一、shell操作hbase
1、进入bhase shell环境
- status 查看集群状态
- version 查看版本信息
- whoami 当前操作的用户是哪个
- DDL操作(系统定义语言)
- create 创建表 create”student”,”base_info”,”private_info”
- list 列出所有表 list
- disable 禁用表 disable disable”student”
- is_disabled 表是否被禁用 is_disabled”student”
- drop 删除表(必须先禁用再删除) drop”student”
- enable 启用一张表 enable”student”
- describe 查看表结构 describe”student”
- alter 修改表的结构,如给表student加入一个列族123 alter”student”,”123”
- exists 验证表是否存在 exists”student”
- disable_all 禁用多个表
- drop_all 删除多个表
- DML操作(数据操作语言)
- 插入数据向当前空间表Student的rowkey为1的行添加数据
- put”Student”,”r1”,”base_info:name”,”张三”
- hbase读取数据只有三种方式
- scan遍历全表 scan”student”
- scan范围查询 scan”student”,{LINIT=>2,STARTROW=>”r1”,ENDROW=>”r2”}
- get按照rowkey查询 get”student”,”rowid” get”student”,”rowid”,”baseinfo:username”
- 删除指定条件的列数据
- delete”student”,”r1”,”baseinfo:username”
- 清空表
- Truncate(只是清空数据) truncate”student”
- 不需要手动disable表,系统会自动disable,再执行清空操作。
- 查看当前空间下的所有表 list_namespace_tables”namespace”
- Truncate(只是清空数据) truncate”student”
- 查看habse版本号
- decsribe”tablename”
- 修改列族的版本号个数
- 模板:alter ‘tablename’,NAME=>’columnFamilyName’,VERSIONS=>versionNumbers
- 样例:alter ‘Student4Job008’,NAME=>’baseInfo’,VERSIONS=>2
- 再去查看表的描述信息,可以查到变化情况。
- 查看表数据的指定版本个数(有效的版本号,若已删除版本但处于标记状态,并未真正删除数据的不属于有效的版本数据)
- 模板1-查看全表:scan ‘tablename’,{VERSIONS => versionNumber}
- 模板1-查看某列族:scan ‘tablename’,{NAME=>’baseInfo’,VERSIONS => versionNumber}
- 样例:scan ‘Student4Job008’,{VERSIONS => 4}
- 注:hbase删除数据时,先加入删除标记,即标记删除法,待到minor 或是 major compaction再进行物理删除。
- 查看表数据的指定所有版本对应的数据(包括全部版本的实际还存在的数据, 即包括加了删除标记但未正式删除的)
- 模板1-查看全表:scan ‘tablename’,{RAW=>true,VERSIONS => versionNumber}
- 模板1-查看某列族:scan ‘tablename’,{RAW=>true,NAME=>’baseInfo’,VERSIONS => versionNumber}
- 样例:scan ‘Student4Job008’,{RAW=>true,VERSIONS => 4}
- 修改列族的版本号个数
- decsribe”tablename”
- Namespace操作
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.1.2</version><!-- <scope>provided</scope> --></dependency>
2、Java操作代码案例
package com.tl.job007.hbase.test;import java.util.ArrayList;import java.util.List;import java.util.Random;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.Cell;import org.apache.hadoop.hbase.CellScanner;import org.apache.hadoop.hbase.CellUtil;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.HColumnDescriptor;import org.apache.hadoop.hbase.HTableDescriptor;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.client.Admin;import org.apache.hadoop.hbase.client.Connection;import org.apache.hadoop.hbase.client.ConnectionFactory;import org.apache.hadoop.hbase.client.Get;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.Table;import org.apache.hadoop.hbase.util.Bytes;/*** @author 天亮教育*/public class HBaseOperator {// 用于链接hbase的连接器对象,类似于mysql jdbc的Connectionpublic Connection connection;// 用hbase configuration初始化配置信息时会自动加载当前应用classpath下的hbase-site.xmlpublic static Configuration configuration = HBaseConfiguration.create();// 初始化hbase操作对象public HBaseOperator() throws Exception {// ad = new HBaseAdmin(configuration); //过期了,推荐使用Adminconfiguration.set("hbase.zookeeper.quorum","192.168.1.34,192.168.1.31,192.168.1.32,192.168.1.41");configuration.set("hbase.zookeeper.property.clientPort", "2181");configuration.set("zookeeper.znode.parent", "/hbase-unsecure");// 对connection初始化connection = ConnectionFactory.createConnection(configuration);}// 创建表public void createTable(String tablename, String... cf1) throws Exception {// 获取admin对象Admin admin = connection.getAdmin();// 创建tablename对象描述表的名称信息TableName tname = TableName.valueOf(tablename);// mytable// 创建HTableDescriptor对象,描述表信息HTableDescriptor tDescriptor = new HTableDescriptor(tname);// 判断是否表已存在if (admin.tableExists(tname)) {System.out.println("表" + tablename + "已存在");return;}// 添加表列簇信息for (String cf : cf1) {HColumnDescriptor famliy = new HColumnDescriptor(cf);tDescriptor.addFamily(famliy);}// 调用admin的createtable方法创建表admin.createTable(tDescriptor);System.out.println("表" + tablename + "创建成功");}// 删除表public void deleteTable(String tablename) throws Exception {Admin admin = connection.getAdmin();TableName tName = TableName.valueOf(tablename);if (admin.tableExists(tName)) {admin.disableTable(tName);admin.deleteTable(tName);System.out.println("删除表" + tablename + "成功!");} else {System.out.println("表" + tablename + "不存在。");}}// 新增数据到表里面Putpublic void putData(String table_name) throws Exception {TableName tableName = TableName.valueOf(table_name);Table table = connection.getTable(tableName);Random random = new Random();List<Put> batPut = new ArrayList<Put>();for (int i = 0; i < 10; i++) {// 构建put的参数是rowkey rowkey_i (Bytes工具类,各种java基础数据类型和字节数组之间的相互转换)Put put = new Put(Bytes.toBytes("rowkey_" + i));put.addColumn(Bytes.toBytes("user"), Bytes.toBytes("username"),Bytes.toBytes("user_" + i));put.addColumn(Bytes.toBytes("user"), Bytes.toBytes("age"),Bytes.toBytes(random.nextInt(50) + 1));put.addColumn(Bytes.toBytes("user"), Bytes.toBytes("birthday"),Bytes.toBytes("20170" + i + "01"));put.addColumn(Bytes.toBytes("content"), Bytes.toBytes("phone"),Bytes.toBytes("电话_" + i));put.addColumn(Bytes.toBytes("content"), Bytes.toBytes("email"),Bytes.toBytes("email_" + i));// 单条记录put// table.put(put);batPut.add(put);}table.put(batPut);System.out.println("表插入数据成功!");}// 查询数据public void getData(String table_Name) throws Exception {TableName tableName = TableName.valueOf(table_Name);Table table = connection.getTable(tableName);// 构建get对象List<Get> gets = new ArrayList<Get>();for (int i = 0; i < 5; i++) {Get get = new Get(Bytes.toBytes("rowkey_" + i));gets.add(get);}Result[] results = table.get(gets);for (Result result : results) {// 使用cell获取result里面的数据CellScanner cellScanner = result.cellScanner();while (cellScanner.advance()) {Cell cell = cellScanner.current();// 从单元格cell中把数据获取并输出// 使用 CellUtil工具类,从cell中把数据获取出来String famliy = Bytes.toString(CellUtil.cloneFamily(cell));String qualify = Bytes.toString(CellUtil.cloneQualifier(cell));String rowkey = Bytes.toString(CellUtil.cloneRow(cell));String value = Bytes.toString(CellUtil.cloneValue(cell));System.out.println("rowkey:" + rowkey + ",columnfamily:"+ famliy + ",qualify:" + qualify + ",value:" + value);}}}// 关闭连接public void cleanUp() throws Exception {connection.close();}// 测试相关功能方法public static void main(String[] args) throws Exception {HBaseOperator hbaseOperator = new HBaseOperator();hbaseOperator.createTable("zel", "user", "content");hbaseOperator.putData("zel");hbaseOperator.getData("zel");hbaseOperator.cleanUp();}}
三、HBase经典面试问题剖析
1、hbase架构设计之元数据管理之root表和meta表
- hbase0.98版本及以前
- hbase用root表来记录meta的Region信息。类似于meta表记录用户表的Region信息。
- Root只会有一个Region。
- client需要先访问root表来获取meta表的Region信息,故需要知道存储root表的Region的RegionServer的地址。
- 该地址被存在zookeeper中。默认路径/hbase/root-region/server
- root表结构示意图

- meta表结构示意图
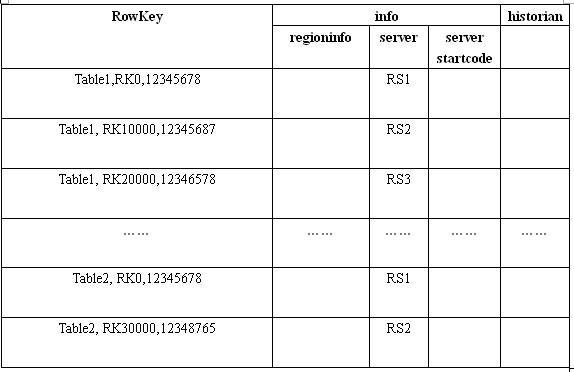
- 工作流程描述
- Hbase的所有Region元数据都没存储在meta表中,随着Region的增多,Meta数据量也会增大,分裂成多个Region。
- 为了定位meta表中各个Region的位置,将meta表中所有的Region的元数据保存在Root表中。
- 最后又zookeeper保存root表的位置信息。
- 所有客户端访问数据时都需要先访问zookeeper来获取root位置信息,然后通过访问root获得meta表的位置,最后通过meta确定用户存放的数据的位置。
- 工作流程示意图
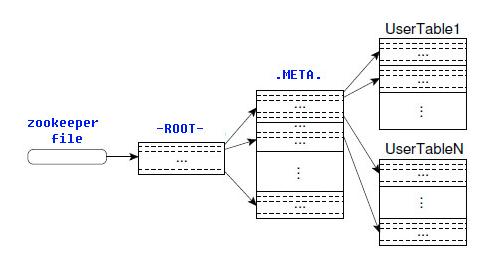
- Root永远不会被分割,他只有一个Region。
- 这样可以保证最多只需要跳跃三次即可定位到任意一个Region。
- 为了加快访问速度,meta表的所有Region都保存在内存中。
- 客户端会将查询过的位置信息缓存起来。且缓存不会失效。
- 如果客户端访问缓存查不到信息,则会访问meta查询信息的位置,如果还是失败,则询问root表相关的meta表在哪里。
- 最后,如果前面的信息全部失效。则通过zookeeper重新定位region信息。所以如果客户端上的缓存全部失效则需要六次网络来回,才能定位到正确的Region。
hbase0.98版本之后元数据管理说明(为优化执行效率而升级)
背景说明
- hbase是三位有序数据表,通过rowkey、列族、timestamp版本号这三个维度进行快速定位数据。
- rowkey唯一标识一行记录,有以下几种方式进行hbase数据查询
- 通过get方式,指定rowkey获取唯一一行数据。
- 通过scan,设置startrow和stopstart进行条件筛选。
- 浅表扫面scan,即扫描整张表中的所有行记录。
- RowKey设计必要性-避免热点问题
- 热点发生在大量的client同时访问少数的那几个节点。(可能是读、写、或者其他操作)
- 大量的访问可能会导致region所在的机器超出承受范围而导致不可用,甚至导致同一个regionserver上的其他region不可用。
- 多数是由于rowkey设计不合理导致的。
- 设计技巧说明
- 长度越短越好,不要太长
- rowkey是二进制码流存储理论上可以是任意字符串,一般最大64kb,实际一般为10-100bytes。设计成定长。
- HFile中是根据KV存储的,rowkey为K,其他值为V,rowkey过长就会导致存储效率低。
- memstore会缓存部分数据到内存,如果rowkey过长则占用空间,降低系统性能。
- rowkey散列原因
- 原因说明
- rowkey是hbase数据的排序和划分region的主要依据,如果过于稠密则导致大量数据都被分配在同一个region中,使得对应regionserver负载过高。
- 很多人用时间戳作为rowkey,这样会导致大量数据集中在一个region中,造成负载过高,降低效率。
- 散列做法
- 至少不能将时间放在二进制码的前面。
- 第一种选择是可以将时间戳倒序后作为rowkey。比较简单,但是失去了rowkey可读性、有序性的意义。
- 第二种是将rowkey的高位作为散列字段。由程序随机生成,地位放时间段
- rowkey唯一原则
- rowkey是一行数据的唯一标识,必须保持唯一性。rowkey是按照字典顺序排序存储的。
- 设计时要充分利用排序这个特点,将经常读取的数据存储在一起,即将会被访问的数据存储在一起。
- 这样更方便的利用数据块集中加载,数据缓存加速等提升查询效率。
- 原因说明
- 长度越短越好,不要太长

若有收获,就点个赞吧
0 人点赞
