1)Hexagon DSP 的介绍:
- Hexagon Digital Signal Processor (DSP),高通的Hexagon计算DSP,作为高通研发的世界一流处理器,集成了CPU和DSP功能,能支持移动平台多媒体和modem功能的深度嵌入处理。拥有高级的可变指令长度、超长指令字、支持硬件多线程机制的处理器架构,Hexagon架构和核心家族给高通带来了modem和多媒体应用的性能和功耗优势,是高通骁龙处理器的关键组件。
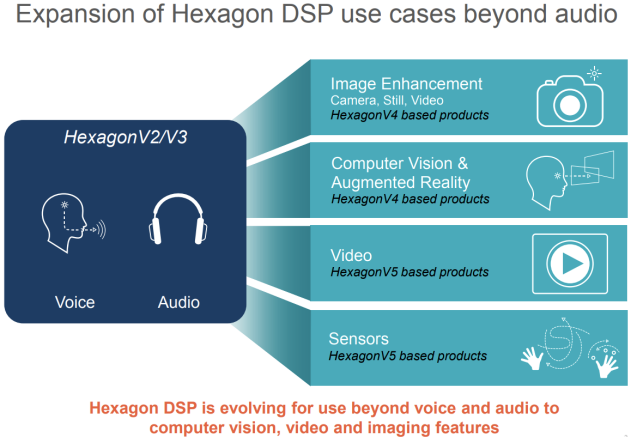
图-1 DSP 的 audio 方案
早期DSP仅用于语音和简单的音频视频解码播放,随着智能化产品的加速摄像头和传感器功能的信号处理任务都可由DSP完成,DSP比CPU更擅长在低功耗下处理这些任务。
其基本特点有:
- DSP相比CPU可实现高性能计算和高能效(省电);
- 用于卸载CPU任务,利用异构计算支持实时在线任务;
- 音频任务。在无延迟、无失真的情况下流式传输音频,消除背景噪声;
- 视觉任务。文本识别、对象识别、图像增强和图像内的面部识别。
2)Hexagon DSP 的架构特性

图-2 DSP 的特性
DSP 的主要功能是围绕在计算单元,以及多媒体单元展开相关的开发使用的。因此,DSP也可以称作特殊处理的计算单元。同时,包括摄像头和传感器功能的信号处理任务都需要借助DSP来完成,相比强大的CPU,DSP尤其擅长在低功耗下处理这些任务。3) Hexagon DSP 的不同版本的介绍
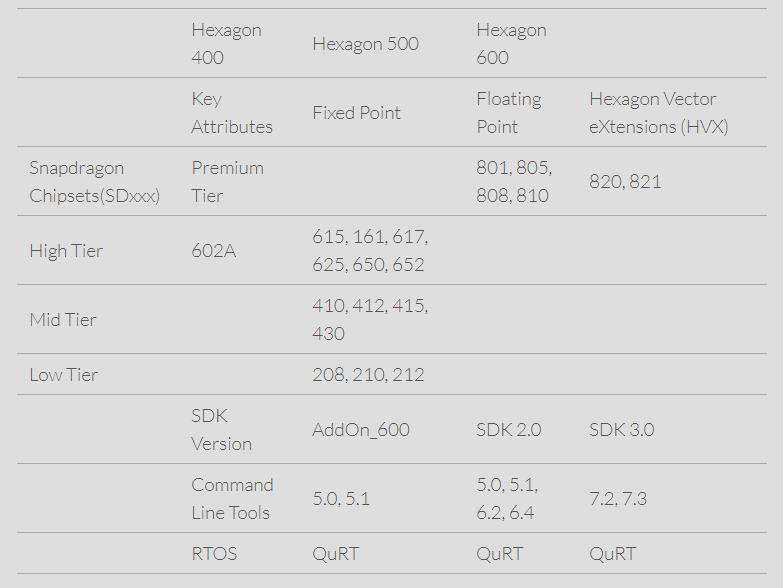
图-3 Hexagon Core Architecture
图-3所示分别是Hexagon400,5000和600系列,其中Hexagon 400、500、600系列的关键特性分别支持定点、浮点、Hexagon Vector eXtension(HVX)。不同的DSP系列同时也对应了相关的Snapdragon SoC芯片型号,分别有旗舰、高端、中端和低端类型。Snapdragon 800系列都属于旗舰级别的芯片,占据了Hexagon 600系列的DSP。不同DSP系列也有对应的不同的SDK版本和命令行工具,支持的实时操作系统是QuRT(更多关于QuRT操作系统的内容可以自行研究,不在做解释)。
4)Hexagon DSP 的发展历史
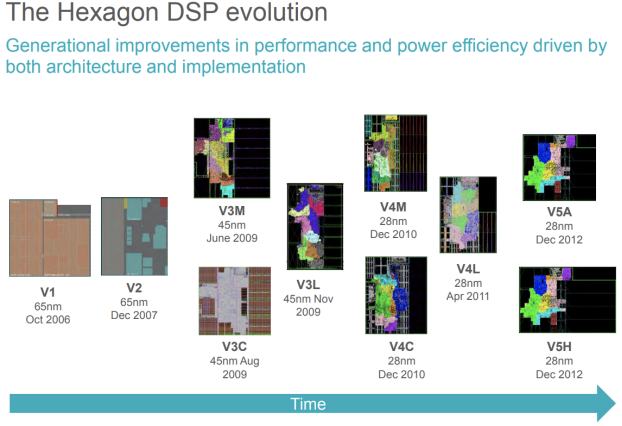
图-4 Hexagon DSP 的发展历程
- 2004 开始研发高性能DSP处理器架构
- 2011 发起Hexagon试用计划,可以使客户在DSP上编程,从而探索性能、功耗和其它需求释放ARM核心所带来的性能和功耗提升
- 2012 多个Hexagon核心处理器伴随着高通发布不同 4G LTE modem 推出,现在已发展到第5代,并且集成进了所有的modem和应用芯片当中
2013 发布Hexagon DSP研发环境-Hexagon SDK
5)Hexagon DSP 的功能特性

图-5 Hexagon DSP 的功能特性硬件多线程(图-5 左下角):由时间多线程(TemporalMultiThreading,TMT)实现,该模式下频率600MHz的物理核心可被抽象成三个频率200MHz的核心。通过高优先级调度算法来调度尽可能多的执行单元,可以认为硬件线程是使用共享内存的独立处理器核心,并用传统软件线程来编程。由RTOS负责把软件线程映射到几个处理器硬件线程上,它在全局调度最高优先级的软件线程并且总是把中断导入到最低优先级的硬件线程;
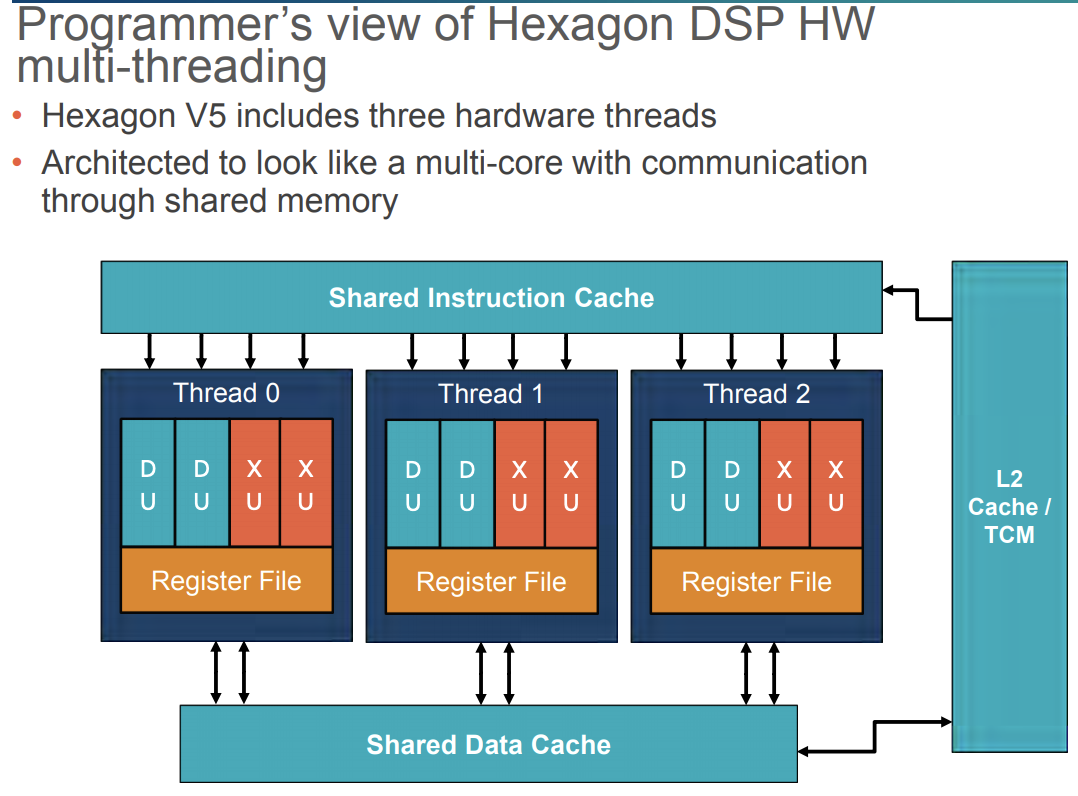
图-6 Hexagon DSP 的多线程运算
- 特权级:一种机制来保护数据和阻止恶意行为,确保计算机安全(可能是代码签名,目前安卓上使用Hexagon限制很多,不仅有高通SOC也有要HVX支持、禁止Secure boot、对手机ROOT、将dsp的库上传到对应的系统路径外,还需要下载Hexagon SDK去对代码签名,才能跑Hexagon NN。其中小米的MACE DOCUMENTATION 有相关的说明,更多内容此处不做解释。
- 指令集优化
- 允许相关/不相关指令分组:例如,通常的加载-比较-分支语句能在单个Hexagon指令包中表达,这样的技术使来自不规则控制代码应用中的指令高度并行执行成为可能。
- 支持超长指令字(VLIW,Very Long Instruction Word)风格的指令分组:VLIW是一种非常长的指令组合,它把许多条指令连在一起,增加了运算的速度;
- 集成丰富的专门适应于信号处理的指令:包括16位和32位小数和复杂的数据类型、32位浮点型、完整的64位整数运算;
- 支持计算向量扩展(HVX):主要用于视频,计算机视觉来减轻 CPU 的运算负担(更多关于 HVX 的介绍见 SNPE 的推理 Engine SDK 的介绍和相关的 Documentation)。
- 引入低功率岛(low power island):
- 一个独立、用于传感器持续工作时关闭其它芯片来省电、基于Hexagon架构的DSP;
- 原生支持Android L接入,包括计步器或活动计数器,以及传感器辅助定位等组件都能以更低的功耗持续运行;
- 低功率岛和传统DSP一样具备可编程能力。
总结: Hexagon DSP 的架构的核心设计:如何在低功耗的情况下能够保持高性能地处理各种各样的上层的应用(包括,不限于 Linux-x86,ios,Android 等操作系统下的上层运用)。
6)Hexagon DSP 的架构的特点
DSP 是完全不同于 CPU, GPU 的架构特点,其中最为关键的内容是:
- DSP最大化了每个时钟周期所能完成的工作:DSP旨在执行复杂的并行计算。例如,Hexagon DSP能够执行主要的快速傅氏变换(FFT)循环,即在一个时钟周期进行29个“精简指令集计算(RISC)操作”。通过搭载针对FFT进行优化的硬件和指令集架构(ISA),FFT可在更短的时间内以更高的性能——以及更低的功耗运行。
- DSP在较低时钟频率下提供高性能,以节省功耗:功耗与时钟频率和电压的平方成正比,以更高频率运行时钟需更高电压,这导致功耗的迅速增长。例如,Hexagon DSP能够通过硬件多线程技术和最大化每个时钟周期所能完成的工作,在低时钟频率下又能提供高性能。
7)Snapdragon NPE - Hexagon DSP runtime
DSP主要的应用就是处理 AI 中的神经网络。以下内容主要对 Snapdragon 855 的 soc 做相关的介绍,其中 Snapdragon 855内集成Hexagon 690(更多内容参见: Snapdragon 855 介绍)。

图-7 Snapdragon 855 - Hexagon DSP 690
- Q6:依据官方文档的介绍应该是一个调度器用于编排管理向量加速器和张量加速器。相关的文档中有查阅到DSP有QDSP5,QDSP6架构,猜想这个Q6是QDSP6的缩写(更多细节没有找到相关的介绍,如果有相关的说明欢迎各位补充说明)
- HTA(Hexagon Tensor Accelerator):张量处理单元,最多支持16位的数据(16位的Data 支持的是SNPE里的AIP Runtime,Snapdragon 855 中的 Hexagon DSP 仅且支持int8),为复杂向量矩阵结构和多维向量数组服务,如卷积,集成HTA的核心是为了更强大的图像处理能力。Hexagon 690首次引入1个张量加速器(HTA),为特定的复杂机器学习任务提供更高的吞吐量。据高通的宣传提及,骁龙 855 与前代移动平台相比可实现高达 3 倍的 AI 性能提升,而与华为麒麟 980 相比,性能提升最高可达 2 倍;
- HVX(Hexagon Vector eXtensions ):Hexagon 690包含4个1024b的HVX向量处理单元(上一代Hexagon 680/685包含4个标量处理单元和2个1024b的向量处理单元),主要应用在机器学习任务,大多是针对INT8优化(SNPE 的 DSP Engine 仅且支持 INT8 类型)。
8) Snapdragon NPE - Hexagon AIP runtime
AIP (AI Processor) Runtime是Q6,HVX,HTA三者 执行模型时候的一层软件抽象。实时上都是有硬件 DSP 来执行的,只是内部设置了扩展指令来实现 HTA/HVX的卷积运算。
- AIP 执行的前提条件:
- 看硬件设备是否支持(SNPE 支持的硬件列表如图-8所示:);
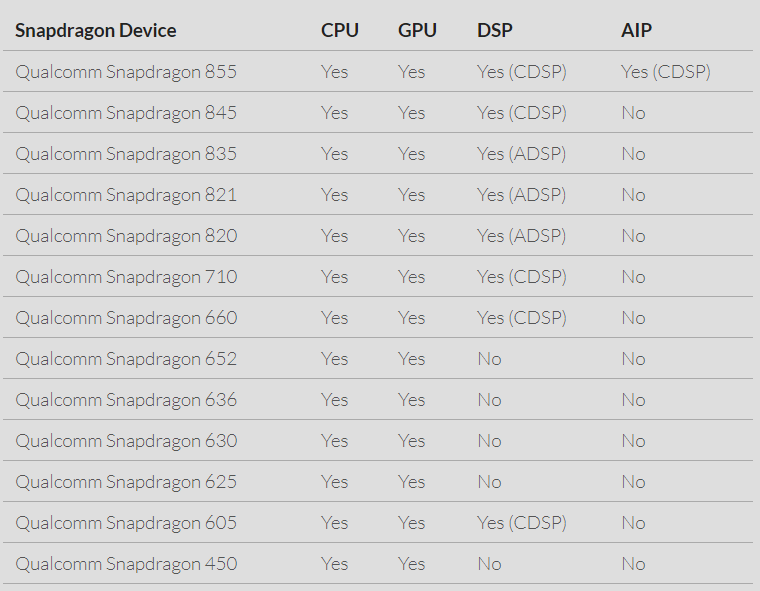
图-8 Snapdragon NPE 支持的 Snapdragon SoC 型号
- 量化模型如caffe转DLC格式时(图-9 HTA 模型的转换),需模型量化命令中带–enable_hta参数(–enable_partitions参数可选,表示一部分即subnet在HTA上执行,一部分即subnet在HNN上执行,调度通过Q6。)。 相比量化,这个过程会调用HTA编译器,将编译好的AIP执行部分以二进制形式嵌入到DLC中(更多内容参见 SNPE 官方 HTA 小节介绍 SNPE HTA 官方介绍 )

图-9 Snapdragon NPE HTA 的模型转换流程
Snapdragon SoC 设备上使用 DSP 和 AIP(也是DSP)的runtime是动态加载的,来实现 SNPE 与 AIP runtime 的通讯。如安卓需要将对应DSP的库文件上传到对应路径,并export导入相关动态库和设备位置的环境变量ADSP_LIBRARY_PATH,ADSP或CDSP(即无论DSP或AIP runtime)都需要该环境变量。
2. 内部调度:
SNPE 在用 AIP 计算时,会通过加载 DSP 的动态库从而与 AIP runtime 通讯,通过调度管理器 Q6 去管理使用 HTA 和HNN,图-10 所示 Q6 是 Hexagon DSP 上的一部分,Q6 部分通常意义应该指的是软件层面。
- 模型调用 AIP 执行过程中,SNPE Runtime 上的 AIP runtime 会调用 DSP 执行器(executor,位于DSP动态库中),DSP执行器来调用 HTA 和 HVX 来管理模型的执行:
- 当DSP executor遇到HTA模型(部分),会通过HTA Driver调用HTA来执行模型该部分subnet;
- 当DSP executor遇到HVX模型(部分),会通过Hexagon NN来调用HVX执行该部分subnet。
- 不同部分在 DLC 量化过程中将相应的描述信息写到了量化后的 DLC 文件中,DSP executor 遇到对应描述信息从而选择对应硬件驱动调用执行,图-10 所示 Hexagon DSP 的执行架构。
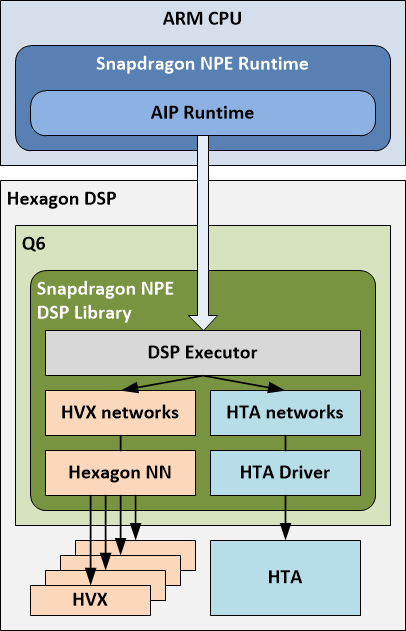
图-10 Hexagon DSP 的执行架构
Hexagon DSP 的 runtime 分为 ARM CPU 和 Hexagon DSP 两部分,两部分又有各自软硬件层面,箭头是指调用关系。两部分中,Q6很大可能是固化到硬件层面的调度器类似driver,SNPE文档中描述的 Q6 类似调度器(orchestrated by Q6),希望通过 Hexagon NN 与 HVX 硬件、HTA Driver 与 HTA 硬件完全打通。
3. 模型的执行
- 模型在量化过程中选择是否启用因–hta_partitions 对应的层数,如果选择启用得到的模型会包含 subnet。在执行过程中遇到subnet 会被 AIP runtime 打断,根据 subnet 描述信息调用不同的硬件设备执行。
- HTA subnets:模型部分由 HTA Compiler 编译,位于 DLC 文件得到 HTA 部分;
- HNN subnets : 模型剩余部分可在 DSP 上调用 Hexagon NN 库完成计算。
- 目前,AIP只支持单独的 HTA subnet + 单独的 HNN subnet。此外,SNPE HTA 官方介绍 小节中还提到其它限制:HTA和 HNN subnets 只支持层的单一输入与输出;HTA subnet 需要从第一层开始 。
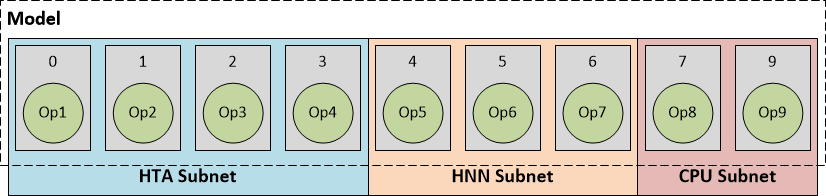
为了清楚地描述模型执行流程,描述DLC中的模型组成如下图所示,圆圈表示模型中的计算操作,方块表示一层。
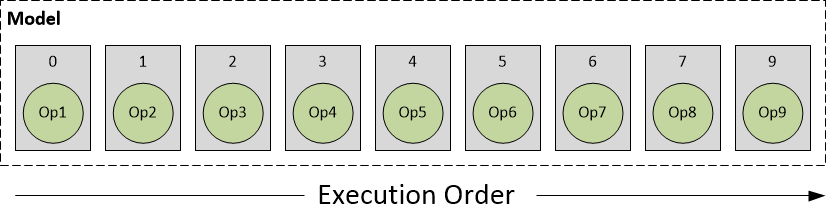
关于 HTA 的使用、根据HTA、HNN subnets 的分片,可将模型执行分为如下几种情况:
- HTA subnet:runtime识别出DLC中描述信息整个网络都是HTA网络,完成计算后,如有必要先做计算结果的转换和反量化,再将输出结果返回给ARM CPU;
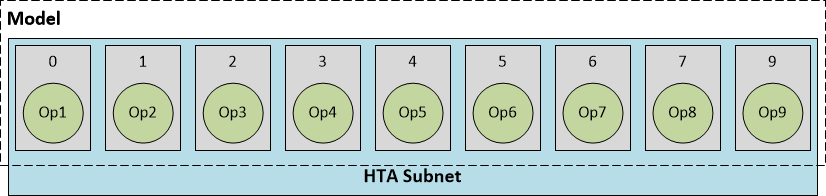
- HTA subnet + HNN subnet:根据量化时的参数选择,模型的0-3层在HTA上计算,后面在HNN上计算。HTA subnet的输出交给HNN subnet作为输入,最后将结果给ARM CPU(同样,如有必要则需要反量化或转换操作);
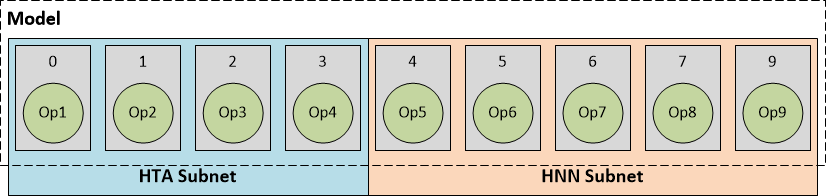
- HTA subnet + HNN subnet + CPU subnet:这部分不同在于,前两个子网络在AIP上计算,最后几层交给ARM CPU完成计算。
9)Hexagon DSP 的总结
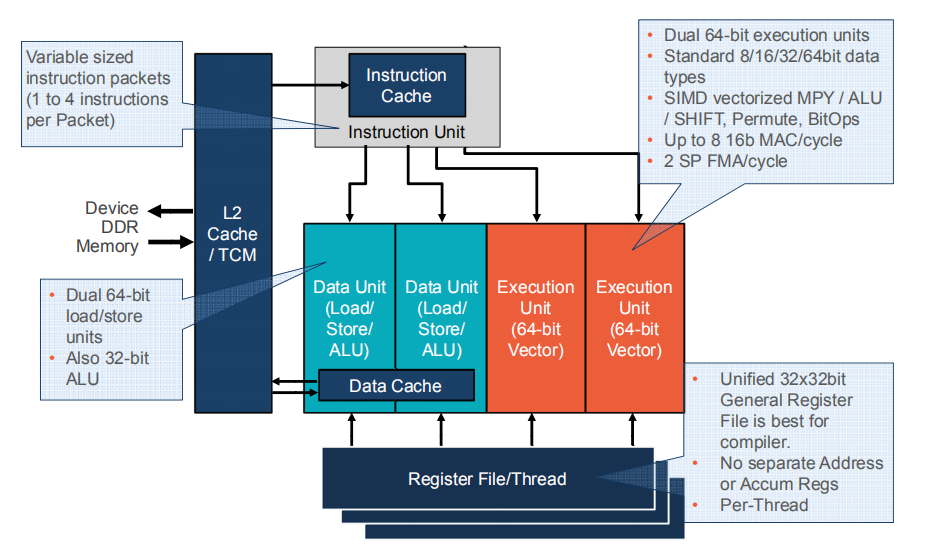
- 如图所示,DSP主要分为L2-Cache,Instruction Cache,以及 Data Cache。其中每个对应的 Cache 占用的内存是256Kbytes,16Kbytes,32Kbytes。完整的 DSP 的运算单元就是这样的组成。
- Hexagon 690 是 Qualcomm DSP 的迭代产品。与 Hexagon 680 和 685 相比,690 在 HVX 矢量管道数量上增加了一倍(其中,680/685 包含四个标量单元以及两个 1024b 矢量处理单元)。在标量管道性能方面,新设备的性能增加了 20%,这可能是由于微体系结构变化或时钟速度越高。在矢量方面,新的DSP 690 包含四个 1024b 矢量管道,使这些单元的处理能力翻倍。

- Hexagon DSP 690,它引进了一个新的专用”张量加速器”单元,该单元似乎在较大的块内紧密耦合。这很可能是一个通常更简单的 MAC 阵列,类似于其他供应商的神经网络推断引擎。实际上,这代表了高通的第一代专用ML推断引擎,尽管高通确实把它作为4th生成”AI 引擎”(以前此术语指的是在 CPU、GPU 和 DSP 上推断的 ML)。
- 高通在以前的体系结构中一直纠结的有趣限制之一是 DSP 无法处理传统的 DSP 工作负载以及 ML 推理工作。然而,对于Snapdragon 855,高通已经确认,新的Tensor单元能够与矢量单元同时独立工作。这意味着传统的图像处理任务现在可以与推理任务并行完成,从而极大地提高了新 Snapdragon 平台上推断的实际可用性。
除了矢量和张量单元外,还有一个新的语音助手AI模块,旨在加速普通人工智能助手的处理(语音主要体现在谷歌和百度)
附录:Hexagon DSP 685 架构
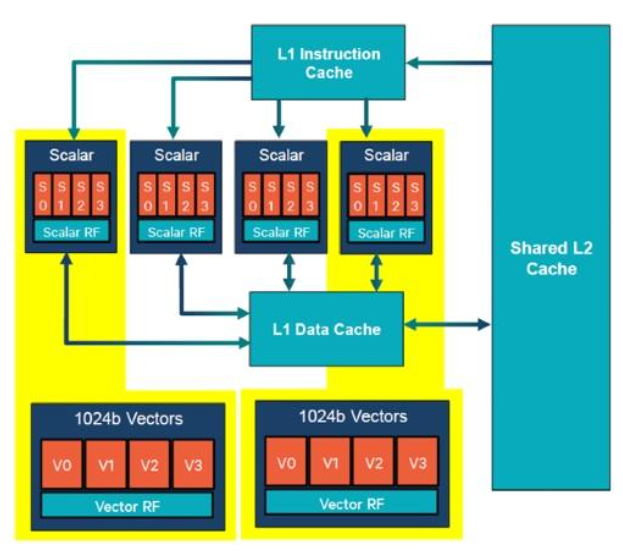
如图所示的Hexagon DSP 685 的架构来看包含四个标量单元以及两个 1024b 矢量处理单元,vector部分是机器学习、深度学习的基础单元。通过特殊指令和安排(Hexagon 685 DSP 的 HVX 体系结构),可加速某些标量和矢量操作。
- HVX 在图像传感器处理方面提供了另一大优势。Hexagon 685 DSP 的 Snapdragon 设备可以绕过设备的 DDR 内存控制器,将数据直接从成像传感器流式传输到 DSP 的本地内存 (L2 缓存)。当然,这减少了延迟,但也缩短了电池寿命 - Snapdragon 处理器旨在在整个操作过程中空闲。
注意:此文档属于科普类型的文章,不具备任何商业价值,大部分内容都属于转载或者复制其它作者的内容。本作者只是对相关的内容做了相应的总结和重构。欢迎有需要的相关人员参与阅读。

若有收获,就点个赞吧
0 人点赞
