1)NIR
由于NIR的光谱波段与可见光VIS不同,故真实人脸及非活体载体对于近红外波段的吸收和反射强度也不同,即也可通过近红外相机出来的图像来活体检测。从出来的图像来说,近红外图像对屏幕攻击的区分度较大,对高清彩色纸张打印的区分度较小。
从特征工程角度来说,方法无非也是提取NIR图中的光照纹理特征[15]或者远程人脸心率特征[16]来进行。下图可见,上面两行是真实人脸图中人脸区域与背景区域的直方图分布,明显与下面两行的非活体图的分布不一致;而通过与文章[5]中一样的rPPG提取方法,在文章[]中说明其在NIR图像中出来的特征更加鲁棒~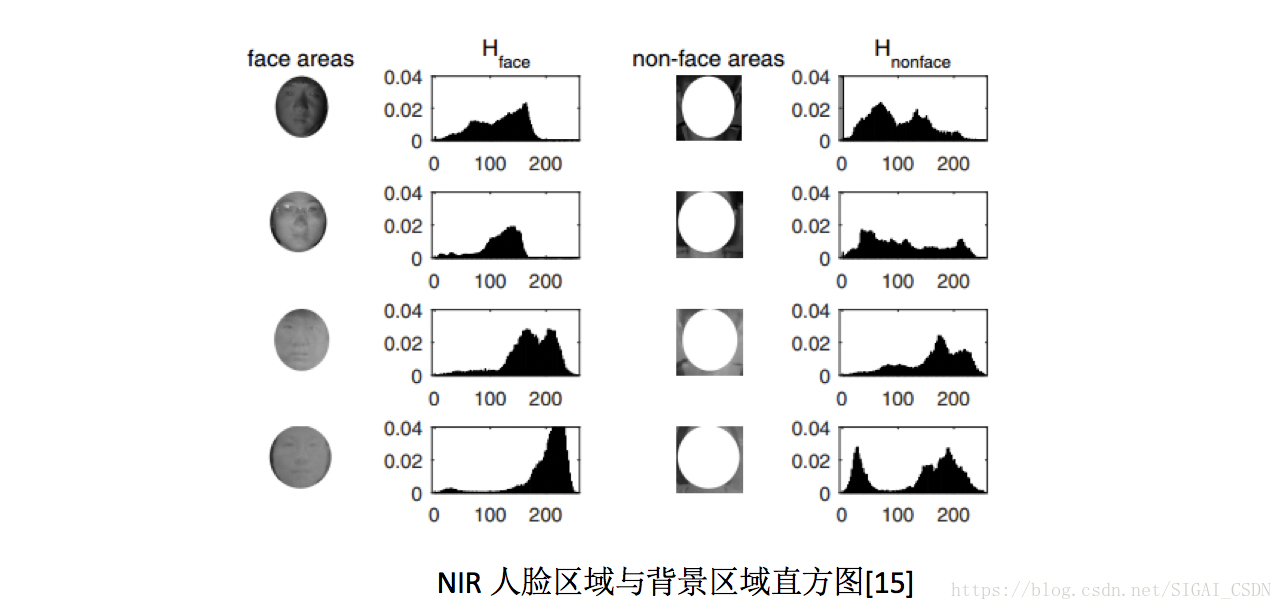
2)结构光/ToF
由于结构光及ToF能在近距离里相对准确地进行3D人脸重构,即可得到人脸及背景的点云图及深度图,可作为精准活体检测(而不像单目RGB或双目RGB中仍需估计深度)。不过就是成本较高,看具体应用场景决定。
3)光场 Light field
光场相机具有光学显微镜头阵列,且由于光场能描述空间中任意一点向任意方向的光线强度,出来的raw光场照片及不同重聚焦的照片,都能用于活体检测:
raw光场照片及对应的子孔径照片
如下图所示,对于真实人脸的脸颊边缘的微镜图像,其像素应该是带边缘梯度分布;而对应纸张打印或屏幕攻击,其边缘像素是随机均匀分布:
3.2 使用一次拍照的重聚焦图像[18]
原理是可以从两张重聚焦图像的差异中,估计出深度信息;从特征提取来说,真实人脸与非活体人脸的3D人脸模型不同,可提取差异图像中的 亮度分布特征+聚焦区域锐利程度特征+频谱直方图特征
IR图,深度图,点云的区别
- 深度图像也叫距离影像,是指将从图像采集器到场景中各点的距离(深度)值作为像素值的图像。获取方法有:激光雷达深度成像法、计算机立体视觉成像、坐标测量机法、莫尔条纹法、结构光法。
- 点云:当一束激光照射到物体表面时,所反射的激光会携带方位、距离等信息。若将激光束按照某种轨迹进行扫描,便会边扫描边记录到反射的激光点信息,由于扫描极为精细,则能够得到大量的激光点,因而就可形成激光点云。点云格式有.las ;.pcd; *.txt等。深度图像经过坐标转换可以计算为点云数据;有规则及必要信息的点云数据可以反算为深度图像。
- TOF是通过红外光发射器发射调制后的红外光脉冲,不停地打在物体表面,经反射后被接收器接收,通过相位的变化来计算时间差,进而结合光速计算出物体深度信息。不怎么受环境光干扰,缺点是分辨率暂时都做不高。
- 结构光是通过红外光发射器发射一束编码后的光斑到物体表面,光斑打在物体表面后,由于物体的形状、深度不同,光斑位置不同,通过光斑的编码信息与成像信息,进而计算出物体深度信息。结构光在室外效果很差,光斑成像容易受环境光干扰。
NIR介绍
- 在低光环境具备高灵敏度的近红外(NIR)相机,近红外相机有何独到之处?
“近红外光”(简称NIR) 是介于可见光和中红外光之间的电磁波[SMM1] ,因此人眼无法察觉它。近红外优化工业相机广泛适用于需要此波长范围的环境,即光照条件较差的应用,例如交通监控等。一直以来,以上应用都依赖价格昂贵的CCD芯片才能实现。
如今,最新的CMOS技术可在超过850 nm的近红外范围提升感光芯片的灵敏度。其方法是在可见光谱区应用了一层较厚的衬底层(相对于单色感光芯片而言)。通过引入近红外灵敏度较佳的工业相机产品,使得该类产品变得物美价廉,也同时增加了这类工业相机在机器视觉市场中的份额。
配备CMOSIS 200万像素 (CMV2000) 和 400万像素 (CMV4000) 芯片,或e2V 130万像素 (EV76C661) 芯片的近红优化外相机,在850 nm的范围仍能保持近40%的量子效率。与非近红外优化相机相比,近红外优化相机在该波长上的灵敏度系数要高出
- 哪些应用需要使用近红外相机?
有些[YY1] 应用领域和监测解决方案需要用到近红外相机,因为其具备广阔的波长范围,并且在正常光线条件下能获得高对比度图像。一般的工业相机在上述特定条件下无法胜任, 因为它们需要在良好的光线条件下才能捕捉到优质的图像。然而,创造良好光线条件需要投入大量的资金,其难度也不容忽视。这也直接造成系统成本增加,降低整体性价比。因此,近红外优化相机为监测类的用户简化和解决了难题。
典型的应用案例包括:需要在较差光线环境中或在夜晚工作的交通监控设施、使用位置传感光谱学对蔬果进行坏点检测,以及通过电致发光检测太阳能硅片
- 近红外优化(NIR)芯片的主要优势包括:
- 在红外范围具备高灵敏度
- 尤其在恶略照明条件下获得高对比度
- 针对许多具有特殊光谱特性的检测物保持高对比度
- 可与CCD相机抗衡的价格优势
- 可靠的生产流程和高品质的保证
Key Difference between Active IR image and depth image in Kinect V2 ?
kinect v2 中主动红外图像和深度图像之间的主要区别?
I just have a confusion in understanding the difference between the Active IR image and depth Image of Kinect v2. Can anyone tell me the what special features Active IR image have as compare to depth image?
我对了解Kinect v2的主动红外图像和深度图像之间的区别感到困惑。谁能告诉我有源红外图像与深度图像相比有哪些特殊功能?
In the depth image, the value of a pixels relates to the distance from the camera as measured by time-of-flight. For the active infrared image, the value of a pixel is determined by the amount of infrared light reflected back to the camera.
Sidenote: I think there is only one sensor that does both these. The Kinect uses the reflected IR to calculate time of flight but then also makes it available as an IR image.
在深度图像中,像素值与通过飞行时间测得的距相机的距离有关。对于活动的红外图像,像素值由反射回相机的红外光量确定。
小注:我认为只有一个传感器可以同时完成这两项工作。Kinect使用反射的IR来计算飞行时间,但也可以将其用作IR图像。
结构光
- 从平面到立体的秘密,结构光3D视觉技术中的其中一种,用于获取物体平面与深度数据。这项技术的原理是通过将激光散斑图像投射到物体表面,再由红外相机接收物体表面反射的散斑信息,交给ASIC处理芯片,最后根据物体造成光信号的变化计算物体位置和深度信息。
- 简单来说就是通过近红外激光器,将具有一定结构特征的光线投射到被拍摄物体上,再由专门的红外摄像头进行采集。这种具备一定结构的光线,会因被摄物体的不同深度区域,而采集不同的图像相位信息,然后通过运算单元将这种结构的变化换算成深度信息,以此来获得三维结构。
图示,结构光(左)& TOF (右)
图示,结构光原理图
关于结构光的方案如何设置呢?以下是对结构光的详细方案的一些统计
| 类别 | 方案 | 特点 |
|---|---|---|
| 相机结构光 | 单目IR+投影红外点阵 | 体积小 |
| 双目IR+投影红外点阵 | 体积大 | |
| 单目IR+投影相移条纹 | 功耗大 | |
| 计算单元 | ASIC | 支持高帧率/高分辨率,功耗低,成本稍高 |
| DSP+软件算法 | 支持低帧率/低分辨率,功耗中等,成本中等 | |
| AP+软件算法 | 支持低帧率/低分辨率,功耗高。成本低 |
从相机方案看:
case1:单目IR+投影红外点阵
case2:双目IR+投影红外点阵,等同于结构光+双目立体融合了,深度测量效果会 case1 好一些,比如Intel RealSense R200采用的就是双目IR+投影红外点阵,不足之处就是体积较大
case3:单目IR+投影红外点阵,虽然体积较小,但是效果会差一点
但从计算资源来看,
case1:直接用ASIC(专用集成电路)进行计算,成本稍微高一点,但是处理速度快,支持高帧率和高分辨率深度相机,关键是比通用芯片功耗低。
case2:DSP+软件算法,成本跟用ASIC差不多,但支持不了高帧率高分辨率,功耗比ASIC稍高。
case3:直接用手机的AP(Application Processor)进行纯软件计算,这个不需要额外增加硬件成本,但是比较消耗AP的计算资源。同样也不支持高帧率高分辨率,功耗比较大。
3D结构光使用的场景:**
- 除手机解锁外,3D结构光还被广泛用于刷脸支付、智能安防、空间扫描、机器人交互、商用屏显、体感游戏等领域。
- 刷脸支付领域,国内3D传感企业奥比中光自主研发的3D结构光摄像头,为支付宝、中国银联提供模组支持,通过3D人脸识别,可以实现快速安全便捷支付,目前刷脸支付设备已经成功落地全国。
- 以上提到的解决方案主要是消费电子领域,车载领域还未普及。
Time-Of-flight
- TOF是Time of flight也就是所谓飞行时间法3D成像,是通过给目标连续发送光脉冲,然后用传感器接收从物体返回的光,通过探测光脉冲的飞行(往返)时间来得到目标物距离。这种技术跟3D激光传感器原理基本类似,只不过3D激光传感器是逐点扫描,而TOF相机则是同时得到整幅图像的深度信息。TOF相机与普通机器视觉成像过程也有类似之处,都是由光源、光学部件、传感器、控制电路以及处理电路等几部单元组成。与同属于非侵入式三维探测、适用领域非常类似的双目测量系统相比,TOF相机具有根本不同的3D成像机理。双目立体测量通过左右立体像对匹配后,再经过三角测量法来进行立体探测,而TOF相机是通过入、反射光探测来获取的目标距离获取。微软kinect2即是基于TOF原理的深度相机。虽然,TOF 方案具有实时性好,算法简单,不受光照变化和物体纹理影响的优点,但受多重反射影响,分辨率低、成本较高。
图示:TOF原理图
TOF 的主要应用领域包括:
- 物流行业:通过 TOF 相机迅速获得包裹的抛重(即体积),来优化装箱和进行运费评估;
- 安防和监控:进行 People counting 确定进入人数不超过上限;通过对人流或复杂交通系统的counting,实现对安防系统的统计分析设计;敏感地区的检测对象监视;
- 机器视觉:工业定位、工业引导和体积预估;替代工位上占用大量空间的、基于红外光进行安全生产控制的设备;
- 机器人:在自动驾驶领域提供更好的避障信息;机器人在安装、质量控制、原料拣选应用上的引导;
- 医疗和生物:足部矫形建模、病人活动/状态监控、手术辅助、面部3D 识别;
- 互动娱乐:动作姿势探测、表情识别、娱乐广告。
RGB双目
RGB双目指的是利用双相机的视差获取深度信息的方式。RGB双目相机是非常依赖纯图像特征匹配,在光照较暗或者过度曝光的情况下效果都非常差,另外如果被测场景本身缺乏纹理,也很难进行特征提取和匹配。驾舱使用方面RGB的方案相对比较差用于图像识别和物体检测等。
总结
1.双目,消耗大量的计算资源,实时性会很差。基本于分辨率,检测的精度直接正相关。总之、分辨率越高,要求精度越高,计算就越复杂。而且,纯双目方案容易受光照,物体纹理性质影响。驾舱使用此方案,基本很多场景无法满足需求。
2.结构光,可以解决双目中匹配算法的复杂度和鲁棒性的问题,规避了双目方案的缺点。重要的是,强光下结构光核心技术激光散斑会被淹没。因此,此方案不太适合室外的场景。另外,长时间监控方面,激光发射设备容易坏,更换设备后,需要重新标定。因此,此方案对于驾舱比较适合,但是后期出现问题更换设备需要技术人员提供标定解决方案。
3.TOF方案,传感器技术不是很成熟。况且、分辨率较低,成本高,但是由于其原理与另外两种完全不同,实时性高,不需要额外增加计算资源,几乎无算法开发工作量,会是未来发展的一个重要方向。适合驾舱,但是需要足够的资金支持。
| RGB双目,结构光,TOF的方案对比 | |||
|---|---|---|---|
| 参数 | 双目 | 结构光 | TOF |
| 原理 | 双目匹配,三角测量 | 激光散斑编码 | 反射时差 |
| 分辨率 | 中高 |
中 | 低 |
| 精度 | 中 | 中高 | 中 |
| 帧率 | 低 | 中 | 高 |
| 抗光照(原理角度) | 高 | 适合室内 | 中 |
| 硬件成本 | 低 | 中 | 高 |
| 算法开发难度 | 高 | 中 | 低 |
| 外参标定 | 与其它算法融合需要 | 与其它算法融合需要 | 与其它算法融合需要 |
| 测量距离的方式 | 被动式 | 主动式 | 主动式 |
| 测量精度 | 近距离可达毫米级别的精度 | 近距离内能达到高精度0.01mm-1mm | 最高可达厘米级别精度 |
| 测量的范围 | 由于基线的限制,一般只能测量较近距离的信息。基线越长,测量范围越大,精度越低。 | 由于基线的限制,一般只能测量较近距离的信息。基线越长,测量范围越大,精度越低。 | 可测量的距离比较长,一般100m以内 |
| 外界影响 | 受光照和纹理的影响 | 受强光照的影响和黑色物体的影响 | 几乎不受外界环境的影响(对于玻璃,透明物体敏感基本无法工作) |
| 户外工作 | 受光照的影响 | 几乎无法工作 | 功率小的话影响较大 |
| 视野 | |||
| 帧率 | 从高到底都有 | 一般30fps | 较高,最高可达上百fps |
| 软件开发 | 高 | 中等 | 较低 |
| 功耗 | 较低,因为纯软件 | 中等,需要投射图案,只找照射局部区域 | 很高,因为需要全面照射 |

若有收获,就点个赞吧
0 人点赞
