一、架构设计
1、架构设计图
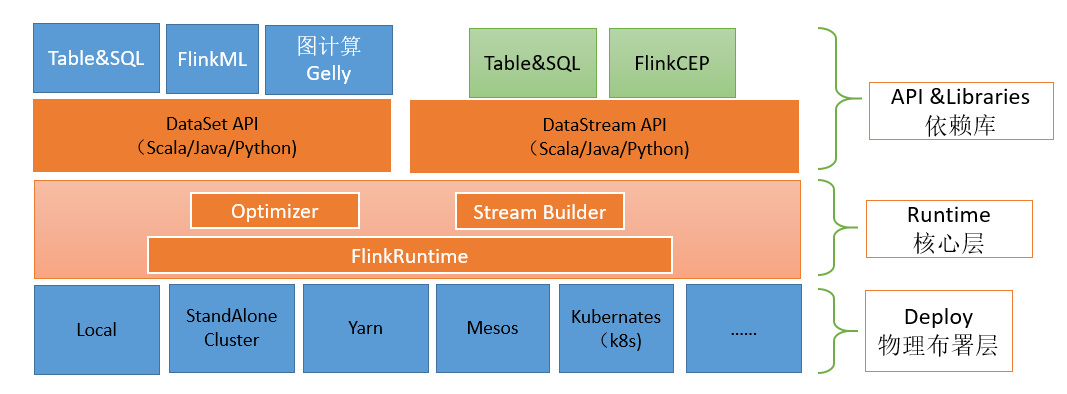
2、分层设计说明
- 物理部署层
- 负责解决Flink的部署模式问题。
- 支持多种部署模式:本地部署、集群部署、云(GCE、EC2)以及kubernates。
- 通过该层支持不同平台的部署用户可以根据自身需要选择适合的部署模式。
- Runtime核心层
- 是Flink分布式计算框架的核心实现层,对上层不同接口提供基础服务。
- 支持分布式Stream作业的执行,JobGroup到ExecutionGroup的映射转换及任务调度。
- 将DataStream和DataSet转成统一的可执行的TaskOperator,达到在流式计算引擎下同时处理批处理和流式计算的目的。
API层
集群的生命周期和资源隔离保证
-
2、各种模式分类
本地运行模式-local
- standalone模式-独立Flink集群
集群运行模式
本地运行模式
- 运行过程:一个机器启动多个进程来模拟分布式计算。
- 主要用于代码测试。
- standalone模式
- 运行过程:完全独立的Flink集群模式,没有比如yarn的资源管理平台,全部由flink搞定。
- 主要用于纯Flink计算的场景,较少用。
集群运行模式
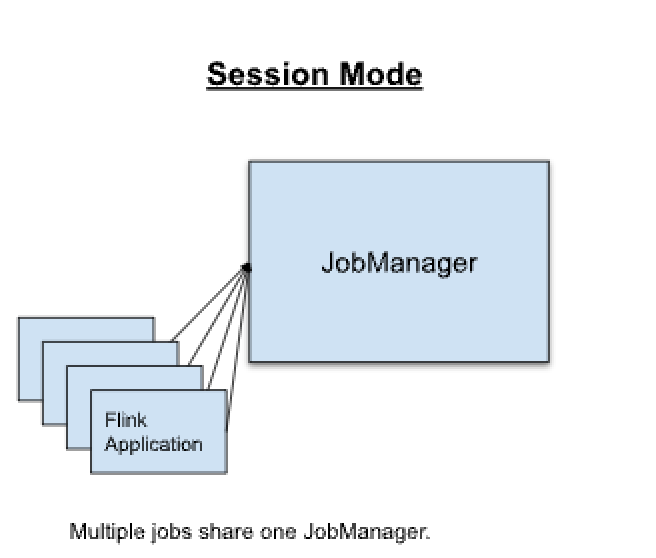
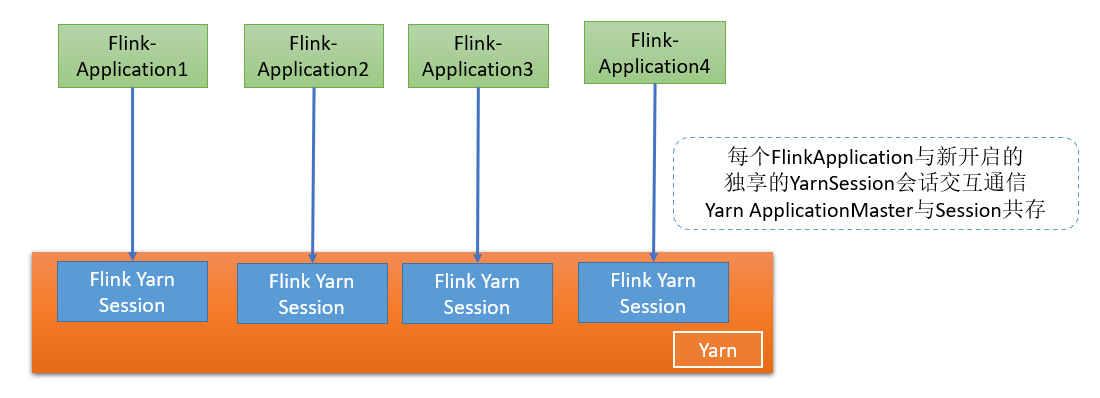
- Flink Session(会话模式)
- 集群的生命周期:在Flink Session集群中客户端连接到一个预先的,长期运行的集群中,可以接收多个多也提交,即使所有作业都运行结束也不会停止。一直到手动停止Session。因此FlinkSession的寿命不受任何作业影响。
- 资源隔离:由于所有作业都共享集群,所以在资源分配上存在一定的竞争。如果TaskManager崩溃,则在此上运行的所有作业都将失败,或者JobManager上发生错误将会影响集群中所有的作业。
- 注意事项:拥有一个实现启动的集群可以节约很多申请和启动资源的时间。适用于启动任务时间比较长但任务运行时间比较短的场景
- flink Session也被称为Session模式下的Flink集群
- 工作模式:
- 附加模式(默认)
- 客户端与flink集群相互同步。
- 客户端将flink集群提交给yarn,但客户保持运行,跟随集群的状态。
- 如果集群出错,客户端显示错误,如果客户端停止,也会通知集群通知。
- 分离模式
- 客户端与集群异步状态,客户端提交之后即可退出。
- 客户端将集群提交给yarn,客户端就返回。
- 需要再次调度yarn或者客户端来停止集群。
- 附加模式(默认)
- 工作流程特征说明:
- 多个FlinkJob向同一个Flink Session提交作业,它来管理所有作业。
- 官方流程示意图
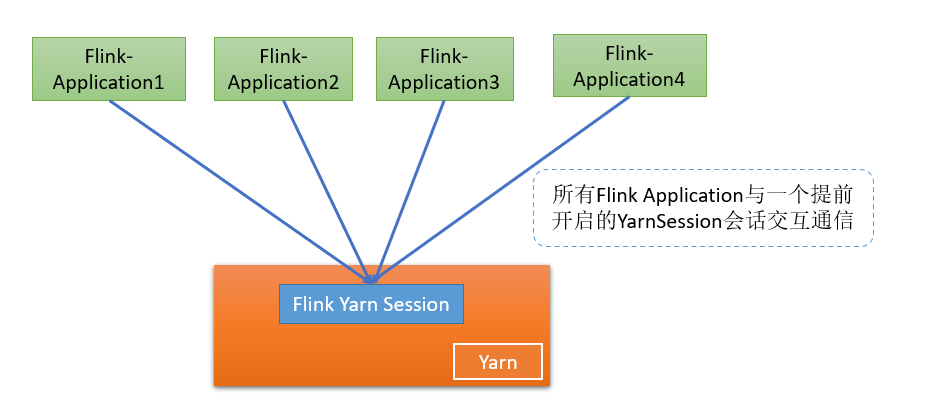
- 经典流程示意图
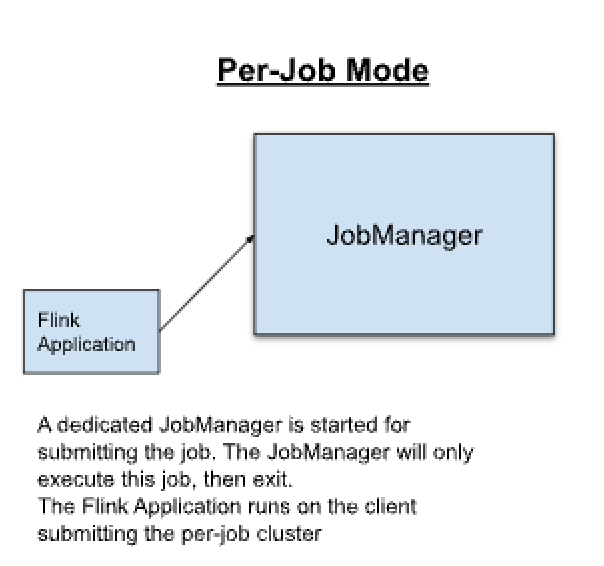
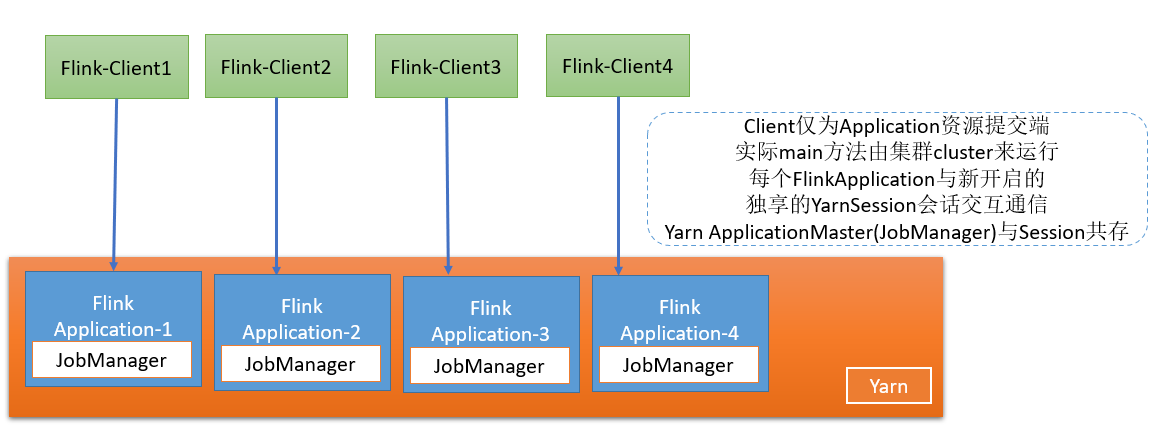
Flink Job集群(per-job集群)
- 集群生命周期:为每个提交的作业单独启动一个集群单独使用。在这里客户端首先从集群管理器请求资源启动JobManager然后将作业提交给这个进程中运行的Dispatcher。然后根据资源请求惰性分配TaskManager。完成后集群将被拆除。
- 资源隔离:Jobmanager中的致命错误在集群中只影响一个作业。
- 注意事项:其计算性能没有Session模式强,所以更适合长期运行、具有高稳定性并且对较长的启动时间不敏感的大型作业。
- Flink Job 集群也被称为Job模式下的Flink集群
- 工作流程特征:多个不同的作业分别向自己的session会话提交作业。
- 官方示意图
- 经典流程示意图
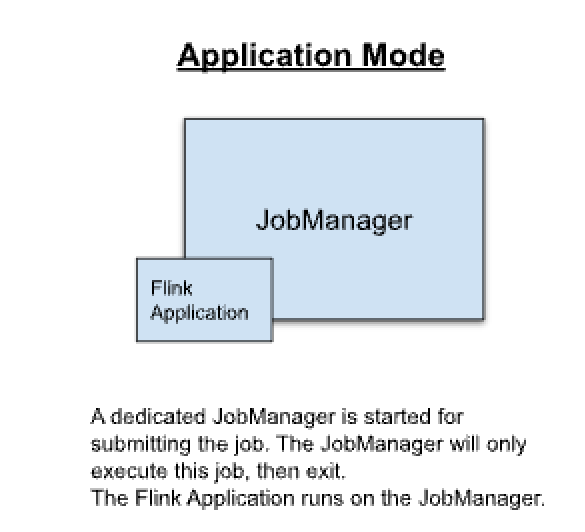
Flink Application集群
- 集群生命周期:
- main方法在集群上而不是在客户端运行。
- 提交作业是一个单步骤过程
- jar包和资源上传到hdfs。
- jobmanager去拉去对应的jar包和资源,如果存在HA就选举。。
- 由jobmanager调用main方法提取JobGrouph作为客户端与集群进行交互,知道作业完成。
- 如果一个main方法中有多个env.execute()/executeAsync()调用,会被视为同一个应用,在同一个集群上执行。
- 集群的寿命与flink应用程序寿命有关。
- 资源隔离:在 Flink Application 集群中,ResourceManager 和 Dispatcher 作用于单个的 Flink 应用程序,相比于 Flink Session 集群,它提供了更好的隔离。
- Flink Job集群可以看作是 Flink Application集群客户端运行的代替方案。
- 该模式为session和per-job的折中选择。
- 工作流程特征
- 相当于每个FlinkJob都有一套专用的服务角色进程。
- 官方示例图
- 经典工作流程示意图
- 集群生命周期:
- 总结
- Flink Session(会话模式)
运行时核心角色组成
- 由两种类型的进程组成,一个JobManager和一个或多个taskManager
- 工作流程图
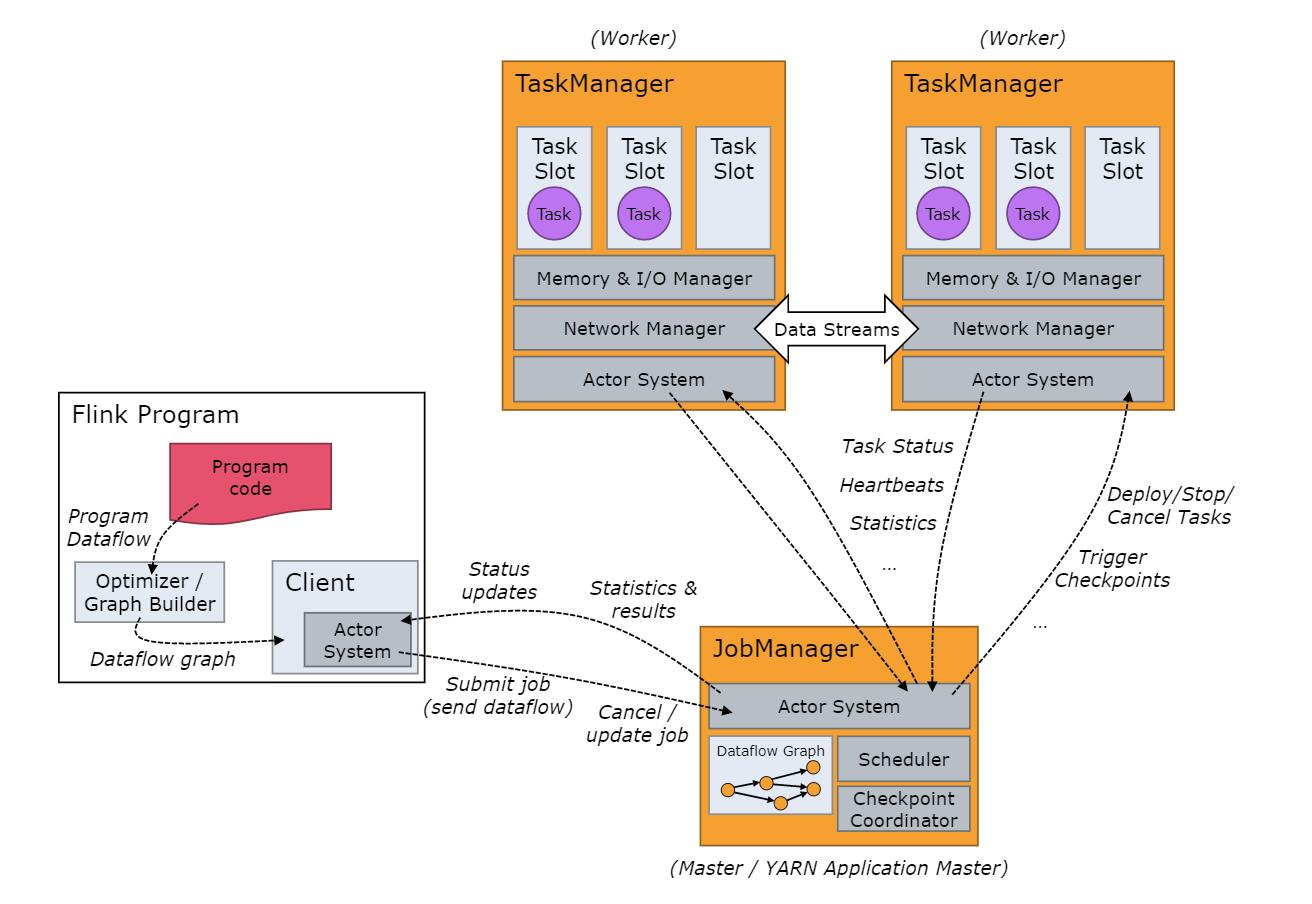
- 注意事项:
- Client不是运行和程序执行的一部分,而是用于准备数据流并且发给JobManager。
- 提交任务之后,此时Client可以断开连接(分离模式),或保持连接来接收进程报告(附加模式)。
- Client可以作为触发执行Java、Scala程序一部分执行,也可以在命令行进程./bin/flink run …中运行
- 可以通过多种方式启动JobManager和taskManager:在机器上作为standalone集群启动、在容器中启动或通过yarn等资源框架启动。taskMansger连接到Jobmanager宣布自己可用并分配工作。
- actor system
- 各个角色组件之间互相通信的消息传递系统中间件。
- 是一种并发编程模型。与另一种模型共享内存完全相反,它没有任何共享。
- 所有线程通过消息传递的方式进行合作。这些线程就被称为actor。
- 以简单高效著称
- 缺点:不能实现真正意义上的并行,而是通过并发实现的并行
- 纯消息通信,实时性和粒度控制上弱于共享内存的方式
核心角色组成剖析
- JobManager
- 主要是协调和监控Task,Task的执行顺序,Task的任务状态决策等等。
- 这个进程由三个不同的组件组成
- ResourceManager
- 负责Flink集群中的资源提供、回收、分配。它管理task slots,这是Flink集群中资源调度的最小单位。Flink为不同的环境和资源管理者实现了对应的ResourceManager
- Dispatcher
- Dispatcher提供了一个REST接口,用来提交Flink应用程序执行。并为每个提交的作业启动一个JobMatser。它还运行 FlinkWbeUI提供作业执行信息。
- JobMaster
- JobMaster负责管理单个JobGrouph的执行。Flink集群中可以同时运行多个作业,每个作业都有自己的JobMaster。
- 始终至少有一个JobManager。HA设置中可能有多个JobManager,一个是活跃的。
- TaskManager
- ResourceManager
- JobManager
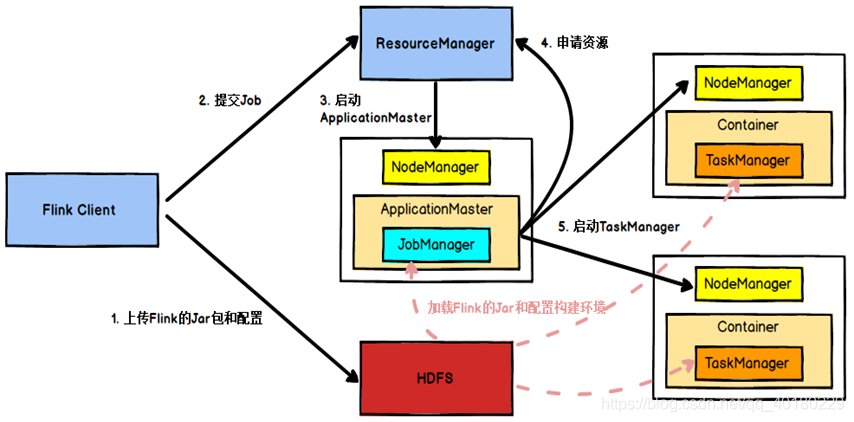
工作流程图(app模式)

若有收获,就点个赞吧
0 人点赞
