1)如何修改resnet适应不同大小的输入:
resnet由于最后的全连接层参数固定,为了适应不同大小的输入。要么对输入图像进行crop或者padding,要么修改网络。以下是LearnOpenCV提供的一种修改网络的方式。
a)将最后的池化层由AdaptiveAvgPool2d 改为 AvgPool2d
b) 将全连接层替换为卷积层。
如下详细的code:
class FullyConvolutionalResnet18(models.ResNet):
def init(self, numclasses=1000, pretrained=False, **kwargs):
# Start with standard resnet18 defined here #https://github.com/pytorch/vision/blob/b2e95657cd5f389e3973212ba7ddbdcc751a7878/torchvision/models/resnet.py
super()._init(
block=models.resnet.BasicBlock,
layers=[2, 2, 2, 2],
num_classes=num_classes,
**kwargs,
)
if pretrained:
state_dict = load_state_dict_from_url(
models.resnet.model_urls[“resnet18”], progress=True,
)
self.load_state_dict(state_dict)
# Replace AdaptiveAvgPool2d with standard AvgPool2d<br /> # [https://github.com/pytorch/vision/blob/b2e95657cd5f389e3973212ba7ddbdcc751a7878/torchvision/models/resnet.py#L153-L154](https://github.com/pytorch/vision/blob/b2e95657cd5f389e3973212ba7ddbdcc751a7878/torchvision/models/resnet.py#L153-L154)<br /> self.avgpool = nn.AvgPool2d((7, 7))# Add final Convolution Layer.<br /> self.last_conv = torch.nn.Conv2d(<br /> in_channels=self.fc.in_features, out_channels=num_classes, kernel_size=1,<br /> )<br /> self.last_conv.weight.data.copy_(<br /> self.fc.weight.data.view(*self.fc.weight.data.shape, 1, 1),<br /> )<br /> self.last_conv.bias.data.copy_(self.fc.bias.data)# Reimplementing forward pass.<br /> # Replacing the following code<br /> # [https://github.com/pytorch/vision/blob/b2e95657cd5f389e3973212ba7ddbdcc751a7878/torchvision/models/resnet.py#L197-L213](https://github.com/pytorch/vision/blob/b2e95657cd5f389e3973212ba7ddbdcc751a7878/torchvision/models/resnet.py#L197-L213)<br /> def _forward_impl(self, x):<br /> # Standard forward for resnet18<br /> x = self.conv1(x)<br /> x = self.bn1(x)<br /> x = self.relu(x)<br /> x = self.maxpool(x)x = self.layer1(x)<br /> x = self.layer2(x)<br /> x = self.layer3(x)<br /> x = self.layer4(x)<br /> x = self.avgpool(x)# Notice, there is no forward pass<br /> # through the original fully connected layer.<br /> # Instead, we forward pass through the last conv layer<br /> x = self.last_conv(x)<br /> return x<br />
2)
为什么resnet的输入是一定的?
因为resnet最后有一个全连接层。正是因为这个全连接层导致了输入的图像的大小必须是固定的。
输入为固定的大小有什么局限性?
原始的resnet在imagenet数据集上都会将图像缩放成224×224的大小,但这么做会有一些局限性:
a,当目标对象占据图像中的位置很小时,对图像进行缩放将导致图像中的对象进一步缩小,图像可能不会正确被分类
b,当图像不是正方形或对象不位于图像的中心处,缩放将导致图像变形
c,如果使用滑动窗口法去寻找目标对象,这种操作是昂贵的
如何修改resnet使其适应不同大小的输入?
1, 自定义一个自己网络类,但是需要继承models.ResNet
2, 将自适应平均池化替换成普通的平均池化
3, 将全连接层替换成卷积层
3)
如果在training的时候加载预训练模型出现如下的错误,如何解决这样的问题呢?
错误如下:
RuntimeError: Error(s) in loading state_dict for ResNet:
size mismatch for fc.weight: copying a param with shape torch.Size([1000, 512]) from checkpoint, the shape in current model is torch.Size([3, 512]).
size mismatch for fc.bias: copying a param with shape torch.Size([1000]) from checkpoint, the shape in current model is torch.Size([3]).
原始的工程code如下:
修改后的工程code如下:
net =resnet34(num_classes=2)
pretrained_dict =torch.load(“./resnet34-pre.pth”)
model_dict =net.state_dict()
# 重新制作预训练的权重,主要是减去参数不匹配的层,楼主这边层名为“fc”,原始代码中报错部分出现 mismatch for fc.bias, 因此需要把此层移除
pretrained_dict ={k: v fork, v inpretrained_dict.items() if(k inmodel_dict and’fc’notink)}
# 更新权重
model_dict.update(pretrained_dict)
net.load_state_dict(model_dict)
4)
TensorFlow中loss与val_loss、accuracy和val_accuracy分别是什么含义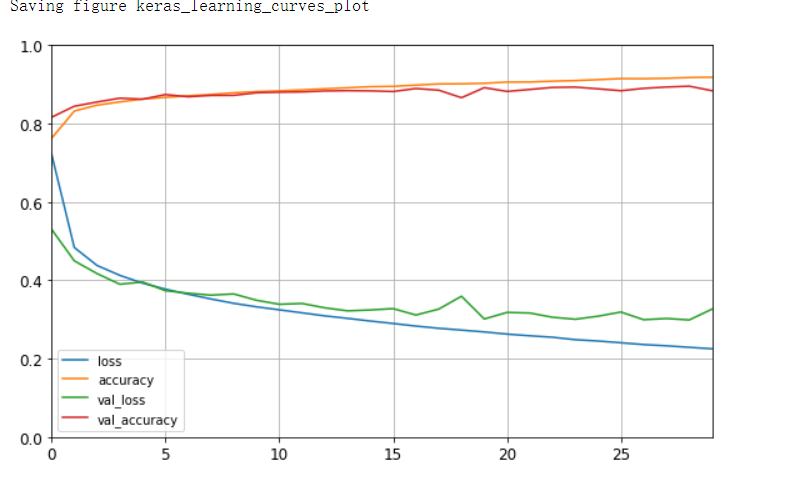
各个Loss的说明:
loss:训练集损失值
accuracy:训练集准确率
val_loss:测试集损失值
val_accruacy:测试集准确率
loss的5种情况的可供参考项:
train loss 不断下降,test loss不断下降,说明网络仍在学习;(最好的)
train loss 不断下降,test loss趋于不变,说明网络过拟合;(max pool或者正则化)
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;(检查dataset)
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;(减少学习率)
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。(最不好的情况)
5)
PyTorch 如何使用多GPU进行训练呢?
device =torch.device(“cuda:0” if torch.cuda.is_available() else “cpu” )
model.to(device)
mytensor =my_tensor.to(device)
使用多GPU的方法如下:
device =torch.device(“cuda:0” if torch.cuda.is_available() else “cpu” )
if torch.cuda.device_count() > 1:
model =nn.DataParallel(model)
model.to(device)
mytensor =my_tensor.to(device)
单机多卡的GPU训练方法:
使用多GPU的时候, 通常可以使用os.environ[‘CUDA_VISIBLE_DEVICES’]来限制使用的GPU个数, 比如需要使用第0和第3编号的GPU, 那么仅仅需要在程序中设置:
os.environ[‘CUDA_VISIBLE_DEVICES’] = ‘0,3’
注意: 此参数的设定要保证在模型加载到gpu上之前, 那么需要在程序开始的时候就设定好此参数, 之后如何将模型加载到多GPU上面呢?
如果是模型, 执行下面的这几句代码:
model = nn.DataParallel(model)
model = model.cuda()
如果是数据, 执行下面这几句代码就可以了:
inputs = inputs.cuda()
labels = labels.cuda()
6)
常用参数的说明:
(1)学习率
学习率(learning rate或作lr)是指在优化算法中更新网络权重的幅度大小。学习率可以是恒定的、逐渐降低的,基于动量的或者是自适应的。不同的优化算法决定不同的学习率。当学习率过大则可能导致模型不收敛,损失loss不断上下震荡;学习率过小则导致模型收敛速度偏慢,需要更长的时间训练。通常lr取值为[0.01,0.001,0.0001]
(2)批次大小batch_size
批次大小是每一次训练神经网络送入模型的样本数,在卷积神经网络中,大批次通常可使网络更快收敛,但由于内存资源的限制,批次过大可能会导致内存不够用或程序内核崩溃。bath_size通常取值为[16,32,64,128]
(3)优化器optimizer
目前Adam是快速收敛且常被使用的优化器。随机梯度下降(SGD)虽然收敛偏慢,但是加入动量Momentum可加快收敛,同时带动量的随机梯度下降算法有更好的最优解,即模型收敛后会有更高的准确性。通常若追求速度则用Adam更多。
(4)迭代次数
迭代次数是指整个训练集输入到神经网络进行训练的次数,当测试错误率和训练错误率相差较小时,可认为当前迭代次数合适;当测试错误率先变小后变大时则说明迭代次数过大了,需要减小迭代次数,否则容易出现过拟合。
(5)激活函数
在神经网络中,激活函数不是真的去激活什么,而是用激活函数给神经网络加入一些非线性因素,使得网络可以更好地解决较为复杂的问题。比如有些问题是线性可分的,而现实场景中更多问题不是线性可分的,若不使用激活函数则难以拟合非线性问题,测试时会有低准确率。所以激活函数主要是非线性的,如sigmoid、tanh、relu。sigmoid函数通常用于二分类,但要防止梯度消失,故适合浅层神经网络且需要配备较小的初始化权重,tanh函数具有中心对称性,适合于有对称性的二分类。在深度学习中,relu是使用最多的激活函数,简单又避免了梯度消失。
Pytorch多卡训练
前一篇博客利用Pytorch手动实现了LeNet-5,因为在训练的时候,机器上的两张卡只用到了一张,所以就想怎么同时利用起两张显卡来训练我们的网络,当然LeNet这种层数比较低而且用到的数据集比较少的神经网络是没有必要两张卡来训练的,这里只是研究怎么调用两张卡。
现有方法
在网络上查找了多卡训练的方法,总结起来就是三种:
- nn.DataParallel
- pytorch-encoding
- distributedDataparallel
第一种方法是pytorch自带的多卡训练的方法,但是从方法的名字也可以看出,它并不是完全的并行计算,只是数据在两张卡上并行计算,模型的保存和Loss的计算都是集中在几张卡中的一张上面,这也导致了用这种方法两张卡的显存占用会不一致。
第二种方法是别人开发的第三方包,它解决了Loss的计算不并行的问题,除此之外还包含了很多其他好用的方法,这里放出它的GitHub链接有兴趣的同学可以去看看。
第三种方法是这几种方法最复杂的一种,对于该方法来说,每个GPU都会对自己分配到的数据进行求导计算,然后将结果传递给下一个GPU,这与DataParallel将所有数据汇聚到一个GPU求导,计算Loss和更新参数不同。
这里我先选择了第一个方法进行并行的计算
并行计算相关代码
首先需要检测机器上是否有多张显卡
USE_MULTI_GPU = True # 检测机器是否有多张显卡 if USE_MULTI_GPU and torch.cuda.device_count() > 1: MULTI_GPU = True os.environ[“CUDA_DEVICE_ORDER”] = “PCI_BUS_ID” os.environ[“CUDA_VISIBLE_DEVICES”] = “0, 1” device_ids = [0, 1] else: MULTI_GPU = False device = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
其中os.environ[“CUDA_VISIBLE_DEVICES”] = “0, 1”是将机器中的GPU进行编号
接下来就是读取模型了
net = LeNet() if MULTI_GPU: net = nn.DataParallel(net,device_ids=device_ids) net.to(device)
这里与单卡的区别就是多了nn.DataParallel这一步操作
接下来是optimizer和scheduler的定义
optimizer=optim.Adam(net.parameters(), lr=1e-3) scheduler = StepLR(optimizer, step_size=100, gamma=0.1) if MULTI_GPU: optimizer = nn.DataParallel(optimizer, device_ids=device_ids) scheduler = nn.DataParallel(scheduler, device_ids=device_ids)
因为optimizer和scheduler的定义发送了变化,所以在后期调用的时候也有所不同
比如读取learning rate的一段代码:
optimizer.state_dict()[‘param_groups’][0][‘lr’]
现在就变成了
optimizer.module.state_dict()[‘param_groups’][0][‘lr’]
详细的代码可以在我的GitHub仓库看到
开始训练
训练过程与单卡一样,这里就展示两张卡的占用情况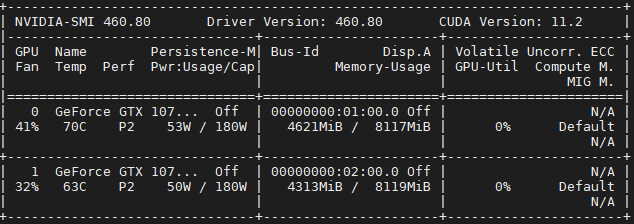
可以看到两张卡都有占用,这说明我们的代码起了作用,但是也可以看到,两张卡的占用有明显的区别,这就是前面说到的DataParallel只是在数据上并行了,在loss计算等操作上并没有并行

若有收获,就点个赞吧
0 人点赞
