MongoDB
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写,旨在为web应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功最丰富,最像关系数据库的
RDBMS vs NoSQL
NoSQL
Not Only SQL,即“不仅仅是SQL”,泛指非关系型数据库
NoSQL的产生是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。例如谷歌或FaceBook每天为他们的而用户手机万亿比特的数据,这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展
特点
代表着不仅仅是SQL
没有声明性查询语句
没有预定义的模式
可以键值对存储、列存储、文档存储、图形存储的方式存储数据
最终一致性,而非ACID属性
非结构化和不可预知的数据
CAP定理
高性能、高可用和可伸缩性
RDBMS
即关系型数据库关系系统
特点
高度组织化、结构化数据
结构化查询语句,即SQL
数据和关系都存储在单独的表中
数据操作语言,数据定义语言
严格的一致性
基础事务
遵循ACID规则
MongoDB概念解析
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
MongoDB各个存储格式
文档
文档是一组键值对,即BSON。MongoDB的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是MongoDB非常突出的特点。
{"site":"www.runoob.com", "name":"菜鸟教程"}
需要注意的是:
- 文档中的键值对是有序的
- 文档中的值不仅可以是在双引号里面的字符串,还可以使其他几种数据类型,甚至可以是整个嵌入的文档
- MongoDB区分类型和大小写
- MongoDB的文档不能有重复的键
- 文档的键是字符串,除了少数例外情况,键可以使用任意UTF-8字符
BSON和JSON的区别
BSON是一种二进制形式的存储格式,采用了类似于C语言结构体的名称,对表示方法、支持内嵌的文档对象和数组对象,具有轻量性、可遍历性、高效性的特点,可以有效描述非结构化数据和结构化数据
虽然BSON和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型
集合
集合就是MongoDB文档组,类似于关系型数据库管理系统中的表格。集合存在于数据库中,且没有固定的结果,这意味着在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性
db.createCollection("mycoll", {capped:true, size:100000})
数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
MongoDB操作
进入MongoDB客户端后
创建并查看数据库
创建数据库使用命令use,此时创建数据库后并进入数据库中
use databaseName
使用show命令查看已创建的数据库,新创建的数据库,需先像其添加数据后才会显示
show dbs
删除数据库
先使用use命令切换到要删除的数据库,再执行下面的命令
db.dropDatabase()
创建并查看集合
db.createCollection(name, options)
name,指要创建的集合名
options,可选参数,指定有关内存大小及索引的选项,可以是如下参数:
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 布尔 | 3.2 之后不再支持该参数。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值,即字节数。 如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
在插入文档时,MongoDB首先检查固定集合的size字段,然后检查max字段
db.createCollection("mycol", { capped : true, autoIndexId : true, size :6142800, max : 10000 } )
也可通过插入的方式创建集合
db.mycol2.insert({"name" : "菜鸟教程"})
查看已创建的集合
show collections
删除集合
db.collection.drop()
collection,需是数据库中存在的集合名
插入文档
使用insert()或者save()方法向集合中插入文档
db.COLLECTION_NAME.insert(document)或db.COLLECTION_NAME.save(document)
db.col.insert({title: 'MongoDB 教程',description: 'MongoDB 是一个 Nosql 数据库',by: '菜鸟教程',url: 'http://www.runoob.com',tags: ['mongodb', 'database', 'NoSQL'],likes: 100})
然后可通过find()查看集合中已插入的文档信息,col为自己创建的集合名,如果没有,在insert的时候会自动创建
db.col.find()
也可通过变量的形式插入文档
先自定义变量
document=({title: 'MongoDB 教程',description: 'MongoDB 是一个 Nosql 数据库',by: '菜鸟教程',url: 'http://www.runoob.com',tags: ['mongodb', 'database', 'NoSQL'],likes: 100});
然后插入
db.col.insert(document)
insert()和save()的区别
save():如果_id主键存在,则更新数据;如果不存在,就插入数据。该方法新版中已废弃,可以使用db.collection.insetOne()或者db.collection.replaceOne()来代替
insert():若插入的数据主键已经存在,则会抛出异常,提示主键重复,不保存当前数据
db.collection.insertOne() 和 db.collection.insertMany()
这两方法是在3.2版本之后新增的
db.collection.insertOne() 用于想集合插入一个新文档
db.collection.insertOne(<document>,{writeConcern: <document>})
db.collection.insertMany()用于想集合插入一个多个文档
db.collection.insertMany([ <document 1> , <document 2>, ... ],{writeConcern: <document>,ordered: <boolean>})
参数说明:
document:要写入的文档
writeConcern:写入策略,默认为1,即要求确认写入操作,为0则不要求
ordered:指定是否按顺序写入,默认为true
更新文档
可通过update()和save()方法来更新集合中的文档
update()
用于更新以存在的文档
db.collection.update(<query>,<update>,{upsert: <boolean>,multi: <boolean>,writeConcern: <document>})
参数说明:
query:update的查询条件,类似sql update查新内where后面的条件
update:update的对象和一些更新的操作符(如inc等等),也可以理解为sql update查询内set后面的
upsert:可选,这个参数的意思是,如果不存在update的记录,是否插入objNew
multi:可选,MongoDB默认是false,只更新找到的第一条记录,如果为true,就把按条件查询出来多条记录全部更新
writeConcern:可选,抛出异常的级别
db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})
save()
通过传入的文档来替换已有文档,_id主键存在就更新,不存在就插入
db.collection.save(<document>,{writeConcern: <document>})
参数说明:
document:文档数据
writeConcern:可选,抛出异常的级别
db.col.save({"_id" : ObjectId("56064f89ade2f21f36b03136"),"title" : "MongoDB","description" : "MongoDB 是一个 Nosql 数据库","by" : "Runoob","url" : "http://www.runoob.com","tags" : ["mongodb","NoSQL"],"likes" : 110})
删除文档
可使用remove()方法来删除文档。在执行remove()方法前先执行find()命令来判断执行的条件是否正确,这是一个比较好的习惯
db.collection.remove(<query>,<justOne>)
2.6版本之后
db.collection.remove(<query>,{justOne: <boolean>,writeConcern: <document>})
参数说明:
query:可选,删除的文档的条件
justOne:可选,如果设为true或1,则只删除一个文档
writeConcern:可选,抛出异常的级别
db.col.remove({'title':'MongoDB 教程'})
查询文档
查询文档使用find()方法,会以非结构化的方式来显示所有文档
db.collection.find(query, projection)
参数说明:
query:可选,使用查询操作符指定查询条件
projection:可选,使用投影操作符指定返回的键。查询时返回文档中所有键值,只需要省略该参数即可
如果需要以易读的方式来读取数据,可以使用pretty()方法:
db.col.find().pretty()
where
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {<key>:<value>} |
db.col.find({"by":"菜鸟教程"}).pretty() |
where by = '菜鸟教程' |
| 小于 | {<key>:{$lt:<value>}} |
db.col.find({"likes":{$lt:50}}).pretty() |
where likes < 50 |
| 小于或等于 | {<key>:{$lte:<value>}} |
db.col.find({"likes":{$lte:50}}).pretty() |
where likes <= 50 |
| 大于 | {<key>:{$gt:<value>}} |
db.col.find({"likes":{$gt:50}}).pretty() |
where likes > 50 |
| 大于或等于 | {<key>:{$gte:<value>}} |
db.col.find({"likes":{$gte:50}}).pretty() |
where likes >= 50 |
| 不等于 | {<key>:{$ne:<value>}} |
db.col.find({"likes":{$ne:50}}).pretty() |
where likes != 50 |
and
可以传入多个键,每个键以逗号隔开,即常规sql的and条件
db.col.find({key1:value1, key2:value2}).pretty()
or
使用关键字$or
db.col.find({$or: [{key1: value1}, {key2:value2}]}).pretty()
and和or联合使用
db.col.find({"likes": {$gt:50}, $or: [{"by": "菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty()
条件操作符
条件操作符用于比较两个表达式并从MongoDB集合中获取数据
MongoDB中条件操作符有:
- (>) 大于 - $gt
- (<) 小于 - $lt
- (>=) 大于等于 - $gte
- (<= ) 小于等于 - $lte
db.col.find({likes : {$gt : 100}})
db.col.find({likes : {$lt :200, $gt : 100}})
$type
基于BSON类型来检索集合中匹配的数据类型,并返回结果
如果想获取 “col” 集合中 title 为 String 的数据,可以使用以下命令:
db.col.find({"title" : {$type : 2}})或db.col.find({"title" : {$type : 'string'}})
MongoDB中的数据类型有:
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃。 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
limit和skip方法
limit()接收一个数字参数,指定从mongodb读取的记录条数
db.COLLECTION_NAME.find().limit(NUMBER)
skip()也是接收一个数据参数,指定跳过的记录条数
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
排序
使用sort()方法对数据进行排序,sort方法可以通过参数指定排序的字段,并使用1和-1来指定排序的方式,其中1为升序,-1为降序
db.COLLECTION_NAME.find().sort({KEY:1})
索引
使用createIndex()方法来创建索引
db.collection.createIndex(keys, options)
createIndex() 接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
查看集合索引
db.col.getIndexes()
查看集合索引大小
db.col.totalIndexSize()
删除集合所有索引
db.col.dropIndexes()
删除集合指定索引
db.col.dropIndex("索引名称")
聚合
使用aggregate()方法,主要用于处理数据(诸如统计、平均值、求和等),并返回计算后的数据结果
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
下表展示了一些聚合的表达式:
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{ |
| $avg | 计算平均值 | db.mycol.aggregate([{ |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{ |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{ |
| $push | 将值加入一个数组中,不会判断是否有重复的值。 | db.mycol.aggregate([{ |
| $addToSet | 将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。 | db.mycol.aggregate([{ |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{ |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{ |
管道
管道在Unix和Linux一般用于将当前命令的输出结果作为下一个命令的参数
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作时可以重复的
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其他的文档。
聚合中管道的几个操作:
$project:修改输入文档的结构,可以同来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档
match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
$group:将集合中的文档分组,可用于统计结果
$sort:将输入文档排序后输出
$geoNear:输出接近某一地理位置的有序文档
实例
1、$project实例:查询的信息中只有_id,title,author三个字段,_id是默认包含的
db.article.aggregate({ $project : {title : 1 ,author : 1 ,}});# 不包含id值db.article.aggregate({ $project : {_id : 0 ,title : 1 ,author : 1}});
2.$match实例:获取分数大于70或等于90
的记录,然后将符合条件的记录送到下一阶段的$group管道操作符进行处理
db.articles.aggregate( [{ $match : { score : { $gt : 70, $lte : 90 } } },{ $group: { _id: null, count: { $sum: 1 } } }] );
3.$skip实例:前五个文档被过滤掉
db.article.aggregate({ $skip : 5 });
复制(副本集)
MongoDB复制是将数据同步在多个服务器的过程
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,并且可以保证数据的安全性,还允许从硬件故障和服务中断中恢复数据
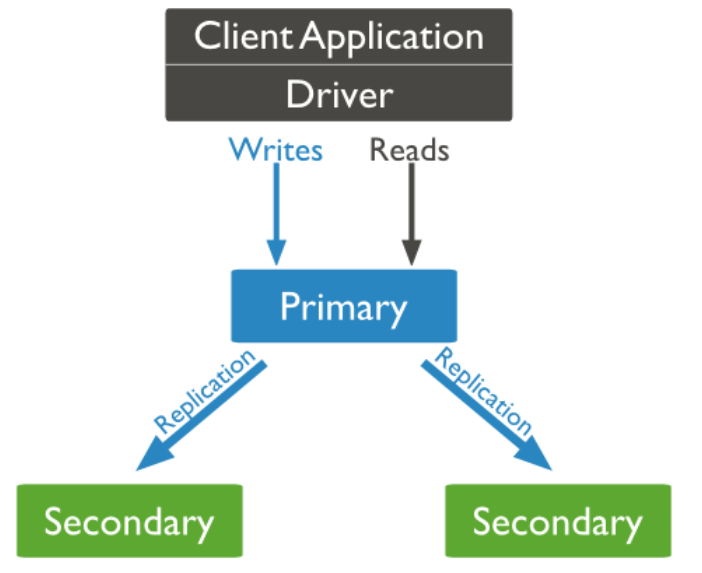
原理
MongoDB的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,复制复制主节点上的数据
主节点记录在其上的所有操作,即oplog日志,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致
设置
启动一个名为rs0的MongoDB实例,端口号为27017
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0
添加副本集成员,使用命令rs.initiate()来启动一个新的副本集,然后启动另外一台mongo实例,名为mongod1.net,端口号为27017
再然后在主节点使用rs.add()方法来添加副本集成员
rs.add("mongod1.net:27017")
最后可通过rs.conf()方法来查看副本集的配置,通过rs.status()方法查看副本集状态
可通过db.isMaster()方法来判断节点是否为主节点
MongoDB的副本集与常见的主从有所不同,主从在主机宕机后所有服务将停止,而MongoDB的副本集在主机宕机后,副本会接管主节点称为主节点,不会出现宕机的情况
分片
在MongoDB里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接收的读写吞吐量。这时,可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据
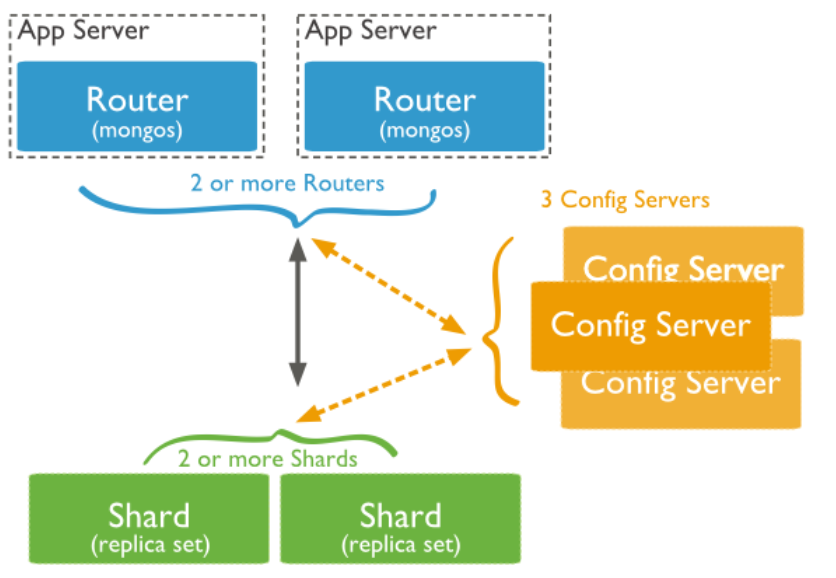
三个主要组件:
Shard:用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组成一个replica set承担,防止主机单点故障
Config Server:mongodb实例,存储了整个ClusterMetadata,其中包括chunk信息
Query Routers:前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用
为什么使用分片
复制所有的写入操作到主节点
延迟的敏感数据会在主节点查询
单个副本集限制在12个节点
当请求量巨大时会出现内存不足
本地磁盘不足
垂直扩展价格昂贵
分片实例
结构
Shard Server 1:27020Shard Server 2:27021Shard Server 3:27022Shard Server 4:27023Config Server :27100Route Process:40000
启动Shard Server
[root@100 /]# mkdir -p /www/mongoDB/shard/s0[root@100 /]# mkdir -p /www/mongoDB/shard/s1[root@100 /]# mkdir -p /www/mongoDB/shard/s2[root@100 /]# mkdir -p /www/mongoDB/shard/s3[root@100 /]# mkdir -p /www/mongoDB/shard/log[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27020 --dbpath=/www/mongoDB/shard/s0 --logpath=/www/mongoDB/shard/log/s0.log --logappend --fork....[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27023 --dbpath=/www/mongoDB/shard/s3 --logpath=/www/mongoDB/shard/log/s3.log --logappend --fork
启动Config Server
[root@100 /]# mkdir -p /www/mongoDB/shard/config[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27100 --dbpath=/www/mongoDB/shard/config --logpath=/www/mongoDB/shard/log/config.log --logappend --fork
启动Route Process
/usr/local/mongoDB/bin/mongos --port 40000 --configdb localhost:27100 --fork --logpath=/www/mongoDB/shard/log/route.log --chunkSize 500
chunkSize:指定chunk的大小,单位是MB,默认大小为200
配置Sharding
登录mongo,添加shard节点
[root@100 shard]# /usr/local/mongoDB/bin/mongo admin --port 40000MongoDB shell version: 2.0.7connecting to: 127.0.0.1:40000/adminmongos> db.runCommand({ addshard:"localhost:27020" }){ "shardAdded" : "shard0000", "ok" : 1 }......mongos> db.runCommand({ addshard:"localhost:27029" }){ "shardAdded" : "shard0009", "ok" : 1 }mongos> db.runCommand({ enablesharding:"test" }) #设置分片存储的数据库{ "ok" : 1 }mongos> db.runCommand({ shardcollection: "test.log", key: { id:1,time:1}}){ "collectionsharded" : "test.log", "ok" : 1 }
最后
程序代码内无需太大更改,直接按照连接普通的mongo数据库那样,将数据库连接接入接口40000
备份与恢复
使用mongodump命令来备份数据,该命令可以导出所有数据到指定目录中。也可以通过参数指定导出的数据量级转存的服务器
mongodump -h dbhost -d dbname -o dbdirectory
- -h:MongoDB 所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
- -d:需要备份的数据库实例,例如:test
- -o:备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。
使用mongorestore命令来恢复备份的数据
mongorestore -h <hostname><:port> -d dbname <path>
- —host <:port>, -h <:port>:MongoDB所在服务器地址,默认为: localhost:27017
- —db , -d :需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
- —drop:恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
- :mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:\data\dump\test。不能同时指定 和 —dir 选项,—dir也可以设置备份目录。
- —dir:指定备份的目录,不能同时指定 和 —dir 选项。
监控
MongoDB中提供了mongostat 和 mongotop 两个命令来监控MongoDB的运行情况。
MongoDB Java
原子操作
MongoDB不支持事务,无论什么设计,都不要要求MongoDB保证数据的完整性。但是MongoDB提供了许多原子操作,比如文档的保存、修改、删除等,都是原子操作。所谓的原子操作就是要么这个文档保存到MongoDB中,要么没保存到mongod中,不会出现查询到的文档没有保存完整的情况
Map Reduce
是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(reduce)
db.collection.mapReduce(function() {emit(key,value);}, //map 函数function(key,values) {return reduceFunction}, //reduce 函数{out: collection,query: document,sort: document,limit: number})
使用MapReduce要实现两个函数map和reduce,map函数调用emit(key,value),遍历collection中所有的记录,将key与value传递给reduce函数进行处理
参数说明:
map:映射函数,生成键值对序列,作为reduce函数的参数
reduce:统计函数,reduce函数的任务就是将key-values编程key-value,也就是把values数组变成一个额单一的值value
out:统计结果存放集合,不指定则使用临时集合,在客户端断开后自动删除
query:一个筛选条件,只有满足条件的文档才会调用map函数
sort:和limit结合的sort排序参数,也是在发往map函数前给文档排序,可以优化分组机制
limit:发往map函数的文档数量的上线。要是没有limit,单独使用sort的用处不大
现在,我们将在 posts 集合中使用 mapReduce 函数来选取已发布的文章(status:”active”),并通过user_name分组,计算每个用户的文章数:
>db.posts.mapReduce(function() { emit(this.user_name,1); },function(key, values) {return Array.sum(values)},{query:{status:"active"},out:"post_total"})
以上 mapReduce 输出结果为:
{"result" : "post_total","timeMillis" : 23,"counts" : {"input" : 5,"emit" : 5,"reduce" : 1,"output" : 2},"ok" : 1}

若有收获,就点个赞吧
0 人点赞
