Master 节点周期性地向集群中的其他节点发送ping, 检查节点是否仍然活跃,如果发现集群中节点数量不足(法定过半),则放弃 master 身份,重新执行选主流程。其他节点也周期性地检查 master 是否活跃,如果得不到 master 的回复则该节点重新执行选主流程。
一、为什么使用主从模式
除了Leader/Follower模式外,另一种是DHT(分布式哈希表),可以支持每小时数千个节点的离开和加入,其可以在不了解底层网络拓扑的异构网络中工作,查询响应时间约为7左右,例如Cassandra(一套开源的NoSQL数据库系统)使用就是这种方案。但是在相对稳定的对等网络中,主从模式会更好。
Elasticsearch经典场景中的另一个简化是集群中没有那么多节点。通常节点的数量远远小于单个节点能够维护的练接数,并且网络环境不必经常处理节点的加入和离开。这就是为什么ES使用主从模式。
我们需要注意的是,所有分布式系统都需要某种方式来处理数据的一致性问题。一般情况下,有两种策略:
1. 试图避免不一致1. 发生不一致之后进行协调
第二种的非常强大,但对于数据模型来说,又比较严格的限制。因此使用前者,主从模式;
二、选举算法
2.1 Bully算法
Leader选举算法之一。基本思想是,它假定所有节点都有一个唯一的ID,使用该ID对节点进行排序。任何时候当前Leader都是参与这个集群的最高的ID节点。优点是易于实现,但是当最大ID节点处于不稳定的状态下时,可能出现假死现象;例如:master负载大假死了,集群中第二大的ID节点选为新主,这是假死的master恢复,再次被选为新主,然后又假死…,如果不同节点之间网络终端,还可能出现脑裂现象。详细讲解,可以查看:https://www.yuque.com/docs/share/11106ca3-a029-46cd-8fea-e043da1e65ae?# 《10 Bully算法》
2.2 Paxos算法
paxos非常强大,在何时、如何进行选举等方面的灵活性比Bully有很多优势,详细讲解,可以查看:https://www.yuque.com/docs/share/57895e39-6c37-43a4-96e0-3be1313bba08?# 《08 Paxos 算法》
三、Elasticsearch选用Bully算法
Elasticsearch 集群中节点数量有限,单个节点能够处理和其他所有节点间的连接,集群中不会出现节点频繁加入和离开的情况,因此 Zen Discovery 中使用了实现比较简单的 Bully 算法。
使用 Bully 算法的集群中有一个 master 维护整个集群的状态信息,并定时向集群中其他节点推送集群状态的版本信息,如果直接使用 Bully 算法,会遇到下面几个问题,因此 Elasticsearch 做了特殊化的处理。
3.1 master节点假死
master 可能因负载过重而处于不稳定的状态,可能无法响应某些节点的请求,但短时间内可以恢复正常,为了避免频繁的选举,ES 中使用了推迟选举的方法,直到 master 失效来解决上述问题。只要当前主节点不挂掉,就不重新选主。但是这样容易产生脑裂,为此,再通过“法定得票人数过半”机制解决脑裂问题。
3.2 脑裂
考虑下面这种情况,原集群由 A、B、C、D、E 组成,主节点是 A。当两个交换机之间连接中断之后,A、B 不能再与C、D、E 进行通信,形成了两个网络分区。A、B 组成的集群中 master 仍然是 A,而C、D、E 会选出一个新的 master,客户端访问 A、B 或者高 C、D、E 时数据不一致。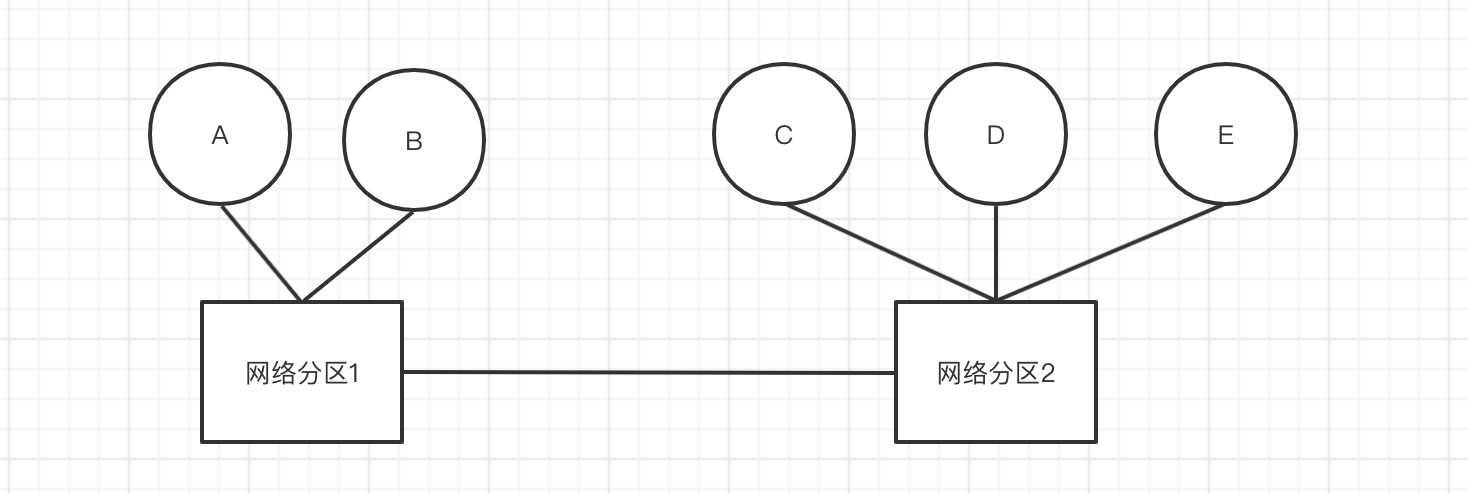
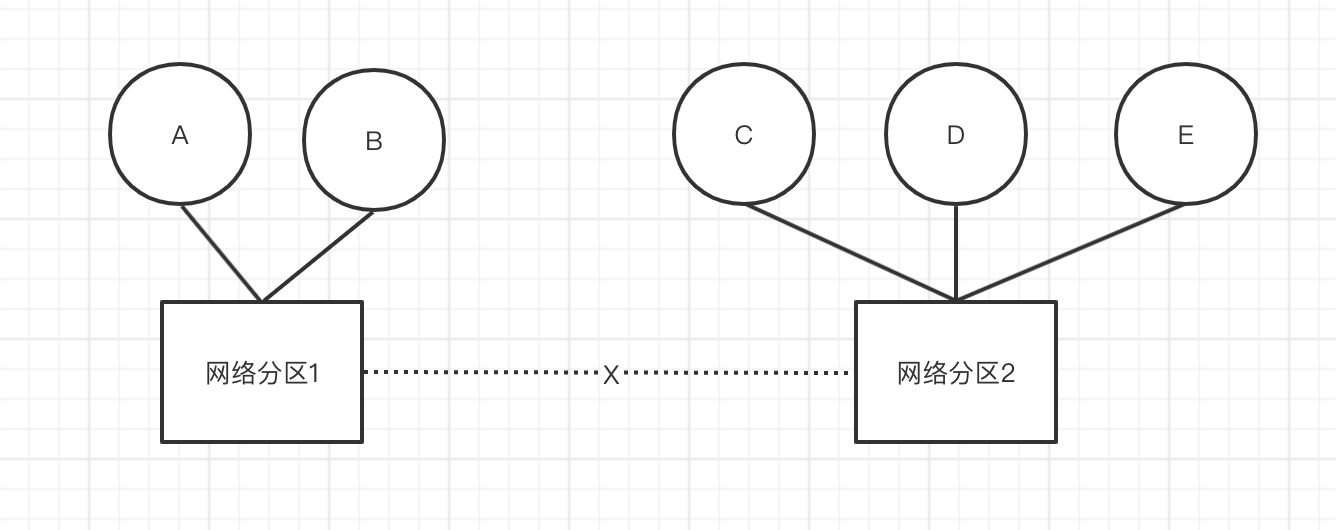
ES采用了设置 “法定得票人数过半” 解决,在选举过程中当节点得票达到 discovery.zen.minimum_master_nodes 的值时才能成为 master,这个值通常设定为:
(master_eligible_node/2)+1 > quorum
discovery.zen.minimum_master_nodes**:最小主节点数,这是防止脑裂、防止数据丢失的及其重要的参数,实际上,它的作用不知表面的含义。除了在选主时用于决定“多数”, 还用于多处重要的判断,如:触发选主、决定master、gateway选举元信息、master发布集群状态
将上例中 discovery.zen.minimum_master_nodes 设置为3。当两个交换机之间连接中断之后,A不能再与C,D,E进行通信,C、D、E所组成的网络分区中不存在活跃的master,因此发起选举。A的集群中只剩下A和B,不足minimum_master_nodes,因此放弃 master 身份。C、D、E进行投票,直到达成一致选出一个 master,形成一个新的集群,其中节点数量为 3,刚好满足 minimum_master_nodes,而A、B不再处理来自客户端的请求。
四、选主过程
4.1 通过 ZenDiscovery::findMaster 确定临时master
该函数查找当前集群活跃Master,或者从候选者中选举新的Master。如果选主成功,则返回选定的Master,否则返回空。
为什么是临时Master?因为还需要等待下一个步骤,该节点的得票数足够时,才确立为真正的Master。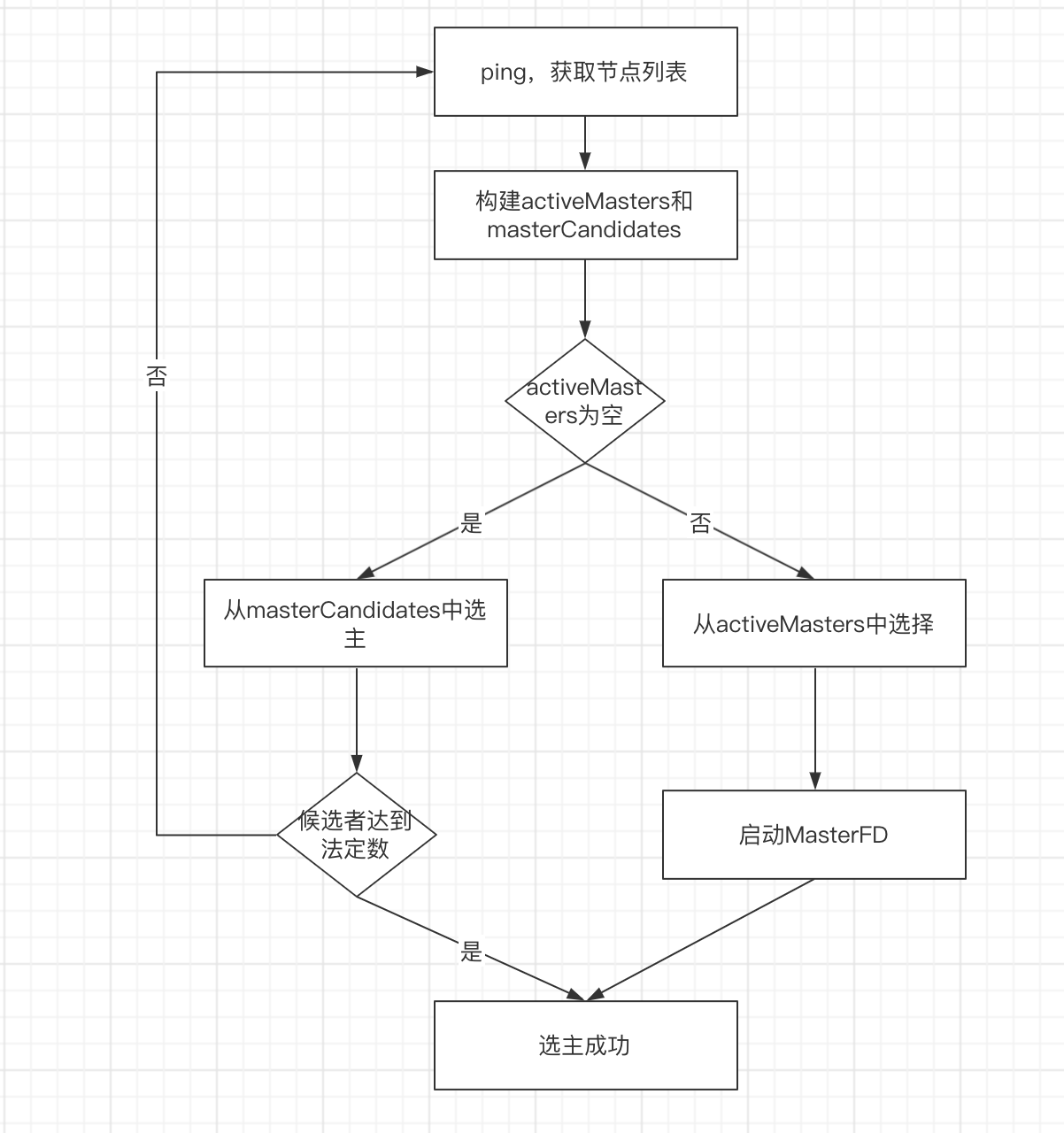
选举过程如下:
- ping所有节点,获取节点列表(fullPingResponses),ping节点不包含本节点,把本节点单独添加到节点列表中。
- 构建2个列表。
- activeMasters列表:储存集群当前活跃的Master列表,正常情况下只有一个。在这个过程中,如果配置了discovery.zen.master_election.ignore_non_master_pings为true,默认为false,而节点又不具备Master资格,则跳过该节点。在构建过程中,如果节点不具备Master资格,则通过ignore_non_master_pings选项忽略它认为的那个Master。
- masterCandidates列表:存储master候选者列表。遍历第一步获取的列表,去掉不具备master资格的节点,添加到这个列表中。
- 如果activeMasters为空,则从masterCandidates中选举,结果可能成功,也可能失败。如果activeMasters不为空,可以从中选择最合适的Master。
选举源码如下:
private DiscoveryNode findMaster() {// 1. PING 所有节点,获取各节点保存的集群信息List<ZenPing.PingResponse> fullPingResponses = pingAndWait(pingTimeout).toList();// 2. 由于上面是获取的其他节点的信息,这里需要将本节点加上final DiscoveryNode localNode = transportService.getLocalNode();fullPingResponses.add(new ZenPing.PingResponse(localNode, null, this.clusterState()));// 3. 若设置了 master_election_ignore_non_masters 则去掉没有 master 资格(node.master: false)的节点final List<ZenPing.PingResponse> pingResponses = filterPingResponses(fullPingResponses, masterElectionIgnoreNonMasters, logger);// 4. 将各节点认为的 master 加入 activeMasters 列表List<DiscoveryNode> activeMasters = new ArrayList<>();for (ZenPing.PingResponse pingResponse : pingResponses) {// 避免未经其他节点检查就将本节点选为 masterif (pingResponse.master() != null && !localNode.equals(pingResponse.master())) {activeMasters.add(pingResponse.master());}}// 5. 将 PING 到的具有 master 资格的节点加入 masterCandidates 列表作为候选节点List<ElectMasterService.MasterCandidate> masterCandidates = new ArrayList<>();for (ZenPing.PingResponse pingResponse : pingResponses) {if (pingResponse.node().isMasterNode()) {masterCandidates.add(new ElectMasterService.MasterCandidate(pingResponse.node(), pingResponse.getClusterStateVersion()));}}if (activeMasters.isEmpty()) {// 6. 没有活跃的 masterif (electMaster.hasEnoughCandidates(masterCandidates)) {// 7. 拥有足够的候选节点,则进行选举final ElectMasterService.MasterCandidate winner = electMaster.electMaster(masterCandidates);return winner.getNode();} else {// 8. 无法选举,无法得到 master,返回 nullreturn null;}} else {assert !activeMasters.contains(localNode) : "local node should never be elected as master when other nodes indicate an active master";// 9. 有活跃的 master,从 activeMasters 中选择return electMaster.tieBreakActiveMasters(activeMasters);}}
在没有活跃的 master 时使用,上面第 7 步执行 master 的选举,通过 MasterCandidate::compare 对候选节点进行比较
// ElectMasterService.MasterCandidate::comparepublic static int compare(MasterCandidate c1, MasterCandidate c2) {// 优先选择集群状态版本最新的节点,先比较集群状态版本,注意此处c2在前,c1在后int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);//如果版本号相同,则比较节点IDif (ret == 0) {ret = compareNodes(c1.getNode(), c2.getNode());}return ret;}// ElectMasterService::compareNodesprivate static int compareNodes(DiscoveryNode o1, DiscoveryNode o2) {// 集群状态版本相同时优先选择具有 master 资格的节点if (o1.isMasterNode() && !o2.isMasterNode()) {return -1;}if (!o1.isMasterNode() && o2.isMasterNode()) {return 1;}// 以上条件都相同时选择 ID 较小的节点return o1.getId().compareTo(o2.getId());}
上述代码中,最后一行可以看出,这里只是将节点排序后选择足校的节点作为Master。但是排序时使用自定义的比较函数MasterCandidate::compare,早期的版本中只是对节点ID进行排序,现在会优先把集群状态版本号高的节点放在前边。
在有活跃的 master 时,上面第 9 步通过 ElectMasterService::tieBreakAcitveMasters 使用 ElectMasterService::compareNodes 的规则从 activeMasters 中选择。选择过程很简单,取列表中的最小值。
4.2 根据临时master投票
在ES中,发送投票就是发送加入集群(requiredJoins)请求。得票就是申请加入该节点的请求的数量。
选举出的临时Master有两种情况:该临时Master是本节点或者非本节点。
- 如果临时Master是本节点
- 等待足够多的具备Master资格的节点加入本节点(投票达到法定人数),以完成选举;
- 超时(默认30s)后还没有满足数量的join请求,则选举失败,需要进行新一轮的选举;
- 成功后发布新的ClusterState
- 如果其他节点被选为Master
- 不再接收其他节点的join请求
- 向Master发送加入请求,并等待回复。超时时间默认为1分钟。如果遇到异常,则默认重试3次。这个步骤在joinElectedMaster方法中实现。
- 最终当选的Master会被发布集群状态,才确认客户的join请求。因此,JoinElectedMaster返回代表收到了join请求的确认,并且已经收到了集群状态。本步骤检查收到的集群状态中的Master节点如果为空,或者当选的Master不是之前选择的节点,则重新选举。
if (transportService.getLocalNode().equals(masterNode)) {// 选出的临时 master 是本节点,则等待被选举为真正的 masterfinal int requiredJoins = Math.max(0, electMaster.minimumMasterNodes() - 1);nodeJoinController.waitToBeElectedAsMaster(requiredJoins, masterElectionWaitForJoinsTimeout,new NodeJoinController.ElectionCallback() {@Overridepublic void onElectedAsMaster(ClusterState state) {// 成功被选举为 mastersynchronized (stateMutex) {joinThreadControl.markThreadAsDone(currentThread);}}@Overridepublic void onFailure(Throwable t) {// 等待超时,重新开始选举流程synchronized (stateMutex) {joinThreadControl.markThreadAsDoneAndStartNew(currentThread);}}});} else {// 选出的临时 master 不是本节点,不再接收其他节点的 join 请求nodeJoinController.stopElectionContext(masterNode + " elected");// 向临时节点发送 join 请求(投票),被选举的临时 master 在确认成为 master 并发布新的集群状态后才会返回final boolean success = joinElectedMaster(masterNode);// 成功加入之前选择的临时 master 节点,则结束线程,否则重新选举synchronized (stateMutex) {if (success) {DiscoveryNode currentMasterNode = this.clusterState().getNodes().getMasterNode();if (currentMasterNode == null) {joinThreadControl.markThreadAsDoneAndStartNew(currentThread);} else if (currentMasterNode.equals(masterNode) == false) {joinThreadControl.stopRunningThreadAndRejoin("master_switched_while_finalizing_join");}joinThreadControl.markThreadAsDone(currentThread);} else {joinThreadControl.markThreadAsDoneAndStartNew(currentThread);}}}复制代码
4.3 选举完成
NodeJoinController::checkPendingJoinsAndElectIfNeeded 在节点获得足够的得票时使节点成为 master,并发布新的集群状态
private synchronized void checkPendingJoinsAndElectIfNeeded() {// 计算节点得票数final int pendingMasterJoins = electionContext.getPendingMasterJoinsCount();if (electionContext.isEnoughPendingJoins(pendingMasterJoins) == false) {...} else {// 得票数足够,成为 masterelectionContext.closeAndBecomeMaster();}}public synchronized int getPendingMasterJoinsCount() {int pendingMasterJoins = 0;// 统计节点得票数,只计算拥有 master 资格节点的投票for (DiscoveryNode node : joinRequestAccumulator.keySet()) {if (node.isMasterNode()) {pendingMasterJoins++;}}return pendingMasterJoins;}

若有收获,就点个赞吧
0 人点赞
