前言
在学习ES之前,下面三个问题是我想了解的问题的一部分;
- 它可以处理海量数据,但它是怎么存储这些数据的?
- 为什么Elasticsarch是近实时,而不是准实时;
- 为什么Elasticsearch能做到保证数据不丢失;
- Elasticsearch存储怎么让数据保存在磁盘上,而不是在内存上;
一、ES是怎么存储数据的
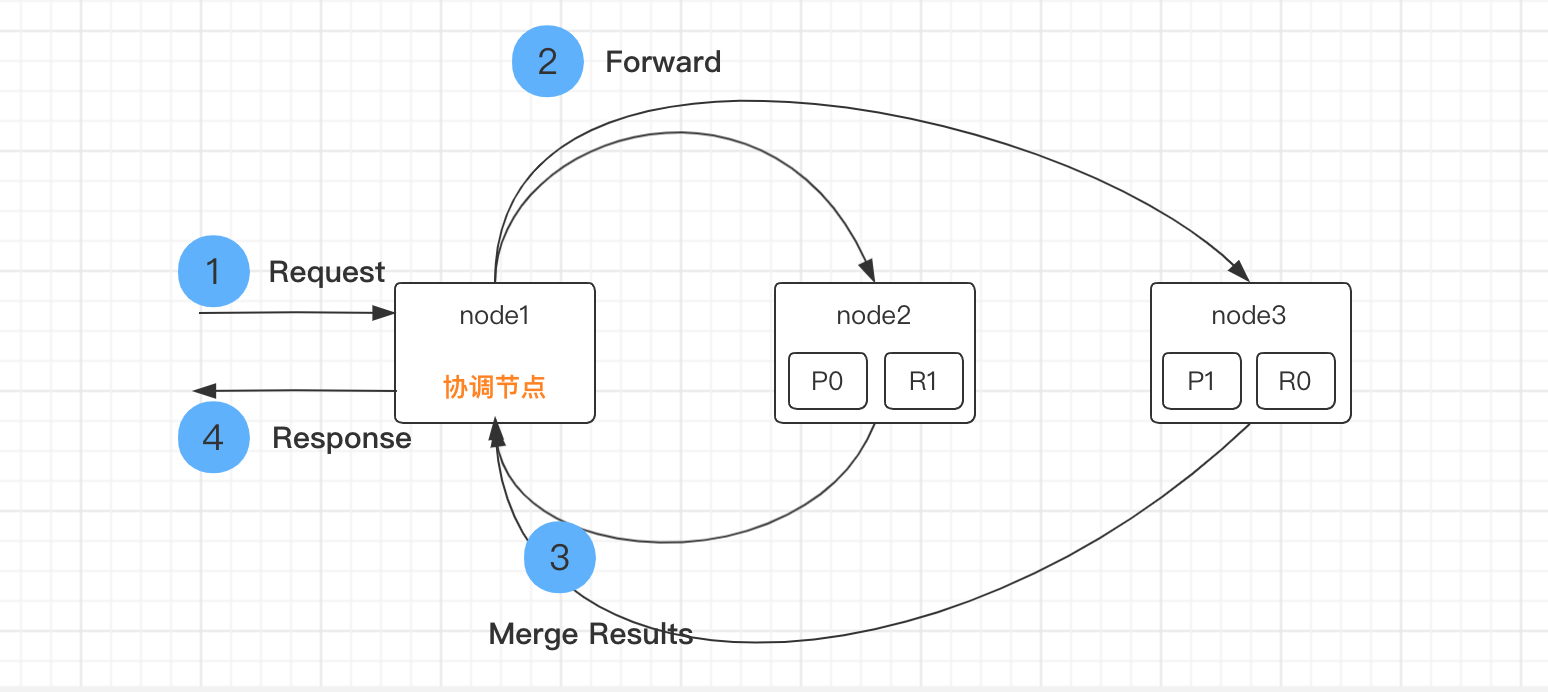
1.1 写入流程
1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
2)协调节点对document进行路由,将请求转发给对应的node(有primary shard)
3)实际的node上的primary shard处理请求,然后将数据同步到replica node
4)协调节点如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
1.2 写入的效率
考虑一个问题,写入的快吗?ES的怎么处理的?
我们都知道一个index是由若干个segment(片)组成,随着每个segment的不断增长,我们索引或者写入一条数据后可能要经过分钟级别的延迟。为什么有种这么大的延迟,这里面的瓶颈点主要在磁盘。
持久化一个segment需要fsync操作用来确保segment能够物理的被写入磁盘以真正的避免数据丢失,但是fsync操作比较耗时,所以它不能在每索引一条数据后就执行一次,如果那样索引和搜索的延迟都会非常之大。
所以这里需要一个更轻量级的处理方式,从而保证搜索的延迟更小。这就需要一个机制FileSystem Cache,所以在ES中新增的document会被收集到indexing buffer区后被重写成一个segment然后直接写入FileSystem Cache中,这个操作是非常轻量级的,相对耗时较少,之后经过一定的间隔或外部触发后才会被flush到磁盘上,这个操作非常耗时。但只要sengment文件被写入cache后,这个sengment就可以打开和查询,从而确保在短时间内就可以搜到,而不用执行一个full commit也就是fsync操作,这是一个非常轻量级的处理方式而且是可以高频次的被执行,而不会破坏es的性能。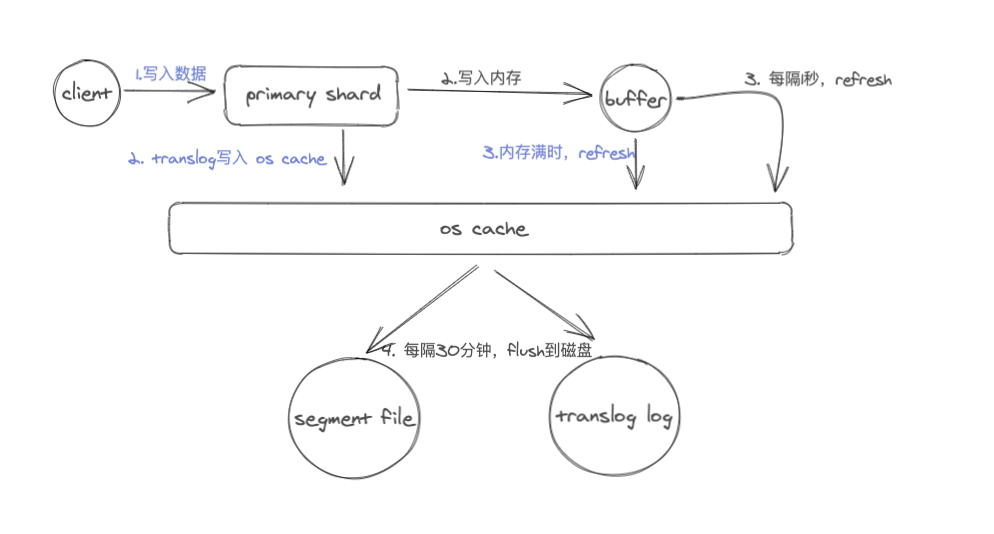
1.3 refresh和flush
1.3.1 refresh操作
相比于Lucene的提交操作,ES的refresh是相对轻量级的操作。先将index-buffer中文档(document)生成的segment写到文件系统之中,这样避免了比较损耗性能io操作,又可以使搜索可见。
默认1s钟刷新一次,所以说ES是近实时的搜索引擎,不是准实时。需要结合自己的业务场景设置refresh频率值。调大了会优化索引速度。注意单位:s代表秒级。
POST /_refresh //刷新所有的索引POST /blogs/_refresh //刷新指定的索引PUT /my_logs //修改refresh间隔,如果短时间内需要索引大量的数据,可以优化索引的写入速度{"settings": {"refresh_interval": "30s"}}PUT /my_logs/_settings{ "refresh_interval": -1 } //禁用刷新机制,如果插入超大索引时,可以关闭refresh机制,等写入完毕后再重新打开,提升写入速度PUT /my_logs/_settings{ "refresh_interval": "1s" } //设置每秒刷新一次,谨慎只设置数字代表是毫秒
1.3.2 flush操作
新创建的document数据会先进入到index buffer之后,与此同时会将操作记录在translog之中,当发生refresh时translog中的操作记录并不会被清除,而是当数据从filesystem cache中被写入磁盘之后才会将translog中清空。
从filesystem cache写入磁盘的过程就是flush。
步骤1:当translog变得太大时 ,可以执行commit ponit操作。
步骤2:使用fsync刷新文件系统缓存,写入磁盘。
步骤3:旧缓冲区被清除。
1.3.3 写入持久化模型
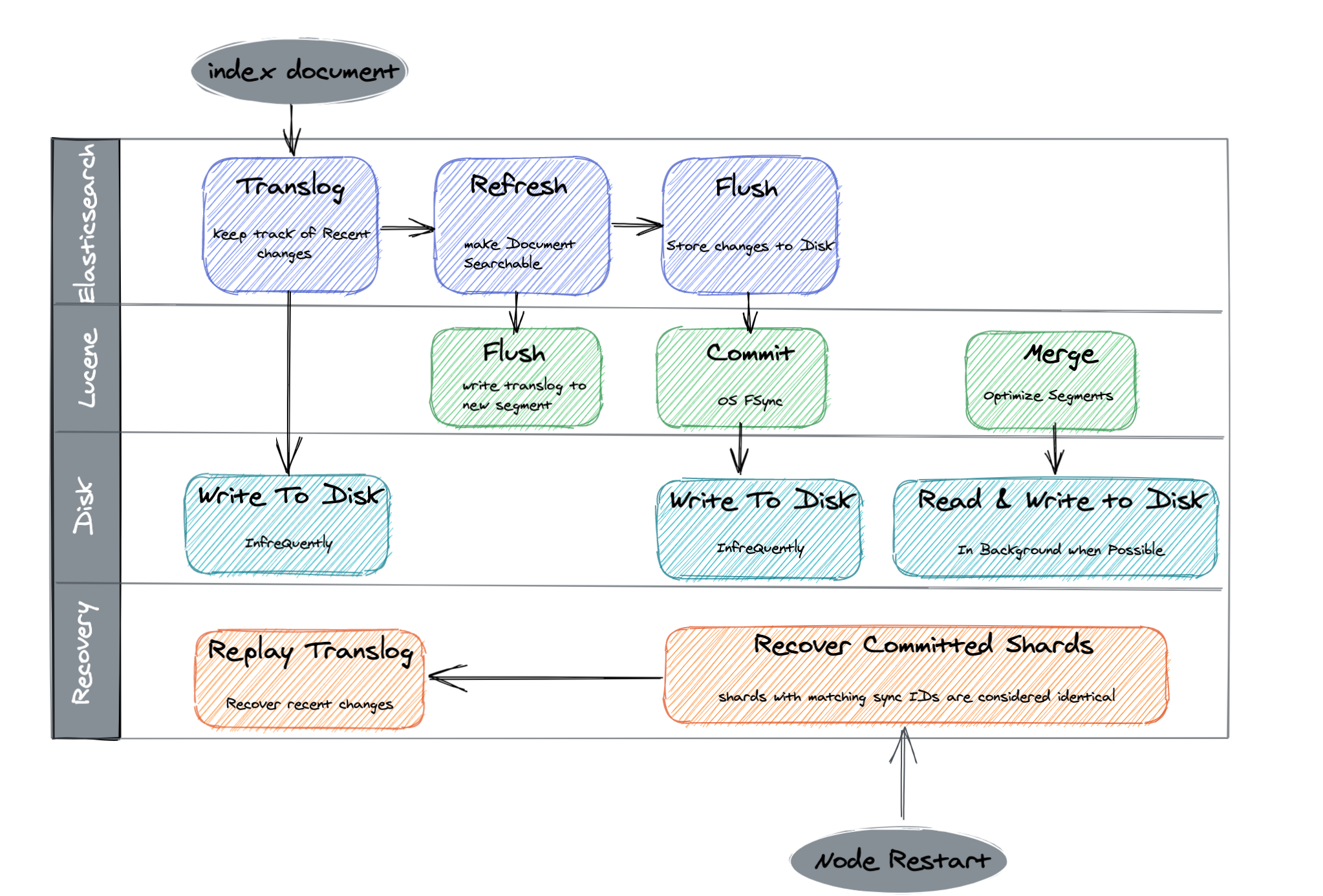
上图所示,从上往下看:
1、当新的文档写入后,写入 index buffer的同时会写入translog。
2、refresh操作使得写入文档搜索可见;
3、flush操作使得filesystem cache写入磁盘,以达到持久化的目的。
二、写优化
2.1 批量写入
目标:确定一个是bulk size。单线程,一个node,一个shard,进行压测。看看单线程最多一次性写多少条数据,性能是比较好的。
你如果要往es里面灌入数据的话,那么根据你的业务场景来,如果你的业务场景可以支持让你将一批数据聚合起来,一次性写入es,那么就尽量采用bulk的方式,每次批量写个几百条这样子。
bulk批量写入的性能比你一条一条写入大量的document的性能要好很多。但是如果要知道一个bulk请求最佳的大小,需要对单个es node的单个shard做压测。先bulk写入100个document,然后200个,400个,以此类推,每次都将bulk size加倍一次。如果bulk写入性能开始变平缓的时候,那么这个就是最佳的bulk大小。并不是bulk size越大越好,而是根据你的集群等环境具体要测试出来的,因为越大的bulk size会导致内存压力过大,因此最好一个请求不要发送超过10mb的数据量。
# 每3w条执行一次bulk插入bulkActions: 30000# 数据量达到10M后执行bulk插入bulkSizeMb: 10# 无论数据量多少,间隔30s执行一次bulkflushInterval: 30# 允许并发的bulk请求数concurrentRequests: 10
这里的具体配置值,可以根据观察集群状态,来逐步增加。对于高版本的es,可以通过x-pack的监控页面观察索引速度进行相应调整,如果es版本较低,可以使用推荐的rest api进行逻辑封装。
在低版本的es中,统计写入速度的思路是:写一个程序定时检查索引的数据量,来计算。python如下:
call_list = es.indices.stats(index=index)total = call_list['indices'][index]['total']['indexing']['index_total']
也可以隔几分钟用CURL来粗略统计单个索引的数据量大小。命令如下:
curl -XGET -uname:pwd'http://esip:port/_cat/count/index-name?v&format=json&pretty'
2.2 使用多线程
单线程发送bulk请求是无法最大化es集群写入的吞吐量的。如果要利用集群的所有资源,就需要使用多线程并发将数据bulk写入集群中。为了更好的利用集群的资源,这样多线程并发写入,可以减少每次底层磁盘fsync的次数和开销。首先对单个es节点的单个shard做压测,比如说,先是2个线程,然后是4个线程,然后是8个线程,16个,每次线程数量倍增。
一旦发现es返回了TOO_MANY_REQUESTS的错误,JavaClient也就是EsRejectedExecutionException。此时那么就说明es是说已经到了一个并发写入的最大瓶颈了,此时我们就知道最多只能支撑这么高的并发写入了。
通过对各个监控指标的观察,来判断是否能继续提高写入条数或增加线程数,从而达到最大吞吐量。
2.2.1 负载
负载值,一定程度上代表了CPU的繁忙程度,那我们如何来解读elasticsearch 监控页面的的负载值呢?
先从主机层面说起,在Linux系统中,uptime、w、top等命令都会有系统平均负载load average的输出
~ » uptime17:39 up 6 days, 7:19, 4 users, load averages: 1.61 1.88 2.11
其中load average的三个值,分别代表主机在1分钟、5分钟、15分钟内的一个负载情况。有人可能会疑惑,2.11是代表主机的负载在2.11%的意思吗,从我们跑的es集群情况来看,这显然不是负载很低的表现。其实在单个cpu的情况下,这个值是可以看做一个百分比的。比如负载为0.05,表明目前系统的负荷为5%。
而大部分情况下,我们的服务器一般都是多个处理器,每个处理器内部会包含多个cpu核心,一个处理器也可能包含多个应用。所以这里负载显示的值,是和cpu的核心数有关,如果非要用百分比来表示系统负荷的话,可以用具体的负载值/服务器的总核心数,观察是否大于1。
总核心数查看的命令为:
# 查看内存信息cat /proc/meminfo# 查看CPU信息(型号)cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c# 查看物理CPU个数cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l# 查看每个物理CPU中core的个数(即核数)cat /proc/cpuinfo| grep "cpu cores"| uniq# 查看逻辑CPU的个数,如果不等于上面的cpu个数 * 每个cpu的核数,说明是开启了超线程cat /proc/cpuinfo| grep "processor"| wc -l# 总核数 = 物理CPU个数 X 物理CPU的核数# 总逻辑CPU数 = 物理CPU个数 X 物理CPU的核数 X 超线程数
2.3 增加refresh间隔
上边我们说过,默认的refresh间隔是1s,用index.refresh_interval参数可以设置,这样会其强迫es每秒中都将内存中的数据写入磁盘中,创建一个新的segment file。正是这个间隔,让我们每次写入数据后,1s以后才能看到。但是如果我们将这个间隔调大,比如30s,可以接受写入的数据30s后才看到,那么我们就可以获取更大的写入吞吐量,因为30s内都是写内存的,每隔30s才会创建一个segment file。
2.4 禁止refresh和replia
如果我们要一次性加载大批量的数据进es(迁移、数据更新等),可以先禁止refresh和replia复制,将index.refresh_interval设置为-1,将index.number_of_replicas设置为0即可。这可能会导致我们的数据丢失,因为没有refresh和replica机制了。但是不需要创建segment file,也不需要将数据replica复制到其他的replica shasrd上面去。此时写入的速度会非常快,一旦写完之后,可以将refresh和replica修改回正常的状态。
2.5 禁止swapping交换内存
如果要将es jvm内存交换到磁盘,再交换回内存,大量磁盘IO,性能很差
2.6 给filesystem cache更多的内存
filesystem cache被用来执行更多的IO操作,如果我们能给filesystem cache更多的内存资源,那么es的写入性能会好很多。
2.7 使用自动生成的id
如果我们要手动给es document设置一个id,那么es需要每次都去确认一下那个id是否存在,这个过程是比较耗费时间的。如果我们使用自动生成的id,那么es就可以跳过这个步骤,写入性能会更好。对于你的业务中的表id,可以作为es document的一个field。
2.8 用性能更好的硬件
我们可以给filesystem cache更多的内存,也可以使用SSD替代机械硬盘,避免使用NAS等网络存储,考虑使用RAID 0来条带化存储提升磁盘并行读写效率,等等。
2.9 index buffer
如果我们要进行非常重的高并发写入操作,那么最好将index buffer调大一些,indices.memory.index_buffer_size,这个可以调节大一些,设置的这个index buffer大小,是所有的shard公用的,但是如果除以shard数量以后,算出来平均每个shard可以使用的内存大小,一般建议,但是对于每个shard来说,最多给512mb,因为再大性能就没什么提升了。es会将这个设置作为每个shard共享的index buffer,那些特别活跃的shard会更多的使用这个buffer。默认这个参数的值是10%,也就是jvm heap的10%,如果我们给jvm heap分配10gb内存,那么这个index buffer就有1gb,对于两个shard共享来说,是足够的了。
三、遇到的问题
3.1 单台主机负载过高
同一个主机两个节点都是数据节点,并且分片分配不均匀,导致这个主机CPU使用率在98%左右,后面通过迁移分片的方式将负载降低。
3.2 数据时区差8小时问题
问题原因:elasticsearch 内部存储时间是按照UTC的标准时间存储的,而我本地是GMT+8时区,因此存储到es的时候需要将时间转成UTC来存储。
几个时间名词:
GMT:格林威治标准时间 UTC:世界协调时间 DST:夏日节约时间 CST:中国标准时间
其中GMT时间可以近似认为和UTC时间是相等的,但从精度上来说UTC时间更精确。其误差值必须保持在0.9秒以内
CST= GMT + 8 =UTC + 8
从上面可以看出来中国的时间是等于UTC时间+8小时,es默认存储时间的格式是UTC时间,如果我们查询es然后获取时间日期默认的数据,会发现跟当前的时间差8个小时,这其实是正常的,因为es默认存储是用的UTC时间,最容易见到的就是,我们使用logstash收集的日志,发送到es里面,然后通过head查询就能发现不一致,但是如果我们用kibana查询,就不会发现时区问题,为什么?
因为kibana已经处理时区问题了,所以在kibana的页面显示的时间是正确的。
此外在使用Java Client聚合查询日期的时候,需要注意时区问题,因为默认的es是按照UTC标准时区算的,所以不设置的聚合统计结果是不正确的。
Java代码如下:
SearchRequestBuilder search = client.prepareSearch("2020-11*").setTypes("log");DateHistogramBuilder dateagg = AggregationBuilders.dateHistogram("dateagg");//聚合时间字段dateagg.field("ctime");//按天聚合第一天的0点到第二天的0点dateagg.interval(DateHistogramInterval.DAY);//指定时区dateagg.timeZone("Asia/Shanghai");//默认都是从0点开始计算一天的dateagg.offset("+8h");search.addAggregation(dateagg);Histogram hs= search.get().getAggregations().get("dateagg");List<Histogram.Bucket> buckets = (List<Histogram.Bucket>) hs.getBuckets();//获取结果for(Histogram.Bucket bk:buckets){//下面的转化,也是因为默认是UTC的时间,所以我们要获取时间戳,自己转化System.out.println(new DateTime(Long.parseLong(bk.getKeyAsString()+"")).toString("yyyy-MM-dd HH:mm:ss") +" "+bk.getDocCount());}client.close();
对于读取字符串需要SimpleDateFormat转换的,默认的时区是GMT+8,format的时候需要设置时区
//读取字符串解析成date的时候用GMT+8:00//format成字符串时用GMT+0:00String dateString = "2020-12-05 10:25:34";SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");df.setTimeZone(TimeZone.getTimeZone("GMT+8:00"));Date date = df.parse(dateString);df.setTimeZone(TimeZone.getTimeZone("GMT+0:00"));dateString = df.format(date);//SimpleDateFormat设置时区以下三种写法,格式化后的时间是一样的SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");dateFormat.setTimeZone(TimeZone.getTimeZone("Etc/GMT-8"));System.out.println("方法一:" + dateFormat.format(new Date()));dateFormat.setTimeZone(TimeZone.getTimeZone("GMT+8:00"));System.out.println("方法二:" + dateFormat.format(new Date()));dateFormat.setTimeZone(TimeZone.getTimeZone("Asia/Shanghai"));System.out.println("方法三:" + dateFormat.format(new Date()));

若有收获,就点个赞吧
0 人点赞
