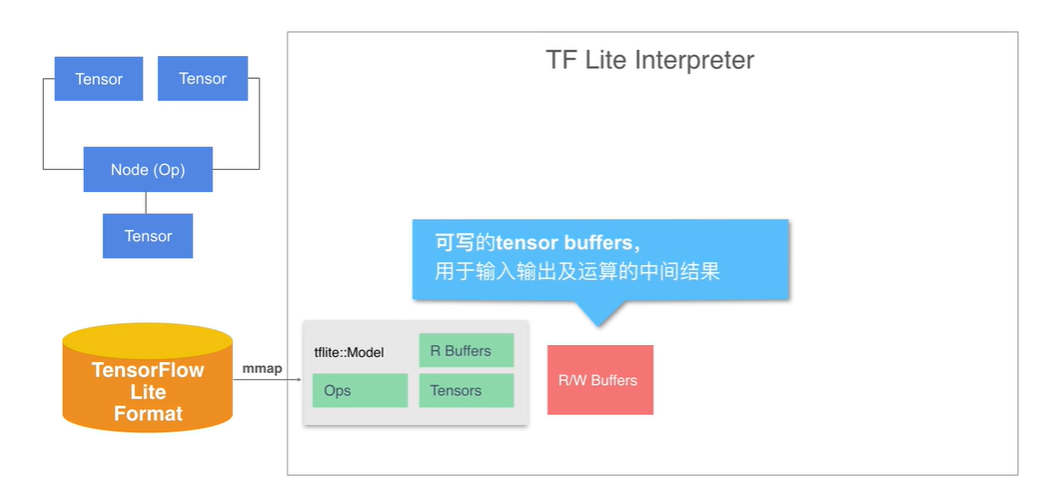
图示:Tensor Buffer 分配可写区域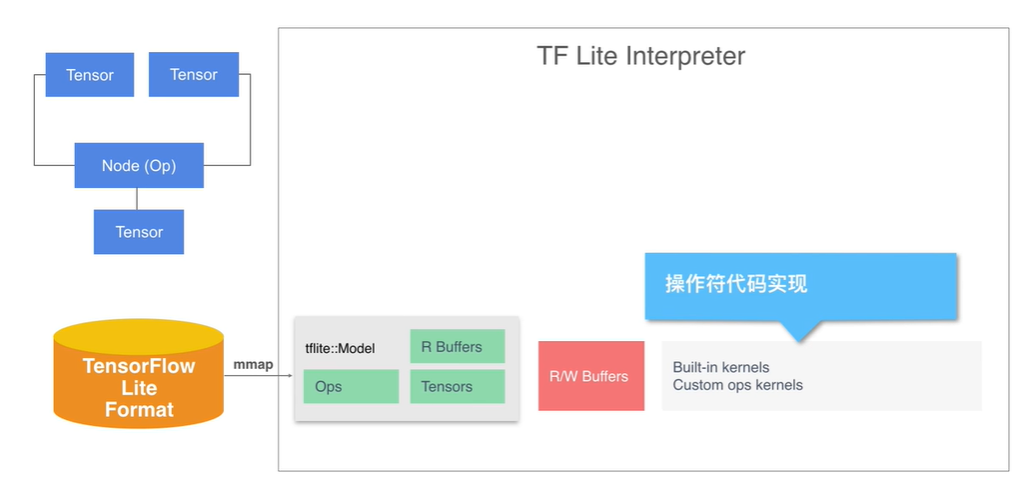
图示:interpreter 操作符的代码实现模块
- interpreter 还包含了具体执行计算的代码,称为 kernel 。model 中的各个 Tensor 被加载为 TFliteTensor 的格式,并且集中存放于 TFLiteContext 中。每个 Tensor 指针指向内存映射中的只读区域或者是已经分配的可写数据区域。
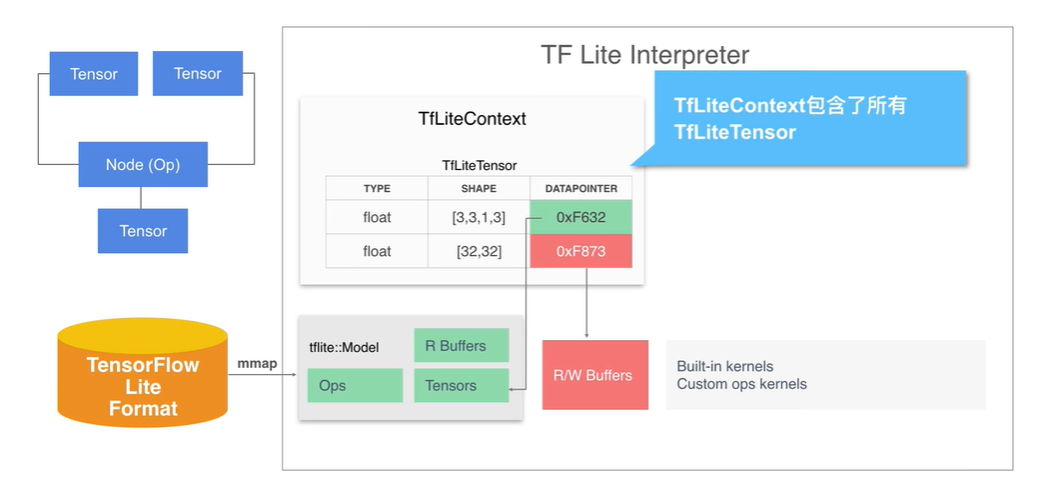
图示:TFLiteContext 信息结构
- model 中的 operator 被加载为 TFLiteNode 的形式。它包含了输入和输出的 Tensor 的索引值。Node 对应的操作符存储的是 TFLiteRegistration,它包含了指向 Kernel 的函数指针。OpResolver 负责维护函数指针映射关系。
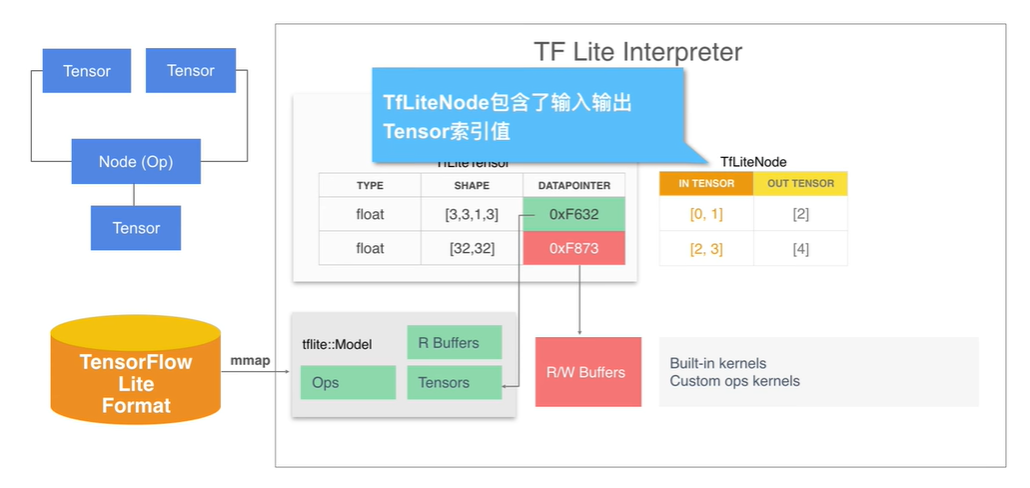
图示:TFLiteNode 信息结构
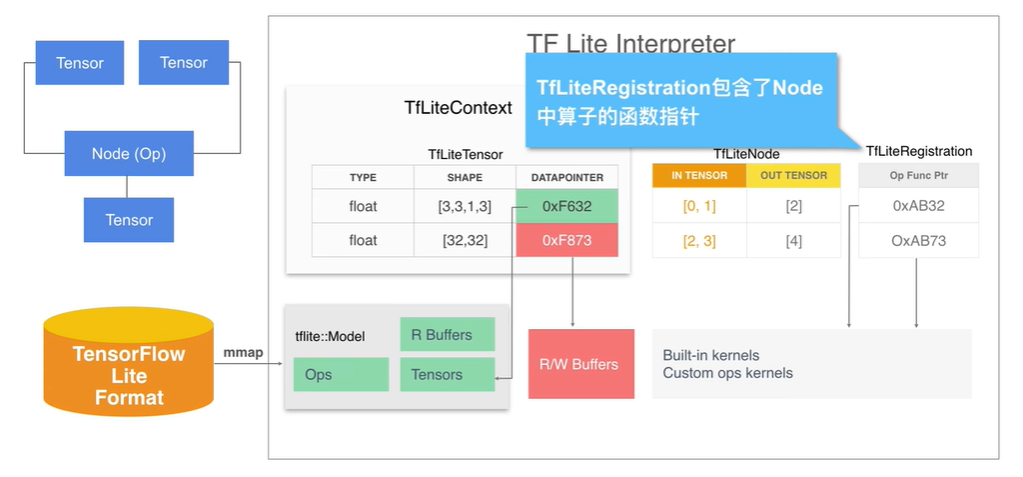
图示:TFLiteRegistration 信息结构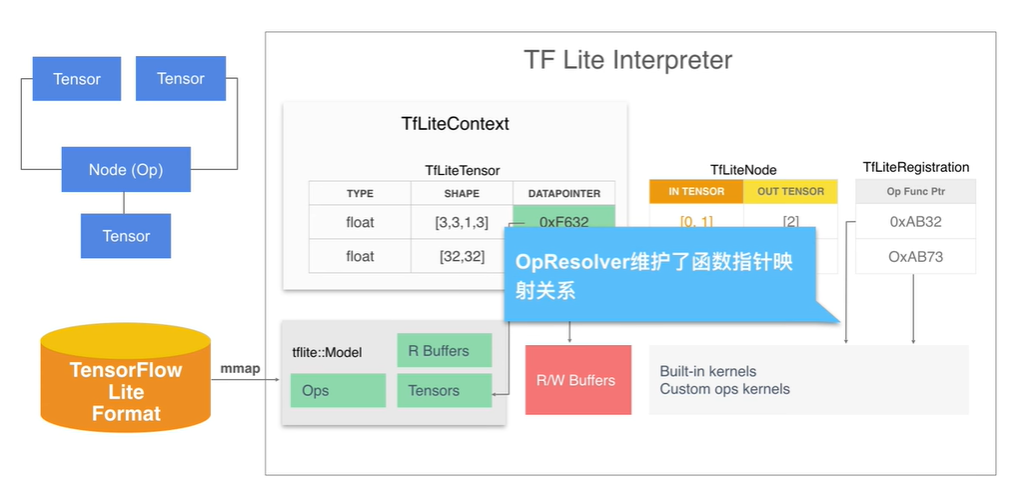
图示:OpResolver 函数关系
总结,TensorFlow Lite Interperter 在加载 model 的时候会确认 Node 的加载顺序,然后依照顺序执行操作。 TFLiteTensor, TFLiteContext,TFLiteNode,TFLiteRegistration 是重要的数据结构。更多详细的内容参见:TensorFlow Lite Original Source Code 数据结构(context.h, model.h, interpreter.h, register.h)
6)TensorFlow Lite 的 Hexagon DSP 性能优化
- TensorFlow Lite Delegate,事实上它是搭载 Hexagon DSP 的移动设备切利用 Hexagon NN Direct 加速库同时量化模型的运行方法。此方法的推出一定意义上加速了深度学习的在端侧的推理速度。同时,Hexagon NN 的加速方案植入 TensorFlow Lite 更加确认了低功耗的场景的使用。TensorFlow Lite 的 Hexagon DSP 的加速方案,如图所示-TensorFlow Lite 的端侧加速推理结构图。
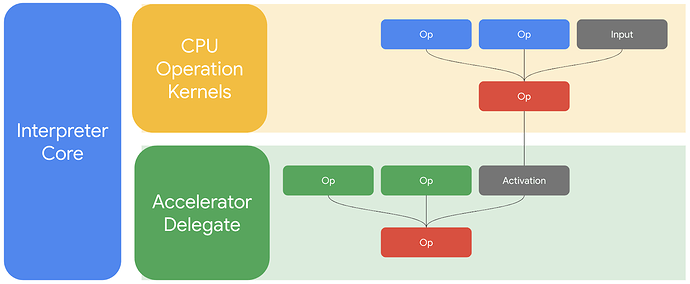
图示- TensorFlow Lite 端侧推理加速方案
**
- 如图 TensorFlow Lite delegate 在运行时的工作方式概览。图中支持的运算部分在加速器(加速器可以是GPU,或者 Hexagon DSP)上运行,而其他运算则通过 TensorFlow Lite 内核在 CPU 上运行。TensorFlow Lite delegate 能进一步实现 NNAPI 加速,并且适用于尚不支持 NNAPI 或缺少适配 DSP 的 NNAPI 驱动程序的设备。
- TensorFlow Lite delegate 支持大多数 Qualcomm® Snapdragon™ SoC 5,包括:
- 骁龙 835/845/855 (682 DSP,685 DSP,690 DSP)
- 骁龙 660/820/821 (680 DSP)
- 骁龙 710/845 (685 DSP)
- 骁龙 855 (690 DSP)
- TensorFlow Lite delegate 都支持哪些模型呢?
- 通过 量化感知训练 完成训练的定点 (uint8) 模型进行推理加速。例如,这类模型包括 Hosted models 2 页上的量化模型变体。这些模型都是针对通过 Post Training量化构建的模型。
- TensorFlow Lite delegate 能够执行许多计算量较大的运算(例如卷积层、池化层和全连接层的运算),只是需要在运行时前检查某些约束。如果不符合这类条件,则由 TensorFlow Lite 在 CPU 上执行该运算。有关运算和相应约束(如有)的完整列表,请参阅 TensorFlow Lite delegate 文档 。
- example 所示相关模型的链接,可以根据自己的需要进行 TensorFlow Lite 的端侧 Hexagon DSP 的工程推理部署,
模型的量化方法可以依照方法: 量化模型的训练 4。
- SSD MobileNet V1 [下载:[量化版本 2](https://storage.googleapis.com/download.tensorflow.org/models/tflite/coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip)([备用链接 2](https://tfugcs.andfun.cn/download.tensorflow.org/models/tflite/coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip))、[浮点版本 1](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md)]:对象检测- 小模型,部分运算在 Hexagon DSP 上运行。后处理运算在 CPU 上运行。- Inception V3 [下载:[量化版本 1](https://storage.googleapis.com/download.tensorflow.org/models/tflite_11_05_08/inception_v3_quant.tgz)([备用链接 1](https://tfugcs.andfun.cn/download.tensorflow.org/models/tflite_11_05_08/inception_v3_quant.tgz))、[浮点版本 1](https://storage.googleapis.com/download.tensorflow.org/models/tflite/model_zoo/upload_20180427/inception_v3_2018_04_27.tgz)([备用链接](https://tfugcs.andfun.cn/download.tensorflow.org/models/tflite/model_zoo/upload_20180427/inception_v3_2018_04_27.tgz))]:图像分类- 大模型,大部分运算在 Hexagon DSP 上运行。
- 如何使用 TensorFlow Lite delegate 呢?
第 1 步:添加 TensorFlow Lite Hexagon AAR 文件
在应用中添加 “tensorflow-lite-hexagon.aar”,这是除标准 tensorflow-lite AAR(Nightly 或 Release 版本)外所添加的另一个文件。
第 2 步:获取 Hexagon 库
运行 “hexagon_nn_skel*.run 2” (备用链接 1),然后接受许可协议。系统应当会提供 3 种 需加入应用 1 的不同共享库。此代理会根据当前设备自动选择性能最佳的共享库。
第 3 步:使用运行时 Delegate API
在推理过程中使用 Java API(如下例所示)或 C 语言 API(如此文档所示 5)调用 TensorFlow Lite 代理。
java 示例
// 创建代理实例。.
Interpreter.Options tfliteOptions = new Interpreter.Options ();
try {
HexagonDelegate hexagonDelegate = new HexagonDelegate (activity);
tfliteOptions.addDelegate (hexagonDelegate);
} catch (UnsupportedOperationException e) {
// 此设备不支持 Hexagon 代理。
}
tfliteInterpreter = new Interpreter (tfliteModel, tfliteOptions);
// 执行推理。
while (true) {
writeToInputTensor (inputTensor);
tfliteInterpreter.run (inputTensor, outputTensor);
readFromOutputTensor (outputTensor);
}
// 完成推理后丢弃代理。
tfliteInterpreter.close ();
if (hexagonDelegate != null) {
hexagonDelegate.close ();
}
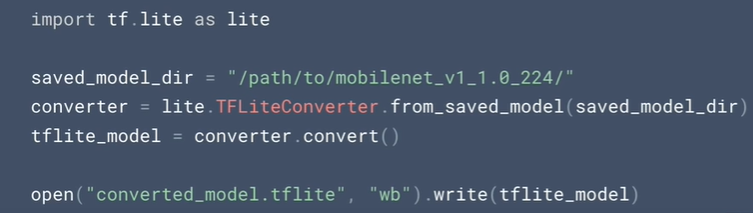
- TensorFlow Lite 的 tflite 格式模型的转换方法,原始的 Python 代码如下所示:
注意:此文档属于科普类型的文章,不具备任何商业价值,大部分内容都属于公开内容的综合汇总。本作者只是对相关的内容做了相应的重构。欢迎有需要的相关人员参与阅读

若有收获,就点个赞吧
0 人点赞
