二叉堆
二叉堆是一个完全二叉树,当树中任意一个节点的权值都大于等于它儿子的权值,那么它是一个大根堆,当树中任意一个节点的权值都小于等于它儿子的权值,那么它是一个小根堆。他需要支持插入一个新数据、删除一个数据、以及查询最值等操作。
heap:[25,14,19,5,12,17,8,1,3,10,6,2]
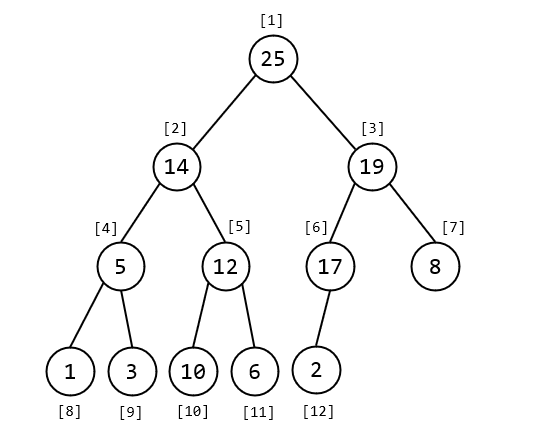
Insert
插入操作向二叉树中插入一个带有权值的新节点。我们并不知道它最合适的位置在哪,即便知道也还需要对其他节点进行调整。所以先把他放在存储二叉堆的数组末尾,然后通过交换的方式进行调整,直到它满足堆性质。
int heap[N], tot; // 使用 tot 来表示当前堆中的元素个数void up(int p) {while(p > 1) {if(heap[p] > heap[p/2]) { // 子节点大于父节点,不满足大根堆性质swap(heap[p], heap[p/2]);p /= 2;} else break;}}void insert(int val) {heap[++tot] = val;up(tot);}
GetTop
取堆顶,这可能是简单的操作,直接返回堆顶即可。
int GetTop(){return heap[1];}
Extract
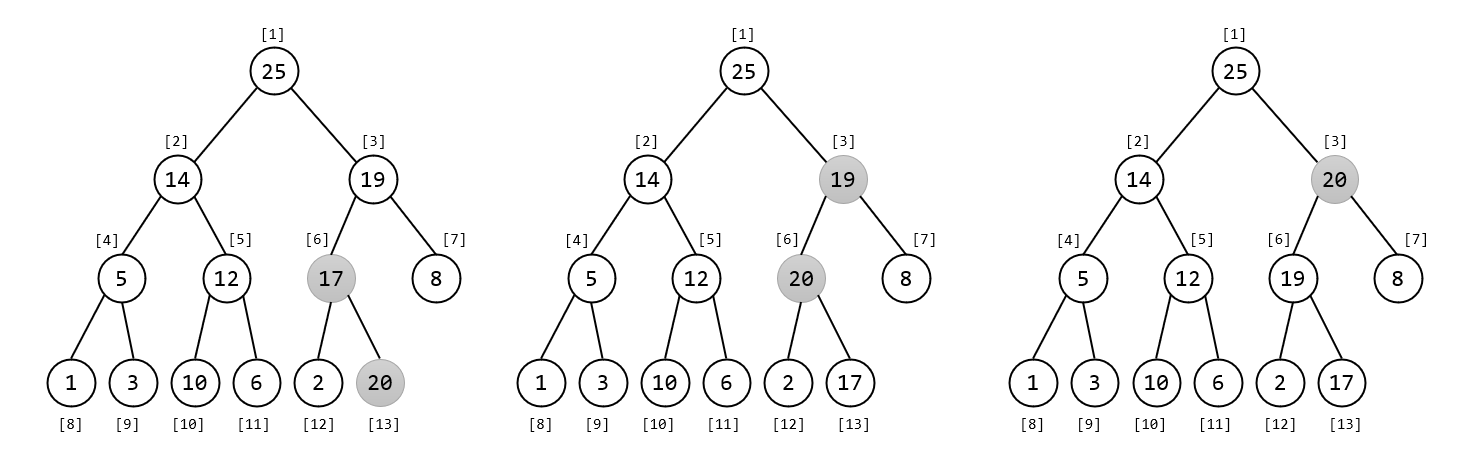
删除堆顶操作。如果直接删除,我们并不知道接下来的左右子树该如何处置。所以,我们先让它与数组末尾的元素交换,然后移除末尾节点(令 减 1),然后通过交换的方式,把堆顶向下调整,直到满足堆性质。
void down(int p){int s = p * 2;while(s <= tot) {if(s < tot && heap[s] < heap[s + 1]) s++; // 左右子节点取较大值。if(heap[s] > heap[p]) {swap(heap[s], heap[p]);p = s; s = p * 2;} else break;}}void extract(){heap[1] = heap[tot--];down(1);}
Remove
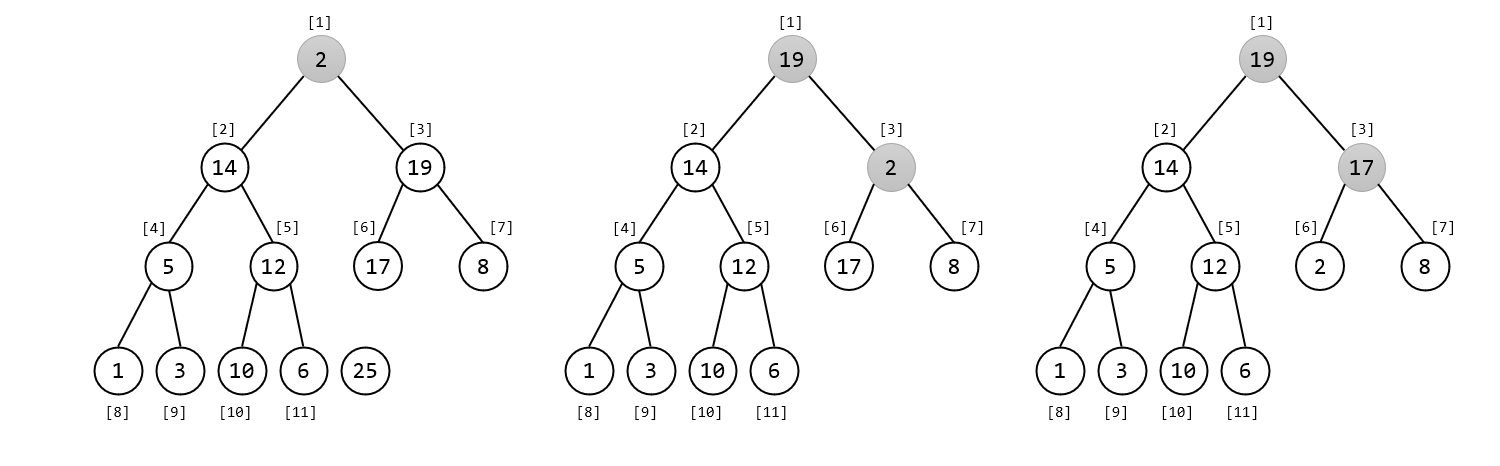
remove(p) 操作把存储在数组下标为 p 位置的节点从二叉树中删除。与 extract 相似,我们先把 heap[p] 与 heap[n] 交换,然后令 减去 1。注意,此时 heap[p] 既可能向上调整又可能向下调整。需要分别检查和处理,但对先后次序并没有特别的要求,因为除去
heap[p] ,其他都是有序的,我们相当于只是不确定它会往上移动还是往下移动,但最终只会选择一个移动。
void remove(int k) {heap[k] = heap[tot--];up(k), down(k);}
时间复杂度
涉及到修改堆结构的操作,复杂度都是 #card=math&code=O%28%5Clog%20n%29&id=xTHvw)。这是一个非常优秀的复杂度。它也将在我们之后的学习过程中,发挥至关重要的作用。
哈夫曼树
哈夫曼编码
什么是编码?比如我要写一篇文章,有 三种字符构成,尽管整篇文章是有这 3 种字符构成,但在计算机底层,他都是用二进制编码组成的。
假设在这片文章中, 有 45 个,
有 10 个,
有 3 个,那么如果将
进行等长编码,每个字符由一个两位二进制数字组成( n 个不同字符需要
位)。那么我们总共需要
*2%20%3D%20116#card=math&code=%2845%2B10%2B3%29%2A2%20%3D%20116&id=Gnzaj) 位长度来存储这篇文章。
但如果我们有选择的,让二进制数字 来编码
,然后
分别表示
,那么我们只需要
*2%3D71#card=math&code=45%2A1%20%2B%20%2810%2B3%29%2A2%3D71&id=d2Sws) 位长度即可存储这边文章。而现在正在使用的,就是不等长编码。
不等长编码 需要两个解决两个关键问题:
- 编码尽可能短,我们可以让使用频率高的字符编码较短,使用频率低的字符编码较长
- 不能有二义性。
对于二义性,举一个例子说明。
例如:ABCD 四个字符如果这样编码:
A:0 B:1 C:11 D:10那么现在有一列数字 0110,该如何翻译呢?是翻译成 ABBA、ABD、CBA还是CD?这种混乱编码的译码如果用在军事情报中后果将非常严重。
如何消除二义性?解决的办法是 任何一个字符的编码都不能是另一个字符编码的前缀,即前缀码特性
1952 年,数学家 D.A.Huffman 提出了一种最佳编码方式,被称为哈夫曼(Huffman)编码。这种编码方式被广泛的应用在数据压缩、尤其是远距离通信和大容量数据存储。常用的JPEG图片就是采用哈夫曼编码压缩的。
哈夫曼的基本思想就是以字符的使用频率作为权值构建一颗哈夫曼树,然后利用哈夫曼树对字符进行编码。
构建一颗哈夫曼树,是将所要编码的字符作为叶子结点,将该字符在文件中的使用频率作为叶子结点的权值,采用自底向上的方式,通过 次的”合并“运算后构造出的树。其核心思想是让权值更大的叶子离根最近。
哈夫曼树构建过程
- 初始化。构造
个结点,每个结点代表了要编码的
个字符。这些结点作为一个单结点树被放入集合
,每个结点都有一个权值,为该字符的使用频率。
- 如果在
中仅剩下一棵树,则算法结束,哈夫曼树构造成功,跳到第六步。否则,从集合
中取出没有双亲且权值最小的两棵树
和
,将他们合并成一颗新的树
,新树的左孩子为
,右孩子为
,
的权值为
的权值之和。
- 从集合中删除
,加入
。
- 重复 2~3 步。
- 约定构成的二叉树中,左分支上面的编码为 “0”,右分支上的编码为 “1”。从叶子结点到根结点逆向求出每个字符的哈夫曼编码。那么从根结点到叶子结点路径上的字符组成的字符串为该叶子结点的哈夫曼编码,算法结束。
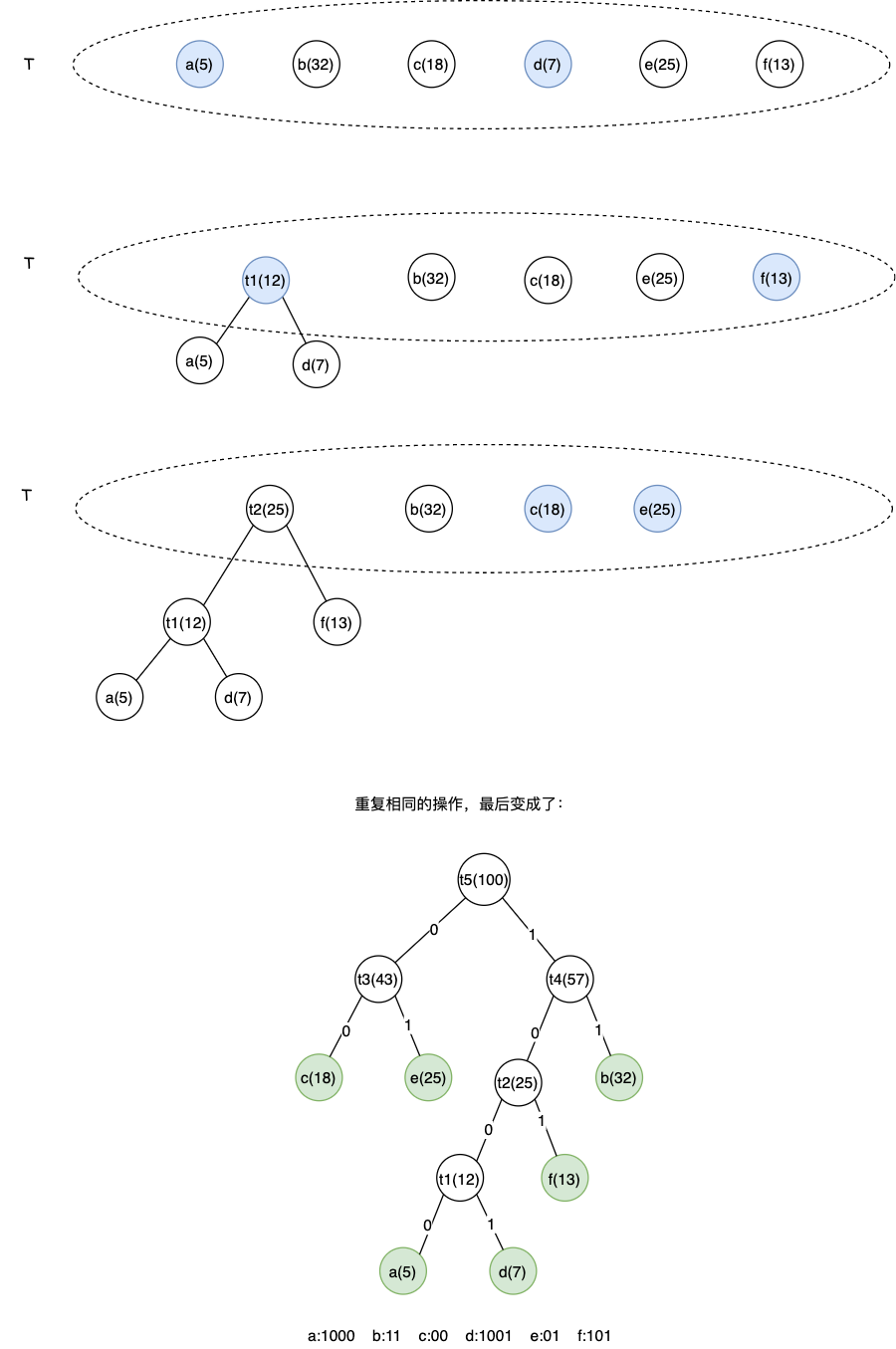
假设一些字符以及他们的使用率如下表所示:
| 字符 | a | b | c | d | e | f |
|---|---|---|---|---|---|---|
| 频率 | 0.05 | 0.32 | 0.18 | 0.07 | 0.25 | 0.13 |
把每个字符都作为叶子,将对应频率作为权值,因为只是比较大小,所以对其同时扩大 100 倍,得到:
| 字符 | a | b | c | d | e | f |
|---|---|---|---|---|---|---|
| 权值 | 5 | 32 | 18 | 7 | 25 | 13 |
构建过程如下图所示
算法实现
- 数据结构
struct Node {double weight; // 权值int p, l, r; // 分别表示父亲、左孩子、右孩子char ch; // 表示该结点表示的字符}
- 算法执行流程
- 初始化:在构造哈夫曼树的过程中,首先将每个节点的父亲、左右孩子都初始化为 -1。
- 每次找到双亲为 -1,且权值最小的两个点
,
- 将
合并为一颗,并建立一个新的结点,更新为
的父亲。规定其左孩子为权值最小的
,右孩子为权值次小的
。如果一样则随意。
char s[N];double rate[N];Node a[N*2]; // 结点数量要比字符数量多一倍int tot = n;// 以下内容在main函数中// 初始化for(int i=1; i<= n; i++){a[i].p = a[i].l = a[i].r = -1;a[i].ch = s[i];a[i].weight = rate[i];}// n 个结点,构建 n-1 次for(int i=1;i <= n-1;i++){// m1 为最小值,m2 为次小值double m1 = INF, m2 = INF;int t1 = -1, t2 = -1;// 找最小以及次小的方法for(int j=1;i<=tot;i++){if(a[j].p != -1) continue;if(a[j].weight < m1) {// 先更新次小的信息m2 = m1; t2 = t1;// 然后更新最小的信息m1 = a[j].weight; t1 = j;} else if(a[j].weight < m2) {m2 = a[j].weight; t2 = j;}}++tot;a[tot].weight = m1 + m2;a[tot].p = -1;a[tot].l = t1;a[tot].r = t2;a[t1].p = a[t2].p = tot;}
至此,哈夫曼树构建完成,根结点下标为tot
如果需要求解哈夫曼编码,则从根开始,向子节点遍历,直到遍历到叶子结点,路径上连接起来构成的二进制串就是其对应的编码。实现方式有很多种。
总结
哈夫曼树可以用来求哈夫曼编码,它基于贪心思想,每次合并总是先考虑权值最小的节点,这使得最后生成的树中,使用率偏低的结点深度总是偏高的(编码长度更长)。
由于本节在构建哈夫曼树中,采取了朴素的扫描算法来找最小值以及次小值,效率是比较低下的。如果与前面的「二叉树」结合起来,就可以使得这个过程变得更快。
例题
超市
题目描述
超市里有 件商品,每件商品都有利润
和过期时间
,每天只能卖一件商品,过期商品不能再卖。
求合理安排每天卖的商品的情况下,可以得到的最大收益是多少。
输入格式
输入包含多组测试用例。
每组测试用例,以输入整数 开始,接下来输入
对
和
,分别代表第
件商品的利润和过期时间。
在输入中,数据之间可以自由穿插任意个空格或空行,输入至文件结尾时终止输入,保证数据正确。
输出格式
对于每组产品,输出一个该组的最大收益值。
每个结果占一行。
数据范围,
最多有 组测试样例
输入样例
4 50 2 10 1 20 2 30 17 20 1 2 1 10 3 100 2 8 25 20 50 10
输出样例
80185
首先,我们肯定要对商品按照时间排个序。然后对于每个时间(天数)t,应该在保证不卖出过期商品的前提下,尽量卖出利润前 大的商品。因此,我们可以依次考虑每个商品,动态维护上述这个方案。
我们先建立一个空的二叉堆,然后按照过期时间递增的顺序遍历每个物品。二叉堆维护的数字为我们当前考虑卖出去的物品的价值。
- 若当前商品过期时间 t 等于当前堆中元素个数,说明现在 t 天已经安排了 t 个物品卖出。如果当前商品价值超过堆中最小值,那么说明卖出当前物品将会更优。这里我们可以想到,我们需要维护一个小根堆,堆顶存放最小值,方便用于比较。
- 若当前商品的过期天数 t 小于当前堆中元素的个数,直接把商品价值插入到堆中即可。
最终,堆里面的所有商品就是我们需要卖出的商品了,他们的利润之和就是答案。时间复杂度为 #card=math&code=O%28n%5Clog%20n%29&id=RHFZL)。
#include <bits/stdc++.h>using namespace std;const int N = 10010;int p[N],d[N],n,id[N];priority_queue<int, vector<int>, greater<int> > q;bool cmp(int a,int b){return d[a] < d[b];}int main(){while(~scanf("%d",&n)){for(int i=1;i<=n;i++){scanf("%d%d",&p[i],&d[i]);}for(int i=1;i<=n;i++)id[i] = i;sort(id+1,id+1+n,cmp);for(int i=1;i<=n;i++){int x = id[i];if(q.size() < d[x])q.push(p[x]);else{if(q.top() < p[x]){q.pop();q.push(p[x]);}}}int res = 0;while(q.size()){res += q.top();q.pop();}printf("%d\n",res);}return 0;}
序列
题目描述
给定 个序列,每个包含
个非负整数。
现在我们可以从每个序列中选择一个数字以形成具有 个整数的序列。
很明显,我们一共可以得到 个这种序列,然后我们可以计算每个序列中的数字之和,并得到
个值。
现在请你求出这些序列和之中最小的 个值。
输入格式
第一行输入一个整数 ,代表输入中包含测试用例的数量。
接下来输入 组测试用例。
对于每组测试用例,第一行输入两个整数 和
。
接下在 行输入
个整数序列,数列中的整数均不超过
。
输出格式
对于每组测试用例,均以递增顺序输出最小的 个序列和,数值之间用空格隔开。
每组输出占一行。
数据范围,
输入样例
12 31 2 32 2 3
输出样例
3 3 4
对于两个长度为 n 的序列,然后求出其所有和的前 n 小,然后这前 n 小,继续与第三个序列合并。
至于如何求,可以参考该题目:
#include <bits/stdc++.h>using namespace std;const int N = 2010;int m,n;int a[N],b[N],c[N];typedef pair<int,int> PII;void merge(){priority_queue<PII,vector<PII>,greater<PII> > heap;for(int i=0;i<n;i++)heap.push({a[0] + b[i], 0});for(int i=0;i<n;i++){auto t = heap.top();heap.pop();int s = t.first, p = t.second;c[i] = s;heap.push({s-a[p] + a[p+1] , p+1});}for(int i=0;i<n;i++)a[i] = c[i];}int main(){int T;scanf("%d",&T);while(T--){scanf("%d%d",&m,&n);for(int i=0;i<n;i++)scanf("%d",&a[i]);sort(a,a+n);for(int i=0;i<m-1;i++){for(int j=0;j<n;j++)scanf("%d",&b[j]);merge();}for(int i=0;i<n;i++)printf("%d ",a[i]);puts("");}return 0;}
数据备份
题目描述
你在一家 IT 公司为大型写字楼或办公楼的计算机数据做备份。然而数据备份的工作是枯燥乏味的,因此你想设计一个系统让不同的办公楼彼此之间互相备份,而你则坐在家中尽享计算机游戏的乐趣。
已知办公楼都位于同一条街上,你决定给这些办公楼配对(两个一组)。
每一对办公楼可以通过在这两个建筑物之间铺设网络电缆使得它们可以互相备份。
然而,网络电缆的费用很高。
当地电信公司仅能为你提供 条网络电缆,这意味着你仅能为
对办公楼(总计
个办公楼)安排备份。
任意一个办公楼都属于唯一的配对组(换句话说,这 个办公楼一定是相异的)。
此外,电信公司需按网络电缆的长度(公里数)收费。
因而,你需要选择这 对办公楼使得电缆的总长度尽可能短。
换句话说,你需要选择这 对办公楼,使得每一对办公楼之间的距离之和(总距离)尽可能小。
下面给出一个示例,假定你有 个客户,其办公楼都在一条街上,如下图所示。
这 个办公楼分别位于距离大街起点
和
处。
电信公司仅为你提供 条电缆。
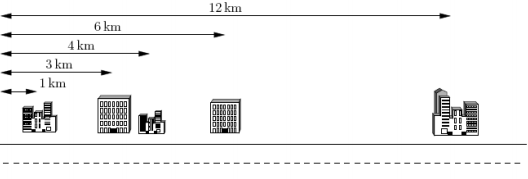
上例中最好的配对方案是将第 个和第
个办公楼相连,第
个和第
个办公楼相连。
这样可按要求使用 条电缆。
第 条电缆的长度是
,第
条电缆的长度是
。
这种配对方案需要总长 的网络电缆,满足距离之和最小的要求。
输入格式
第一行输入整数 和
,其中
表示办公楼的数目,
表示可利用的网络电缆的数目。
接下来的 行每行仅包含一个整数
,表示每个办公楼到大街起点处的距离。
这些整数将按照从小到大的顺序依次出现。
输出格式
输出应由一个正整数组成,给出将 个相异的办公楼连成
对所需的网络电缆的最小总长度。
数据范围,
,
输入样例
5 2134612
输出样例
4
很容易发现,最优解中每两个配对的办公楼一定是相邻的。
求出每两个相邻的办公楼之间的距离,记为  。
。
于是问题简化为:从数列 D 中选择不超过 K 个数,使它们的和最小,并且相邻两个数不能同时被选。
从最基本的情况开始考虑:
- K = 1,直接选最小的。
- K = 2,答案一定是以下两种情况之一:
- 选择最小值
 ,以及除去
,以及除去  之外的最小值。
之外的最小值。 - 选择最小值
 左右两侧的两个数,即
左右两侧的两个数,即  和
和 
- 选择最小值
证明很简单,如果 和
和  都没选,那么不选择
都没选,那么不选择 一定不是最优的。如果
一定不是最优的。如果 和
和  中的一个,那么还不如将它换成
中的一个,那么还不如将它换成  。
。
所以就有结论:「在最优解中,最小值左右两侧的数要么同时选,要么都不选」
策略:
先选当前数组中的最小值  ,然后将
,然后将  删除,再把
删除,再把  添加到 D 数列中刚才删除的位置。
添加到 D 数列中刚才删除的位置。
然后在求解从新的 D 序列中选择不超过 K - 1 个数,使它们的和最小,并且相邻两个数不能同时被选的子问题。
算法:
建立一个链表,维护 D 序列,然后再建立一个小根堆,与链表构成映射关系(堆中以 D 值优先排序,并保存它们在链表中的节点指针)。
取出堆顶,累加答案,然后更新链表即可。
#include <bits/stdc++.h>using namespace std;const int N = 100010;#define inf 0x3f3f3f3ftypedef long long ll;int l[N],r[N];int del[N];int n,k;long long d[N];priority_queue<pair<ll,int>> q;int main(){scanf("%d%d",&n,&k);for(int i=0;i<n;i++){scanf("%lld",&d[i]);}for(int i=n-1;i>=1;i--){d[i] = d[i] - d[i-1];l[i] = i-1; r[i] = i+1;q.push({-d[i],i});}d[0] = d[n] = inf;long long res = 0;while(k--){int t = q.top().second;if(del[t]){k++;q.pop();continue;}res -= q.top().first;q.pop();long long nval = d[l[t]] + d[r[t]] - d[t];d[t] = nval;del[l[t]] = del[r[t]] = 1;l[t] = l[l[t]];r[t] = r[r[t]];r[l[t]] = t;l[r[t]] = t;q.push({-nval,t});}printf("%lld\n",res);return 0;}
合并果子
题目描述
在一个果园里,达达已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。
达达决定把所有的果子合成一堆。
每一次合并,达达可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。
可以看出,所有的果子经过 次合并之后,就只剩下一堆了。
达达在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以达达在合并果子时要尽可能地节省体力。
假定每个果子重量都为 ,并且已知果子的种类数和每种果子的数目,你的任务是设计出合并的次序方案,使达达耗费的体力最少,并输出这个最小的体力耗费值。
例如有 种果子,数目依次为
。
可以先将 堆合并,新堆数目为
,耗费体力为
。
接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 ,耗费体力为
。
所以达达总共耗费体力。
可以证明 为最小的体力耗费值。
输入格式
输入包括两行,第一行是一个整数 ,表示果子的种类数。
第二行包含 个整数,用空格分隔,第
个整数
是第
种果子的数目。
输出格式
输出包括一行,这一行只包含一个整数,也就是最小的体力耗费值。
输入数据保证这个值小于 。
数据范围,
输入样例
31 2 9
输出样例
15
哈夫曼树裸题
#include <bits/stdc++.h>using namespace std;priority_queue<int,vector<int>, greater<int> > q;int x,n;int main(){scanf("%d",&n);for(int i=1;i<=n;i++){scanf("%d",&x);q.push(x);}int res = 0;while(q.size() > 1){int x = q.top();q.pop();int y = q.top();q.pop();res += x + y;q.push(x+y);}cout<<res<<endl;return 0;}
荷马史诗
题目描述
追逐影子的人,自己就是影子。 ——荷马
达达最近迷上了文学。
她喜欢在一个慵懒的午后,细细地品上一杯卡布奇诺,静静地阅读她爱不释手的《荷马史诗》。
但是由《奥德赛》和《伊利亚特》组成的鸿篇巨制《荷马史诗》实在是太长了,达达想通过一种编码方式使得它变得短一些。
一部《荷马史诗》中有 种不同的单词,从
到
进行编号。其中第
种单词出现的总次数为
。
达达想要用 进制串
来替换第
种单词,使得其满足如下要求:
对于任意的 ,都有:
不是
的前缀。
现在达达想要知道,如何选择 ,才能使替换以后得到的新的《荷马史诗》长度最小。
在确保总长度最小的情况下,达达还想知道最长的 的最短长度是多少?
一个字符串被称为 进制字符串,当且仅当它的每个字符是
到
之间(包括
和
)的整数。
字符串 被称为字符串
的前缀,当且仅当:存在
,使得
。
其中, 是字符串
的长度,
表示
的前
个字符组成的字符串。
注意:请使用 位整数进行输入输出、储存和计算。
输入格式
输入文件的第 行包含
个正整数
,中间用单个空格隔开,表示共有
种单词,需要使用
进制字符串进行替换。
第 行:第
行包含
个非负整数
,表示第
种单词的出现次数。
输出格式
输出文件包括 行。
第 行输出
个整数,为《荷马史诗》经过重新编码以后的最短长度。
第 行输出
个整数,为保证最短总长度的情况下,最长字符串
的最短长度。
数据范围,
输入样例
4 21122
输出样例
122
本题所构造的编码方式其实就是 Huffman 编码。我们把单词的出现次数  作为 Huffman 树的叶子节点的权值,然后求出 k 叉树。对于 Huffman 树的每个分支,分别在边上标记字符
作为 Huffman 树的叶子节点的权值,然后求出 k 叉树。对于 Huffman 树的每个分支,分别在边上标记字符  。
。
将这个树看做一个 Trie 树,就得到了使总长度最小的编码方法——单词 i 的编码就是从根节点到叶子节点 i 的路径上各边的字符相连。
一个单词不是另一个的前缀,其实就对应着:在 Trie 树中,所有单词编码的末尾都在叶子节点上,而不是在 Trie 树的一个内部节点上。
本题还要求最长的  要最短,那么在合并 k 个子树时,尽可能的优先选择当前深度最小的进行合并。
要最短,那么在合并 k 个子树时,尽可能的优先选择当前深度最小的进行合并。
另外,由于每次合并,堆中的节点个数都会减少  个,最终只会剩下一个,所以起初堆中的节点应当满足对
个,最终只会剩下一个,所以起初堆中的节点应当满足对  取模等于 1,如果不满足,那么补充一些空节点即可(权值为 0,深度为 0)。
取模等于 1,如果不满足,那么补充一些空节点即可(权值为 0,深度为 0)。
#include <bits/stdc++.h>using namespace std;const int N = 100010;typedef long long ll;int n,k;priority_queue<pair<ll,ll> > q;ll x;int main(){scanf("%d%d",&n,&k);for(int i=1;i<=n;i++){scanf("%lld",&x);q.push({-x, 0});}while((q.size() - 1) % (k-1)){q.push({0, 0});}ll res = 0;while(q.size() >= k){ll dep = 0, sum = 0;for(int i=1;i<=k;i++){sum -= q.top().first;dep = min(dep,q.top().second);q.pop();}res += sum;q.push({-sum,dep-1});}cout << res << endl;cout << -q.top().second << endl;return 0;}

若有收获,就点个赞吧
0 人点赞
