java8新特性
Lambda表达式和函数式接口
Java8中引入了一个新的操作符“ -> ”,该操作符被称为箭头操作符或Lambda操作符,箭头操作符将Lambda表达式拆分成两部分:
- 左侧:Lambda表达式的参数列表
- 右侧:Lambda表达式中所需要执行的功能,即Lambda体
Lambda表达式(也称为闭包)是Java 8中最大和最令人期待的语言改变。它允许我们将函数当成参数传递给某个方法,或者把代码本身当作数据处理:函数式开发者非常熟悉这些概念。很多JVM平台上的语言(Groovy、Scala等)从诞生之日就支持Lambda表达式,但是Java开发者没有选择,只能使用匿名内部类代替Lambda表达式。
Lambda的设计耗费了很多时间和很大的社区力量,最终找到一种折中的实现方案,可以实现简洁而紧凑的语言结构。最简单的Lambda表达式可由逗号分隔的参数列表、->符号和语句块组成,例如:
Arrays.asList( "a", "b", "d" ).forEach( e -> System.out.println( e ) );
在上面这个代码中的参数e的类型是由编译器推理得出的,你也可以显式指定该参数的类型,例如:
Arrays.asList( "a", "b", "d" ).forEach( ( String e ) -> System.out.println( e ) );
如果Lambda表达式需要更复杂的语句块,则可以使用花括号将该语句块括起来,类似于Java中的函数体,例如:
Arrays.asList( "a", "b", "d" ).forEach( e -> {System.out.print( e );System.out.print( e );} );
Lambda表达式可以引用类成员和局部变量(会将这些变量隐式得转换成final的),例如下列两个代码块的效果完全相同:
String separator = ",";Arrays.asList( "a", "b", "d" ).forEach( ( String e ) -> System.out.print( e + separator ) );
和
final String separator = ",";Arrays.asList( "a", "b", "d" ).forEach( ( String e ) -> System.out.print( e + separator ) );
Lambda表达式有返回值,返回值的类型也由编译器推理得出。如果Lambda表达式中的语句块只有一行,则可以不用使用return语句,下列两个代码片段效果相同:
Arrays.asList( "a", "b", "d" ).sort( ( e1, e2 ) -> e1.compareTo( e2 ) );
和
Arrays.asList( "a", "b", "d" ).sort( ( e1, e2 ) -> {int result = e1.compareTo( e2 );return result;} );
Lambda的设计者们为了让现有的功能与Lambda表达式良好兼容,考虑了很多方法,于是产生了函数接口这个概念。函数接口指的是只有一个函数的接口,这样的接口可以隐式转换为Lambda表达式。java.lang.Runnable和java.util.concurrent.Callable是函数式接口的最佳例子。在实践中,函数式接口非常脆弱:只要某个开发者在该接口中添加一个函数,则该接口就不再是函数式接口进而导致编译失败。为了克服这种代码层面的脆弱性,并显式说明某个接口是函数式接口,Java 8 提供了一个特殊的注解@FunctionalInterface (Java 库中的所有相关接口都已经带有这个注解了),举个简单的函数式接口的定义:
@FunctionalInterfacepublic interface Functional {void method();}
不过有一点需要注意,默认方法和静态方法不会破坏函数式接口的定义,因此如下的代码是合法的。
@FunctionalInterfacepublic interface FunctionalDefaultMethods {void method();default void defaultMethod() {}}
Lambda表达式作为Java 8的最大卖点,它有潜力吸引更多的开发者加入到JVM平台,并在纯Java编程中使用函数式编程的概念。如果你需要了解更多Lambda表达式的细节,可以参考官方文档。
接口的默认方法和静态方法
Java 8使用两个新概念扩展了接口的含义:默认方法和静态方法。默认方法使得接口有点类似traits,不过要实现的目标不一样。默认方法使得开发者可以在 不破坏二进制兼容性的前提下,往现存接口中添加新的方法,即不强制那些实现了该接口的类也同时实现这个新加的方法。
默认方法和抽象方法之间的区别在于抽象方法需要实现,而默认方法不需要。接口提供的默认方法会被接口的实现类继承或者覆写,例子代码如下:
private interface Defaulable {// Interfaces now allow default methods, the implementer may or// may not implement (override) them.default String notRequired() {return "Default implementation";}}private static class DefaultableImpl implements Defaulable {}private static class OverridableImpl implements Defaulable {@Overridepublic String notRequired() {return "Overridden implementation";}}
Defaulable接口使用关键字default定义了一个默认方法notRequired()。DefaultableImpl类实现了这个接口,同时默认继承了这个接口中的默认方法;OverridableImpl类也实现了这个接口,但覆写了该接口的默认方法,并提供了一个不同的实现。
Java 8带来的另一个有趣的特性是在接口中可以定义静态方法,例子代码如下:
private interface DefaulableFactory {// Interfaces now allow static methodsstatic Defaulable create( Supplier< Defaulable > supplier ) {return supplier.get();}}
下面的代码片段整合了默认方法和静态方法的使用场景:
public static void main( String[] args ) {Defaulable defaulable = DefaulableFactory.create( DefaultableImpl::new );System.out.println( defaulable.notRequired() );defaulable = DefaulableFactory.create( OverridableImpl::new );System.out.println( defaulable.notRequired() );}
这段代码的输出结果如下:
Default implementationOverridden implementation
由于JVM上的默认方法的实现在字节码层面提供了支持,因此效率非常高。默认方法允许在不打破现有继承体系的基础上改进接口。该特性在官方库中的应用是:给java.util.Collection接口添加新方法,如stream()、parallelStream()、forEach()和removeIf()等等。
尽管默认方法有这么多好处,但在实际开发中应该谨慎使用:在复杂的继承体系中,默认方法可能引起歧义和编译错误。如果你想了解更多细节,可以参考官方文档。
方法引用
方法引用使得开发者可以直接引用现存的方法、Java类的构造方法或者实例对象。方法引用和Lambda表达式配合使用,使得java类的构造方法看起来紧凑而简洁,没有很多复杂的模板代码。
西门的例子中,Car类是不同方法引用的例子,可以帮助读者区分四种类型的方法引用。
public static class Car {public static Car create( final Supplier< Car > supplier ) {return supplier.get();}public static void collide( final Car car ) {System.out.println( "Collided " + car.toString() );}public void follow( final Car another ) {System.out.println( "Following the " + another.toString() );}public void repair() {System.out.println( "Repaired " + this.toString() );}}
第一种方法引用的类型是构造器引用,语法是Class::new,或者更一般的形式:Class::new。注意:这个构造器没有参数。
final Car car = Car.create( Car::new );final List< Car > cars = Arrays.asList( car );
第二种方法引用的类型是静态方法引用,语法是Class::static_method。注意:这个方法接受一个Car类型的参数。
cars.forEach( Car::collide );
第三种方法引用的类型是某个类的成员方法的引用,语法是Class::method,注意,这个方法没有定义入参:
cars.forEach( Car::repair );
第四种方法引用的类型是某个实例对象的成员方法的引用,语法是instance::method。注意:这个方法接受一个Car类型的参数:
final Car police = Car.create( Car::new );cars.forEach( police::follow );
运行上述例子,可以在控制台看到如下输出(Car实例可能不同):
Collided com.javacodegeeks.java8.method.references.MethodReferences$Car@7a81197dRepaired com.javacodegeeks.java8.method.references.MethodReferences$Car@7a81197dFollowing the com.javacodegeeks.java8.method.references.MethodReferences$Car@7a81197d
如果想了解和学习更详细的内容,可以参考官方文档
重复注解
自从Java 5中引入注解以来,这个特性开始变得非常流行,并在各个框架和项目中被广泛使用。不过,注解有一个很大的限制是:在同一个地方不能多次使用同一个注解。Java 8打破了这个限制,引入了重复注解的概念,允许在同一个地方多次使用同一个注解。
在Java 8中使用@Repeatable 注解定义重复注解,实际上,这并不是语言层面的改进,而是编译器做的一个trick,底层的技术仍然相同。可以利用下面的代码说明:
package com.javacodegeeks.java8.repeatable.annotations;import java.lang.annotation.ElementType;import java.lang.annotation.Repeatable;import java.lang.annotation.Retention;import java.lang.annotation.RetentionPolicy;import java.lang.annotation.Target;public class RepeatingAnnotations {@Target( ElementType.TYPE )@Retention( RetentionPolicy.RUNTIME )public @interface Filters {Filter[] value();}@Target( ElementType.TYPE )@Retention( RetentionPolicy.RUNTIME )@Repeatable( Filters.class )public @interface Filter {String value();};@Filter( "filter1" )@Filter( "filter2" )public interface Filterable {}public static void main(String[] args) {for( Filter filter: Filterable.class.getAnnotationsByType( Filter.class ) ) {System.out.println( filter.value() );}}}
正如我们所见,这里的Filter类使用@Repeatable(Filters.class)注解修饰,而Filters是存放Filter注解的容器,编译器尽量对开发者屏蔽这些细节。这样,Filterable接口可以用两个Filter注解注释(这里并没有提到任何关于Filters的信息)。
另外,反射API提供了一个新的方法:getAnnotationsByType(),可以返回某个类型的重复注解,例如Filterable.class.getAnnoation(Filters.class)将返回两个Filter实例,输出到控制台的内容如下所示:
filter1filter2
如果你希望了解更多内容,可以参考官方文档。
更好的类型推断
Java 8编译器在类型推断方面有很大的提升,在很多场景下编译器可以推导出某个参数的数据类型,从而使得代码更为简洁。例子代码如下:
package com.javacodegeeks.java8.type.inference;public class Value< T > {public static< T > T defaultValue() {return null;}public T getOrDefault( T value, T defaultValue ) {return ( value != null ) ? value : defaultValue;}}
下列代码是Value类型的应用:
package com.javacodegeeks.java8.type.inference;public class TypeInference {public static void main(String[] args) {final Value< String > value = new Value<>();value.getOrDefault( "22", Value.defaultValue() );}}
参数Value.defaultValue()的类型由编译器推导得出,不需要显式指明。在Java 7中这段代码会有编译错误,除非使用Value.<String>defaultValue()。
拓宽注解的应用场景
Java 8拓宽了注解的应用场景。现在,注解几乎可以使用在任何元素上:局部变量、接口类型、超类和接口实现类,甚至可以用在函数的异常定义上。下面是一些例子:
package com.javacodegeeks.java8.annotations;import java.lang.annotation.ElementType;import java.lang.annotation.Retention;import java.lang.annotation.RetentionPolicy;import java.lang.annotation.Target;import java.util.ArrayList;import java.util.Collection;public class Annotations {@Retention( RetentionPolicy.RUNTIME )@Target( { ElementType.TYPE_USE, ElementType.TYPE_PARAMETER } )public @interface NonEmpty {}public static class Holder< @NonEmpty T > extends @NonEmpty Object {public void method() throws @NonEmpty Exception {}}@SuppressWarnings( "unused" )public static void main(String[] args) {final Holder< String > holder = new @NonEmpty Holder< String >();@NonEmpty Collection< @NonEmpty String > strings = new ArrayList<>();}}
ElementType.TYPE_USER和ElementType.TYPE_PARAMETER是Java 8新增的两个注解,用于描述注解的使用场景。Java 语言也做了对应的改变,以识别这些新增的注解。
新的日期和时间API
java.time
通过local来表示一个国家或地区的日期、时间、数字、货币等格式
特点
- 严格区分日期、时间
- 不变类,类似String
- Month范围
- Week范围
LocalDateTime
LocalDate d = LocalDate.now(); // 当前日期LocalTime t = LocalTime.now(); //当前时间LocalDateTime dt = LocalDateTime.now(); // 当前日期时间System.out.println(dt); // 严格按照ISO 8601格式打印 2020-07-05T16:38:37.356//指定日期和时间LocalDate d2 = LocalDate.of(2020, 7, 5); // 2020-07-05,注意 7=7月LocalTime t2 = LocalTime.of(16, 38, 37); // 16:38:37LocalDateTime dt2 = LocalDateTime.of(2020, 7, 5,16, 38, 37); // 2020-07-05T16:38:37LocalDateTime dt3 = LocalDateTime.of(d2, t2); // 2020-07-05T16:38:37//对日期进行格式化aDateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");System.out.println(dtf.format(LocalDateTime.now())); // 2020-07-05 16:45:08//将字符串解析成日期LocalDateTime parse = LocalDateTime.parse("2020-07-05 16:45:08", dtf);System.out.println(parse); // 2020-07-05T16:45:08// +5 天LocalDate today = LocalDate.now();LocalDate after5Days = today.plusDays(5);System.out.println(after5Days); //2020-07-10// -2小时LocalTime now = LocalTime.now();LocalTime before2Hours = now.minusHours(2);System.out.println(before2Hours); // 14:59:22.526// +1月-2周LocalDate date = today.plusMonths(1).minusWeeks(2);System.out.println(date); // 2020-07-22//本月第一天LocalDate firstDay = LocalDate.now().withDayOfMonth(1);System.out.println(firstDay); // 2020-07-01//把秒和纳秒调整为0LocalTime at = LocalTime.now().withSecond(0).withNano(0);System.out.println(at); // 17:08//本月最后一天LocalDate lastDay = LocalDate.now().with(TemporalAdjusters.lastDayOfMonth());System.out.println(lastDay); // 2020-07-31//本月第一个周日LocalDate firstSunday = LocalDate.now().with(TemporalAdjusters.firstInMonth(DayOfWeek.SUNDAY));System.out.println(firstSunday); //2020-07-05LocalDate d01 = LocalDate.of(2020,7,5);LocalDate d02 = LocalDate.of(2020,7,4);System.out.println(d01.isBefore(d02)); // falseSystem.out.println(d01.isAfter(d02)); // trueLocalDate d03 = LocalDate.of(2020,7,5);LocalDate d04 = LocalDate.of(2018,3,28);//通过until()方法获取Period对象,判断两个日期相差?年?月?天Period period = d03.until(d04);System.out.println(period); // P-2Y-3M-8D 表示2020年7月5日到2018年3月28日中相差 2年3个月8天//两个日期一共相差多少天?long day01 = LocalDate.of(2020, 7, 5).toEpochDay();long day02 = LocalDate.of(2018,3,28).toEpochDay();System.out.println(day01-day02); // 830
ZonedDateTime
Stream API
Stream使用一种类似用SQL语句从数据库查询数据的直观方式来提供一种对java集合运算和表达的高阶抽象。这种风格将要处理的元素集合看作一种流,流在管道中传输,并且可以在管道的节点上进行处理,比如筛选、排序、聚合等。元素流在管道中进过中间操作的处理,最后又最终操作得到前面处理的结果。
注意
Stream自己不会存储元素
Stream不会改变源对象,相反,它们会返回一个持有结果的新Stream
Stream操作时延迟执行的,这意味着他们回等到需要结果的时候执行
步骤
创建Stream:一个数据源(如数组、集合等),获取一个流
//创建Stream@Testpublic void test01(){//1.可以通过Collection系列集合提供的stream() 或 parallelStream()List<String> list = new ArrayList();Stream<String> stream01 = list.stream();//2、通过Arrays中的静态方法stream() 获取数组流Emp[] emps = new Emp[10];Stream<Emp> stream02 = Arrays.stream(emps);//3.通过Stream类中的静态方法of()Stream<String> stream03 = Stream.of("aa","bb","cc");//4.创建无限流//迭代Stream<Integer> stream04 = Stream.iterate(0,(x) -> x+2);stream04.forEach(System.out::println);//只要10个数据stream04.limit(10).forEach(System.out::println);//生成5个随机数Stream.generate(() -> Math.random()).limit(5).forEach(System.out::println);}
中间操作:一个中间操作链,对数据源的数据进行处理
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理。而在终止操作时一次性全部处理,称为惰性求值筛选与切片:filter,接收lambda,从流中排除某些元素limit,截断流,使其元素不超过给定数量skip(n),跳过元素,返回一个扔掉了前n个元素的流,若六中元素不足n个,则返回一个空流,与limit(n)互补distinct,筛选,通过流所生成元素的hashcode()和equals()去重映射:map,接收lambda,将元素转换为其他形式或提取信息(接收一个函数作为参数,该函数被应用到每个元素上,并将其映射成一个新的元素)flatMap,接收一个函数作为参数,将流中的每个值都换成另外一个流,然后把所有的流连凑成一个流排序:sorted,自然排序sorted(Comparator comparator),定制排序
下面通过代码来练习这些中间操作,先创建一个Employee实体类:
public class Employee {private String name;private Integer age;private Double salary;public Employee(String name, Integer age, Double salary) {this.name = name;this.age = age;this.salary = salary;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public Double getSalary() {return salary;}public void setSalary(Double salary) {this.salary = salary;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Employee employee = (Employee) o;return Objects.equals(name, employee.name) &&Objects.equals(age, employee.age) &&Objects.equals(salary, employee.salary);}@Overridepublic int hashCode() {return Objects.hash(name, age, salary);}@Overridepublic String toString() {return "Employee{" +"name='" + name + '\'' +", age=" + age +", salary=" + salary +'}';}}
测试中间操作filter的用法:
List<Employee> emps = Arrays.asList(new Employee("张三",21,4500.00),new Employee("李四",25,6000.00),new Employee("王五",56,3500.00),new Employee("王五",56,3500.00),new Employee("田七",30,8000.00),new Employee("田七",30,8000.00));@Testpublic void test02(){//中间操作:不会执行任何操作Stream<Employee> stream = employeeList.stream().filter(e -> e.getAge()>25);//终止操作:一次型执行全部内容,即”惰性求值“//内部迭代:迭代操作由Stream API 完成stream.forEach(System.out::println);}//外部迭代@Testpublic void test03(){Iterator<Employee> it = emps.iterator();while(it.hasNext()){System.out.println(it.next());}}
中间操作:limit —只要找到符合条件的指定条数数据,就不会执行后面的数据过滤操作了,可以提高效率
@Testpublic void test04(){emps.stream().filter(e -> e.getSalary()>3000.00).limit(2) //短路 : 只要找到符合条件的两条数据,就不会执行后面的数据过滤操作了,可以提高效率.forEach(System.out::println);}
中间操作:skip(n) ——跳过n个元素,返回一个扔掉了前n个元素的流,若流中元素不足n个,则返回一个空流,与limit(n)互补
@Testpublic void test05(){emps.stream().filter(e -> e.getSalary()>3000.00).skip(2).forEach(System.out::println);}
中间操作: distinct —— 筛选,通过流所生成元素的hashCode() 和 equals() 去除重复元素
@Testpublic void test06(){emps.stream().filter(e -> e.getSalary()>3000.00).distinct ().forEach(System.out::println);}
中间操作: map ——— 接受一个函数作为参数,该函数或被应用到每个元素上,并将其映射成一个新的元素
@Testpublic void test07(){List<String> list = Arrays.asList("aaa","bbb","ccc","ddd","hello");list.stream()//toUpperCase()函数被应用到流中每个元素上,并将其映射成一个新的元素.map((str) -> str.toUpperCase()).forEach(System.out::println); //输出结果:AAA BBB CCC DDD HELLOSystem.out.println("------------------------------");emps.stream().map(Employee::getName).forEach(System.out::println);//输出结果:张三 李四 王五 王五 田七 田七System.out.println("------------------------------");Stream<Stream<Character>> stream01 = list.stream()//调用filterCharacter(),将流中的字符串元素都转为字符流,返回值类型为Stream<Stream<Character>>.map(StreamApiTest::filterCharacter);stream01.forEach((sm) -> {sm.forEach(System.out::println);});System.out.println("------------------------------");}//字符串转为字符流public static Stream<Character> filterCharacter(String str){List<Character> list = new ArrayList<>();for(Character ch : str.toCharArray()){list.add(ch);}return list.stream();}
中间操作: flatMap —- 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有的流连凑成一个流
@Testpublic void test08(){List<String> list = Arrays.asList("aaa","bbb","ccc","ddd","hello");Stream<Character> stream02 = list.stream()//调用filterCharacter(),将流中的字符串元素都转为字符流,并将这些流加入到一个新流中,返回值类型为Stream<Character>.flatMap(StreamApiTest::filterCharacter);stream02.forEach(System.out::println);}
中间操作: sorted() —— 自然排序
@Testpublic void test09(){List<String> list = Arrays.asList("ccc","aaa","ddd","bbb","eee");list.stream().sorted().forEach(System.out::println);}
中间操作: sorted(Comparator comparator) ——— 定制排序(Comparator )
自定义排序规则,这个根据员工年龄排序,若员工年龄相同,则根据员工姓名排序 —- 升序
@Testpublic void test10(){emps.stream().sorted((e1,e2) -> {if(e1.getAge().equals(e2.getAge())){return e1.getName().compareTo(e2.getName());}else{return e1.getAge().compareTo(e2.getAge());}}).forEach(System.out::println);}
终止操作:一个终止操作,执行中间操作链,并产生结果
查找与匹配:allMatch,检查是否匹配所有元素anyMatch,检查是否至少匹配一个元素noneMatch,检查是否至少匹配一个元素findFirst,返回第一个元素findAny,返回流中的任意元素count,返回六中元素的总个数max,返回流中的最大值min,返回流中的最小值归约:可以将流中元素反复结合起来,得到一个值reduce(T indentity,BinaryOperator bin),indentity为起始值reduce(BinaryOperator bin)收集:collect,将流装换为其他形式,接收一个Collector接口的实现,用于给Stream中元素汇总的方法
终止操作练习:在此之前,我们先创建一个员工实体类,方便测试效果
public class Employee {private String name;private Integer age;private Double salary;private Status status;public Employee(String name, Integer age, Double salary) {this.name = name;this.age = age;this.salary = salary;}public Employee(String name, Integer age, Double salary, Status status) {this.name = name;this.age = age;this.salary = salary;this.status = status;}public Status getStatus() {return status;}public void setStatus(Status status) {this.status = status;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public Double getSalary() {return salary;}public void setSalary(Double salary) {this.salary = salary;}@Overridepublic String toString() {return "Employee{" +"name='" + name + '\'' +", age=" + age +", salary=" + salary +", status=" + status +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (!(o instanceof Employee)) return false;Employee employee = (Employee) o;return Objects.equals(getName(), employee.getName()) &&Objects.equals(getAge(), employee.getAge()) &&Objects.equals(getSalary(), employee.getSalary()) &&getStatus() == employee.getStatus();}@Overridepublic int hashCode() {return Objects.hash(getName(), getAge(), getSalary(), getStatus());}public enum Status{BUSY,FREE,VACATION;}}
接下来我们先对 查找与匹配 中的几个终止操作进行代码测试:
List<Employee> employees = Arrays.asList(new Employee("张三",21,4500.00, Employee.Status.BUSY),new Employee("李四",25,6000.00,Employee.Status.VACTION),new Employee("王五",56,3500.00,Employee.Status.BUSY),new Employee("王五",56,3500.00,Employee.Status.BUSY),new Employee("田七",30,8000.00,Employee.Status.FREE),new Employee("田七",30,8000.00,Employee.Status.FREE));@Testpublic void test11(){//allMatch ----- 检查是否匹配所有元素boolean b1 = employees.stream().allMatch((e) -> e.getStatus().equals(Employee.Status.FREE));System.out.println(b1); //输出结果: false//anyMatch ------ 检查是否至少匹配一个元素boolean b2 = employees.stream().anyMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));System.out.println(b2); //输出结果: true//noneMatch --------- 检查是否没有匹配所有元素boolean b3 = employees.stream().noneMatch((e) -> e.getStatus().equals(Employee.Status.BUSY));System.out.println(b3); //输出结果: false//findFirst ------- 返回第一个元素//Optional --- 是Java8 提供的处理空指针异常的类Optional<Employee> employee = employees.stream()//按员工的薪资排序.sorted((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary()))//获取第一个员工信息,即薪资最新的员工信息.findFirst();System.out.println(employee.get());//findAny -------- 返回流中的任意元素//parallelStream --- 获取并行流Optional<Employee> any = employees.parallelStream()//获取状态为 FREE 的任意一个员工信息.filter(e -> e.getStatus().equals(Employee.Status.FREE)).findAny();System.out.println(any.get());}
测试终止操作中,count,max,min的运用
@Testpublic void test12(){//返回流中元素的总个数long count = employees.stream().count();System.out.println(count); //输出结果为:6Optional<Employee> max = employees.stream().//获取年龄最大的员工信息max((e1, e2) -> Integer.compare(e1.getAge(), e2.getAge()));System.out.println(max.get()); // 输出结果为:Employee{name='王五', age=56, salary=3500.0, status=BUSY}Optional<Double> min = employees.stream().map((e) -> e.getSalary())//获取最低的薪资.min(Double::compare);System.out.println(min.get());//输出结果为:3500.0}
终止操作:归约 —— reduce(T indentity,BinaryOperator) / reduce(BinaryOperator),可以将流中元素反复结合起来,得到一个值
@Testpublic void test13(){List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);Integer reduce = list.stream()//0为初始值,将流中的元素按照 lambda体中的方式进行汇总,这里即是通过求和的方式汇总.reduce(0, (x, y) -> x + y);System.out.println(reduce); // 输出结果为:55Optional<Double> sum = employees.stream()//获取员工的薪资信息.map((e) -> e.getSalary())//调用Double的sum(),对员工薪资进行求和.reduce(Double::sum);System.out.println(sum.get()); //输出结果为:33500.0}
终止操作:收集:collect ———- 将流装换为其它形式,接收一个Collector 接口的实现,用于给Stream中元素汇总的方法
@Testpublic void test14(){//Collectors工具类对Collector接口提供了很多实现List<String> list = employees.stream().map(e -> e.getName()).collect(Collectors.toList());System.out.println(list);//输出结果为:[张三, 李四, 王五, 王五, 田七, 田七]Set<Integer> set = employees.stream().map(e -> e.getAge()).collect(Collectors.toSet());System.out.println(set);//输出结果为:[21, 56, 25, 30]HashSet<String> hashSet = employees.stream().map(e -> e.getName()).collect(Collectors.toCollection(HashSet::new));System.out.println(hashSet);//输出结果为:[李四, 张三, 王五, 田七]}
因为collect收集使用是很常见的,接下来我们通过使用collect进行统计、求平均值、总和、最大值、最小值,更加熟悉collect的使用,并了解工具类Collectors中常用的方法
@Testpublic void test15(){//总数Long count = employees.stream().collect(Collectors.counting());System.out.println(count); // 输出结果为:6//获取员工薪资的平均值Double avgSalary = employees.stream().collect(Collectors.averagingDouble(Employee::getSalary));System.out.println(avgSalary);// 输出结果为:5583.333333333333//获取员工薪资的总和Double total = employees.stream().collect(Collectors.summingDouble(Employee::getSalary));System.out.println(total); // 输出结果为:33500.0//获取最高薪资的员工信息Optional<Employee> maxSalary = employees.stream().collect(Collectors.maxBy((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())));System.out.println(maxSalary.get()); //输出结果为:Employee{name='田七', age=30, salary=8000.0, status=FREE}//获取最低薪资的员工信息Optional<Employee> minSalary = employees.stream().collect(Collectors.minBy((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())));System.out.println(minSalary.get()); //输出结果为:Employee{name='王五', age=56, salary=3500.0, status=BUSY}}
通过使用collect,对流中元素进行分组、多级分组、分区操作。
@Testpublic void test16(){//通过员工状态进行分组Map<Employee.Status, List<Employee>> statusListMap = employees.stream().collect(Collectors.groupingBy(Employee::getStatus));System.out.println(statusListMap);}/*** 多级分组*/@Testpublic void test17(){//通过员工状态进行分组Map<Employee.Status, Map<String, List<Employee>>> map = employees.stream().collect(Collectors.groupingBy(Employee::getStatus, Collectors.groupingBy(e -> {if (e.getAge() < 30) {return "青年";} else if (e.getAge() < 50) {return "中年";} else {return "老年";}})));System.out.println(map);}/*** 分区*/@Testpublic void test18(){Map<Boolean, List<Employee>> map = employees.stream().collect(Collectors.partitioningBy(e -> e.getSalary() > 6000));System.out.println(map);}/*** 将流中的元素,按照指定格式连接*/@Testpublic void test19(){String str = employees.stream().map(e -> e.getName()).collect(Collectors.joining(","));System.out.println(str); //输出结果为: 张三,李四,王五,王五,田七,田七}
并行流与顺序流
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。java8中将并行流进行了优化,可以很容易的对数据进行并行操作。Stream API可以声明性地通过Paralle()与Sequential()在并行流与顺序流之间进行切换
以下实例我们使用 parallelStream 来输出空字符串的数量:
@Testpublic void test20(){List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");// 获取空字符串的数量long count = strings.parallelStream().filter(string -> string.isEmpty()).count();System.out.println(count); //输出结果为:2}
应用
Java8中的Stream API可以极大提高我们的的生产力,让我们写出高效率、干净、简洁的代码。
例如:使用Java8来求两个集合的交集、差集、并集
@Testpublic void test(){//准备两个集合List<String> list1 = new ArrayList<String>();list1.add("aa");list1.add("bb");list1.add("cc");list1.add("dd");list1.add("ee");List<String> list2 = new ArrayList<String>();list2.add("bb");list2.add("cc");list2.add("ff");list2.add("gg");// 交集List<String> intersection = list1.stream().filter(item -> list2.contains(item)).collect(toList());System.out.println("---交集 intersection---");intersection.parallelStream().forEach(System.out :: println);// 差集List<String> reduce = list2.stream().filter(item -> !list1.contains(item)).collect(toList());System.out.println("---差集 reduce2 (list2 - list1)---");reduce.parallelStream().forEach(System.out :: println);//并集list1.addAll(list2);List<String> collect = list1.stream().distinct().collect(toList());System.out.println("并集----去重");collect.stream().forEach(System.out::println);}
Java编译器的新特性
参数名称
为了在运行时获得Java程序中方法的参数名称,老一辈的Java程序员必须使用不同方法,例如Paranamer liberary。Java 8终于将这个特性规范化,在语言层面(使用反射API和Parameter.getName()方法)和字节码层面(使用新的javac编译器以及-parameters参数)提供支持。
package com.javacodegeeks.java8.parameter.names;import java.lang.reflect.Method;import java.lang.reflect.Parameter;public class ParameterNames {public static void main(String[] args) throws Exception {Method method = ParameterNames.class.getMethod( "main", String[].class );for( final Parameter parameter: method.getParameters() ) {System.out.println( "Parameter: " + parameter.getName() );}}}
在Java 8中这个特性是默认关闭的,因此如果不带-parameters参数编译上述代码并运行,则会输出如下结果:
Parameter: arg0
如果带-parameters参数,则会输出如下结果(正确的结果):
Parameter: args
如果你使用Maven进行项目管理,则可以在maven-compiler-plugin编译器的配置项中配置-parameters参数:
<plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><compilerArgument>-parameters</compilerArgument><source>1.8</source><target>1.8</target></configuration></plugin>
动态代理和静态代理
动态代理
我们大家都知道微商代理,简单地说就是代替厂家卖商品,厂家“委托”代理为其销售商品。把微商代理和厂家进一步抽象,前者可抽象为代理类,后者可抽象为委托类(被代理类)
通过使用代理,通常有两个优点,并且能够分别与我们提到的微商代理的两个特点对应起来:优点一:可以隐藏委托类(工厂)的实现;——-(关于微商代理,首先我们从他们那里买东西时通常不知道背后的厂家究竟是谁,也就是说,“委托者”对我们来说是不可见的)优点二:可以实现客户与委托类间的解耦,在不修改委托类代码的情况下能够做一些额外的处理。
概念
代理类在程序运行时创建的代理方式被成为 动态代理。 也就是说,这种情况下,代理类并不是在Java代码中定义的,而是在运行时根据我们在Java代码中的“指示”动态生成的。相比于静态代理, 动态代理的优势在于可以很方便的对代理类的函数进行统一的处理,而不用修改每个代理类的函数。
动态代理实现
使用 动态代理 来完成 执行委托类中的方法之前输出“before”,在执行完毕后输出“after”。
(1)InvocationHandler接口在使用动态代理时,我们需要定义一个位于代理类与委托类之间的中介类,这个中介类被要求实现InvocationHandler接口,这个接口的定义如下:
public interface InvocationHandler {Object invoke(Object proxy, Method method, Object[] args);}
从InvocationHandler这个名称我们就可以知道,实现了这个接口的中介类,用做“调用处理器”。当我们调用代理类对象的方法时,这个“调用”会转送到invoke方法中,代理类对象作为proxy参数传入,参数method标识了我们具体调用的是代理类的哪个方法,args为这个方法的参数。这样一来,我们对代理类中的所有方法的调用都会变为对invoke的调用,这样我们可以在invoke方法中添加统一的处理逻辑(也可以根据method参数对不同的代理类方法做不同的处理)。因此我们只需在中介类的invoke方法实现中输出“before”,然后调用委托类的invoke方法,再输出“after”。下面我们来一步一步具体实现它。
(2)委托类的定义动态代理方式下,要求委托类必须实现某个接口,这里我们实现的是Sell接口。委托类Vendor类的定义如下:
public class Vendor implements Sell{public void sell(){System.out.println("In sell method");}public void ad(){System,out.println("ad method")}}
(3)中介类上面我们提到过,中介类必须实现InvocationHandler接口,作为调用处理器”拦截“对代理类方法的调用。中介类的定义如下:
public class DynamicProxy implements InvocationHandler{private Object obj; //obj为委托类对象;public DynamicProxy(Object obj){this.obj = obj;}@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable{System.out.println("before");//在invoke方法中添加统一的处理逻辑(也可以根据method参数对不同的代理类方法做不同的处理)Object result = method.invoke(obj, args);System.out.println("after");return result;}}
从以上代码中我们可以看到,中介类持有一个委托类对象引用,在invoke方法中调用了委托类对象的相应方法(第11行),看到这里是不是觉得似曾相识?通过聚合方式持有委托类对象引用,把外部对invoke的调用最终都转为对委托类对象的调用。这不就是我们上面介绍的静态代理的一种实现方式吗?实际上,中介类与委托类构成了静态代理关系,在这个关系中,中介类是代理类,委托类就是委托类; 代理类与中介类也构成一个静态代理关系,在这个关系中,中介类是委托类,代理类是代理类。也就是说,动态代理关系由两组静态代理关系组成,这就是动态代理的原理。下面我们来介绍一下如何”指示“以动态生成代理类。
(4)动态生成代理类动态生成代理类的相关代码如下:
public class Main {public static void main(String[] args){//创建中介类实例DynamicProxy inter = new DynamicProxy(new Vendor());//加上这句将会产生一个$Proxy0.class文件,这个文件即为动态生成的代理类文件System.getProperties().put("sun.misc.ProxyGenerator.saveGeneratedFiles","true");//获取代理类实例sellSell sell = (Sell)(Proxy.newProxyInstance(Sell.class.getClassLoader(), new Class[] {Sell.class}, inter));//通过代理类对象调用代理类方法,实际上会转到invoke方法调用sell.sell();sell.ad();}}
在以上代码中,我们调用Proxy类的newProxyInstance方法来获取一个代理类实例。这个代理类实现了我们指定的接口并且会把方法调用分发到指定的调用处理器。这个方法的声明如下
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h) throws IllegalArgumentException
方法的三个参数含义分别如下:loader:定义了代理类的ClassLoder;interfaces:代理类实现的接口列表h:调用处理器,也就是我们上面定义的实现了InvocationHandler接口的类实例我们运行一下,看看我们的动态代理是否能正常工作。我这里运行后的输出为: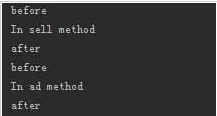
说明我们的动态代理确实奏效了。上面我们已经简单提到过动态代理的原理,这里再简单的总结下:首先通过newProxyInstance方法获取代理类实例,而后我们便可以通过这个代理类实例调用代理类的方法,对代理类的方法的调用实际上都会调用中介类(调用处理器)的invoke方法,在invoke方法中我们调用委托类的相应方法,并且可以添加自己的处理逻辑。
JDK动态代理
a、定义一个接口Car:
public interface Car {void drive(String driverName, String carName);}
b、定义接口Car的一个实现类Audi:
public class Audi implements Car {@Overridepublic void drive(String driverName, String carName) {System.err.println("Audi is driving... " + "driverName: " + driverName + ", carName" + carName);}}
c、定义一个动态调用的控制器CarHandler:
public class CarHandler implements InvocationHandler {private Car car;public CarHandler(Car car) {this.car = car;}@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {System.err.println("before");method.invoke(car, args);System.err.println("after");return null;}}
d、测试类ProxyTest:
public class ProxyTest {@Testpublic void proxyTest() throws Exception {Car audi = (Car) Proxy.newProxyInstance(Car.class.getClassLoader(), new Class<?>[] {Car.class}, new CarHandler(new Audi()));audi.drive("name1", "audi");}}
e、输出结果:
before
Audi is driving… driverName: name1, carNameaudi
after
上面这段,相信大家都懂,也明白原理,这就是所谓的知其然,但是不一定都能知其所以然。接下来就解释下“知其所以然”。
进入到Proxy类的newProxyInstance方法:
public static Object newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h)throws IllegalArgumentException{if (h == null) {throw new NullPointerException();}/** Look up or generate the designated proxy class.*/Class<?> cl = getProxyClass(loader, interfaces);/** Invoke its constructor with the designated invocation handler.*/try {Constructor cons = cl.getConstructor(constructorParams);return cons.newInstance(new Object[] { h });} catch (NoSuchMethodException e) {throw new InternalError(e.toString());} catch (IllegalAccessException e) {throw new InternalError(e.toString());} catch (InstantiationException e) {throw new InternalError(e.toString());} catch (InvocationTargetException e) {throw new InternalError(e.toString());}}
关键的3行:
// 创建代理类Class<?> cl = getProxyClass(loader, interfaces);// 实例化代理对象Constructor cons = cl.getConstructor(constructorParams);
返回的是代理类的实例化对象。接下来的调用就很清晰了。
那么,JDK动态代理最核心的关键就是这个方法:
Class<?> cl = getProxyClass(loader, interfaces);
进入该方法,这个方法很长,前面很多都是铺垫,在方法的最后调用了一个方法:
byte[] proxyClassFile = ProxyGenerator.generateProxyClass(proxyName, interfaces);
这个方法就是产生代理对象的方法。我们先不看前后,只关注这一个方法,我们自己来写一个该方法:
public class ProxyTest {@SuppressWarnings("resource")@Testpublic void proxyTest() throws Exception {byte[] bs = ProxyGenerator.generateProxyClass("AudiImpl", new Class<?>[] {Car.class});new FileOutputStream(new File("d:/AudiImpl.class")).write(bs);}}
于是,我们就在D盘里面看到了一个叫做AudiImpl.class的文件,对该文件进行反编译,得到下面这个类:
public final class AudiImpl extends Proxy implements Car {private static final long serialVersionUID = 5351158173626517207L;private static Method m1;private static Method m3;private static Method m0;private static Method m2;public AudiImpl(InvocationHandler paramInvocationHandler) {super(paramInvocationHandler);}public final boolean equals(Object paramObject) {try {return ((Boolean) this.h.invoke(this, m1, new Object[] { paramObject })).booleanValue();} catch (Error | RuntimeException localError) {throw localError;} catch (Throwable localThrowable) {throw new UndeclaredThrowableException(localThrowable);}}public final void drive(String paramString1, String paramString2) {try {this.h.invoke(this, m3, new Object[] { paramString1, paramString2 });return;} catch (Error | RuntimeException localError) {throw localError;} catch (Throwable localThrowable) {throw new UndeclaredThrowableException(localThrowable);}}public final int hashCode() {try {return ((Integer) this.h.invoke(this, m0, null)).intValue();} catch (Error | RuntimeException localError) {throw localError;} catch (Throwable localThrowable) {throw new UndeclaredThrowableException(localThrowable);}}public final String toString() {try {return (String) this.h.invoke(this, m2, null);} catch (Error | RuntimeException localError) {throw localError;} catch (Throwable localThrowable) {throw new UndeclaredThrowableException(localThrowable);}}static {try {m1 = Class.forName("java.lang.Object").getMethod("equals",new Class[] { Class.forName("java.lang.Object") });m3 = Class.forName("com.mook.core.service.Car").getMethod("drive",new Class[] { Class.forName("java.lang.String"), Class.forName("java.lang.String") });m0 = Class.forName("java.lang.Object").getMethod("hashCode", new Class[0]);m2 = Class.forName("java.lang.Object").getMethod("toString", new Class[0]);} catch (NoSuchMethodException localNoSuchMethodException) {throw new NoSuchMethodError(localNoSuchMethodException.getMessage());} catch (ClassNotFoundException localClassNotFoundException) {throw new NoClassDefFoundError(localClassNotFoundException.getMessage());}}}
这个时候,JDK动态代理所有的秘密都暴露在了你的面前,当我们调用drive方法的时候,实际上是把方法名称传给控制器,然后执行控制器逻辑。这就实现了动态代理。Spring AOP有两种方式实现动态代理,如果基于接口编程,默认就是JDK动态代理,否则就是cglib方式,另外spring的配置文件里面也可以设置使用cglib来做动态代理,关于二者的性能问题,网上也是众说纷纭,不过我个人的观点,性能都不是问题,不太需要去纠结这一点性能问题。
cglib动态代理
静态代理
若代理类在程序运行前就已经存在,那么这种代理方式被成为 静态代理 ,这种情况下的代理类通常都是我们在Java代码中定义的。
通常情况下, 静态代理中的代理类和委托类会实现同一接口或是派生自相同的父类
下面我们用Vendor类代表生产厂家,BusinessAgent类代表微商代理,来介绍下静态代理的简单实现,委托类和代理类都实现了Sell接口
Sell接口定义如下:
public interface Sell{void sell();void ad();}//Vendor类的定义如下:public class Vendor implements Sell{public void sell(){System.out.println("In sell method");}public void ad(){System,out.println("ad method")}}
让代理类持有一个委托类的引用。
假设我们要实现这样一个需求:在执行委托类中的方法之前输出“before”,在执行完毕后输出“after”。现在试试先使用静态代理来实现这一需求
public class BusinessAgent implements Sell{//静态代理--让代理类持有一个委托类的引用。private Vendor mVendor;public BusinessAgent(Vendor vendor){this.mVendor = vendor;}public void sell(){System.out.println("before");mVendor.sell();System.out.println("after");}public void ad(){System.out.println("before");mVendor.ad();System.out.println("after");}}
从以上代码中我们可以了解到,通过静态代理实现我们的需求需要我们在每个方法中都添加相应的逻辑,这里只存在两个方法所以工作量还不算大,假如Sell接口中包含上百个方法呢?这时候使用静态代理就会编写许多冗余代码。通过使用动态代理,我们可以做一个“统一指示”,从而对所有代理类的方法进行统一处理,而不用逐一修改每个方法。下面我们来具体介绍下如何使用动态代理方式实现我们的需求。
Java集合
Java集合分为两大类:Collection和Map
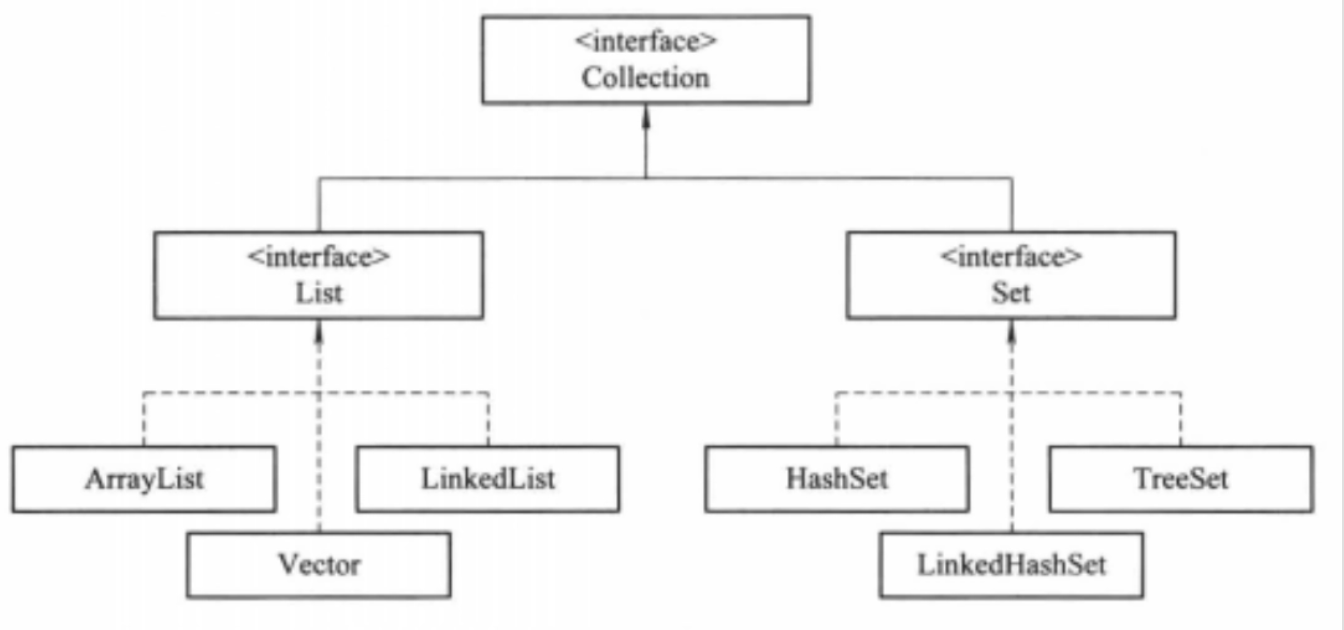
Collection
一组对立的元素,通常这些元素都服从某种规则:List必须保持元素特定的顺序;Set不能有重复元素;Queue保持一个先进先出的顺序
Collection接口的父接口是迭代器接口,这意味着每个Collection集合对象都具有可遍历性
List
LinkeList
// 引入 LinkedList 类import java.util.LinkedList;LinkedList<E> list = new LinkedList<E>(); // 普通创建方法或者LinkedList<E> list = new LinkedList(Collection<? extends E> c); // 使用集合创建链表
| 方法 | 描述 |
|---|---|
| public boolean add(E e) | 链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public void add(int index, E element) | 向指定位置插入元素。 |
| public boolean addAll(Collection c) | 将一个集合的所有元素添加到链表后面,返回是否成功,成功为 true,失败为 false。 |
| public boolean addAll(int index, Collection c) | 将一个集合的所有元素添加到链表的指定位置后面,返回是否成功,成功为 true,失败为 false。 |
| public void addFirst(E e) | 元素添加到头部。 |
| public void addLast(E e) | 元素添加到尾部。 |
| public boolean offer(E e) | 向链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerFirst(E e) | 头部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerLast(E e) | 尾部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public void clear() | 清空链表。 |
| public E removeFirst() | 删除并返回第一个元素。 |
| public E removeLast() | 删除并返回最后一个元素。 |
| public boolean remove(Object o) | 删除某一元素,返回是否成功,成功为 true,失败为 false。 |
| public E remove(int index) | 删除指定位置的元素。 |
| public E poll() | 删除并返回第一个元素。 |
| public E remove() | 删除并返回第一个元素。 |
| public boolean contains(Object o) | 判断是否含有某一元素。 |
| public E get(int index) | 返回指定位置的元素。 |
| public E getFirst() | 返回第一个元素。 |
| public E getLast() | 返回最后一个元素。 |
| public int indexOf(Object o) | 查找指定元素从前往后第一次出现的索引。 |
| public int lastIndexOf(Object o) | 查找指定元素最后一次出现的索引。 |
| public E peek() | 返回第一个元素。 |
| public E element() | 返回第一个元素。 |
| public E peekFirst() | 返回头部元素。 |
| public E peekLast() | 返回尾部元素。 |
| public E set(int index, E element) | 设置指定位置的元素。 |
| public Object clone() | 克隆该列表。 |
| public Iterator descendingIterator() | 返回倒序迭代器。 |
| public int size() | 返回链表元素个数。 |
| public ListIterator listIterator(int index) | 返回从指定位置开始到末尾的迭代器。 |
| public Object[] toArray() | 返回一个由链表元素组成的数组。 |
| public T[] toArray(T[] a) | 返回一个由链表元素转换类型而成的数组。 |
ArrayList
是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制
ArrayList继承了AbstractList,并实现了List接口
import java.util.ArrayList; // 引入 ArrayList 类ArrayList<E> objectName =new ArrayList<>(); // 初始化
| 方法 | 描述 |
|---|---|
| add() | 将元素插入到指定位置的 arraylist 中 |
| addAll() | 添加集合中的所有元素到 arraylist 中 |
| clear() | 删除 arraylist 中的所有元素 |
| clone() | 复制一份 arraylist |
| contains() | 判断元素是否在 arraylist |
| get() | 通过索引值获取 arraylist 中的元素 |
| indexOf() | 返回 arraylist 中元素的索引值 |
| removeAll() | 删除存在于指定集合中的 arraylist 里的所有元素 |
| remove() | 删除 arraylist 里的单个元素 |
| size() | 返回 arraylist 里元素数量 |
| isEmpty() | 判断 arraylist 是否为空 |
| subList() | 截取部分 arraylist 的元素 |
| set() | 替换 arraylist 中指定索引的元素 |
| sort() | 对 arraylist 元素进行排序 |
| toArray() | 将 arraylist 转换为数组 |
| toString() | 将 arraylist 转换为字符串 |
| ensureCapacity () |
设置指定容量大小的 arraylist |
| lastIndexOf() | 返回指定元素在 arraylist 中最后一次出现的位置 |
| retainAll() | 保留 arraylist 中在指定集合中也存在的那些元素 |
| containsAll() | 查看 arraylist 是否包含指定集合中的所有元素 |
| trimToSize() | 将 arraylist 中的容量调整为数组中的元素个数 |
| removeRange() | 删除 arraylist 中指定索引之间存在的元素 |
| replaceAll() | 将给定的操作内容替换掉数组中每一个元素 |
| removeIf() | 删除所有满足特定条件的 arraylist 元素 |
| forEach() | 遍历 arraylist 中每一个元素并执行特定操作 |
Vector
用法上和ArrayList相同,底层也是动态数组的实现,但Vector是线程安全的
| 序号 | 方法描述 |
|---|---|
| 1 | void add(int index, Object element) 在此向量的指定位置插入指定的元素。 |
| 2 | boolean add(Object o) 将指定元素添加到此向量的末尾。 |
| 3 | boolean addAll(Collection c) 将指定 Collection 中的所有元素添加到此向量的末尾,按照指定 collection 的迭代器所返回的顺序添加这些元素。 |
| 4 | boolean addAll(int index, Collection c) 在指定位置将指定 Collection 中的所有元素插入到此向量中。 |
| 5 | void addElement(Object obj) 将指定的组件添加到此向量的末尾,将其大小增加 1。 |
| 6 | int capacity() 返回此向量的当前容量。 |
| 7 | void clear() 从此向量中移除所有元素。 |
| 8 | Object clone() 返回向量的一个副本。 |
| 9 | boolean contains(Object elem) 如果此向量包含指定的元素,则返回 true。 |
| 10 | boolean containsAll(Collection c) 如果此向量包含指定 Collection 中的所有元素,则返回 true。 |
| 11 | void copyInto(Object[] anArray) 将此向量的组件复制到指定的数组中。 |
| 12 | Object elementAt(int index) 返回指定索引处的组件。 |
| 13 | Enumeration elements() 返回此向量的组件的枚举。 |
| 14 | void ensureCapacity(int minCapacity) 增加此向量的容量(如有必要),以确保其至少能够保存最小容量参数指定的组件数。 |
| 15 | boolean equals(Object o) 比较指定对象与此向量的相等性。 |
| 16 | Object firstElement() 返回此向量的第一个组件(位于索引 0) 处的项)。 |
| 17 | Object get(int index) 返回向量中指定位置的元素。 |
| 18 | int hashCode() 返回此向量的哈希码值。 |
| 19 | int indexOf(Object elem) 返回此向量中第一次出现的指定元素的索引,如果此向量不包含该元素,则返回 -1。 |
| 20 | int indexOf(Object elem, int index) 返回此向量中第一次出现的指定元素的索引,从 index 处正向搜索,如果未找到该元素,则返回 -1。 |
| 21 | void insertElementAt(Object obj, int index) 将指定对象作为此向量中的组件插入到指定的 index 处。 |
| 22 | boolean isEmpty() 测试此向量是否不包含组件。 |
| 23 | Object lastElement() 返回此向量的最后一个组件。 |
| 24 | int lastIndexOf(Object elem) 返回此向量中最后一次出现的指定元素的索引;如果此向量不包含该元素,则返回 -1。 |
| 25 | int lastIndexOf(Object elem, int index) 返回此向量中最后一次出现的指定元素的索引,从 index 处逆向搜索,如果未找到该元素,则返回 -1。 |
| 26 | Object remove(int index) 移除此向量中指定位置的元素。 |
| 27 | boolean remove(Object o) 移除此向量中指定元素的第一个匹配项,如果向量不包含该元素,则元素保持不变。 |
| 28 | boolean removeAll(Collection c) 从此向量中移除包含在指定 Collection 中的所有元素。 |
| 29 | void removeAllElements() 从此向量中移除全部组件,并将其大小设置为零。 |
| 30 | boolean removeElement(Object obj) 从此向量中移除变量的第一个(索引最小的)匹配项。 |
| 31 | void removeElementAt(int index) 删除指定索引处的组件。 |
| 32 | protected void removeRange(int fromIndex, int toIndex) 从此 List 中移除其索引位于 fromIndex(包括)与 toIndex(不包括)之间的所有元素。 |
| 33 | boolean retainAll(Collection c) 在此向量中仅保留包含在指定 Collection 中的元素。 |
| 34 | Object set(int index, Object element) 用指定的元素替换此向量中指定位置处的元素。 |
| 35 | void setElementAt(Object obj, int index) 将此向量指定 index 处的组件设置为指定的对象。 |
| 36 | void setSize(int newSize) 设置此向量的大小。 |
| 37 | int size() 返回此向量中的组件数。 |
| 38 | List subList(int fromIndex, int toIndex) 返回此 List 的部分视图,元素范围为从 fromIndex(包括)到 toIndex(不包括)。 |
| 39 | Object[] toArray() 返回一个数组,包含此向量中以恰当顺序存放的所有元素。 |
| 40 | Object[] toArray(Object[] a) 返回一个数组,包含此向量中以恰当顺序存放的所有元素;返回数组的运行时类型为指定数组的类型。 |
| 41 | String toString() 返回此向量的字符串表示形式,其中包含每个元素的 String 表示形式。 |
| 42 | void trimToSize() 对此向量的容量进行微调,使其等于向量的当前大小。 |
Stack
是Vector提供的一个子类,用于模拟栈这种数据结构
除了由Vector定义的所有方法,自己也定义了一些方法:
| 序号 | 方法描述 |
|---|---|
| 1 | boolean empty() 测试堆栈是否为空。 |
| 2 | Object peek( ) 查看堆栈顶部的对象,但不从堆栈中移除它。 |
| 3 | Object pop( ) 移除堆栈顶部的对象,并作为此函数的值返回该对象。 |
| 4 | Object push(Object element) 把项压入堆栈顶部。 |
| 5 | int search(Object element) 返回对象在堆栈中的位置,以 1 为基数。 |
Set
Set集合中多个对象之间没有明显的顺序,且不能包含重复元素
Set判断两个对象相同不是使用==运算符,而是根据equals方法,且都会返回false
HashSet
使用Hash算法来存储集合中的元素,具有良好的存取和查找性能。
底层采用哈希表实现,元素无序且唯一,线程不安全,效率高
元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性
当想HashSet集合存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置,此时会与HashSet中元素的HashCode值进行比较,如果不相等则直接插入,如果相等,则继续比较,比较使用的是equals方法,此时如果比较的内容不相等,就会采用哈希解决地址冲突的算法,在当前hashCode值处增加一个新的链表,以此来存储hashCode相等,但不同对象的元素,如果不相等则不存储
LinkedHashSet
也是根据元素的hashCode值来决定元素的存储位置,但和HashSet不同的是,它同时使用链表来维护元素的次序,这样是的元素看起来是以插入的顺序保存的
也正因为如此,LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时有较好的性能,因为链表本身就很适合遍历
线程不安全
SortedSet
此接口主要用于排序操作,即实现此接口的子类都属于排序的子类
TreeSet
是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态
EnumSet
是一个专门为枚举类设计的集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显示或隐式地指定。
EnumSet也是SortedSet接口的实现类,因此也是有序的
Queue
用于模拟队列这种数据结构
PriorityQueue(优先队列)
保证每次取出的元素都是队列中权值最小的。元素大小的评判可以通过元素本身的自然顺序,也可以通过构造是传入的比较器。
Java中PriorityQueue实现了Queue接口,不允许放入null元素,其通过堆实现,具体说是通过完全二叉树实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为PriorityQueue的底层实现。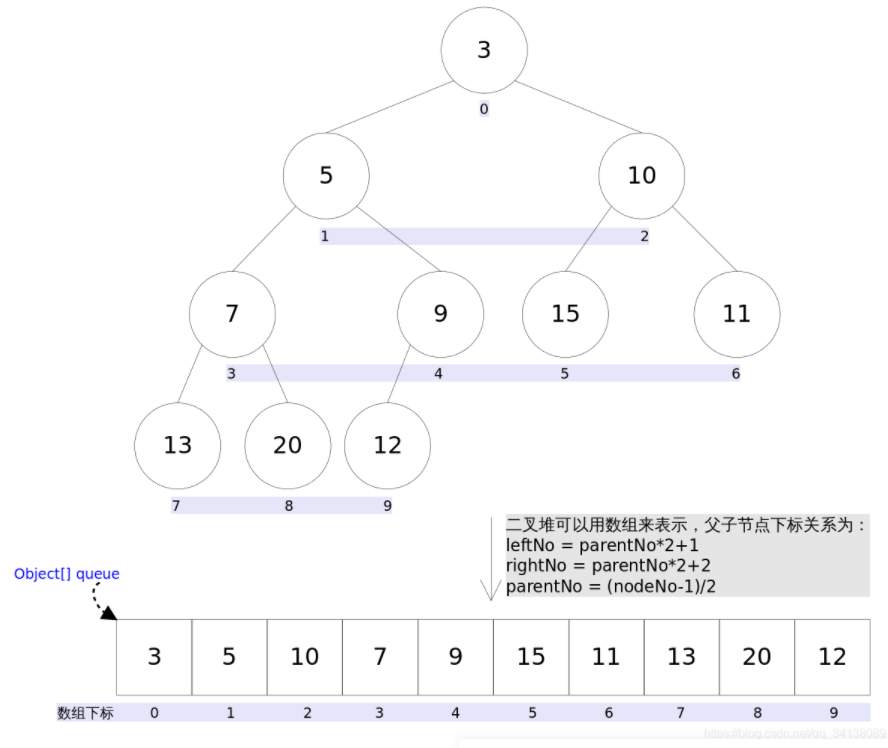
add()和offer()
add(E e)和offer(E e)的语义相同,都是向有限队列中插入元素,只是Queue接口规定二者对插入失败时的处理不同,前者在插入失败时抛出异常,后者则返回false,除此之外别无差别
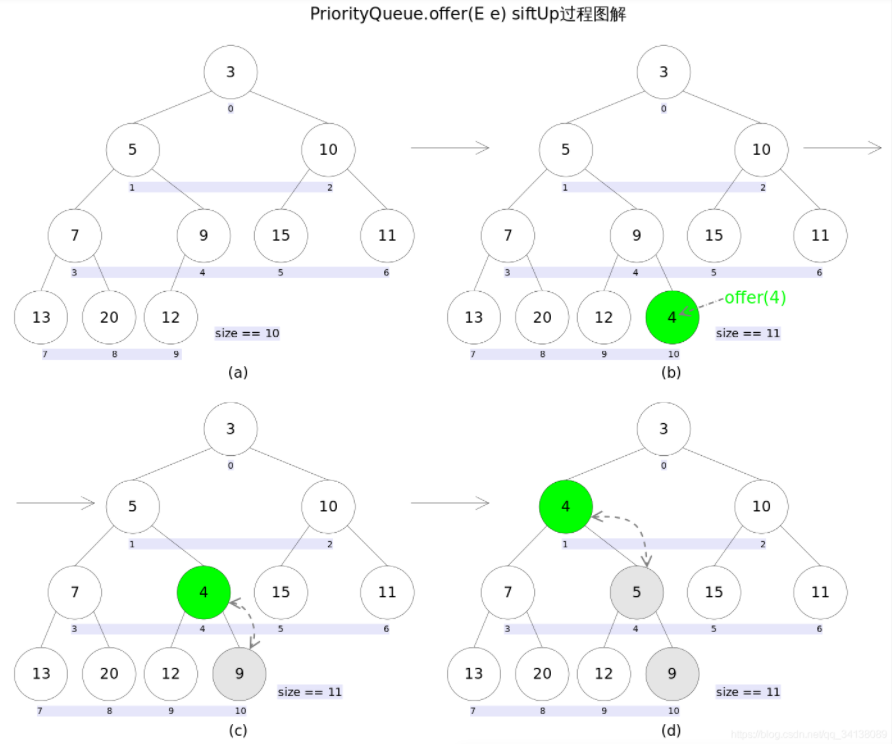
新加入的元素可能会破坏小顶堆的性质,因此offer或者add中会通过siftUp()方法进行必要的调整
//offer(E e)public boolean offer(E e) {if (e == null)//不允许放入null元素throw new NullPointerException();modCount++;int i = size;if (i >= queue.length)grow(i + 1);//自动扩容size = i + 1;if (i == 0)//队列原来为空,这是插入的第一个元素queue[0] = e;elsesiftUp(i, e);//调整return true;}//siftUp()/**从k指定的位置开始,将x逐层与当前点的parent进行比较,知道满足x>=queue[parent]*/private void siftUp(int k, E x) {while (k > 0) {int parent = (k - 1) >>> 1;//parentNo = (nodeNo-1)/2Object e = queue[parent];if (comparator.compare(x, (E) e) >= 0)//调用比较器的比较方法break;queue[k] = e;k = parent;}queue[k] = x;}
element()和peek()
element()和peek()的语义完全相同,都是获取但不删除队首元素,也就是队列中权值最小的那个元素,二者唯一的区别是当方法失败时前者抛出异常,后者返回null
//peek()public E peek() {if (size == 0)return null;return (E) queue[0];//0下标处的那个元素就是最小的那个}
remove()和poll()
两种方法的语义相同,都是获取并删除队首元素,区别是当方法失败时,前者抛出异常,后者返回null。由于删除操作会改变队列的结构,因此为维护小顶堆的性质,两种方法都是通过siftDown()方法进行必要的调整。
public E poll() {if (size == 0)return null;int s = --size;modCount++;E result = (E) queue[0];//0下标处的那个元素就是最小的那个E x = (E) queue[s];queue[s] = null;if (s != 0)siftDown(0, x);//调整return result;}//siftDown()/***从k指定的位置开始,将x逐层向下与当前节点的左右孩子中较小的那个交换,知道x小于或者*等于左右孩子中的任何一个为止*/private void siftDown(int k, E x) {int half = size >>> 1;while (k < half) {//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标int child = (k << 1) + 1;//leftNo = parentNo*2+1Object c = queue[child];int right = child + 1;if (right < size &&comparator.compare((E) c, (E) queue[right]) > 0)c = queue[child = right];if (comparator.compare(x, (E) c) <= 0)break;queue[k] = c;//然后用c取代原来的值k = child;}queue[k] = x;}
remove(Object o)
用于删除队列中跟参数相等的某一个元素(如果有多个相等,只会删除一个),该方法不是Queue接口内的方法,而是Collection接口的方法,由于删除操作会改变队列结果,所以要进行调整,又因为删除元素的位置可能是任意的,所以调整过程比其他函数稍加繁琐:当删除的元素是最后一个时,可直接删除,反正,则需要从删除点开始以最后一个元素为参照调用一个siftDown()
//remove(Object o)public boolean remove(Object o) {//通过遍历数组的方式找到第一个满足o.equals(queue[i])元素的下标int i = indexOf(o);if (i == -1)return false;int s = --size;if (s == i) //情况1queue[i] = null;else {E moved = (E) queue[s];queue[s] = null;siftDown(i, moved);//情况2......}return true;}
Deque
代表一个双端队列,双端队列可以同时从两端来添加、删除元素,因此Deque的实现类既可以当成队列使用,也可以当成栈使用
ArrayDeque
是一个基于数组实现的双端队列,和ArrayList类似,底层都采用一个动态的,可重分配的Object[]数组来存储集合元素,当集合元素超出该数组的容量时,系统会在底层重新分配一个Object[]数组老存储集合元素
Map
一组成对的键值对对象,键不允许重复
HashMap
可以允许key为null,但也只允许一个
线程不安全
jdk1.8以后在解决哈希冲突是有了较大的变化,当链表长度大于阈值(默认为8)时,且数组长度大于64时,将arr[i]处的链表转化为红黑树,以减少搜索时间
| 方法 | 描述 |
|---|---|
| clear() | 删除 hashMap 中的所有键/值对 |
| clone() | 复制一份 hashMap |
| isEmpty() | 判断 hashMap 是否为空 |
| size() | 计算 hashMap 中键/值对的数量 |
| put() | 将键/值对添加到 hashMap 中 |
| putAll() | 将所有键/值对添加到 hashMap 中 |
| putIfAbsent() | 如果 hashMap 中不存在指定的键,则将指定的键/值对插入到 hashMap 中。 |
| remove() | 删除 hashMap 中指定键 key 的映射关系 |
| containsKey() | 检查 hashMap 中是否存在指定的 key 对应的映射关系。 |
| containsValue() | 检查 hashMap 中是否存在指定的 value 对应的映射关系。 |
| replace() | 替换 hashMap 中是指定的 key 对应的 value。 |
| replaceAll() | 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果。 |
| get() | 获取指定 key 对应对 value |
| getOrDefault() | 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 |
| forEach() | 对 hashMap 中的每个映射执行指定的操作。 |
| entrySet() | 返回 hashMap 中所有映射项的集合集合视图。 |
| keySet () |
返回 hashMap 中所有 key 组成的集合视图。 |
| values() | 返回 hashMap 中存在的所有 value 值。 |
| merge() | 添加键值对到 hashMap 中 |
| compute() | 对 hashMap 中指定 key 的值进行重新计算 |
| computeIfAbsent() | 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hasMap 中 |
| computeIfPresent() | 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中。 |
LinkedHashMap
使用的是双向链表来维护key-value的次序,该链表负责维护Map的迭代顺序,与key-value对的插入顺序一直
HashTable
线程安全
Properties
Properties对象在处理属性文件时特别方便,Properties类可以Map对象和属性文件关联起来,从而可以把Map对象中的key-value对写入到属性文件中,也可以把属性文件中的属性名-属性值加载到Map对象中
SortedMap
TreeMap
TreeMap是一个红黑树的数据结构,每个key-value对即作为红黑树的一个节点。TreeMap存储key-value对,即节点时,需要根据key对节点进行排序。因此可以保证所有的键值对处于有序状态
WeakHashMap
WeakHashMap与HashMap的用法基本类似。区别在意,HashMap的key保留了实际对象的强引用,这意味着只要该HashMap对象不被销毁,该HashMap所引用的对象就不会被垃圾回收;而WeakHashMap的key只保留了对实际对象的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量引用这,则这些key所引用的香客可能被垃圾回收,当垃圾回收了该key所对应的实际对象之后,WeakHashMap也可能会自动删除这些key所对用的键值对
IdentityHashMap
实现机制与HashMap基本类似。在IdentityHashMap中,当且仅当两个key严格相等(key1 == key2)时,IdentityHashMap才认为两个key相等
EnumMap
EnumMap是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。创建EnumMap时必须显式或隐式指定它对应的枚举类。EnumMap根据key的自然顺序(即枚举值在枚举类中的定义顺序)
Collection提供的方法
unmodifiableMap
产生一个只读的map对象,即允许模块为用户提供对内部映射的只读访问,当视图修改返回的映射会抛出UnsupportedOperationException异常信息
如果指定映射是可序列化的,则返回的映射也将是可序列化的
public static <K,V> Map<K,V> unmodifiableMap(Map<? extends K,? extends V> m)
CopyOnWriteArrayList
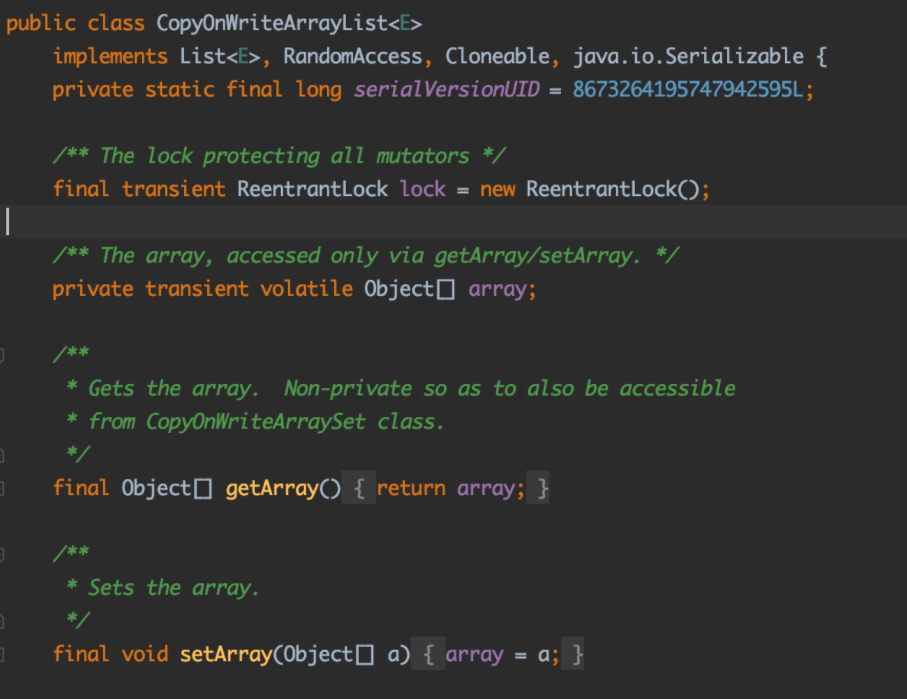
运用了不可变对象模式(实际是等效不可变对象(存储对象的内部状态可能改变),因为其维护的array的内部状态是可以替换的,即就得新的数组替换旧的数组),使得集合在进行遍历操作的时候,不用加锁也可以保证线程安全。
底层维护了一个array对象数组,用于存储集合的每个元素,并且array数组只能通过getArray和setArray方法来访问
其iterator方法实际就是通过getArray()方法获取array数组,然后对该数组进行遍历
写时复制思想主要体现在写操作上,每个写操作中(添加或者删除),都是用了ReentrantLock,可重入锁
在新增或者删除一个元素时,最终都是基于原有的数组复制出一个新的数组,然后直接用新的数据替换掉就的数组
缺点:弱一致性,并不能保证某一时刻读取到的数据是最新的
适用于读多写少的场景上
JDBC中加载Mysql的驱动就用到了CopyOnWriteArrayList,将驱动信息添加到registerDriver中
Java IO
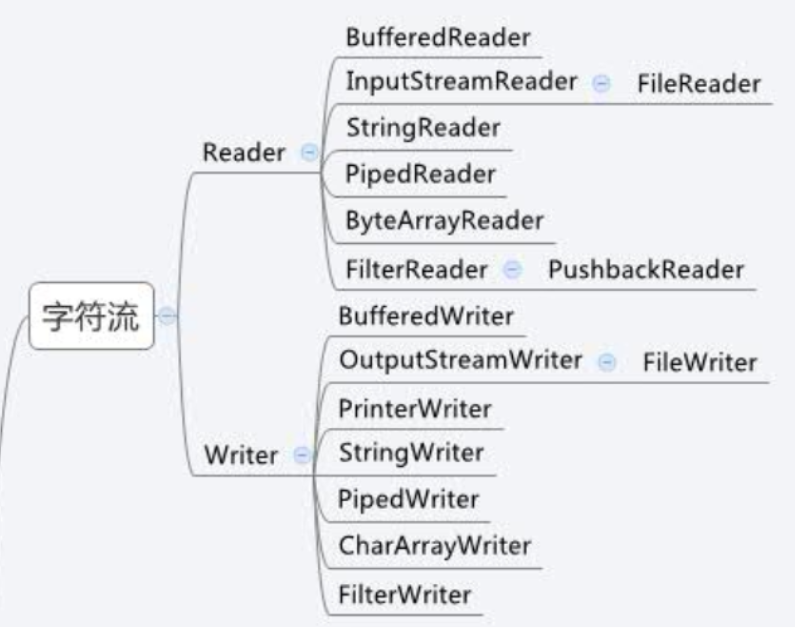
IO流主要用于硬板、内存、键盘等处理设备上的数据操作,根据处理数据的数据类型的不同可以分为字节流(抽象基类为InputStream和OutPutStream)和字符流(抽象基类为Reader和Writer),其根据流向的不同可分为输入流和输出流
字符流和字节流的主要区别
字节流读取的时候,读到一个字节就返回一个字节;字符流使用了字节流读到一个或者多个字节(中文对应的字节数是两个,在UTF-8码表中是3个字节)时,先去查指定的编码表,将查到的字符返回
字节流可以处理所有的数据类型,如图片、mp3、avi视频文件等,而字符流只能处理字符数据。只要是处理纯文本数据,就要优先考虑使用字符流,除此之外都用字节流
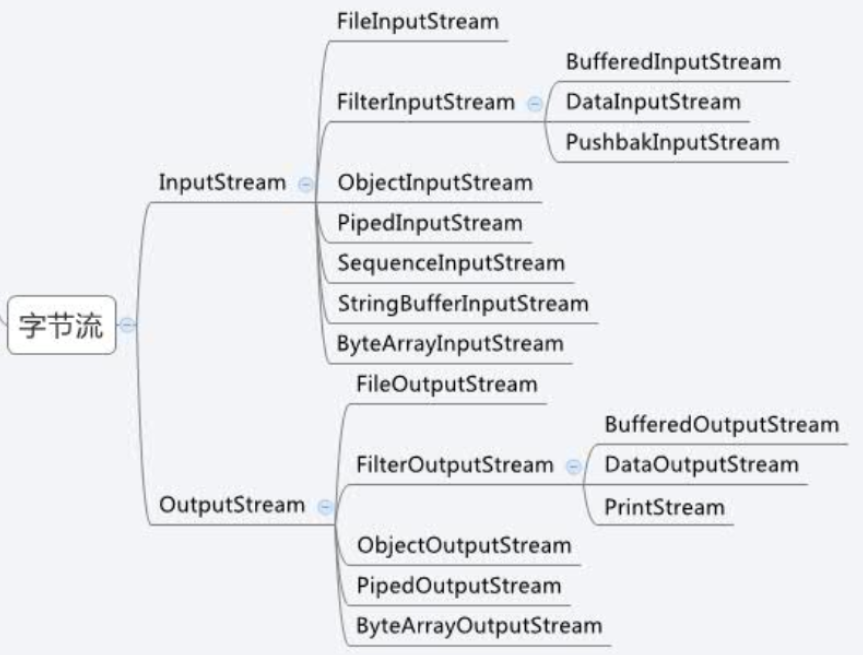
处理流和节点流
即IO流的两大类
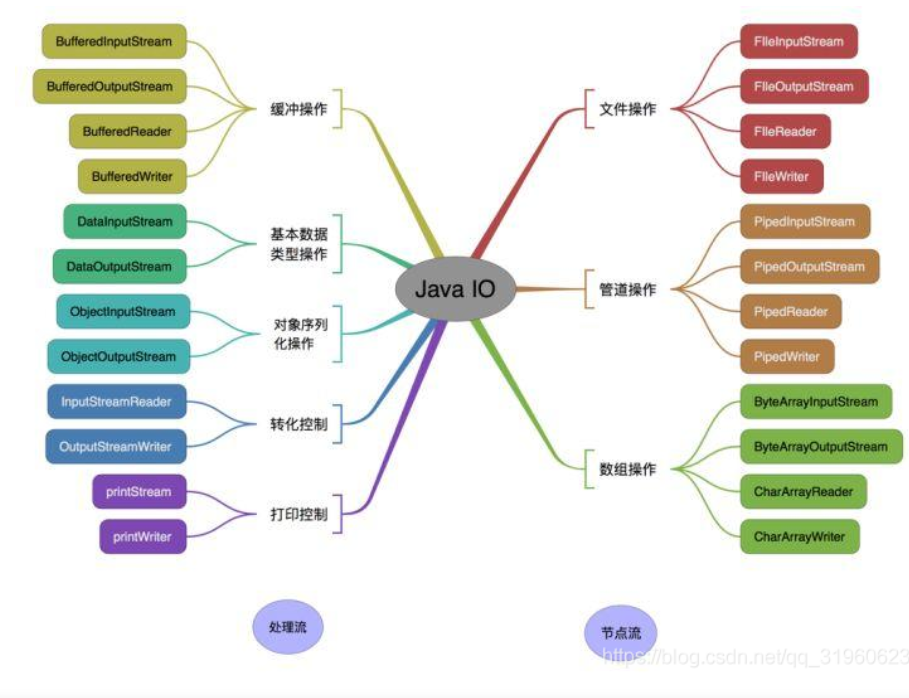
场景
- FileInputStream/FileOutputStream 需要逐个字节处理原始二进制流的时候使用,效率低下
- FileReader/FileWriter 需要组个字符处理的时候使用
- StringReader/StringWriter 需要处理字符串的时候,可以将字符串保存为字符数组
- PrintStream/PrintWriter 用来包装FileOutputStream 对象,方便直接将String字符串写入文件
- Scanner 用来包装System.in流,很方便地将输入的String字符串转换成需要的数据类型
- InputStreamReader/OutputStreamReader , 字节和字符的转换桥梁,在网络通信或者处理键盘输入的时候用
- BufferedReader/BufferedWriter , BufferedInputStream/BufferedOutputStream , 缓冲流用来包装字节流后者字符流,提升IO性能,BufferedReader还可以方便地读取一行,简化编程。
I/O多路复用技术(multiplexing)是什么?
下面举一个例子,模拟一个tcp服务器处理30个客户socket。
假设你是一个老师,让30个学生解答一道题目,然后检查学生做的是否正确,你有下面几个选择:
- 第一种选择:按顺序逐个检查,先检查A,然后是B,之后是C、D。。。这中间如果有一个学生卡主,全班都会被耽误。
这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。 - 第二种选择:你创建30个分身,每个分身检查一个学生的答案是否正确。 这种类似于为每一个用户创建一个进程或者线程处理连接。
- 第三种选择,你站在讲台上等,谁解答完谁举手。这时C、D举手,表示他们解答问题完毕,你下去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。。。
这种就是IO复用模型,Linux下的select、poll和epoll就是干这个的。将用户socket对应的fd注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。
这样,整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor模式。

若有收获,就点个赞吧
0 人点赞
