ElasticSearch安装
- 准备安装包
版本:7.14.0
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
选择对应操作系统平台版本,此文档以CentOS为例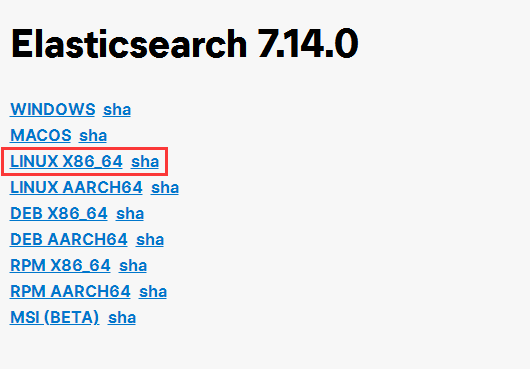
- 创建普通用户账号
因为安全问题,ES不允许使用root用户安装运行,所以我们需要创建一个普通用户。
useradd espasswd es
es为我们自定义的新用户的名称,按顺序运行两条shell命令,会提示输入两次密码
创建成功之后,可以快速切换登录用户
su es
- 上传解压缩ES
上传安装包至/application/下并进入到这个目录,解压缩安装包
tar -xvf elasticsearch-7.14.0-linux-x86_64.tar.gz
为了方便管理操作,建议对此目录重命名
mv elasticsearch-7.14.0 elasticsearch
- 启动ES
注意:ElasticSearch 7.x运行依赖jre11.x及以上版本,但是ES安装包中自带有jdk,因此我们不必卸载已安装的jdk,直接使用包内自带jdk即可。
注:ElasticSearch 7.14.0自带JDK版本为16.0.1。
使用ES安装包内jdk,需要配置到环境变量中,否则
warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOMEThe minimum required Java version is 8; your Java version from [/usr/local/java/jdk1.7.0_79/jre] does not meet this requirement. Consider switching to a distribution of Elasticsearch with a bundled JDK. If you are already using a distribution with a bundled JDK, ensure the JAVA_HOME environment variable is not set.
配置使用ES包内jdk (使用root账号)
vi /etc/profile
添加配置
export ES_JAVA_HOME=/application/elasticsearch/jdk
刷新配置
source /etc/profile
启动ES,需要重新登录es用户
/application/elasticsearch/bin/elasticsearch
如果需要后台静默启动,则需要在启动命令后添加参数:-d
- 验证启动状态
如果是以前台的方式启动,则可以在控制台中看到启动的日志,若出现
[2022-03-15T16:05:05,529][INFO ][o.e.n.Node ] [localhost.localdomain] initialized[2022-03-15T16:05:05,529][INFO ][o.e.n.Node ] [localhost.localdomain] starting ...
或者查询ES进程
ps -ef | grep elasticsearch
出现
es 7260 7228 42 16:04 pts/0 00:00:35 /opt/elasticsearch/jdk/bin/java ...org.elasticsearch.bootstrap.Elasticsearch
说明启动成功
- 测试本地访问
在未进行配置的情况下,ES只允许本地访问,端口号默认为9200
curl http://localhost:9200/
结果:
{"name" : "localhost.localdomain","cluster_name" : "elasticsearch","cluster_uuid" : "4X47rTeTQMybCSnfy7csPg","version" : {"number" : "7.14.0","build_flavor" : "default","build_type" : "tar","build_hash" : "dd5a0a2acaa2045ff9624f3729fc8a6f40835aa1","build_date" : "2021-07-29T20:49:32.864135063Z","build_snapshot" : false,"lucene_version" : "8.9.0","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"}
表示启动成功
- 开启远程访问
开启远程访问,需要修改ES的配置文件
vi /application/elasticsearch/conf/elasticsearch.yml
添加配置:
# ======================== Elasticsearch Configuration =========================# 配置ES集群的名称,默认是elasticsearch。建议修改成一个有意义的名称cluster.name: jeecg-ES# 配置当前ES应用节点的名称,默认由ES随机指定一个名称。建议修改成一个有意义的名称node.name: node-0# ES默认只允许本地访问,在此处设置域名、IP白名单,设置为0.0.0.0时表示允许任意IPnetwork.host: 0.0.0.0# 配置ES应用访问端口,默认为9200。不建议修改http.port: 9200# 配置集群初始化时选举master节点列表cluster.initial_master_nodes: ["node-0"]
重新启动ES
意外情况
配置ES远程访问后重启,发现启动时报错
ERROR: [3] bootstrap checks failed. You must address the points described in the following [3] lines before starting Elasticsearch.bootstrap check failure [1] of [3]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]bootstrap check failure [2] of [3]: max number of threads [3833] for user [esch] is too low, increase to at least [4096]bootstrap check failure [3] of [3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]ERROR: Elasticsearch did not exit normally - check the logs at /opt/elasticsearch/logs/my-application.log
第一个描述是:最大文件句柄4096太小了,需要至少65535
第二个描述是:最大线程数3833太少了,需要分配至少4096
第三个描述是:最大虚拟内存65530太小了,需要至少262144
需要对服务器进行配置(使用root用户)
es soft nofile 65536 es hard nofile 65536
es soft nproc 4096 es hard nproc 4096
使用es用户重新登录,验证配置是否成功(四个值都是4096表示成功)```shellulimit -Hnulimit -Snulimit -Huulimit -Hu
- /etc/sucurity/limits.d/**-nproc.conf
如果配置1不生效,则继续配置
es soft nofile 65536es hard nofile 65536es soft nproc 4096es hard nproc 4096# 注意要在 * 前配置
同样需要es用户重新登录
- /etc/sysctl.config
然后sysctl重新加载vm.max_map_count=262145
再次启动ES,直到成功启动。sysctl -p
ES启动成功之后,需要开放服务器9200端口
然后在远程访问http://es主机ip:9200/,直到出现本地访问相同的响应。
Kibana安装
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。
Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。
可以理解成,ES是MySQL服务器,而Kibana就是连接MySQL的可视化工具
- 准备安装包
版本:7.14.0
下载地址:https://www.elastic.co/cn/downloads/past-releases#kibana
与ES安装过程类似,使用非root用户解压
- 配置Kibana
Kibana与ES一样,是运行在服务器上的一个应用,但Kibana启动前需要指定其连接的ES服务
vi /application/kibana/config/kibana.yml
添加配置
# kibana的http访问端口,默认为5601server.port: 5601# kibana访问白名单,0.0.0.0表示任意IP都可以访问server.host: "0.0.0.0"# kibana服务名称,可以自定义。建议定义为有意义的名称,方便管理server.name: "kibana-itcast"# 连接访问ES的域名端口,表示这个kibana需要连接哪些ES应用,可以配置多个elasticsearch.hosts: ["http://127.0.0.1:9200"]# 请求ES的超时时间,默认为30000,单位ms,需要根据实际情况进行设置elasticsearch.requestTimeout: 30000
- 启动Kibana(使用非root用户)
Kibana和ES一样,因为安全问题,不建议使用root用户启动Kibana,但Kibana并没有绝对禁止使用root用户启动,如果需要,则需要在启动命令后添加参数:./opt/kibana/bin/kibana
--allow-root
前台启动Kibana,如果日志中出现
log [15:41:19.631] [info][status] Kibana is now available (was unavailable)
则表示Kibana启动成功
- 测试使用
Kibana启动成功后,我们可以通过浏览器进行访问
url:http://Kibana所在主机ip:5601/
进入到Kibana的home页
点击左侧菜单栏【Management】>【Dev Tools】>【Console】,运行第一行
IK分词器安装
- 准备安装包
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
注意:IK版本号需要与ES完全对应,否则无法使用
例如此文档ES版本为7.14.0,则使用IK的版本也必须是7.14.0
进入源码仓库后,在右侧找到【Releases】->【+** releases】,可以找到旧版版本IK
找到对应版本的IK后进入,一般存在3个文件
elasticsearch-analysis-ik-7.14.0.zip
此文件为编译后的压缩文件,可以直接使用,我们需要下载的就是这个
Source code (zip)
- Source code (tar.gz)
剩余这两个文件为不同压缩格式的源码文件,需要我们进行编译才能使用
- 上传解压缩
将下载的zip文件上传到目录/application/elasticsearch/plugins/下
解压后重命名
mv elasticsearch-analysis-ik-7.14.0 ik
最后确保目录结构是/application/elasticsearch/plugins/ik,并且ik目录下原压缩包里的各个jar文件和config文件夹等。
ik目录只是示例,这个目录的名称可以随便定义,因为ES能够扫描到plugins目录下的所有文件,当读取到ik目录下的plugin-descriptor.properties文件时就能正确加载到IK
- 重启ES验证插件
ES重启完成后进入Kibana后台执行测试请求
GET _analyze{"analyzer": "ik_max_word","text": "测试:我是一名Java程序员"}
查看返回结果,发现中文不再被拆分成一个个字,而是有“一名、程序、程序员”这种词语,则表示IK安装成功
- IK应用到索引
IK插件安装成功之后,需要用户指定字段使用该插件
PUT /user{"mappings": {"properties": {"id": {"type": "long"},"name": {"type": "text",#比如我们在创建索引时设置映射,配置映射时就能设置哪个字段使用哪个分词器的分词策略"analyzer": "ik_max_word"}}}}
索引创建完成后,我们再通过这个字段进行查询时,这个字段的值就能被分词进行匹配
例如:
# 测试数据POST /user/_doc/1{"id": 1,"name": "我是一名程序员,名字是mike"}#执行分词查询GET /user/_search{"query": {"term": {"name": {"value": "程序"}}}}
发现能正确查询到索引的文档数据
ElasticSearch
ES有3个基本概念:索引(index),映射(mapping),文档(document)
它其实也是参考关系型数据库的设计风格。类比一下:
- 一个ES服务可以看做是一个schema
- 一个索引可以看做这个schema中的一张数据表
- 一个映射可以看做一张数据表的表结构,包含了字段、字段的类型等
- 一个文档可以看做是数据表的一条数据记录
基本操作
官方文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.14/index.html
索引操作
对于索引,ES提供了四种操作接口:
- PUT(创建)
- GET(查询)
- DELETE(删除)
- HEAD(检测请求有效性)
注意:索引名称必须全部为小写,使用下划线分隔多个单词。 例如:article_category
创建索引
创建索引使用PUT请求
PUT /索引名称
创建索引时可以携带参数,比如索引配置信息、索引映射信息,详情参考下文[映射]和官方文档。不进行配置则会使用默认缺省值。
例如: PUT /member
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "member"}
查询索引
查询使用GET请求
GET /索引名称
例如:GET /member
{"member" : {"aliases" : { },"mappings" : { },"settings" : {"index" : {"routing" : {"allocation" : {"include" : {"_tier_preference" : "data_content"}}},"number_of_shards" : "1","provided_name" : "member","creation_date" : "1649670665493","number_of_replicas" : "1","uuid" : "QsBOSd23TNa9MuzOpQn52Q","version" : {"created" : "7140099"}}}}}
会返回该索引的映射、配置信息等。
查看所有索引GET /_cat/indices?v
| health | status | index | uuid | pri | rep | docs.count | docs.deleted | store.size | pri.store.size |
|---|---|---|---|---|---|---|---|---|---|
| green | open | .geoip_databases | 2u-8wlMDTZK1Q7jjrU4XHA | 1 | 0 | 44 | 41 | 41.8mb | 41.8mb |
| green | open | .kibana_7.14.0_001 | p3_HpQycQcK5RB1DpH03Mw | 1 | 0 | 37 | 23 | 2.1mb | 2.1mb |
| yellow | open | member | ne850sZsStaHpCxCVITW_g | 1 | 1 | 0 | 0 | 208kb | 208kb |
?v:?号表示请求后拼接的query参数,v表示显示表头信息 health:表示该索引的健康状态,green表示正常,yellow表示有风险。为什么我们新建的
member索引是yellow呢?观察第5、6列数据,pri表示索引主分片所在位置,1表示在本机,0表示在其他位置,rep表示索引分片的备份副本所在位置。若主分片和主分片副本都在本机上,那么主分片和副本就有可能一起丢失,存在风险
检测索引有效性
在创建索引之前,我们需要知道索引是否存在且正常,可以使用HEAD请求检测验证指定索引的有效性状态,即使不存在,也会有一个良好的返回。
HEAD /索引名称
例如:HEAD /member
如果索引存在且正常,则会返回200 - OK
如果不存在,则会返回{"statusCode":404,"error":"Not Found","message":"404 - Not Found"}
删除索引
删除索引使用DELETE请求
DELETE /索引名称
映射操作
索引的映射,可以在创建索引时手动创建,也可以在添加文档数据时自动创建。
自动创建(不建议)
ES没有强制要求创建索引时必须创建映射,但支持新增文档时,根据文档数据自动的创建映射。
由于文档一般是一个json数据,所以才支持这样使用。
类似于创建数据表时没有创建表的字段结构,在录入一条数据时,根据数据反射生成表字段及字段数据类型等。
但强烈不建议这样使用,因为我们更多需要对字段进行精确控制,比如使用指定分词器、数据类型、格式化等等。
手动创建(推荐)
手动创建映射即在创建索引时就创建索引的映射
PUT /member{# 这里可以设置索引相关的设置,固定用法,比如分片数量,备份数量# 当然这些设置都是有缺省默认的,可选"settings": {"number_of_shards": 1,"number_of_replicas": 0},# mappings表示索引的映射,固定用法"mappings": {# 映射字段信息,固定用法"properties": {"字段名称1": {# 字段类型,固定用法"type": "类型"},"字段名称2": {"type": "类型"}}}}
ES可用的字段数据类型:
- keyword:关键词,即最小文本单位,不可再分词
- text:文本,所有数据类型唯一一个会进行分词的数据类型
- integer、long、double、float:数值类型
- boolean:布尔型
- date:日期类型,注意,json没有date类型,记录的是timestamp,因此ES的date默认记录的也是timestamp
查询映射
查询映射使用GET请求
GET /索引名称/_mapping
文档操作
对于文档,ES提供了四种操作接口:
- POST(创建)
- GET(查询)
- PUT(更新)
- DELETE(删除)
创建文档
创建文档使用POST请求
POST /索引名称/_doc/[id值]
_doc:是一个固定用法,表示该条文档的类型 [id值]:[ ]表示该参数是可选参数,id值表示用户自定义新增的这条文档的id
顺带一提这个_doc,我们随便查询一条文档
{"_index" : "mopai_article","_type" : "_doc","_id" : "18","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"hits" : 0,"create_time" : 1649333154087,"author" : "张三","id" : 18,"is_publication" : 1,"title" : "张三的一生","content" : "","is_top" : 0,"likes" : 0}}
我们看到第3行有一个_type,它的值就是_doc,这是什么意思呢?
_type是早期版本的设计缺陷。 在5.x以前的版本里边,一个所以下面是支持多个type的。 6版本以后改为只支持一个type, type可以自定义。 7以后所有的type就默认为_doc。 8版本后移除type
而当前文档所使用的ES版本为7.14.0,默认就是_doc,因此我们不需要关心,只需要知道这么用就行了。
关于[id值],也类似于关系型数据库:
- 在索引中,任何一条文档都必须有一个唯一非空标识,即文档的PK;
- 文档的id可以使用用户指定值,但只会存在一条文档记录;
- 用户不指定文档id时,将会由ES自动生成;
- 文档的唯一标识,与索引映射中的id字段,并非同一个概念,它更类似于Oracle的ROWID,不论这个索引的映射中是否存在
id字段,这个索引的每一条文档都一定有自己的唯一标识; - 若索引映射中存在
id字段,并且也是唯一非空,那么强烈建议文档id使用映射中id字段的值,方便统一管理。
例如:
# 这里建议指定文档的id为映射中id字段的值,在查询时可以更方便快速查询到这条文档POST /users/_doc/9527{"id": 9527,"name": “张三”,"age": 28}
查询文档
查询文档使用GET请求
GET /索引名称/_doc/文档id
删除文档
删除文档使用DELETE请求
DELETE /索引名称/_doc/文档id
更新文档
更新文档使用PUT请求
基于id更新
PUT /索引名称/_doc/文档id{文档json数据}
注意:ES对文档的更新,并非和传统关系型数据库那样直接在原数据记录上进行修改,而是根据文档id,直接删除原文档,然后使用新的文档json数据,创建一条新文档,文档id不变。所以使用这种策略,改动的数据和未改动的数据,都要一并重新提交。
基于字段更新
上文中的更新策略似乎不太符合传统关系型数据库的操作习惯,所以ES也提供了这种习惯的更新策略
POST /索引名称/_doc/文档id/_update{# doc为固定用法,表示对文档进行操作"doc": {"待映射字段名": "新值"}}
此时,更新操作的请求类型不再是PUT,而是POST,并且需要拼接参数_update
这种策略就能只更新指定字段,并保留未更新的字段值
批量操作
如果需要一次性提交多个文档,我们显然不能为每一条文档发一次请求。_bulk表示批量操作,注意这个批量操作可以同时做新增、修改、删除操作
POST /索引名称/_doc/_bulk# 新增操作{"index": {"_id": 文档id值}}{文档json数据,注意这里面不允许换行}# 更新操作{"update": {"_id": 文档id值}}{文档json数据,注意这里面不允许换行}# 删除操作{"delete": {"_id": 文档id值}}
这三种操作可以有任意数量、任意顺序。
注意:单条文档操作具有原子性,但批量操作不具备原子性,其本质相当于批量逐条发起多次请求,而每个请求都是独立的,并没有事务的控制
高级查询
Query_DSL
DSL全称domain specified language,特殊领域语言。
Query_DSL是利用Restful API传递JSON数据的请求与ES交互,让ES检索更强大简洁。
语法:
GET /索引名/[_doc]/_search{json格式请求数据}
_doc在搜索操作中可以省略不写,其次不写_doc,ES可以在请求数据体中自动提示可选映射字段名称。
term
关键词查询,表示使用指定值做全匹配查询。
GET /索引名/_search{"query": {"term": {"映射字段名": {"value": 值}}}}
在【映射操作】这一章节中,我们提到了ES有一个数据类型为keyword。那么什么是关键词?
所谓关键词,就是ES中的最小文本单位,不可被分词,比如中文里一个汉字或词语、英文里一个单词,无法再被拆分出更小的单位(即使汉字能被拆成偏旁部首,单词能被拆成一个个字母,这些都不算)。
但是注意,最小文本单位并不是客观概念,而是由人为主观定义的,比如“手机“、“笔记本”,这些是由多个汉字组合成的具有语义的词语,同样可以作为的关键词,一旦拆分成逐个汉字,就会失去原有的语义,类似于字母组成单词,单词有语义。
举个例子:我们以“手机”为关键词去搜索商品,倘若“手机”还能拆分成“手”、“机”这两个字,以逐字为客观关键词,那么你搜索到的商品,除了手机,还有可能搜到“手摇发电机”、“手扶拖拉机”。而关键词的作用就是,保证文本中逐字的顺序,以及逐字的连续(“手”、“机”这两个字一定是连着的,中间不允许有其他文本)
全匹配,即要求查询值与被查询值及其分词(字段数据类型为text)完全相同
查询值:在查询请求的参数中,自定义的文本。比如下文查询例子中的”小浣熊干脆面” 被查询值:在索引的文档中,某字段的文本数据。
举个例子:我们需要搜索商品名为“小浣熊干脆面”的商品
GET /索引名/_search{"query": {"term": {"product_name": {"value": "小浣熊干脆面"}}}}
在未使用中文分词器的情况下,只有商品名刚好是“小浣熊干脆面”这6个字的商品才能被搜索到。
关于分词,若我们再ES中安装了IK分词器,并且索引的映射中指定某个类型为text的字段使用IK分词器,那么在term查询时,会先对被查询的字段进行分词,然后使用关键词去匹配字段的值,和该字段值的所有分词结果,一旦有一个匹配到,则表示整个文档匹配到这个关键词。
比如商品索引的product_name字段类型为text,分词策略为ik_max_word,那么这个字段在被查询前会被分词处理,例如商品名为“白象小浣熊干脆面”,就有可能被分词为“白象、浣熊、小浣熊、干脆、面、干脆面”等,此时使用term查询,关键词为“小浣熊”,就能够匹配到分词中的“小浣熊”。
match
模糊匹配查询
GET /索引名/_search{"query": {"match": {"映射字段名": {"query": 值,# 默认使用标准分词器,但实际上用到中文,就必须指定分词器,比如“ik_max_word”或“ik_smart”"analyzer": "ik_max_word"}}}}
上一节中,说到关键词是不会被分词的,而match查询会对查询值进行分词
例如:我们要查询商品名中包含“小浣熊”字样的商品
GET /索引名/_search{"query": {"match": {"product_name": {"query": "小浣熊","analyzer": "ik_max_word"}}}}
那么ES除了会对索引中product_name字段的值进行分词以外,还会对查询值“小浣熊”进行分词,比如分词结果为“小”、“浣熊”、“熊”。然后ES会使用“小浣熊”以及所有分词,分别做一次term查询,最后将所有term查询的结果做一个并集处理,作为这个match查询的最终返回。
我们知道,关键词保证了查询值文本中逐字的顺序和连续性,而分词后就无法保证这两点,也就是说同样的文本,使用match查询可能查询到“小当家浣熊干脆面”、“浣熊小干脆面”
match_phrase
短语查询
GET /索引名/_search{"query": {"match_phrase": {"映射字段名": {"query": 值,"analyzer": "ik_max_word"}}}}
上一节最后的问题,高度自由的模糊匹配,可能会导致查询精确度降低。
短语查询就考虑到精确度的问题,在对查询值进行分词之余,还会记录查询值所有分词的顺序位置。默认情况下匹配时:
- 要求被查询值及分词必须包含查询值的所有分词
- 被查询值的分词匹配到的顺序必须和查询值分词的顺序一致
- 默认情况下,要求所有匹配到的被查询值分词连续,且所有分词都必须匹配到
举个例子:
查询商品名中包含“小浣熊”的商品,分词顺序为“小”、“浣熊”。
索引中存在一条文档,商品名为“小浣熊干脆面”,分词顺序为“小”、“浣熊”、“干脆”、“面”。
在默认情况下,
- 要求“小浣熊干脆面”的所有分词必须包含“小浣熊”的全部分词
- 其次要求被查询值中匹配到所有分词的顺序必须和查询值的分词顺序一致(比如商品名为“浣熊小干脆面”,分词顺序为“浣熊”、“小”、“干脆”、“面”,“浣熊、小”的顺序与“小、浣熊”的顺序不匹配)
- 最后被查询值中匹配的所有分词位置必须和查询值的分词顺序一致(比如商品名为“小当家浣熊干脆面”,分词顺序为“小”、“当家”、“浣熊”、“干脆”、“面”,虽然匹配到的“小”、“浣熊”先后顺序正确,但中间还有一个分词“当家”导致“小”、“浣熊”不连续)
当短语文本过长时,会发现查询匹配率快速下降。短语查询提供了容错数的配置
GET /索引名/_search{"query": {"match_phrase": {"映射字段名": {"query": 值,"analyzer": "ik_max_word","slop": 0}}}}
slop表示容错数,缺省值为0,表示不允许任何匹配错误,增加该值可以提高匹配容错率
combined_fields
组合字段查询,可以同时对多个字段使用同一个查询值进行查询。
GET /索引名/_search{"query": {"combined_fields": {"fields": ["字段1", "字段2"],"query": "查询值","operator": "or"}}}
比如我们在搜索一篇文章时,可能需要同时搜索标题、副标题、正文、作者,只要能在这几个字段中任意一个匹配上就算匹配成功。
注意:fields中的字段只能是text类型,并且这些字段必须使用同一个分词策略。由于被查询字段的分词策略统一,所以查询值无需指定分词策略,一定使用被查询字段的分词策略。operator表示匹配策略,缺省默认为or,表示多个字段中只有有一个匹配则整体匹配成功,另有可选值and,表示必须所有字段都必须匹配成功。
multi_match
复合模糊查询,同样支持多字段同时查询。
GET /索引名/_search{"query": {"multi_match": {"fields": ["字段1", "字段2"],"query": "查询值","type": "best_fields","operator": "or","analyzer": "ik_max_word"}}}
复合查询的本质是多个字段的match查询的并集。
与combined_fiedls功能相同,都是同时查询多个字段,但区别在于复合查询允许多个字段的数据类型、分词策略不一致,其次查询值也可以指定使用分词策略。
复合查询的fields中允许使用通配符,比如:*_name表示所有以_name结尾的字段
还可以对指定字段提升权重,提高文档的_score值,比如:"fields": ["author^3", "字段2"]
复合查询还可以指定查询类型type,默认为best_fields。type的作用是什么?
举个例子:假设查询一篇文章的title、subtitle两个字段,这两个字段中都包含我们需要查询的值,但title、subtitle的内容不一样,导致使用不同字段查询时的score不一样,那么ES就犯难了,在title中的score是0.8,在subtitle中的score是0.6,那这条文档到底使用哪个score作为文档的score?
best_fields是默认策略,表示使用匹配度最高的score作为文档的score。优点是靠前的文档匹配精准度度很高,缺点是靠后的文档匹配度低,排序不均匀。
most_fields是另一种策略,表示综合使用所有字段进行匹配查询,每一个字段的score都会参与到文档score的计算中,匹配到的字段越多,score也就越高。优点是排序均匀,缺点是匹配精准度高的文档不一定排序靠前。
range
范围查询
GET /索引名/_search{"query": {"range": {"映射字段名": {"匹配符": 值1,"匹配符2": 值2}}}}
对于数值型字段的查询,可以使用范围查询。匹配符可用值:gt大于、gte大于等于、lt小于、lte小于等于
例如:
GET /索引名/_search{"query": {"range": {"age": {"gt": 20,"lte": 30}}}}

若有收获,就点个赞吧
0 人点赞
