Elasticsearch的SearchScroll接口可用于从索引中检索大量数据,或者是所有的数据,值得注意的是它不是为了用户进行实时请求,而是为了更快导出大量数据。同时该接口提供稳定的查询结果,不会因为用户一直在更新数据导致查询结果集合重复或缺失。典型场景如索引重建、将符合某一个条件的所有的数据全部导出来然后交给计算平台进行分析处理。SearchScroll支持多slice进行请求,在客户端以多并发的方式进行查询,导出速度可以更快。
一、为什么需要SearchScroll
Search接口的功能已经足够丰富,那么为什么还需要SearchScroll?原因就是Search接口的速度不够快和结果不够稳定。
1.1 from和size
Search接口进行翻页的方式主要有两种,一是size+from的翻页方式,这种翻页方式存在很大的性能瓶颈,时间复杂度O(n),空间复杂度O(n)。
其每次查询都需要从第1页翻到第n页,但是只有第n页的数据需要返回给用户。那么之前n-1页都是做的无用功。如果翻的更深,那么消耗的系统资源更是翻倍增长,很容易出现OOM,系统各项指标出现异常。
举个例子,假设每个文档在协调节点进行merge的ScoreDoc需要16字节,那么翻到一亿条时候,需要1.6G的内存,如果多来几个并发,普通用户的计算机根本扛不住这么大的内存开销。因此,很多产品在功能上直接禁止用户深度翻页来避免这种技术难题。
1.2 SearchAfter
Search接口另一种翻页方式是SearchAfter,时间复杂度O(n),空间复杂度O(1)。
SearchAfter是一种动态指针的技术,每次查询都会携带上一次的排序值,这样下次取结果只需要从上次的位点继续扫数据,前提条件也是该字段是数值类型且设置了docValue。
举个例子,假设”val_1”是数值类型的字段,然后使用Search接口查询时候添加Sort(“val_1”),那么response中可以拿到最后一条数据的”val_1”的值,也就是response中sort字段的值,然后下次查询将该值放在query中的searchAfter参数中,下次查询就可以在上一次结果之后继续查询,如此反复,最后可以翻页很深,内存消耗相比size+from的方式降低了数倍。
该方式效果类似于我们直接在bool查询中主动加一个rangeFilter,可以达到类似的效果。表面看这种方案能将查询速度降到O(1)的复杂度,实际上其内部还是会扫sort字段的docValue,翻页越深,则扫docValve越多,因此复杂度和翻页深度成正比,越往后查询越慢,但是相比size+from的方式,至少可以完成深度翻页的任务,不至于OOM,速度勉强可以接受。SearchAfter的翻页方式在性能上有了质的提升,但是其限制了用户只能一页一页往后翻,无法跳页,因此很多产品在功能设计时候是不允许跳页的,只能一页一页往后翻,也是有一定的技术原因的。
1.3 SearchScroll
Search接口在使用SearchAfter后,相比size+from的翻页方式,翻页性能有质的提升,但是和SearchScroll相比,性能逊色很多,用户需要获取的数据越多,翻的越深,则差别越大。
在查询性能上,SearchScroll的翻页方式,时间复杂度O(1),空间复杂度O(1)。SearchScroll能够以恒定的速度翻页获取完所有数据,而采用SearchAfter的方式获取数据会随翻页深度增大而吞吐能力大幅下降。在我们的单机单shard 2亿数据测试中,采用SearchScroll方式能够以每次50ms延时稳定获取完2亿数据,而SearchAfter深度翻页到千万级条数据后查询延时就到了秒级别,查询速度线性下降。
在吞吐能力上,SearchScroll请求天然支持多并发方式查询。在Elasticsearch中把每个并发称之为一个Slice(分片),Elasticsearch内部对用户的请求进行分片,分片越多则速度越快,拉取数据的速度翻倍提高。当然之前的普通的Search查询方式也可以并发访问,但是需要用户将Search请求的query进行拆分,比如原来是获取1年的数据,那么可以将query拆分为12个,一个月一个请求,体现在查询语句里就是将月份条件添加到query语句中的filter中来保证仅返回某一个月的数据。Search查询通过拆分query有时候可以达到类似的并发效果,来加速Search查询,但是有些query语句是难以拆分的,使用成本较高,因此直接利用SearchScroll让Elasticsearch帮助我们进行并发拆分是一个不错的选择。
在结果稳定性上,SearchScroll由于会“打snapshot”,context会保留目前的segments,后续写入的数据都是感知不到的,因此不会造成查到的结果中存在重复数据或者缺失数据。在批量导数据等要求结果稳定的场景下,SearchScroll特别适用。从另一个角度讲,对需要稳定结果的用户来说是件好事,但是会导致该部分segments暂时无法被merge,也会占用一些操作系统的文件句柄,因此需要留意系统的这些方面的指标,确保Elasticsearch系统稳定运行。
二、原理剖析
2.1 流程剖析
使用SearchScroll功能,用户的请求主要分为两个阶段,我们将第一阶段称之为Search阶段,第二阶段称之为Scroll阶段。如下图所示。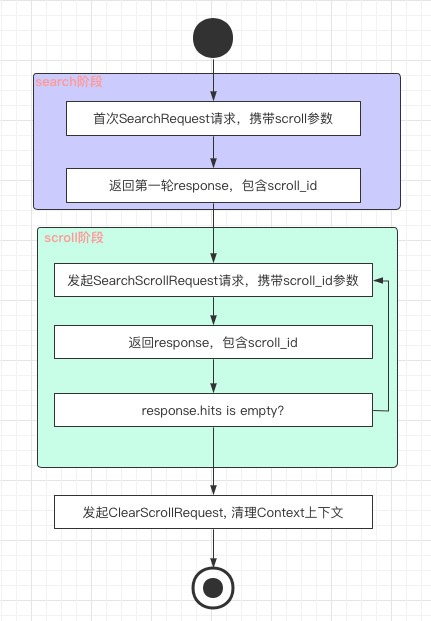
其中第一阶段和传统的Search请求流程几乎一致,在Search流程的基础上进行了一些额外的特殊处理,比如Slice并发处理、Context上下文保留、Response中返回scroll_id、记录本次的游标地址方便下一次scroll请求继续获取数据等等。
第二阶段Scroll请求则大大简化,Search中的许多流程都不要再次进行,仅需要执行query、fetch、response三个阶段。而完整的search请求包含rewrite、can_match、dfs、query、fetch、dfs_query、expand、response等复杂的流程,因此其在es的代码实现中也没有严格遵循上述的流程流转的框架,也没有SearchPhaseContext等context实现。
2.1.1 Search阶段
CreateContext
创建SearchContex后,如果是scroll请求,则在searchContext中设置ScrollContext。ScrollContext中主要包含context的有效时间、上一次访问了哪个文档lastEmittedDoc(即游标位置)等信息。具体如下:
private Map<String, Object> context = null;public long totalHits = -1;public float maxScore;public ScoreDoc lastEmittedDoc;public Scroll scroll;
queryPhase.preProcess中会处理sliceFilter,判断该slice请求到达哪个shard。这里是进行slice并发请求核心处理逻辑,简单来说根据slice的id和shard_id是否匹配来判断是否在本shard上进行请求。然后将query进行重写,将用户原有的query放入到boolQuery的must中,slice构建出的filter放入boolQuery的filter中。
SearchScroll通过SearchContext保留上下文。每个context都有一个id,它是单机原子自增的,后续如果还需要使用则可以根据id拿到该context。context会自动清理,默认5分钟的keepAlive,新来的请求会刷新keepAlive,或者通过clearScroll来主动清除该context。
LoadOrExecuteQueryPhase
SearchScroll请求结果永远不会被cache,判断条件很简单,如果请求中携带了scroll参数,这一步会直接跳过。
QueryPhase.execute
该步骤为search查询的核心逻辑,search请求携带scroll和不携带scroll在这里几乎是一模一样的,具体参考上述链接的文章介绍。
FetchSearchPhase
fetch阶段,需要将query阶段返回的doc_id进行fetch其doc内容。
如果是scroll类型的search请求,则需要buildScrollId,scrollid中保存了一个数组,每个元素包含2个值:
nodeid,下次请求知道上一次请求在哪个shard上进行的。RequestId(ContextId),找到上一次请求对应的searchContext,方便进行下一次请求。
fetch结束的时候,需要将本次请求发给用户的最后一个元素的排序字段的值的大小保留下来,这个值是哪个字段取决于search请求中的sort设置了什么值。elasticsearch推荐使用_doc进行排序,这样性能最好。当获取到最后一个文档后,需要更新到searchContext中的ScrollContext的lastEmittedDoc值,这样下次请求就知道从哪里开始进行搜索了。
总结一下Search和Scroll的核心区别,主要是在query阶段需要处理并发的scroll请求(slice),fetch阶段需要得到本次返回给用户的最后一个文档lastEmittedDoc,然后告知data节点的context,这样下次请求就可以继续从上一个记录点进行搜索。
2.1.2 Scroll阶段
该阶段是在elasticsearch中是通过调用SearchScrollRequest发起请求,其参数主要有两个:
- scroll_id,方便在data节点上找到对应的context,继续上一次的请求。
- scroll失效时间,即刷新context的aliveTime,aliveTime过后该context失效。这个参数一般使用不多,使用默认值即可。
该阶段从api层面来看已经区别很大,一个是SearchRequest,另一个是SearchScrollRequest。search的流程上面主要是分析了一些不同的地方,接下来讲一下scroll的流程,只有query、fetch、response三个phase,其中response仅仅是拼装和返回数据,这里略过。
query
- 在协调节点上,将scroll_id进行parse,得到本次请求的目标shard和对应shard上的searchContext的id,将这两个参数通过InternalScrollSearchRequest请求转发到data节点上。
- 在data节点上,从内存中获取到对应的searchContext,即获取到了用户原来的query和上次游标信息lastEmittedDoc。然后再执行QueryPhase.execute时,会将query进行改写,如下代码所示。改写后将lastEmittedDoc放入boolQuery的filter中,这就是为什么scroll请求可以知道下次请求的数据应该从哪里开始。并且这个MinDocQuery的性能是比传统的rangeQuery要快很多的,它仅仅匹配 >=after.doc + 1的文档,可以直接跳过很多无效的扫描。
final ScoreDoc after = scrollContext.lastEmittedDoc;if (after != null) {BooleanQuery bq = new BooleanQuery.Builder().add(query, BooleanClause.Occur.MUST).add(new MinDocQuery(after.doc + 1), BooleanClause.Occur.FILTER).build();query = bq;}// ... and stop collecting after ${size} matchessearchContext.terminateAfter(searchContext.size());searchContext.trackTotalHits(false);
fetch
在协调节点上,将各个shard返回的数据进行排序,然后将用户想要的size个数据进行fetch,这些数据同样需要得到lastEmittedDoc, 与Search阶段一致,都是通过ShardFetchRequest告知data节点上searchContext本次的lastEmittedDoc,并更新在context中供下次查询使用。
在data节点上,如果传入的request.lastEmittedDoc不为空,则更新searchContext中的lastEmittedDoc。
2.2 SearchScroll的并发原理介绍
SearchScroll天然支持基于shard的并发查询,而Search接口想要支持并发查询,需要将query进行拆分,虽然也能进行并发查询,但是其背后浪费的集群资源相对较多。
首先从API使用方式上介绍SearchScroll的并发,我们用一个简单的例子做说明。Slice参数是SearchScroll控制并发切分的参数,id、max是其最主要的两个参数,id取值为[0,max),max取值没有特别的限制,一般不超过1024,但是推荐max取值为小于等于索引shard的个数。id、max两个参数决定了后续在data节点如何检索数据。
GET /bar/_search?scroll=1m{"slice": {"id": 0,"max": 128},"query": {"match" : {"title" : "foo"}}}
SearchScroll并发获取数据只需要我们多个线程调用Elasticsearch的接口即可,然后请求到达data节点后,开始处理slice,如果该slice不应该查询本shard,则直接返回一个MatchNoDocsQuery这样的filter,然后本shard上的查询会迅速得到执行。
如果并发数等于shard数,就相当于一个并发真实的查询了一个shard。而用Search接口拆query后进行并发查询,每个并发还是会访问所有的shard在所有数据上进行查询,浪费集群的资源。
SearchScroll如何判定一个slice是否应该查询一个节点上的shard,只需要进行简单的hash值判断即可。有4个参数id、max、shardID、numShards(索引shard个数)决定了是否会进行MatchNoDocsQuery,具体规则如下:
- 当max>=numShards,如果 id%numShards!=shardID,则返回MatchNoDocsQuery
- 当max<numShards,如果 id!=shardId%max,则返回MatchNoDocsQuery
为什么推荐SearchScroll的max取值小于等于索引shard个数?简单说明就是并发数大于索引shard数后,需要将一个shard切分为多份来给多个slice使用,而切分单个shard是需要消耗一些资源的,会造成首次查询较慢,且有内存溢出风险。
单shard内切分slice的两种方式总结:
- TermsSliceQuery耗内存,可能会造成jvm内存紧张;DocValuesSliceQuery不占用内存,但是依赖读DocValue,因此速度没有TermsSliceQuery快。
- TermsSliceQuery真实的遍历了_uid的值,而DocValuesSliceQuery遍历了doc_id序号,根据这个doc_id去取DocValue。
三、性能和稳定性优化改进
当前Elasticsearch在SearchScroll接口上有很多地方存在性能问题或者稳定性问题,我们对他们进行了一些优化和改进,让该接口性能更好和使用更佳。本节主要介绍的是我们在SearchScroll接口上做的一些优化的工作。
3.1 queryAndFetch
这个优化是Elasticsearch目前就有的,但是还有改进的空间。
当索引只有一个shard的时候,Elasticsearch能够启用该优化,这时候SearchScroll查询能够启用queryAndFetch查询策略,这样在协调节点上只需要一步queryAndFetch操作就可以从data节点上拿到数据,而默认的查询策略queryThenFetch需要经历一个两阶段操作。如图所示,queryAndFetch这种查询方式可以节省一次网络开销,查询时间缩短。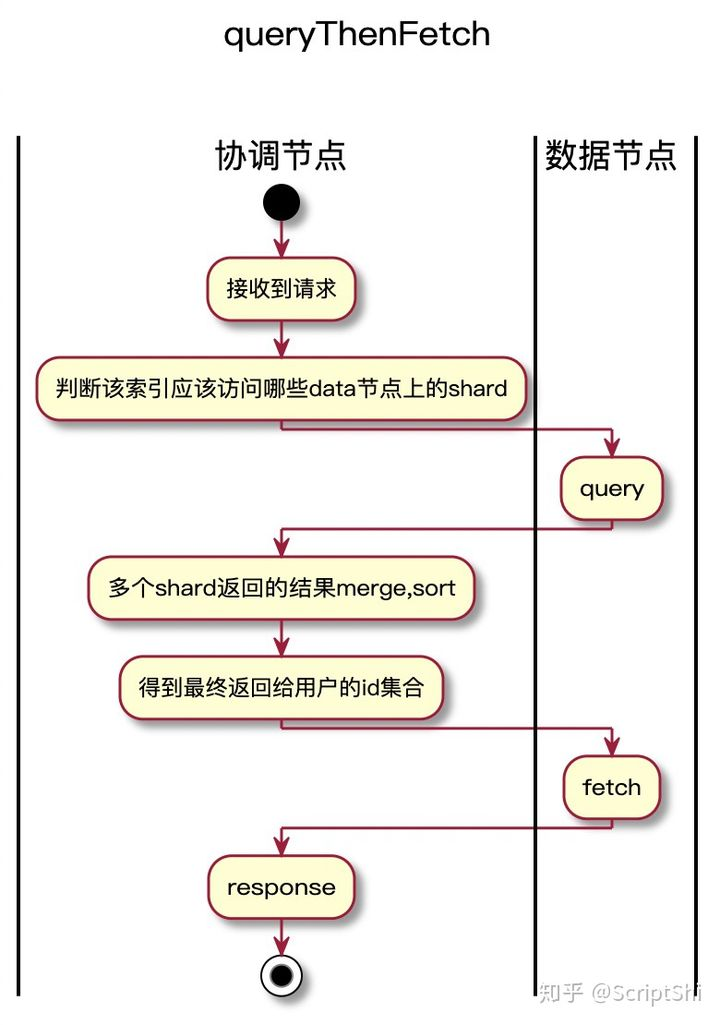
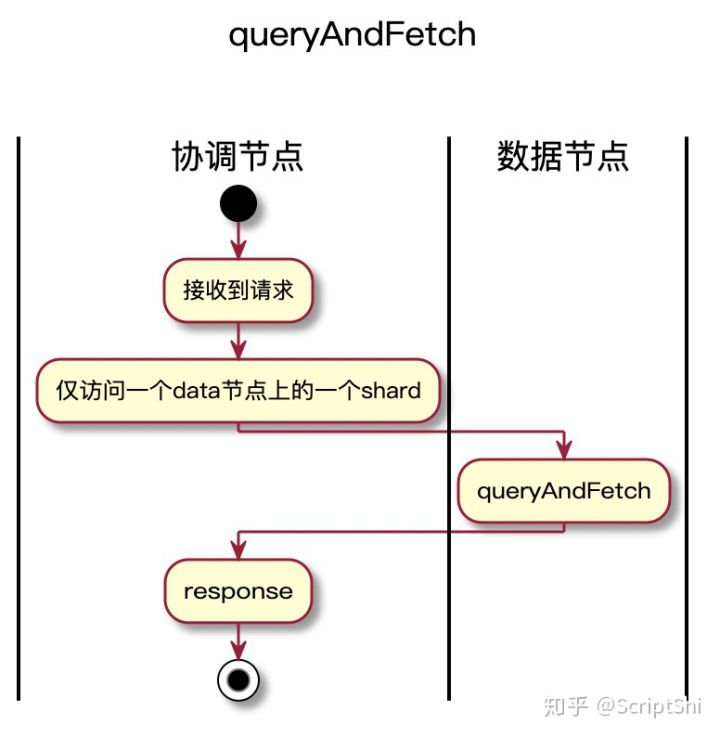
当用户的shard数不等于1时候,Elasticsearch没有任何优化。但是,当用户的SearchScroll的max和shard数一致的时候,也是可以开启queryAndFetch优化的,因为一个并发仅仅在一个shard上真正的执行。我们将这些case也进行了优化,在多并发时候也能进行queryAndFetch优化,节省CPU、网络、内存等资源消耗,提高整体吞吐率。
3.2 查询剪枝
SearchScroll多并发场景下,请求刚到协调节点上,会查询出每个shard在哪些节点上,然后将请求转发到这些节点上。当查询请求到达data节点上,根据slice参数重写query时候,会判断该shard应不应该被当前slice进行查询。主要判断逻辑本文上述章节已经介绍。如果该slice不应该查询本shard,则直接返回一个MatchNoDocsQuery这样的filter,相当于该请求在data节点上浪费了一次查询。虽然加了MatchNoDocsQuery的原请求执行速度很快,但是会占用线程池浪费一些cpu时间,而且会浪费线程池的队列空间。
假如用户有512个shard,且用户用512个并发进行访问。需要注意的是,每个并发请求都会转发到所有的shard上,因此在集群的data节点上瞬间会有512*512=26万个任务需要执行,其中仅有512个任务是真正需要执行的,其它的请求都是在浪费集群资源。默认情况下单个节点查询线程池队列是1000,一般集群也没有那么多data节点,难支撑26万个请求。
针对该问题,我们将slice的MatchNoDocsQuery的filter过滤提前到协调节点,不需要再转发这些无用的请求。在协调节点上会计算哪些shard需要真正执行查询任务,因此我们将MatchNoDocsQuery的filter逻辑前置,达到查询剪枝的目的。
除此之外,在并发数和shard数不相等时候,一个并发请求可能会发送到n个shard上。假如用户需要返回m条数据,会向n个shard各请求m条数据,然后在协调节点需要将n_m条数据进行排序,选出前m条进行fetch然后再返回给用户,这样相当于浪费了(n-1)_m条数据的计算和io资源。因此可以仅从一个shard上获取数据,按顺序将所有shard上的数据拉取结束,在挨个拉取的过程中,还要保持之前在各个shard创建的searchContext,避免SearchContext失效。
查询剪枝后,并发访问方式下,scroll_id也将变得特别短。之前用户拿到的scroll_id特别长,跟用户的shard数成正比,当shard数较多时候,scroll_id也特别长,在传输过程和scroll_id编码解析过程中都会浪费一些系统资源。
3.2 shard选择策略
一个索引通常会有很多副本,当请求到达协调节点后,请求应该转发到哪个副本呢?
默认情况下,采用的是随机策略,将所有副本打乱随机拿出一个副本即可。默认的随机策略能够将请求均匀地打散在每一个shard上。假如我们的data节点处理能力不一致,或者由于一些原因造成某些机器负载较高,那么采用随机策略可能不太适用。Elasticsearch提供了一个自适应的选择策略,其能够根据当前的每个节点的状态来选择最佳的副本。参考因素有如下源码列出的,包括节点的client数、队列长度、响应时间、服务时间等。因此,通过”cluster.routing.use_adaptive_replica_selection”参数将副本自适应选择策略打开,能够发挥每一台机器的能力,请求延时能够有效降低,每台机器的负载能够更加均匀。
针对SearchScroll请求,如果是频率较高的拉取不同索引的少量数据,那么副本自适应选择策略可以满足需求。但是针对一些大索引拉取数据的case则不再适用。假如某一个索引有512个shard,且需要拉取的数据较多,那么集群资源可能仅够该索引大量拉取,不会再有其他请求过来。当512个并发请求一下子进来协调节点,这时候协调节点会拉取每个data节点的状态来决定把请求发往哪个副本。但是512个并发是一起过来的,因此拿到的nodeStats可能是一致的,会造请求发往相同的data节点,造成一些data节点负载较高,而其他data节点负载较低。SearchScroll的首轮请求会决定了后续请求在哪个data节点执行,因此后续所有请求和首轮一样,造成各个data节点负载不一致。
针对这种情况,如果索引shard较多,且用户是SearchScroll请求,则需要不再使用副本自适应选择策略。
3.3 请求支持重试
自Elasticsearch支持SearchScroll以来,scroll_id都是不变的,所有的游标位点信息都是维护在data节点的searchContext中。scroll_id仅仅编码了node_id和context_id。协调节点根据node_id将请求转发到对应的data节点,在data节点上根据context_id拿到searchContext,最后拿到所有相关的具体信息。
当前scroll_id是不支持重试的,强行进行重试可能会造成数据丢失,因此遇到失败则需要全部重新拉取。比如用户有100条数据需要拉取,每次拉10条。当拉取20~30条时候,Elasticsearch已经拿到数据,代表着data节点的游标位点信息已经更新,但是用户网络发生问题,没有取到这10条数据。这时候用户忽略网络异常而继续请求的话,会拿到30~40的10条数据,而20~30的10条数据再也拿不到,造成读取数据丢失。针对这一问题,我们将searchContext中维护的last_emitted_doc编码到scroll_id中,这样在部分场景失败下就可以进行重试。
之前scroll_id的编码是为query_type + array_size + array[context_id + node_id],我们优化后的scroll_id为增加了version、index_name、last_emitted_doc等信息:
- version字段是为了以后做版本兼容使用,当前的scroll_id并没有版本的概念,因此版本兼容难做。
- index_name是索引的名字。虽然该字段对查询没有任何用处,但是在stats监控中需要用到。之前我们仅能统计SearchScroll的整个集群或者Node级别的监控,现在拿到index_name后,可以做到索引级别更细粒度的监控,比如拿到某一个索引Scroll阶段的query、merge、sort、fetch等各项监控信息。
- last_emitted_doc是新增的字段,在Elasticsearch中是ScoreDoc.java,主要编码的是doc和score两个字段。如果ScoreDoc是FieldDoc子类型,则还会编码fields。
scroll_id中编码last_emitted_doc后,用户的每次请求我们都能拿到当前的游标位点信息。在协调节点中,通过InternalScrollSearchRequest将该Request从协调节点发送到data节点,最终data节点不再从searchContext中拿last_emitted_doc,而是从InternalScrollSearchRequest拿到last_emitted_doc游标位点。
除此之外,当前Elasticsearch的SearchContext是不支持并发访问的,且没有给出任何提示,如果并发访问会造成拿到的数据错乱。因此,我们将SearchContext加了状态,如果访问一个正在被访问的SearchContext,则抛出冲突异常。

若有收获,就点个赞吧
0 人点赞
