一、Shard&Replica机制
1、shard&replica规则
(1)index包含多个shard
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
2、单node环境下创建index是什么样子的
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)集群status是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}}
3、2个node环境下replica shard是如何分配的
(1)replica shard分配:3个primary shard,3个replica shard,1 node
(2)primary —-> replica同步
(3)读请求:primary/replica
4、横向扩容过程,如何超出扩容极限,以及如何提升容错性
(1)primary&replica自动负载均衡,2台机器,其中6个shard(3 primary,3 replica)
(2)每个node有更少的shard,IO/CPU/Memory资源给每个shard分配更多,每个shard性能更好
(3)扩容的极限,6个shard(3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好
(4)超出扩容极限,动态修改replica数量,9个shard(3primary,6 replica),扩容到9台机器,比3台机器时,拥有3倍的读吞吐量
(5)3台机器下,9个shard(3 primary,6 replica),资源更少,但是容错性更好,最多容纳2台机器宕机,6个shard只能容纳1台机器宕机
(6)这里的这些知识点,你综合起来看,就是说,一方面告诉你扩容的原理,怎么扩容,怎么提升系统整体吞吐量;另一方面要考虑到系统的容错性,怎么保证提高容错性,让尽可能多的服务器宕机,保证数据不丢失
二、选举&容错
1、选举机制
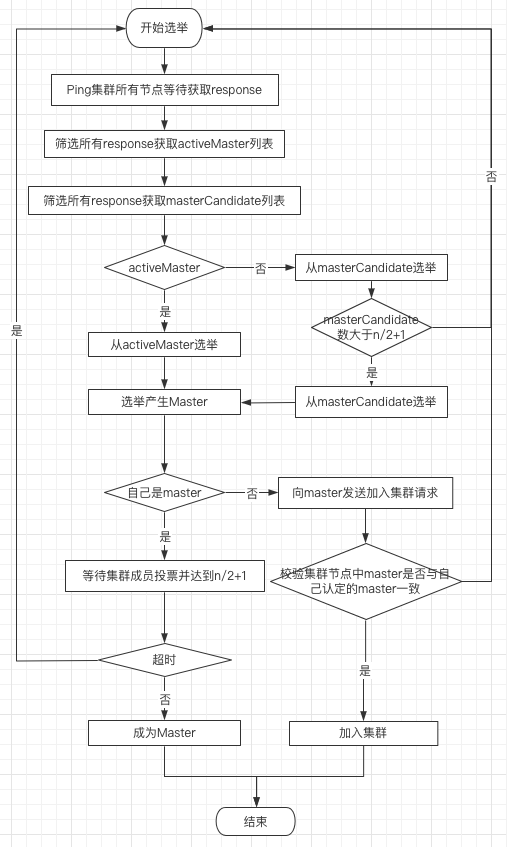
2、容错机制
1. master node宕机
2. 副本容错
新的master将丢失掉的primary shard的某个replica shard提升为primary shard。此时cluster status会变为yellow。因为primary shard全变成为active。但是少了一个replica shard,不是所有的replica shard都是active
3. 重启宕机node
重启故障的node,new master会将缺失副本都copy一份到该node上。而且该node会使用之前已有的shard数据,只是同步一下宕机之后发生的修改。cluster status变为green,因为primary shard和replica shard都齐全了。

若有收获,就点个赞吧
0 人点赞
