在手机应用越来越多,机身越来越轻薄的今天。CPU卡顿问题、手机发热问题和待机续航问题越来越多。限频、降帧,这些常用的手段会降低用户的体验,并不是根本的解决之策。我们迫切需要一个低功耗高性能的秘密武器,来解决遇到的上述问题。DSP作为手机中已配置的资源,其拥有强大的计算能力和更低的功耗,在相机视频、游戏这类高负载的应用场景,如果能充分利用,可以很好的降低CPU的负载,减少发热和卡顿。
本文主要基于高通Hexagon DSP平台,介绍SIMD加速技技术。可以为手机功耗问题提供一些切实可行的解决方案。
一、背景介绍
SIMD 全称Single Instruction Multiple Data,单指令多数据流。是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在图像处理过程中,由于图像的数据常用的数据类型是RGB565, RGBA8888, YUV422等格式,这些格式的数据特点是一个像素点的一个分量总是用小于等于8bit的数据表示的。如果使用传统的处理器做计算,虽然处理器的寄存器是32位或是64位的,处理这些数据却只能用于他们的低8位,效率太低。如果把64位寄存器拆成8个8位寄存器就能同时完成8个操作,计算效率提升了8倍。这就是SIMD指令的核心思想。随着后来的发展慢慢cover的功能越来越多。
DSP(digital signal processor)是一种独特的微处理器,是以数字信号来处理大量信息的器件。是高通或者MTK的SoC套片中为数据处理做过优化的专用处理器单元。一向以低功耗,高性能著称。高通通过引入HVX,也就是Hexagon Vector eXtensions(Hexagon矢量扩展引擎)来加强处理器的矢量计算能力。其高效、强大的处理能力正是基于SIMD技术,可以并行处理1024bit的数据,在视频处理、AI等对需要处理大量数据的领域有着CPU无法比拟的优势。相比强大的CPU,DSP尤其擅长在低功耗下处理这些任务。随着手机使用需求的不断扩大,电池容量却很难提高,如果能利用好DSP低功耗的特点,可以很好的解决一些遇到的发热、卡顿等性能问题。
高通Hexagon DSP以独特的体系架构领先一步,下面以高通Hexagon V66 DSP来做简单介绍。
二、cDSP 运算部件的特点
结构特点:
DSP中包含cDSP(Compute DSP)、aDSP(Application/Audio DSP)、mDsp(Modem DSP)、lDSP(Low power DSP)等多个组成单元。其中cDSP是DSP中的核心计算单元,在SoC的架构中与CPU处于同等地位,其也可以访问系统总线,访问DDR等。
cDSP主要部件包含:
标量处理器:Scalar Processor(Hexagon),一般用于逻辑控制,支持整型和浮点型数据运算。
矢量处理器:Vector Processor(HVX/Hexagon Vector Extension),处理向量运行;
二级缓存:L2 cache,可用于复杂场景的内存加速。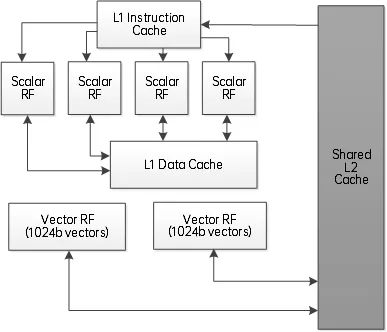
图1 cDSP架构图
Hexagon处理器中包含常见的处理单元XU(Execution Unit)、$(Cache)、RF(Register File)、MMU(Memory Management Unit)等。每个硬件线程均包含32个向量寄存器,4个predicate寄存器。每个向量寄存器宽度为1024bit,可以以word、halfword或byte三种方式进行运算。每个predicate寄存器包含128bit。两个向量寄存器(vector)可以组成一个寄存器组(vectorPair)。
三、指令介绍
通过在idl文件中定义供上层调用的接口,会编译生成一个后缀名为skel的so文件,里面接口用DSP实现。通过FastRPC接口实现Applications PRocessor对DSP Processor底层实现的调用。
HVX 提供了如查表(vlut/vscatter/vgather)、移位(vror/vasl/vasr/vlsr)、拼接(valign/vlalign)等多种指令,可以组合实现各种功能。
1、拼接 (valign/vlalign)
valign/vlalign:去掉右边/左边寄存器的Rt个字节,将剩下的拼接在一起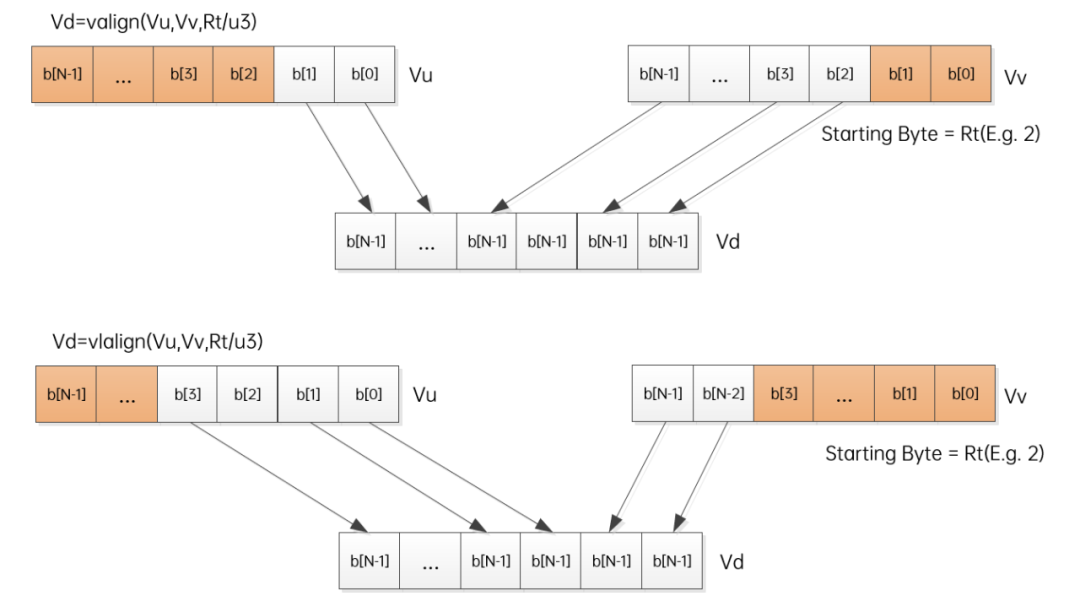
2、移位 (vror/vasl/vasr/vlsr)
vror:循环右移,将一个vector首位当做一个环,右移Rt个字节。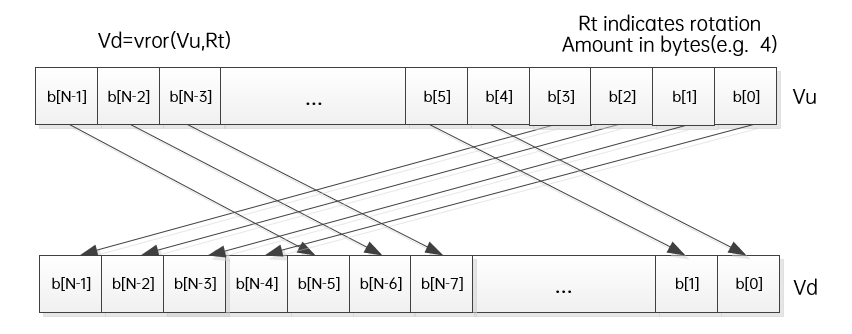
vasl/vasr/vlsr:逻辑移位
vasr/vlsr 都是右移,区别在于是有符号位和无符号数
可以用在乘除运算,图像10bit —> 8bit的位数转换等场景。
3、拆分 (vshuffe/vshuffo/vshuffoe/vdeal/vshuff)
vshuffe/vshuffo:将even/odd位挑出来放一起
vshuffe/vshuffo:同时执行两个操作,分开放置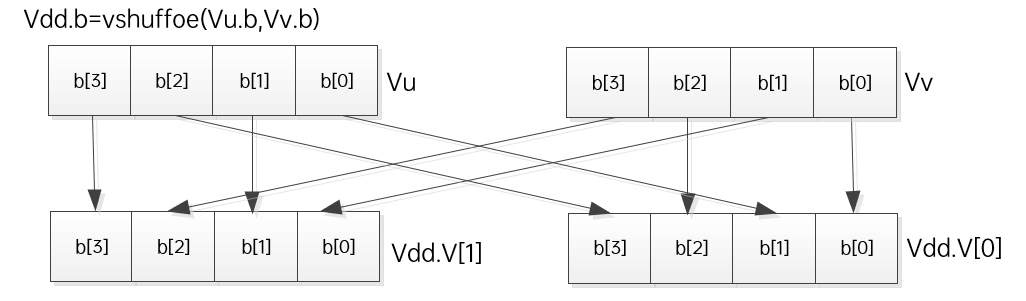
vdeal 奇数/偶数收集起来分两个部分放置
vshuff 跟vdeal 操作相反,将高低两个部分分散到奇/偶位
4、打包 (vpacke/vpacko/vpack)
vpacke/vpacko:可以收集两个vector 中的奇数位/偶数位
vpack:给两个vector 压缩到一个vector,从half word —> byte
5、查表 (vlut/vscatter/vgather)
vlut:可以查256字节的小表
vscatter/vgather 可以查64kb大小的表
四、算法优化示例
例1、对一个输入矩阵取绝对值
C++ 一般实现方法: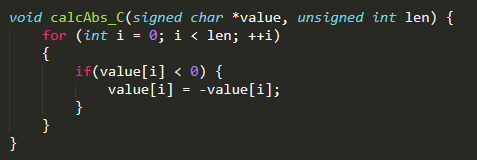
HVX 实现方法: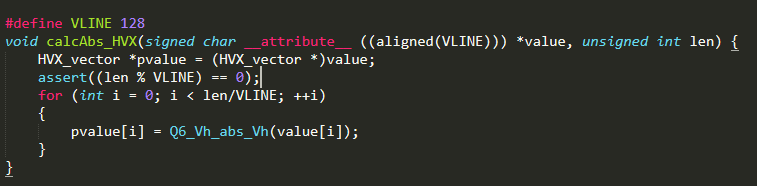
通过上面的对比可以看出,HVX 并行处理可以大大减少循环次数,只有原来的128分之一,显著提高运算效率。其中的Q6_Vh_abs_Vh()这个函数是HVX封装的intrinsic 接口。可以通过查询HVX programming guide 文档选择合适的指令。
例2、使用L2 Cache加速
对例1,使用L2 Cache加速
使用L2 Cache 提前将fetch需要访问的数据,能使内存读取的速度提高一倍以上。
需要注意几点:
1)需要提前prefetche
2)三条以上的fetch指令,如果前面的fetch指令没有执行完会被后面的冲掉
3)fetch的内容读取比较快,写入有时会很慢,可能有cache miss
4)通常fetch 8kb在以下,多发出几个fetch指令效果会比较好
L2 Catch 的使用可以参考HVX编程指南文档。
例3、多线程优化
HVX支持多线程,开启多线程需要四个步骤:
1)prepare&check
2)prepare data and callbackFuntion
3)submit job
4)synctoken job token 同步令牌
通过合理的分配任务,开启多线程可以将大幅减少算法的运行时间。
五、总结
SIMD技术,是一种“数据并行”的加速方案,在处理向量计算的情况下,同一个向量的不同维度之间的计算是相互独立的。与CPU或GPU相比,DSP有着低功耗,高性能的特点,在大数据量处理方面还是有着很大的优势,并且在如人工智能、视频处理等领域有着广阔的应用前景。合理的利用DSP的并行计算能力,可以很好的从CPU上offload一部分负载,从而减少CPU卡顿和手机发热的问题。
参考文献:
https://zhuanlan.zhihu.com/p/31271788
https://new.qq.com/omn/20180527/20180527A099CU.html
https://developer.qualcomm.com/software/hexagon-dsp-sdk/dsp-processor

若有收获,就点个赞吧
0 人点赞
