综述
1)使用4个单色鱼眼相机, 且使用者的手至少会落在两颗相机的视野中
2)深度学习:a,手部检测算法网络;b,手部关键点回归算法网络;
3)可伸缩的半自动机制以及结合人工标注和自动跟踪式的大量搜集真实场景的数据
4)跟踪检测的算法:a,降低主要的计算成本;b,增加平滑度;
5)相关处理器的效率,PC机60HZ,MobileEnd 30HZ
6)手势跟踪是Oculus Quest的 defaut function
引文
1)主流的商用头盔类型:
a,Oculus Quest
b,MicroSoft Hololens
c,HTCVive
2)VR/AR的常见输入方式:
a,鼠标,键盘
b,游戏控制器,6自由度运动控制器
c,可穿戴手套
d,计算机视觉手势跟踪
3)手势跟踪的方法:
4)陈旧方案存在的问题:
a,单个RGB相机在预测3D手势存在尺度模糊的问题
b,基于RGB的方法专注于关键点回归,不能渲染真实手或者重定向手的运动
c,基于手姿势和形状的重建,不能保证手形随时间的一致性
5)本算法的发明:
a,使用4个以自我为中心的单色鱼眼相机,对三维手部姿态进行估计
b,通过跟踪的历史,提高跨帧的时间平滑性和跨视图的空间一致性
c,通过可移植的轻量级数据搜集方法,生成不同的高质量标签
d,单色相机代替RGB相机,在弱光下比RGB相机有更好的信噪比
e,鱼眼透镜扩大视野
f,关键点的回归可以提供暂时的光滑结果,解决自遮挡问题
数据的生成:
- 现有RGB手势数据训练得到的算法模型,无法适应新的算法环境和相机的配置;
- 算法模型:
- a,手检测要求标注的bbox要十分的准确;
- b,关键点的估计对摄像头的敏感度较低,需要标注整个手的姿势
- 关键点的标签:
- 基于深度的手动跟踪系统,生成ground truth关键点标签,将结果关键点投影到几个校准过的单色图像;
- 1个单色深度相机,捕捉和标记手部运动,生成的关键点被重投影和插值到6个单色鱼眼相机的单色视图中;
- 通过握住用户的手来限制遮挡,手掌总是指向深度相机,手指保持在视野中;
- 每个序列的第一帧手动标注手部包围框,在以后的帧跟踪手部;
- 使用适合于高质量手部扫描的校准用户特定手部模版模型进行跟踪
- 手的姿态估计结合了关键点估计和基于模型的跟踪
- 半自动bbox的标注:
- 用户手动标注初始帧的bbox,使用训练好的KeyNet(关键点的回归网络)和跟踪手的姿态传播pipeline,得到剩余帧的结果框。
单色相机的手势跟踪
a,算法的思路流程
- 通过4个单色VGA鱼眼相机(640*480),检测每幅图像的左右手,生成bounding box,即完成手的定位;
- 通过定位出来的手从原始图像中crop出bounding box里含有手的区域,送给手部关键点回归(21 landmark)算法网络;
- 通过获取到的21 landmark完成3D姿势的适应;
-
b,硬件配置
4个单色VGA鱼眼全局曝光相机,采集VGA格式的图像
每个相机覆盖150(宽度),120(高度)和175(对角线)FOV
c,DetNet(手检测)
使用半自动标注方法收集数据
- 提出基于SSD的DetNet用于手的检测和定位
使用跟踪检测的方法,能够更好的处理手部在多个摄像机之间的移动
d,KeyNet(关键点的回归)
算法训练:通过深度相机采集图像,完成KeyNet模型的训练
- VR眼镜中:使用已经训练好的模型+普通摄像头来近似深度摄像头的作用,获取3D坐标,在进行手部建模
- 理论方法:
- 根据bounding box预测出手的区域图像中回归出手部的21个关键点;
- keynet的输入:DetNet的输出的bounding box;21个3D post手部关键点;
- 预测手部关键点的2.5D坐标(注意:什么是2.5D坐标);
- 之所以可以生成2.5D的坐标,是因为普通的鱼眼相机只能生成2D的坐标;
- 使用深度学习进行训练的时候,对每一张图片中像素都增加了深度信息(即增加了一维热力图)这样可以达到手部模型的最终生成;
- 事实上并没得到真实的3D坐标,而是这种2D坐标+相对深度坐标的方法叫做2.5D的方法;
- 关键技术:
- 90%的关键点预测是由上一步输入的3D生成,其余的10%的关键点预测是由20帧前的手部姿势生成;
研究内容
算法实现:
1)DetNet训练(手检测模型,如图所示):
- DataSet:VGA格式的图片,260w张图片
- Training Param:学习率(0.001),epoch(75),动量为0.9的SGD的随机梯度下降优化器
- 数据增强:随机缩放,模拟环境和光照变化
- 对比实验:
- 定量评估
- 不同摄像头拍摄手部图像可能有很大的不同:
- 底部的摄像头倾向于不住用户的身体和周围环境
- 顶部的摄像头倾向于捕捉天花板
- 不同摄像头拍摄手部图像可能有很大的不同:
- 定性评估
- 通过跟踪检测的方法对手出现在图像中的位置不敏感,在不同视图之间性能差异变小
- 定量评估
2)KeyNet训练(关键点回归模型,如图所示):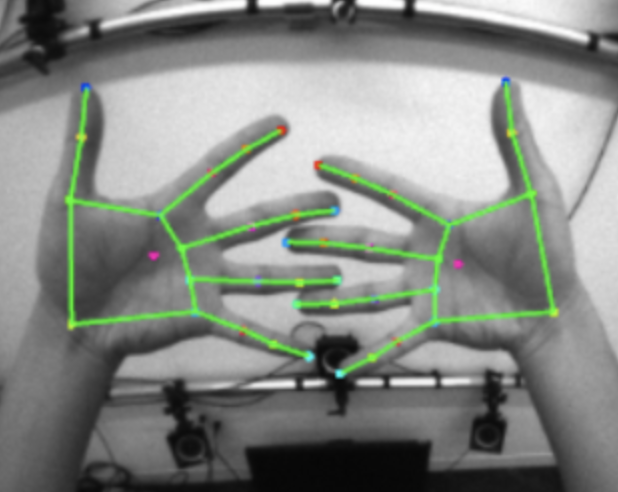
- DataSet:200w张,由深度相机自采集的图片
- Training Param:学习率(0.025),epoch(75),动量为0.9的SGD的随机梯度下降优化器
- input data:
- 96*96 单色图像,63维(外部关键点);
- 单色图像 hand crop image 来自于 DetNet的检测结果,将得到的bbox扩充20%,使得box里包含全部手的信息,即分辨率96*96
- addon向量,有上一帧推断处理的附加信息,即为63维的向量,跟之前detection-by-tracking类似根据预测的poset 可以得到该相机下的2D pose(42维)以及 1D relative distance(21维)
- 这里是经过DetNet处理后的图像,而且有21个用于参考的3D手势点,即63维);
- 21个关键点来源于 Hand Kinematic Model,使用上次生成的手部模型来辅助下一轮的输入;
- 96*96 单色图像,63维(外部关键点);
- output data:
- 21个手部预测的2.5D手部关键点坐标
- 211818(2D joint headmap) 二维热力图和21*18(relative distance)一维热力图
- 策略:
- 加入高斯噪声来增强关键点特征;
- 90%为训练数据,根据外部姿势计算关键点
- 10%的训练数据,根据前20帧的手部姿势计算关键点
- 数据增强:
- 设置像素值为0随机抹去图像边界的巨行区域
- 随机几何平移,旋转和缩放
- 模拟关照和视点的变化
- 相关的研究:
- 对比实验:
- KeyNet-S只接受单个图像作为输入,没有关键点特征
- KeyNet-N使用与KeyNet相同的结构,在训练过程中添加高斯噪声
- KeyNet-F类似与KeyNet的快速模型,在Hexagon V62 DSP中实现实时的运算和交互
- 精度的运算:
- 使用均值-关键点位置-误差(MKPE)计算所有帧中估计关键点和地面关键点之间的欧式距离
- 通过关键点加速度的估计来度量估计的时间平滑性
- 跟踪性能:
- 立体跟踪
- 单目跟踪
- 对比实验:
- KeyNet的亮点:
- 63维外部关键点的输入,即21个3D点,最大的效果就是在于稳定模型的预测,主要解决以下的扰动:
- 当手在重叠的相机视图之间移动时,预测的质量会降低
- 手指交叉咬合时
- 在手部或者VR眼镜出现强烈抖动时
- 上一轮生成的关键点用来辅助下一轮关键点的预测,由于有了上一轮的关键点做为参考,那么就可以重点观察新的关键点的特点和分布了。
- 对于KeyNet来说,他最终输出的21个点,其中90%其实还是来自于上一步输入的3D点,只有剩下10%的关键点的预测才是有KeyNet新生成的,系通过此方法来优化计算的速度,不至于每帧都产生大量的计算。
- 63维外部关键点的输入,即21个3D点,最大的效果就是在于稳定模型的预测,主要解决以下的扰动:
3)Hand Kinematic Model(手部运动模型,如图所示):
- input data:
- 使用前两帧KeyNet输出的21个2.5D的手部关键点,来生成本帧的手部3D模型
- 对于输入的两帧数据,将计算两帧之间的残差,来优化第三帧的生成
- 具体优化的残差项:
- 将前两帧的21个3D点的前2D数据投影回相机空间,与这一帧KeyNet预测的2D位置坐标越接近越好
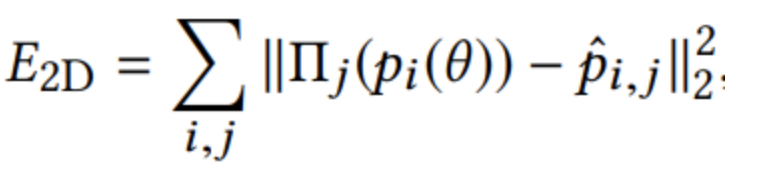
- 计算前两帧21个3D点的相对深度,与这一帧KeyNet预测的depth distance越接近越好;
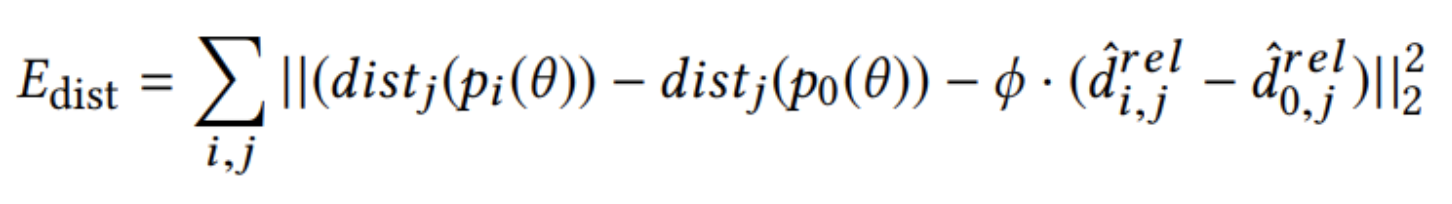
- 预测这一帧与上一帧的点越接近越好,即smooth term;(注意,这里不是这一帧与前两帧做对比,而是只和上一帧做对比)
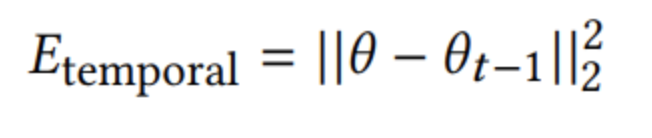
- output data:
- 最终生成由26个自由度组成的3D的手部模型(这一层最终成像);
- 并且保存这个手模的scale,以及保存使用者的信息;
4)不同手部动作的评估:
- 手指运动序列:测试系统如何在立体声捕捉微妙的手指运动
- 手-手序列:测试系统如何处理轻微的立体手部运动
- 慢速和快速运动序列:测试系统如何捕捉大体积的手部运动
5)公共数据集的实验评估:
- 统一需要把RGB图像转换成GRAY图像
- STB【Zhang et al. 2016】
- Dexter+Object【Mueller et al. 2017】
- EgoDexter【Sridhar et al. 2016】
6) 算法综述:
- 优点:
- 双手与手持物体的联合推理是实现更好的手的跟踪
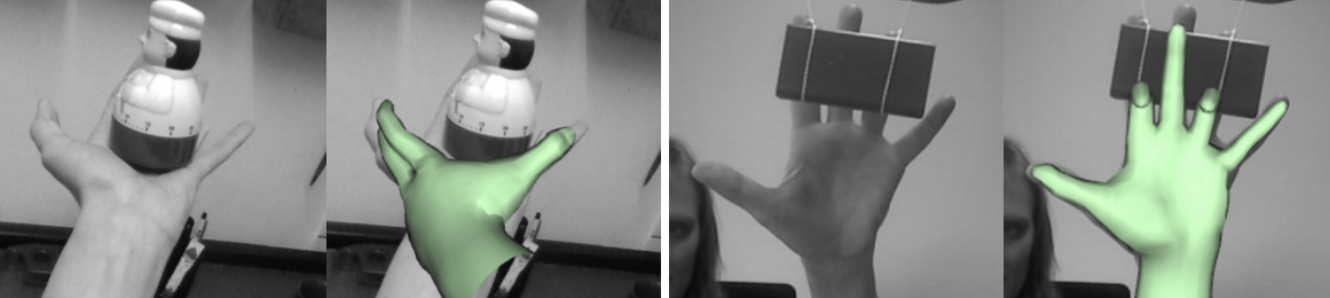
- 缺点(如图所示,详细说明情况):
- 双手有复杂交叉的时候,识别会失效

- 当手的方向不是以自我的方向为中心,识别失败

- 手和现实物体交互时,识别失败
- 此外,每当一个新的使用者使用该设备,整个系统会先进入kinematic model scale 模块,在预存的手模库里查看是否是该设备的老用户,并进行手部姿态的矫正。
总结
- 实时手势跟踪系统,用于VR/VR的交互;
- 使用4个自我为中心的鱼眼摄像机,部分重叠FOV,实现大的跟踪量;
- 手部检测网络DetNet,结合跟踪检测策略,处理手部多个摄像机之间的移动;
- 提出了关键点估计网络KeyNet,利用跟踪信息实现空间和时间上的一致性的关键点预测,生成精确的,低抖动的手部运动;
- 使用传统的线性混合皮肤平台,基于模型的姿态估计和手比例尺校准;
- 手标度校准限于改变手的单个参数(刻度),准确性不够;
附录
2.5D
在摄像头输入图像中,在大部分情况下将手腕处或是手掌中心会被设为相对深度的基准点,也就是这个位置的深度视为0。这种相对深度的方法被统称为2.5D表示法
2.5D与3D的映射
各个点在图像上的2D位置
- 各个关键点的相对深度
- 假设手骨长度,将2D预测与相对深度以几何投影方式投到3D空间,并放置在手骨长度恰好等于假设值的3D位置上,这样就完成了3D手姿态的近似
- 映射的过程,如图所示:
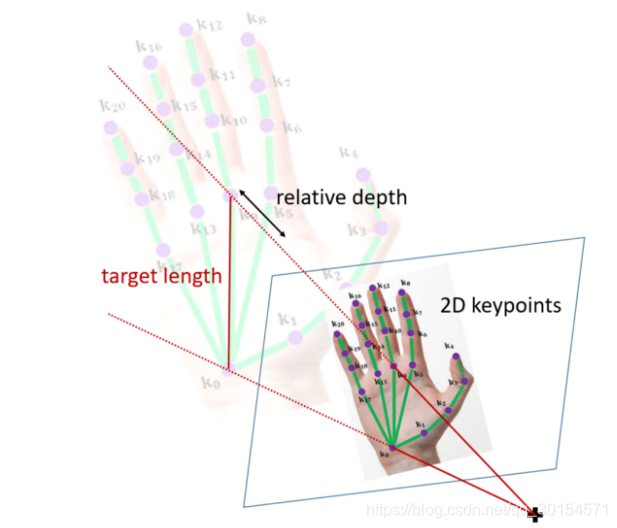
图示:2.5D -> 3D
26自由度DOF
- 手腕6个自由度
-
21关键点
每根手指4个关键点,共20个关键点
-
3D手势估计
数据驱动
- 预先对手势图像进行标注
- 利用标注好的数据训练一个分类器或者回归模型
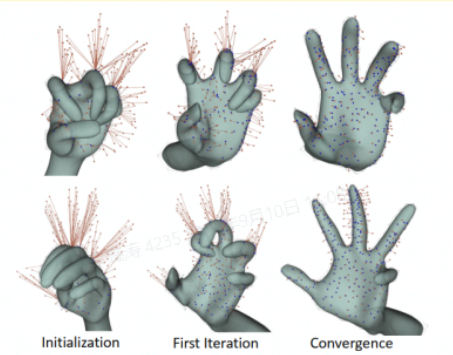
- 模型驱动
- 原理:
- 构造一个模型,比较生成的手势图像与实际图像的差异
- 采用优化问题的思路,最小化差异
- example:基于Gauss-Newton优化方法进行手势追踪和识别的效果示意图
- 原理:
Question:
1)为什么使用鱼眼相机?而且是4个鱼眼相机
- 首先,鱼眼摄像头的视野足够大,如果不用鱼眼相机很容易超出视野范围
- 其次,能够更好的解决“遮盖问题”(手被自己或者物品遮盖,遮盖是一个比较难的问题对于视觉算法,为了解决这样的问题只能通过多相机的输入来避免这样的尴尬)
- 然后,大多情况会使用多个相机来抓取手的位置,只有非常少的情况使用单一相机的算法(比如,手的位置远离身体,这样仅有一个摄像机可以捕捉到手的姿势。。。)
2)为什么不使用VR眼镜的四个摄像头生成3D坐标?
文中并没有直接说明,很大可能直接生成的3D坐标效果不好,因此使用2.5D的坐标实现3D坐标的映射
3)完整实现手势跟踪的三大步骤(如图所示):
- DetNet 完成手部检测
- KeyNet 完成手的关键点的回归
- Hand Kinematic Model(手势的估计)建立手部运动模型

4)完整的运行流程:
- 1,首先,在4个不同鱼眼相机上跑DetNet,直到找到使用者的手。
- 2,将camera的影像通过KeyNet和Hand Kinematic Model得到第一个3D姿态的手部模型。
- 3,随后,利用这个3D姿态投影到其他camera中找到别的camera中的手。这个方法减少了多次跑DetNet所需的运算资源(相当于告诉DetNet一个手的大致位置,从而不需要让DetNet进行全图搜索)。
- 4,接下来进入手部追踪模式,每次进行KeyNet预测的时候,插入上一帧的Hand kinematic model,以推测下一帧中手可能会出现的位置,更进一步的减少运行DetNet的运算需求。
- 5,运行100帧之后,这个手的scale会被储存下来,直到VR眼镜被放下才会清除。
- 6,大多数的情况下,三大层中只有KeyNet会持续地运行,DetNet只有在丢失手部追踪(比如手突然抽走,再突然出现在另一个位置)的情况下才会被重新启动
- 7,另外,为了压低运算量,即使同一支手存在于超过两个camera的视角内,MegaTrack还是只会跑其中两只camera。

若有收获,就点个赞吧
0 人点赞
