在 Elasticsearch选主流程源码分析 一文中提过ES为什么选择使用Bully算法,首先它是在分布式系统中,避免数据产生不一致的一种方案。这种比出现不一致后进行协调简便很多。
我们知道,分布式系统中有的各个节点的地位是均等的,谁都有可能被选择Leader(Leader/Flower)。这种区分 leader 的集群更好管理些。这样在写操作的时候都交给Leader去处理,然后由Leader再将数据同步给各个Flower上的副本。如果同时对多个分布式节点写数据,在比较各个节点的数据一致性上很复杂。在读的时候可以从Flower上读取,也可以从Leader上读取,分散下系统压力。而Bully就是一种分布式这种保障数据一致性的主从模式的一种算法。ES的选主和MongoDB副本集选主就是采用的Bully算法。
一、原理
选举原则:在所有活着的节点中,选取节点ID最大或者最小的节点为主节点。
节点角色:主节点和普通节点(活跃的)
消息类型:
- Election 消息,向节点发起选举的消息
- Alive 消息,节点对 Election 消息的应答
- Victory 消息,竞选成功的主节点向普通节点发送竞选成功的消息
选举过程
- 集群中每个活着的节点查找比自己ID大的节点,如果不存在则向其他节点发送Victory消息,表明自己为主节点。
- 如果存在比自己ID大的节点,则向这些节点发送Election消息,并等待响应。
- 如果在给定的时间内,没有收到这些节点回复的消息,则自己成为主节点,并向比自己ID小的节点发送Victory消息。
- 节点收到比自己ID小的节点发送的Election消息,则回复Alive消息。
拿现实生活举例,比如你们部门的领导不在了,调走了,然后大家都彼此相互了解(节点保存集群中所有节点的信息),每个人都对自己资质老的(id 比自己 id 大的)发起选举消息,意思是我选你当 Leader;如果自己资历最老对其他人说,我当老大(发起Election消息),当它发送竞选(Election)消息有返回后,如果有比自己资历还老的存在,那么自己选举就失败了;如果过一段时间,没有收到选举消息的回复,那说明我最大,我就可以对其他节点发送 victory 消息,宣告我当 leader 了。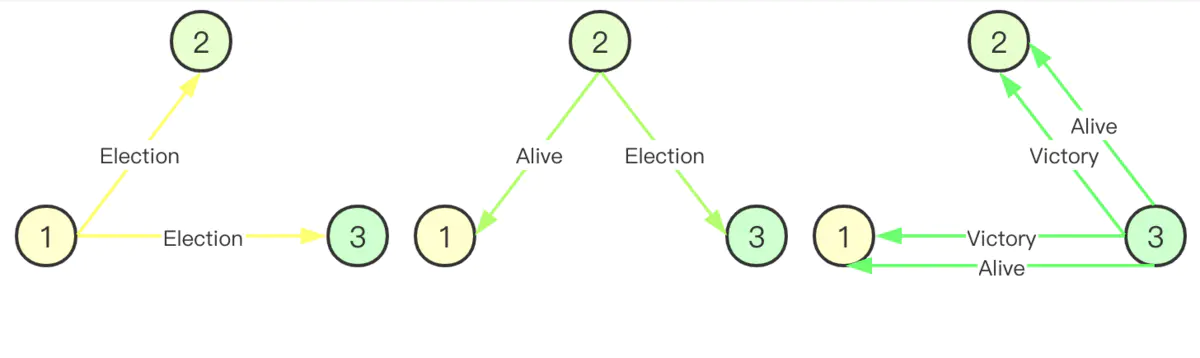
二、特点
Bully 算法又叫欺负算法,是因为直接粗暴的选择最大 id 作为 Leader。
优点:算法实现比较简单,直接通过比较 id 就可以抉择出谁是 Leader,由于简单,所以性能比较好,实现起来也比较容易;
缺点:集群的最大 id 机器不稳定,那么频繁掉线上线,可能会造成频繁选举,从而造成集群不稳定。
使用Bully算法需要考虑的问题 假死和脑裂 方案细节可以参考 Elasticsearch选主流程源码分析
三、集群中Leader节点挂掉具体过程
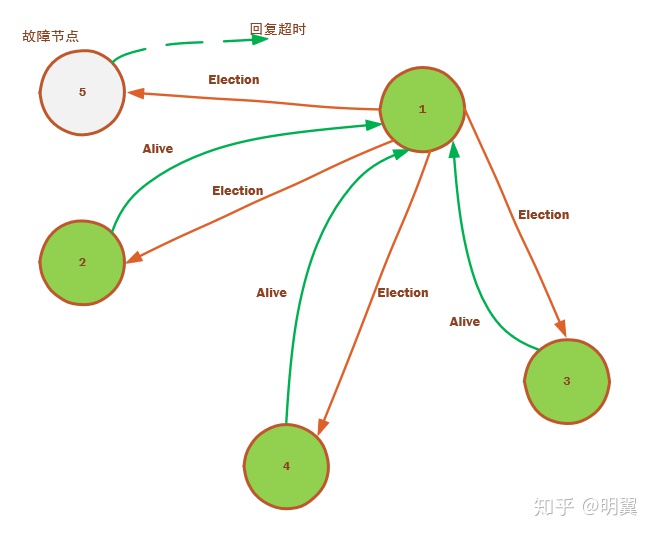
1) Leader 挂掉后,1 节点通过心跳探测消息发现,将发起新的选举,节点 1 向比它大的所有节点发起选举消息,也需要向节点 5 发送选举消息,因为节点 5 这时候可能已经活了,所以再发一次。 节点 2,3,4 回复 Alive 给 1 节点,5 节点由于网络故障回复 Alive 消息丢失。 1 有收到 Alive 的回复后,说明有比它资格老的还活着,老老实实等待选举完成的 Victory 消息吧。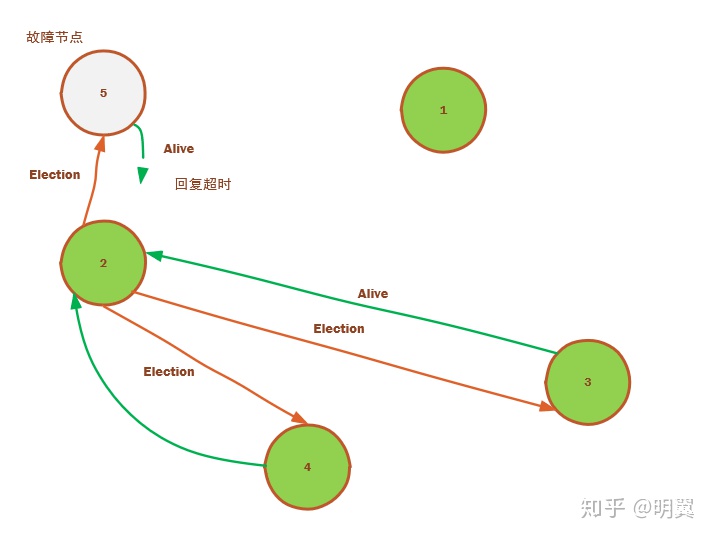
2)节点 2 也通过心跳探测发现 leader 5 挂了,这时候,通过向所有节点 ID 比它大的 3,4,5 发送选举消息,这时候,3 和 4 都回复 Alive 消息给 2,2 就知道自己不能当 leader,老老实实等待吧;同样道理节点 3 也会向节点 4 和节点 5 发送选举消息,同样收到节点 4 回复的 Alive 消息后就进入等待状态。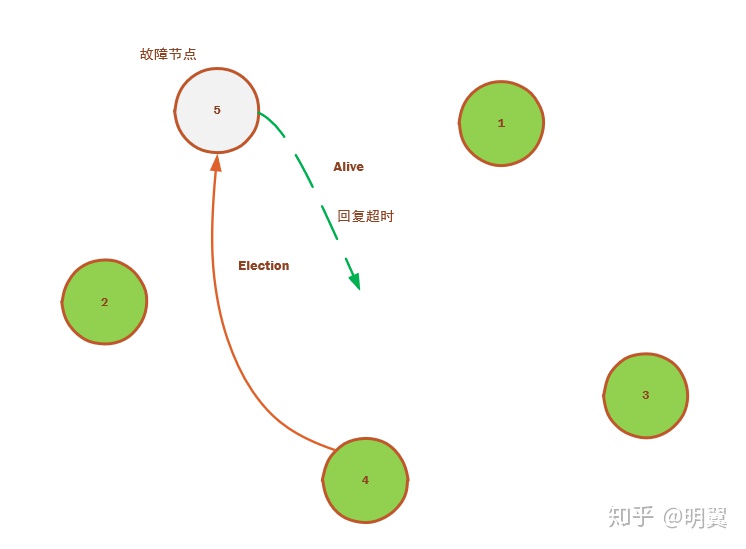
3)节点 4 也探测到超时后,发起选举消息给节点 5,接收选举回复消息超时,这时候由于节点 4 没有收到任何选举消息的恢复消息,那就认为自己是 leader,向其他所有节点发送 victory 消息,宣布主权,从而完成这轮选举。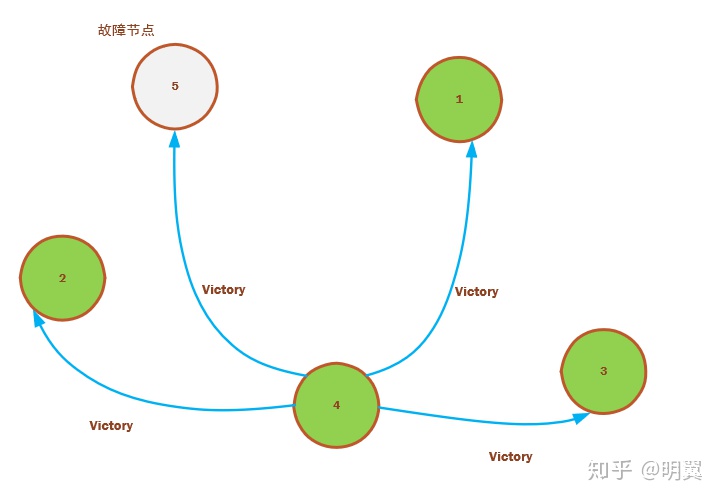

若有收获,就点个赞吧
0 人点赞
