| 题号 | 标题 | 已通过代码 | 通过率 | tag | 难度 |
|---|---|---|---|---|---|
| A | 智乃的Hello XXXX | 点击查看 | 3023/3257 | 签到 | 500 |
| B | 智乃买瓜 | 点击查看 | 1632/3604 | DP | 1300 |
| C | 智乃买瓜(another version) | 点击查看 | 331/811 | DP | 1900 |
| D | 智乃的01串打乱 | 点击查看 | 2851/4923 | 模拟 | 1000 |
| E | 智乃的数字积木(easy version) | 点击查看 | 829/1948 | 模拟 | 1400 |
| F | 智乃的数字积木(hard version) | 点击查看 | 31/264 | 并查集启发式合并 | 2300 |
| G | 智乃的树旋转(easy version) | 点击查看 | 438/1443 | 平衡树 | 1700 |
| H | 智乃的树旋转(hard version) | 点击查看 | 77/179 | 平衡树 | 2000 |
| I | 智乃的密码 | 点击查看 | 746/4260 | 贪心模拟二分 | 1500 |
| J | 智乃的C语言模除方程 | 点击查看 | 109/861 | 数学 | 2000 |
| K | 智乃的C语言模除方程(another version) | 点击查看 | 16/95 | 数学 | 2200 |
| L | 智乃的数据库 | 点击查看 | 1078/2757 | 模拟数据结构 | 1500 |
A
B
分组背包DP模版题
设 d[i][j] 表示前 i 个西瓜,凑出重量 j 的方案数。
那么有动态转移方程:
第 i 个瓜有三种转移策略:
- 不买,累加

- 买半个,累加

- 买一整个,累加

将这三个加到一起,就是 d[i][j] 了。
注意到,计算 d[i][j] 时,只会用到 d[i-1] 中更小的 j,所以可以使用滚动数组来压缩,倒序枚举 j 即可。(当然这一步省掉也是OK的)
#include<bits/stdc++.h>using namespace std;#define rep(i,j,k) for(int i=int(j);i<=int(k);i++)#define per(i,j,k) for(int i=int(j);i>=int(k);i--)typedef long long ll;const int N = 1010, mod = 1e9 + 7;int n, m, w[N];ll d[N];int main(){cin >> n >> m;d[0] = 1;rep(i,1,n) {scanf("%d", &w[i]);for(int j = m; j >= 0;j--){if(j >= w[i]) d[j] = (d[j] + d[j - w[i]]) % mod;if(j >= w[i] / 2) d[j] = (d[j] + d[j - w[i] / 2]) % mod;}}rep(i,1,m) printf("%lld ", d[i]);puts("");}
C
DP
由于只有买半个重量为 2 的西瓜,才有可能使得总重量为 1,所以 d[1] 就是西瓜重量为 2 的数量。
然后试图从 DP 数组中删除这些瓜的贡献:
for(int t = 1; t <= d[1]; t ++){for(int j = 1; j <= m; j ++) {if(j >= w / 2) d[j] = (d[j] - d[j - 1] + mod) % mod;if(j >= w) d[j] = (d[j] - d[j - 2] + mod) % mod;}}
删除掉以后,当前 d[2] 的值就是西瓜重量为 4 的数量,然后再紧接着消除即可。
#include<bits/stdc++.h>using namespace std;#define rep(i,j,k) for(int i=int(j);i<=int(k);i++)#define per(i,j,k) for(int i=int(j);i>=int(k);i--)typedef long long ll;const int N = 1010, mod = 1e9 + 7;int n, m, a[N], c[2 * N];ll d[N], f[N];int main(){scanf("%d", &m);rep(i,1,m) {scanf("%lld", &d[i]);}d[0] = 1;for(int i = 1; i <= m; i++){int w = i * 2;c[w] = d[i];n += c[w];for(int t = 1; t <= c[w]; t ++){for(int j = 1; j <= m; j++){if(j >= w / 2) d[j] = (d[j] - d[j - w / 2] + mod) % mod;if(j >= w) d[j] = (d[j] - d[j - w] + mod) % mod;}}}printf("%d\n", n);for(int i=2;i<=2*m;i+=2){while(c[i]) {printf("%d ", i);c[i] --;}}return 0;}
D
签到题
很简单,这里提供两种思路:
- 可以排序后与原串对比,如果不一样则输出,否则倒序之后输出。
- 找到随便一个与 s[0] 不同的字符,与之交换输出。
```cpp
include
using namespace std;define rep(i,j,k) for(int i=int(j);i<=int(k);i++)
define per(i,j,k) for(int i=int(j);i>=int(k);i—)
typedef long long ll; int n; string s, t;
int main(){ cin >> n >> s; t = s; sort(s.begin(), s.end()); if(s != t) { cout << s << endl; } else{ reverse(s.begin(), s.end()); cout << s << endl; } return 0; }
```cpp#include <bits/stdc++.h>using i64 = long long;int main() {std::ios::sync_with_stdio(false);std::cin.tie(nullptr);int n;std::cin >> n;std::string s;std::cin >> s;int x = s.find(s[0] ^ 1); // 由于字符中只有 '0'(ASCII 48) 和 '1' (ASCII 49),所以可以通过异或来指定std::swap(s[0], s[x]);std::cout << s << "\n";return 0;}
E
计算一个字符串表示的数字取模后的值:
string s;cin >> s;long long rs = 0;for(auto &c : s) {rs = (rs * 10 + c - '0') % mod;}cout << rs << endl;
对于原串中颜色相同的一个区间 [l, r](用双指针维护一下),然后对 [l, r] 按照降序排列,最后计算即可。
#include<bits/stdc++.h>using namespace std;#define rep(i,j,k) for(int i=int(j);i<=int(k);i++)#define per(i,j,k) for(int i=int(j);i>=int(k);i--)typedef long long ll;const int N = 100010, mod = 1e9 + 7;int n, m, k;char s[N], t[N];int c[N];int get() {memcpy(t, s, sizeof t);int l = 1;rep(i, 1, n) {// 当 i == n 或 i 和 i + 1 颜色不同时,i 为区间右端点if(i == n || c[i] != c[i + 1]) {sort(t + l, t + i + 1, greater<char>()); // 对 [l, i] 降序排序l = i + 1; // 设置新的区间左端点}}ll sum = 0;rep(i,1,n) {sum = sum * 10 + (t[i] - '0');sum %= mod;}return sum;}int main(){scanf("%d%d%d", &n, &m, &k);scanf("%s", s + 1);rep(i,1,n) {scanf("%d", &c[i]);}printf("%d\n", get());while(k--){int x, y;scanf("%d%d", &x, &y);rep(i,1,n) if(c[i] == x) c[i] = y; // 修改颜色printf("%d\n", get());}return 0;}
F
题意与E题相同,不同的是变色次数变成了  。
。
样例: 字符:12345 初试颜色:1 2 3 4 3
每个颜色分配一个集合:
颜色1:[1, 1]
颜色2:[2, 2]
颜色3:[3, 3],[5, 5]
颜色4:[4, 4]
每种颜色对应一个集合,集合中包含若干区间,每个区间的颜色都应当统一。
当颜色 x 和染成颜色 y 时,等同于将集合 x 中的元素移动到集合 y 中,并对集合 y 中的区间进行合并。
我们每次将小的集合向大的集合合并,这样的操作,总体复杂度为  ,因为每次合并,集合大小至少扩大二倍,所以最终每个元素的合并次数不超过
,因为每次合并,集合大小至少扩大二倍,所以最终每个元素的合并次数不超过  。
。
具体合并时,假设 x 是较小的集合,遍历其中的每个区间,尝试与 y 中与之相邻的区间进行合并(使用 lower_bound等二分快速找到相邻集合)。
我们可以用一个结构体来描述一个区间:
struct Node {int l, r; // 区间左右端点int cnt[10]; // cnt[x] 表示该区间中 x 的个数ll sum; // 该区间对整体答案的贡献Node(){ // 构造函数,初始化l = r = sum = 0;memset(cnt, 0, sizeof cnt);}void get(){ // 更新该区间对最终答案的贡献sum = 0;int suf = n - l + 1; // suf 为当前区间所处的后缀长度for(int i = 9; i >= 0; i--){ // 贪心的,优先考虑拼凑最大的,从9开始倒序考虑// 这里要拼凑 cnt[i] 个 i,可以用 10^cnt[i] - 1 来表示 cnt[i] 个 9 的数值,然后除以 9 再乘 i// 比如 5 个 4 即 44444 等于 (10^5 - 1) / 9 * 4 = 99999 / 9 * 4// 模意义下,除法要变为乘逆元// 最后还要乘上 10^sufsuf -= cnt[i];// (10^cnt - 1) / 9 * ksum = (sum + (P[cnt[i]] - 1 + mod) % mod * inv9 % mod * i % mod * P[suf] % mod) % mod;}}// 重载 < 运算符,用于二分查找bool operator < (const Node & o) const {return l < o.l;}};
因此,可以方便的实现集合合并,顺便进行最终答案的修改。由于启发式合并以及单次合并要进行二分查找,所以总体复杂度为 。
。
#include<bits/stdc++.h>using namespace std;#define dbg(x...) do { cout << "\033[32;1m" << #x <<" -> "; err(x); } while (0)void err() { cout << "\033[39;0m" << endl; }template<class T, class... Ts> void err(const T& arg,const Ts&... args) { cout << arg << " "; err(args...); }#define rep(i,j,k) for(int i=int(j);i<=int(k);i++)#define per(i,j,k) for(int i=int(j);i>=int(k);i--)typedef long long ll;const int N = 100010, mod = 1e9 + 7;int n, m, k, col[N];ll P[N], inv9, rs;ll ksm(ll a, ll b){ll rs = 1;for(;b;b >>= 1) {if(b & 1) rs = rs * a % mod;a = a * a % mod;}return rs;}char s[N];struct Node {int l, r;int cnt[10];ll sum;Node(){l = r = sum = 0;memset(cnt, 0, sizeof cnt);}void get(){sum = 0;int suf = n - l + 1;for(int i = 9; i >= 0; i--){suf -= cnt[i];sum = (sum + (P[cnt[i]] - 1 + mod) % mod * inv9 % mod * i % mod * P[suf] % mod) % mod;}}bool operator < (const Node & o) const {return l < o.l;}};set<Node> st[N];void get(){Node t;t.l = 1; t.sum = 0;rep(i,1,n) {t.cnt[s[i] - '0'] ++;if(i == n || col[i] != col[i + 1]) {t.r = i;t.get();rs = (rs + t.sum) % mod;st[col[i]].insert(t);t.l = i + 1;memset(t.cnt, 0, sizeof t.cnt);}}}void merge(int x, int y){if(st[x].size() < st[y].size()) {swap(st[x], st[y]);}// 集合合并for(auto t : st[y]) {auto it = st[x].upper_bound(t);if(it != st[x].end() && (*it).l == t.r + 1) {Node p = *it;st[x].erase(it);rs = (rs - t.sum + mod - p.sum + mod) % mod;for(int i = 9; i >= 0; i--) t.cnt[i] += p.cnt[i];t.r = p.r;t.get();rs = (rs + t.sum) % mod;}it = st[x].lower_bound(t);if(it != st[x].begin() && ((*--it).r == t.l - 1)) {Node p = *it;st[x].erase(it);rs = (rs - t.sum + mod - p.sum + mod) % mod;for(int i = 9; i >= 0; i--) t.cnt[i] += p.cnt[i];t.l = p.l;t.get();rs = (rs + t.sum) % mod;}st[x].insert(t);}swap(st[x], st[y]);st[x].clear();}int main(){scanf("%d%d%d", &n, &m, &k);scanf("%s", s + 1);P[0] = 1;rep(i,1,n) P[i] = P[i-1] * 10 % mod;inv9 = ksm(9, mod - 2);rep(i,1,n) {scanf("%d", &col[i]);}get();printf("%lld\n", rs);while(k --){int x, y; scanf("%d%d", &x, &y);if(x != y) merge(x, y);printf("%lld\n", rs);}}
G
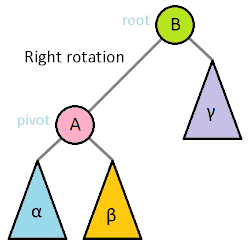
A 要进行右旋,旋转后 A 将变为 B 的父亲,假设实际树中 B 还有父亲 C,那么 C 的孩子将有原来的 B 替换为 A。
所以,给定两个树 A,B,如果只进行了最多一次旋转,我们只需要同时从两个树的根开始 DFS,如果遇到某个结点 X,X 在 A 树中的左孩子(或右孩子)是 H,而 X 在 B 树中的左孩子(或右孩子)是 G,那么说明是 G 进行了旋转。
#include<bits/stdc++.h>using namespace std;#define rep(i,j,k) for(int i=int(j);i<=int(k);i++)#define per(i,j,k) for(int i=int(j);i>=int(k);i--)typedef long long ll;const int N = 1010;int n;bool flag;struct Tr{int l[N], r[N];int fa[N];int rt;// 初始化 fa 数组 和 rt(即 root)void getf(){rep(i,1,n) {fa[l[i]] = i;fa[r[i]] = i;}rep(i,1,n) {if(fa[i] == 0) rt = i;}}}A, B;void dfs(int x) {if(x == 0) return; // 为 0 直接返回,否则会无限递归if(flag) return;if(A.l[x] == B.l[x]) {dfs(A.l[x]);} else { // 左孩子不同printf("%d\n", A.l[x]);flag = true; return;}if(A.r[x] == B.r[x]) { // 右孩子不同dfs(A.r[x]);} else {printf("%d\n", A.r[x]);flag = true; return;}}int main(){scanf("%d", &n);rep(i,1,n) {scanf("%d%d", &A.l[i], &A.r[i]);}A.getf();rep(i,1,n) {scanf("%d%d", &B.l[i], &B.r[i]);}B.getf();bool fg = false;// 判断两个树是否一致rep(i,1,n) {if(A.l[i] == B.l[i] && A.r[i] == B.r[i]) continue;fg = true; break;}if(!fg) {printf("0\n");return 0;}printf("1\n");if(A.rt != B.rt) {printf("%d\n", A.rt);return 0;}dfs(A.rt);return 0;}
H
有两个树A,B。我们要对 B 进行复原成A。
第一步可以做的就是,判断 A 和 B 的根是否一致。
如果不一致,设 X 为 A 当前的根,在 B 中找到 X,然后将 X 向上旋转,直到 X 为当前的根。(实际处理过程要注意细节)
如果一致则分别递归左右两边。
递归后,当做子树问题来处理即可。根据二叉搜索树的性质,根结点如果一致,那么两边的结点集合也一定是相同的。
难点在于代码上。
#include<bits/stdc++.h>using namespace std;#define dbg(x...) do { cout << "\033[32;1m" << #x <<" -> "; err(x); } while (0)void err() { cout << "\033[39;0m" << endl; }template<class T, class... Ts> void err(const T& arg,const Ts&... args) { cout << arg << " "; err(args...); }#define rep(i,j,k) for(int i=int(j);i<=int(k);i++)#define per(i,j,k) for(int i=int(j);i>=int(k);i--)typedef long long ll;const int N = 1010;int n;bool flag;struct Tr{int l[N], r[N];int fa[N];int rt;void getf(){rep(i,1,n) {fa[l[i]] = i;fa[r[i]] = i;}rep(i,1,n) {if(fa[i] == 0) {rt = i;l[0] = rt;}}}void rotate(int p) {// 旋转代码不要写错,除了维护 l,r 还要维护 faint f = fa[p], anc = fa[f];if(p == l[f]) { // 右旋int rson = r[p];l[f] = rson; fa[rson] = f;r[p] = f; fa[f] = p;if(f == l[anc]) l[anc] = p;else r[anc] = p;fa[p] = anc;} else { // 左旋int lson = l[p];r[f] = lson; fa[lson] = f;l[p] = f; fa[f] = p;if(f == l[anc]) l[anc] = p;else r[anc] = p;fa[p] = anc;}rt = l[0];}}A, B;vector<int> rs;void dfs(int Art, int Brt) {if(Art == 0) return;// 如果当前子树中,A的根和B的根不一致,那么就要对B进行调整if(Art != Brt){// 不断的调整 B 中 Art 的位置,使得 Art 在A 和 B 中的父亲是一致的(也就是子树的根一致了)while(A.fa[Art] != B.fa[Art]) {B.rotate(Art);rs.push_back(Art);}}dfs(A.l[Art], B.l[Art]);dfs(A.r[Art], B.r[Art]);}int main(){scanf("%d", &n);rep(i,1,n) {scanf("%d%d", &A.l[i], &A.r[i]);}A.getf();rep(i,1,n) {scanf("%d%d", &B.l[i], &B.r[i]);}B.getf();bool fg = false;rep(i,1,n) {if(A.l[i] == B.l[i] && A.r[i] == B.r[i]) continue;fg = true; break;}if(!fg) {printf("0\n");return 0;}dfs(A.rt, B.rt);printf("%d\n", (int) rs.size());for(auto &x : rs) printf("%d ", x);return 0;}
I
首先判断得到每个字符它所属的类别,然后用前缀和 d[i][j] 表示前面 i 个字符中,类别 j 的个数。
假设 [L, R] 满足要求,那么对于所有的 l < L, [l, R] 都满足要求。
固定 R,求解最大的 L,使得 [L, R] 满足要求。然后考虑 R 递增,这样的 L 也是非严格递增的,所以可以用一个指针来维护 L。
每次求到的都是最短的区间 [L, R], 所以符合要求的长度区间为 [R - L + 1, R], 与题目输入的区间求交即可。
当然,L 也可以每次二分去求。
7ms
#include<bits/stdc++.h>using namespace std;#define dbg(x...) do { cout << "\033[32;1m" << #x <<" -> "; err(x); } while (0)void err() { cout << "\033[39;0m" << endl; }template<class T, class... Ts> void err(const T& arg,const Ts&... args) { cout << arg << " "; err(args...); }#define rep(i,j,k) for(int i=int(j);i<=int(k);i++)#define per(i,j,k) for(int i=int(j);i>=int(k);i--)typedef long long ll;const int N = 100010;int n, l, r;char s[N];int d[N][4];int get(int L, int R) {return max(0, min(R, r) - max(L, l) + 1);}bool check(int L, int R) {int cnt = 0;rep(i,0,3) if(d[R][i] - d[L - 1][i] > 0) cnt ++;return cnt >= 3;}int main(){cin >> n >> l >> r;scanf("%s", s + 1);ll rs = 0;int L = 1;rep(i,1,n) {int t;if(s[i] >= 'a' && s[i] <= 'z') t = 0;else if(s[i] >= 'A' && s[i] <= 'Z') t = 1;else if(s[i] >= '0' && s[i] <= '9') t = 2;else t = 3;// memcpy 内存拷贝,直接赋值之前的memcpy(d[i], d[i-1], sizeof d[i]);d[i][t] ++;// 贪心,尽量让 L 变得更大while(L < i && check(L + 1, i)) L++;if(check(L, i)) {rs += get(i - L + 1, i); // [i - L + 1, i] 与 [l, r] 求交}}printf("%lld\n", rs);return 0;}
二分(12ms):
#include<bits/stdc++.h>using namespace std;#define dbg(x...) do { cout << "\033[32;1m" << #x <<" -> "; err(x); } while (0)void err() { cout << "\033[39;0m" << endl; }template<class T, class... Ts> void err(const T& arg,const Ts&... args) { cout << arg << " "; err(args...); }#define rep(i,j,k) for(int i=int(j);i<=int(k);i++)#define per(i,j,k) for(int i=int(j);i>=int(k);i--)typedef long long ll;const int N = 100010;int n, l, r;char s[N];int d[N][4];int get(int L, int R) {return max(0, min(R, r) - max(L, l) + 1);}int main(){cin >> n >> l >> r;scanf("%s", s + 1);ll rs = 0;rep(i,1,n) {int t;if(s[i] >= 'a' && s[i] <= 'z') t = 0;else if(s[i] >= 'A' && s[i] <= 'Z') t = 1;else if(s[i] >= '0' && s[i] <= '9') t = 2;else t = 3;memcpy(d[i], d[i-1], sizeof d[i]);d[i][t] ++;int L = -1, R = i - 1;while(L < R) {int m = L + R + 1 >> 1;int mn = 0;rep(j,0,3) mn += d[i][j] - d[m][j] > 0;if(mn >= 3) {L = m;} else R = m - 1;}if(L != -1) {rs += get(i - L, i);}}printf("%lld\n", rs);return 0;}
J
 ,问有多少 x,满足
,问有多少 x,满足

题目中有说,取模后的结果,正负号与 P 无关,只与 x 有关。所以一开始我们就可以将 P 直接取绝对值。
对于 [L,R] 和 [l,r],区间内可能正负数都有,但我们可以将负数对称过来当正数处理。
对于原本正数的部分:[ max(0, L), R] 和 [ max(0, l), r]
对于原本负数的部分:[max(0, -R), -L] 和 [max(0, -r), -l]
当然,如果 R < 0, 那么 [ max(0, L), R] 就是个不正确的区间,区间右端点小于左端点的特殊情况,可以直接返回 0 的结果。
然后,按照上面的分类,进行正数和负数部分计算时,0会被计算两次,所以可以将负数部分整体右移:[max(1, -R), -L] 和 [max(0, -r), -l](值域并不右移)
所以,现在问题简化为:
设 get(R, r) 表示有多少 0 <= x <= R 模 P 后 Q 满足 0 <= Q <= r。
那么直接调用 (get(R, r) - get(R, l - 1)) - (get(L - 1, r) - get(L - 1, l - 1)) 即可。
get(R, r) 如何实现,留给自己想象。
int p, l, r, L, R;ll rs;int get(int R, int r) {if(R < 0 || r < 0) return 0;r = min(r, p - 1);return R / p * (r + 1) + min(R % p, r) + 1;}int get(int L, int R, int l, int r) {if(R < L || r < l) return 0;return (get(R, r) - get(R, l - 1)) - (get(L - 1, r) - get(L - 1, l - 1));}int main(){cin >> p >> l >> r >> L >> R;p = abs(p);int rs = get(max(0, L), R, max(0, l), r)+ get(max(1, -R), -L, max(0, -r), -l);printf("%d\n", rs);return 0;}
K
 ,问有多少 x,满足
,问有多少 x,满足
找不到切入点时,可以尝试打表找规律。下面是给出定理和证明:
如果有两个整数 
由取模定义:
可以得到:
所以,如果有一个数列: ,其取值
,其取值 相同。那么
相同。那么  是一个等差数列。
是一个等差数列。
例如,100 / 34 = 100 / 50 = 2,所以对于 {34, 35, 36, … 50},取模后构成等差数列: 100 % 34 = 32, 100 % 35 = 30, 100 % 36 = 28, … 100 % 50 = 0
所以,如果要求 [1, R] 中有多少 x 满足 P % x 在 [0, r] 范围内,可以使用数论分块快速计算。(即每一块内,构成一个等差数列)
其余的部分与 J 题类似。
const int inf = 1e9 + 3;int p, l, r, L, R;int get(int R, int r) {if(R < 1 || r < 0) return 0;int rs = 0;// 对于 R > p 的情况,p % x 恒等于 p,单独统计答案if(R > p) {if(r >= p) rs += R - p;R = p;}// 数论分块,复杂度 O(根号R)for(int x = 1, y = 0; x <= R; x = y + 1) {//定义 k = p / x,那么 [x, y] 中的所有值 i 都有 p / i = k,且 y 是满足这个条件的最大值,x是最小值。y = min(R, p / (p / x));// s 为等差数列首项,t 为末项int s = p % y, t = p % x;int cnt = y - x + 1;// 计算等差数列中有多少数字在 [0, r] 中if(t <= r) rs += cnt;else if(s <= r) {int d = (t - s) / (y - x);rs += (r - s) / d + 1;}}return rs;}int get(int L, int R, int l, int r) {if(L > R || l > r) return 0;return get(R, r) - get(R, l - 1) - get(L - 1, r) + get(L - 1, l - 1);}int main(){cin >> p >> l >> r >> L >> R;// 将 p < 0 的情况对称到 p >= 0, 值域 [l,r] 也要相应翻转if(p < 0) {p = -p;l = -l, r = -r;swap(l, r);}// 由于 p >= 0,所以 l >= 0 的情况才会被计算l = max(0, l);int rs = get(max(1, L), R, l, r)+ get(max(1, -R), -L, l, r);printf("%d\n", rs);}
L
序列去重、计数问题。
难点:从输入的SQL语句中提取出关键字,然后筛选出目标列。序列计数操作。
可以直接用 map
直接用 map 166 ms
#include<bits/stdc++.h>using namespace std;#define rep(i,j,k) for(int i=int(j);i<=int(k);i++)#define per(i,j,k) for(int i=int(j);i>=int(k);i--)typedef long long ll;const int N = 1010;int n, m;string s[N], q;int a[N][N];vector<int> v;unordered_map<string,int> mp;vector<vector<int>> b;map<vector<int>, int> mp2;vector<int> rs;int main(){scanf("%d%d", &n, &m);rep(i,1,m) cin >> s[i], mp[s[i]] = i;rep(i,1,n) rep(j,1,m) scanf("%d", &a[i][j]);getline(cin, q); // 读取空行getline(cin, q); // 读取 SQLq = q.substr(36);q.pop_back(); // 将最后的分号去掉int i = 0;while(i < q.size()) {int j = q.find(',', i); // 获得下一个 ',' 的位置if(j == -1) j = q.size(); // 如果没有,直接定位到最后string t = q.substr(i, j - i); // 获得子串 termv.push_back(mp[t]);i = j + 1;}rep(i,1,n) {vector<int> t;for(auto &x : v) {t.push_back(a[i][x]);}mp2[t] ++;}printf("%d\n",(int) mp2.size());for(auto [k, v] : mp2) {printf("%d ", v);}puts("");return 0;}
对 vector
#include<bits/stdc++.h>using namespace std;#define rep(i,j,k) for(int i=int(j);i<=int(k);i++)#define per(i,j,k) for(int i=int(j);i>=int(k);i--)typedef long long ll;const int N = 1010;int n, m;string s[N], q;int a[N][N];vector<int> v;unordered_map<string,int> mp;vector<vector<int>> b;vector<int> rs;int main(){scanf("%d%d", &n, &m);rep(i,1,m) cin >> s[i], mp[s[i]] = i;rep(i,1,n) rep(j,1,m) scanf("%d", &a[i][j]);getline(cin, q);getline(cin, q);q = q.substr(36);q.pop_back();int i = 0;while(i < q.size()) {int j = q.find(',', i);if(j == -1) j = q.size();string t = q.substr(i, j - i);v.push_back(mp[t]);i = j + 1;}rep(i,1,n) {vector<int> t;for(auto &x : v) {t.push_back(a[i][x]);}b.push_back(t);}// 排序sort(b.begin(), b.end());for(int i = 0; i < b.size(); i++){if(i == 0 || b[i] != b[i-1]) { // 与前面的不一样,则新增一个 1rs.push_back(1);} else { // 一样则 ++rs[rs.size() - 1] ++;}}cout << rs.size() << endl;for(auto &x : rs) printf("%d ", x);puts("");return 0;}

若有收获,就点个赞吧
0 人点赞
