一、数据仓库架构设计
1、数据架构
2、数据仓库分层(水平)
数据架构分三层:数据源落地区,数据仓库层,数据集市层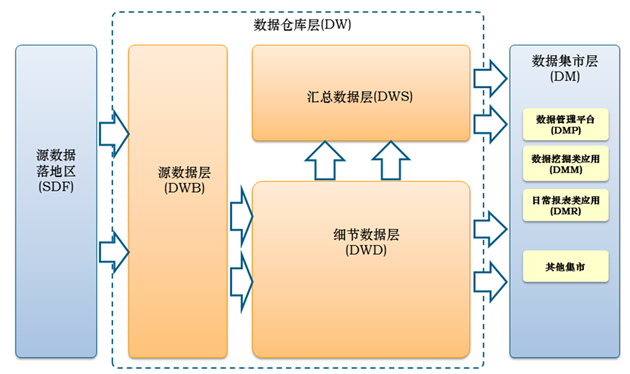
数据仓库又分为三层:源数据层,细节数据层,汇总数据层

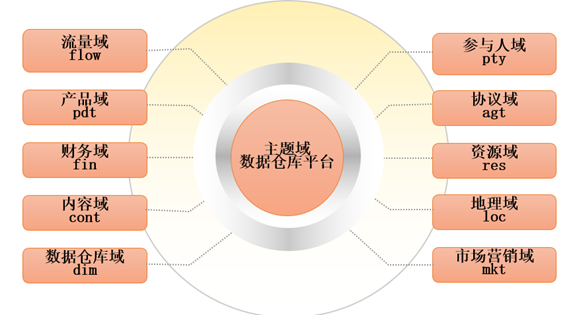
3、数据仓库分层(垂直)
二、数据仓库建模
1、定义
2、数据仓库建模的发展和意义
数据仓库的发展:
简单报表阶段(简单、单一)
数据集市阶段(多维度、业务场景化、按需定制性)
数据仓库阶段(全面、灵活、数据模型支撑、体系化)
数据建模的意义:
- 进行全面的业务梳理,改善流程。
- 建立全方位的数据视角,消灭信息孤岛和信息差异。
- 解决业务的变动和数据仓库的灵活性。
-
3、如何构建数据模型
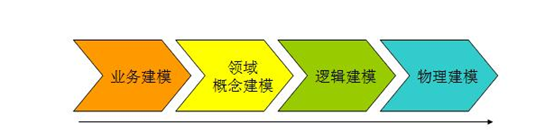
3.1 流程说明
业务建模:生成业务模型,主要解决业务层面的分解和程序化。
领域建模:生成领域模型,主要对业务模型进行抽象,生成领域概念模型。
逻辑建模:生成逻辑建模,将领域建模的概念实体以及记之间的关系进行数据库层的逻辑化。
物理建模,生成物理模型,主要解决,逻辑模型针对不同关系型数据库的物理化以及性能等一些具体的技术问题。3.2 目前的构建方法主要有三种:范式建模法,维度建模法,实体建模法。
3.2.1 范式建模法
范式建模法其实是我们在构建数据模型常用的方法之一。
- 主要解决关系型数据库得数据存储,我们在关系型数据库中的建模方法,大部分采用的是三范式建模法。
- 主要使用第3范式-3NF:属性不依赖于其它非主属性,即属于依赖于主键不能出现传递依赖。
优点:从关系型数据库角度出发,结合了业务系统的数据模型,计较方便实现。
缺点:建模方法限定在关系型数据库,在需要冗余的时候反而限制灵活性,特别是考虑到数据仓库的底层数据向数据集市的数据进行汇总时,需要灵活调整才能达到要求。
3.2.2 维度建模法
- 即按照事实表,维度表来构建数据仓库,即最被人广泛知晓的名字就是星型模式和雪花模式
- 星型建模法:维度表全部直接关联到事实表中,其形状类似星星。
- 雪花建模法:维度表并非全部关联到事实表中,存在一个或多个表没有直接关联到事实表中时,其形状类似雪花。
关于星型建模法和维度建模法的对比总结:
数据规范性:学花强于星型。
性能:雪花表关联较多计算性能上低于星型。
ETL开发:雪花关系多则关联多,代码量较复杂一些。而星型数据较集中,关联少,代码量会少一些。
实际使用,两者应用的均比较多,但星型略胜一筹。
关于维度建模法的使用建议:在数据架构设计中的细节数据层、汇总数据层、数据集市层等需要提升计算性能的时候,均可以使用,也是建模过程中逻辑建模阶段最常用的方法之一。多用于数据仓库建模。
3.2.3 实体建模法
源于哲学的一个流派。从哲学的意义上说,客观世界应该是可以细分的,客观世界应该可以分成由一个个实体,以及实体与实体之间的关系组成。
三、数据分析
1、定义
对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
2、专业术语
2.1 OLTP(联机事务处理)
- 其是数据库的主要应用,主要是执行基本日常的事务处理,如数据库记录的增删查改。
特点:实时性要求比较高,操作完立刻见到结果。
数据量不是很大。
交易一般是确定的。
高并发。总结:主要是指关系数据库中的增删查改,也是我们最常用操作,此为数据库的基础。
2.2 数据库事务ACID四大特征。
原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:一个事务可以封装状态改变(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。
隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。
如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。
持久性:在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。2.3 OLAP(联机分析处理)
其是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态的报表系统。
特点:实时性要求不是很高,数据量大,OLAP系统的重点是通过数据提供决策支持,所以查询一般都是动态,自定义的。
总结:其是数据仓库的核心部件。
所谓数据仓库是对于大量已经由OLTP形成的数据的一种分析型的数据库,用于处理商业智能(BI)、决策支持等重要的决策信息。
数据仓库是在数据库应用到一定程序之后而对历史数据的加工与分析,读取较多,更新较少。
OLTP发展到一定阶段后产生的OLAP。3、hive对数据分析的支持
3.1 产生背景
常规的qsl中,明细数据和聚合后的数据不能出现在同一张表上,而此类需求又常见。
3.2 函数分类
分析函数(不支持与windows子句连用)
- ntile:对数据进行分片排序。不均匀时以此增加前面的数量。
- row_number:排序,不关心相等情况。即1,2,3,4,5
- rank:排序,关心相等。即1,2,2,4,5
- dense_rank:排序:关心相等情况,但不留空位。即1,2,2,3,3,4,5
- 窗口函数
- lag:用于统计窗口内往上第n个值。lag(列名,n,默认值)
- lead:和lag相反(列名,n,默认值)
- first_value:取分组排序后,截止当前行第一个值。
- last_value:和first_value相反,取分组排序后,截止到当前最后一个值。注意:需要和rows between连用,否则会出错。
- over()开窗子句
- ROWS BETWEEN:即为window子句或称窗口子句,属于物理截取,即物理窗口,从行数上控制截取数据的大小多少。
- RANGE BETWEEN: 即为window子句或称窗口子句,属于逻辑截取,即逻辑窗口,从列值上控制窗口的大小多少。
- PRECEDING:window子句之往前
- FOLLOWING:window子句之往后
- CURRENT ROW:window子句之当前行
- UNBOUNDED:window子句之起点,UNBOUNDED PRECEDING 表示从前面的起点,UNBOUNDED FOLLOWING:表示到后面的终点。

若有收获,就点个赞吧
0 人点赞
