一、Java版flink-wordount离线计算版
1、maven构建项目搭建开发环境
- maven构建scala项目
因为要同时编写scala和Java,所以需要加入依赖,并且在main目录下创建Java文件夹
<!-- 因为往往是scala和java在一起混合开发,故需要设置多个源文件目录,故需要maven新插件build-helper-maven-plugin来支持设置多个源文件夹,也可以设置多个资源路径 --><plugin><groupId>org.codehaus.mojo</groupId><artifactId>build-helper-maven-plugin</artifactId><version>3.0.0</version><executions><execution><id>add-source</id><phase>generate-sources</phase><goals><goal>add-source</goal></goals><configuration><sources><!-- 我们可以通过在这里添加多个source节点,来添加任意多个源文件夹 --><source>${basedir}/src/main/java</source><source>${basedir}/src/main/scala</source></sources></configuration></execution><execution><id>add-test-source</id><phase>generate-test-sources</phase><goals><goal>add-test-source</goal></goals><configuration><sources><source>${basedir}/src/test/scala</source><source>${basedir}/src/test/java</source></sources></configuration></execution></executions></plugin>
然后加入flink依赖
<!-- 一般环境配置 --><properties><project.build.sourceEncoding>utf-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><encoding>UTF-8</encoding><scala.version>2.11.11</scala.version><scala.compile.at.version>2.11</scala.compile.at.version><flink.version>1.13.1</flink.version><jdk.version>1.8</jdk.version></properties><!-- flink包依赖配置-start --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><!-- <scope>provided</scope> --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.compile.at.version}</artifactId><version>${flink.version}</version></dependency><!-- flink包依赖配置-end -->
2、Java代码的编写
```java public class FlinkWordCount4DataSet { public static void main(String[] args) throws Exception { //创建环境变量 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //定义文件路径 String filePath = “”; if (args == null||args.length==0){
filePath = "C:\\学习\\技术学习\\data.txt";
}else {
filePath = args[0];
} //获取输入文件对应的DataSet对象 DataSet
inputLineDataSet = env.readTextFile(filePath); //对数据集进行多个算子处理,转换为(word,1)二元组 DataSet .flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {String[] wordArray = s.split(" ");for (String word:wordArray){collector.collect(new Tuple2<String, Integer>(word, 1));}}}).groupBy(0).sum(1);
//打印 resultSet.print(); } }
<a name="tRflf"></a>## 3、项目打包与部署- 需要加入对应的build打包配置,由于flink复杂的打包依赖与之前的有一些差距。- 去掉之前maven-assembly-plugin打包配置插件,当其配置复杂依赖、多配置文件时容易出现版本依赖处理异常。- 加入解决配置文件、版本不一致冲突的maven-shade-plugin打包配置插件,以后所有的all-in-one打包,均可以优先使用maven-shade-plugin配置打包。- 需要加入的build如下。```xml<!-- 打包配置 --><build><plugins><!-- 因为往往是scala和java在一起混合开发,故需要设置多个源文件目录,故需要maven新插件build-helper-maven-plugin来支持设置多个源文件夹,也可以设置多个资源路径 --><plugin><groupId>org.codehaus.mojo</groupId><artifactId>build-helper-maven-plugin</artifactId><version>3.0.0</version><executions><execution><id>add-source</id><phase>generate-sources</phase><goals><goal>add-source</goal></goals><configuration><sources><!-- 我们可以通过在这里添加多个source节点,来添加任意多个源文件夹 --><source>${basedir}/src/main/java</source><source>${basedir}/src/main/scala</source></sources></configuration></execution></executions></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>${jdk.version}</source><target>${jdk.version}</target><encoding>${encoding}</encoding></configuration></plugin><!--打all-in-one jar包 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>2.3</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><transformers><!--<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>flink.KafkaDemo1</mainClass> </transformer> --><transformerimplementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"><resource>reference.conf</resource></transformer></transformers></configuration></execution></executions></plugin></plugins></build>
- 然后执行maven打包,得到jar包。
- 上传到服务器上。
-
4、执行的三种方式
1、第一种方式-传统的yarn jar方式(java -cp)
- 优点:
- 简单、易操作。
- 缺点:
- 默认仅支持local模式,改成分布式模式很麻烦。
- 在打包时需要去掉provided。最终形成的jar包比较大。
命令格式:
优点:
- 支持flink的所有方式,比较灵活。
- 不需要再打入那么多的包。
- 缺点:
- 较第一种比较复杂,需要下载flink发布包,解压缩即可。
- 注意事项:
- 优点:
yarn application模式
- 操作步骤
- 首先进入安装flink的home路径
- 执行flink任务的代码即可
- run-application:即运行作业类型。专指application类型。
- -t:指定运行模式
- -c:指入口主类
- app.jar:上传的jar包
- 参数运行类的参数
- 示例
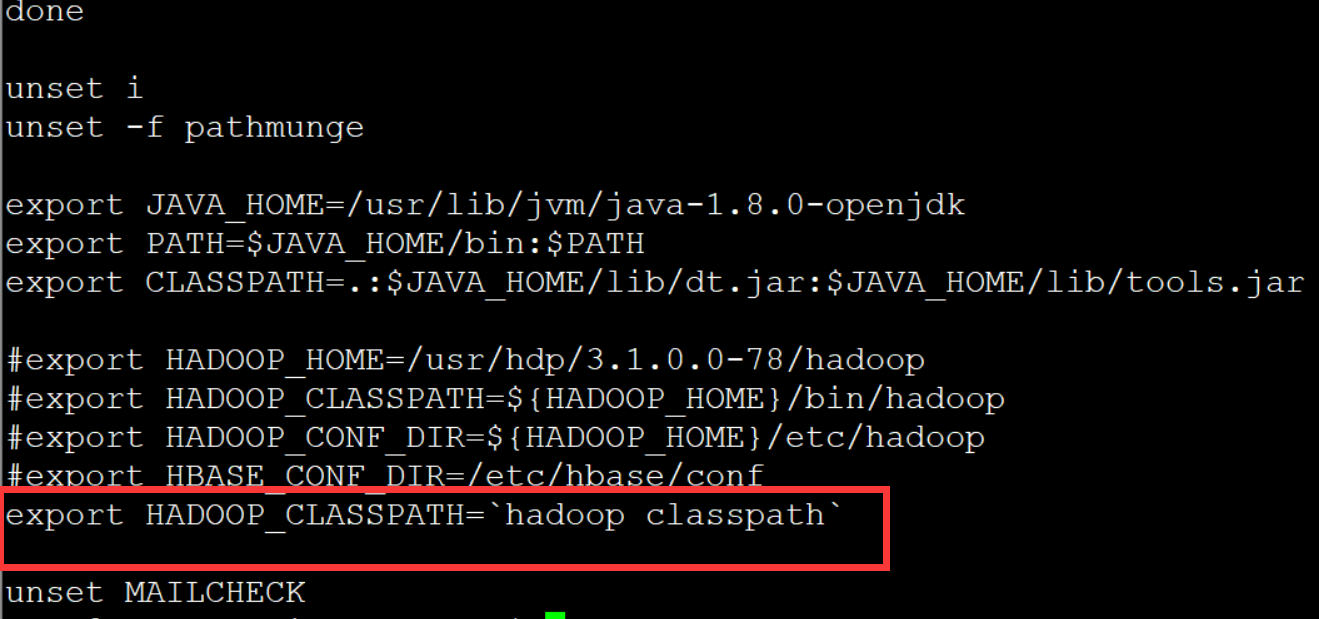
``xml [miaohongkai@cluster0 flink-1.13.1]$ export HADOOP_CLASSPATH=hadoop classpath` [miaohongkai@cluster0 flink-1.13.1]$ ./bin/flink run-application -t yarn-application -c com.tledu.FlinkWordCount4DataSet /home/job018/miaohongkai/flink/Flink-1.0-SNAPSHOT.jar hdfs:///user/miaohongkai/data.txt
- 操作步骤

- 运行结果- 进入yarn中,找到运行日志- - yarn per-job运行模式- 操作步骤- 首先进入安装路径- 执行flink提交代码- run:即作业运行模式。包括session和per-job- -t:指定运行模式- -c:指定入口主类- APP.jar:上传的jar包- 参数- 需要先设置不需要进行classloader leaked check,在配置文件路径设置./conf/flink-conf.yaml,有则修改,无则新加即可#注意yaml参数文件修改,请在value前加上一个空格<br />classloader.check-leaked-classloader: false- 然后运行```xml./bin/flink run -t yarn-per-job -c com.tledu.FlinkWordCount4DataSet../Flink-1.0-SNAPSHOT.jarhdfs:///user/miaohongkai/data.txt
- 运行结果- 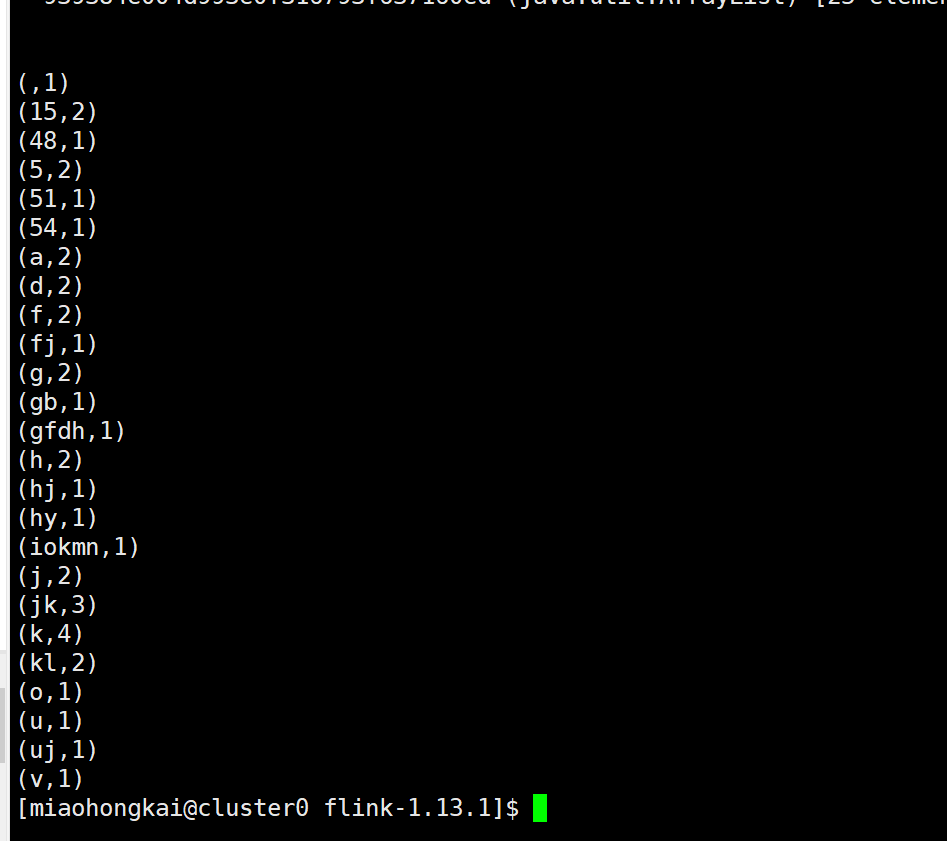
- yarn session运行方式
- 操作步骤
- 首先进入flinkhome目录
- 附加模式(默认模式)
- 特点
- yarn-session.sh客户端将 Flink 集群提交给 YARN,但客户端保持运行,跟踪集群的状态。如果集群失败,客户端将显示错误。如果客户端被终止,它也会通知集群关闭。
- 工作流程
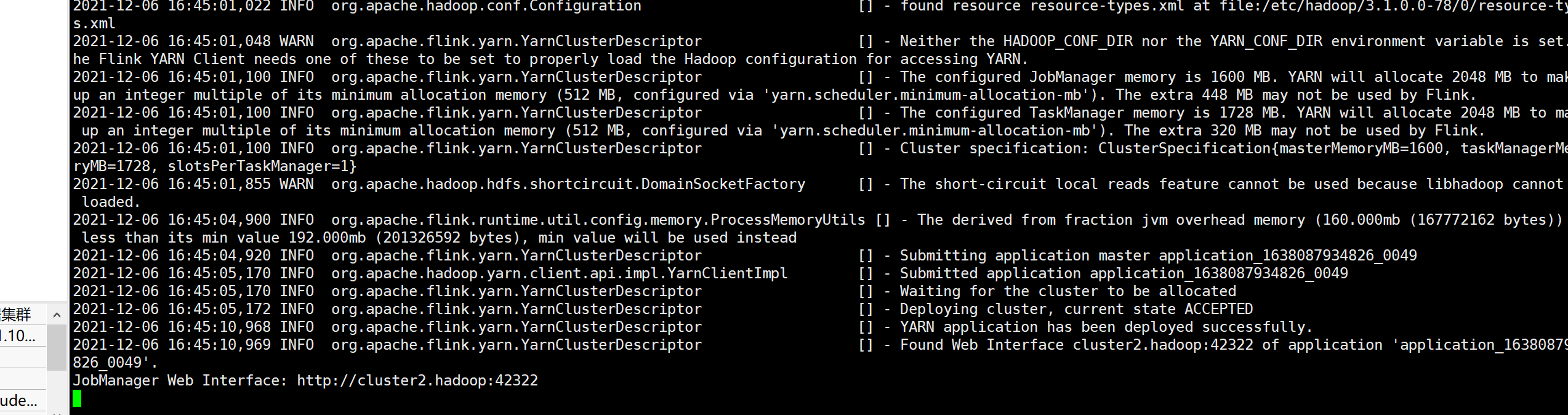
- 首先在yarn上启动flink session,并得到session task任务的yarn app-id。
- ./bin/yarn-session.sh
- 运行截图(一直在等待中,并不退出)
- 特点
- 操作步骤
- 提交作业到session中- #第1种提交: 多加入-t yarn-session参数,此时必须指定app-id参数,即提前启动的session作业任务id
./bin/flink run -t yarn-session -Dyarn.application.id=application_1627998129686_0475 -c com.tl.bigdata.flink.demo.FlinkWordCount4DataSet ../FirstFlink-0.0.1-SNAPSHOT.jar hdfs:///user/zel/input.txt
- #第2种提交: 不加入-t yarn-session参数,则不需要手动指定app-id,其是自行寻找提前启动的session作业任务id
./bin/flink run -c com.tl.bigdata.flink.demo.FlinkWordCount4DataSet ../FirstFlink-0.0.1-SNAPSHOT.jar hdfs:///user/zel/input.txt
- 注意:也需要加export HADOOP_CLASSPATH=`hadoop classpath`- 运行截图- 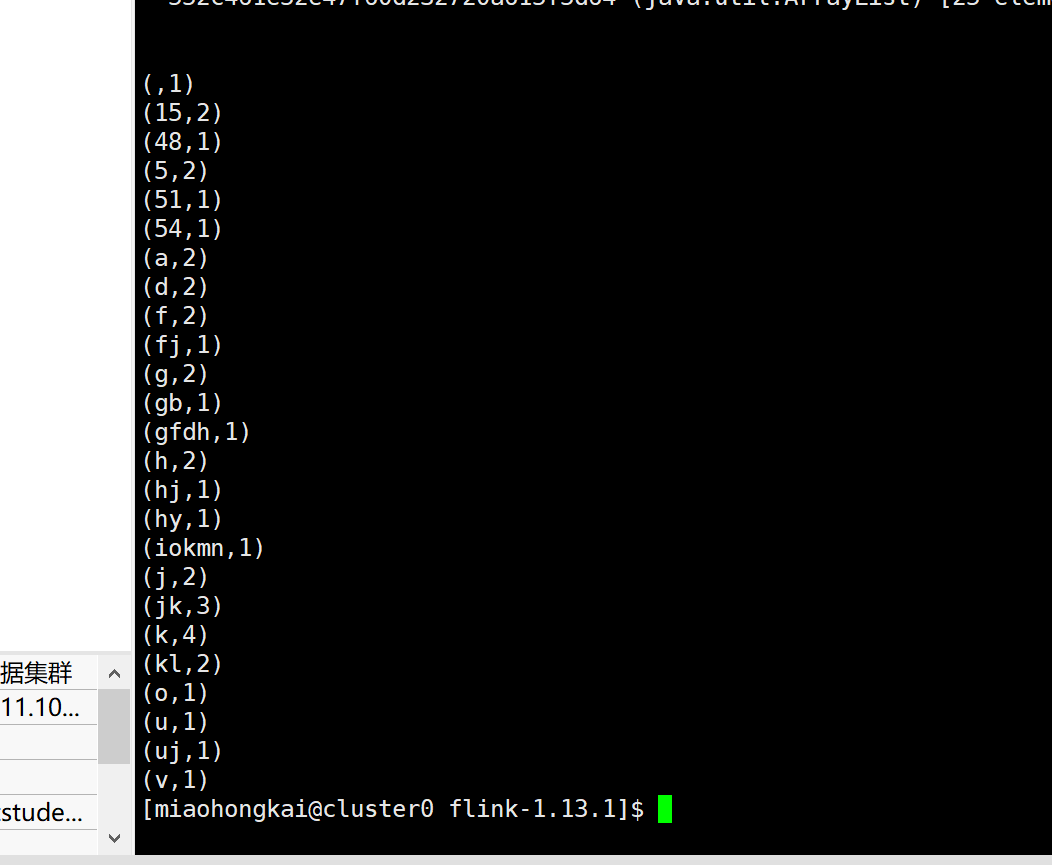- 分离模式-detached模式- 特点- yarn-session.sh客户端将Flink集群提交给YARN,然后客户端返回。需要再次调用客户端或 YARN 工具来停止 Flink 集群。- 流程- 首先在yarn上提前启动flink session会话任务,并得到session task任务的yarn app-id- ./bin/yarn-session.sh --detached- 提交任务(与默认模式一样)- #第1种提交: 多加入-t yarn-session参数,此时必须指定app-id参数,即提前启动的session作业任务id
./bin/flink run -t yarn-session -Dyarn.application.id=application_1627998129686_0475 -c com.tl.bigdata.flink.demo.FlinkWordCount4DataSet ../FirstFlink-0.0.1-SNAPSHOT.jar hdfs:///user/zel/input.txt
- #第2种提交: 不加入-t yarn-session参数,则不需要手动指定app-id,其是自行寻找提前启动的session作业任务id
./bin/flink run -c com.tl.bigdata.flink.demo.FlinkWordCount4DataSet ../FirstFlink-0.0.1-SNAPSHOT.jar hdfs:///user/zel/input.txt
- 注意:也需要加export HADOOP_CLASSPATH=`hadoop classpath`
二、Java版flink-wordcount实时计算版
1、加入依赖
<!-- flink包依赖配置-start --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><!-- <scope>provided</scope> --></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.version}</artifactId><version>${flink.version}</version><!-- <scope>provided</scope> --></dependency><!-- flink包依赖配置-end -->
2、代码实现
public class FlinkWordCount4DataStream {public static void main(String[] args) throws Exception {//创建上下文环境变量StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//定义主机和端口号String host = "localhost";int port = 9999;//获取输入的socket输入实时数据流DataStream<String> inputLineDataStream = env.socketTextStream(host,port);//进行算子操作DataStream<Tuple2<String, Integer>> resultStream = inputLineDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String line,Collector<Tuple2<String, Integer>> out)throws Exception {String[] wordArray = line.split("\\s");for (String word : wordArray) {out.collect(new Tuple2<String, Integer>(word, 1));}}}).keyBy(0).sum(1);//打印resultStream.print();//正式启动实时流处理引擎env.execute();}}
- 启动nc 输入 nc -lp 9999
- 运行Java程序
-
三、Scala版flink-wordcount离线计算版
1、环境搭建
<!-- flink包依赖配置-start --><!-- java开发flink依赖-start --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.compile.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- java开发flink依赖-end --><!-- scala开发flink依赖-start --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_${scala.compile.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_${scala.compile.version}</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- scala开发flink依赖-end --><!-- flink包依赖配置-end -->
2、代码编写
object FlinkWordCount4DataSet4Scala {def main(args: Array[String]): Unit = {//获取上下文环境var env = ExecutionEnvironment.getExecutionEnvironment//加载字符串(测试用)//val source = env.fromElements("中国 抗美 援朝 战争 很伟大", "抗美 需要 中国")//定义从本地文件系统当中文件路径var filePath = ""if(args == null||args.length==0){filePath = "C:\\学习\\技术学习\\data.txt"}else{filePath = args(0)}val source = env.readTextFile(filePath)//进行transformaion操作val ds = source.flatMap(s => s.split(" ")).map(t => (t,1)).groupBy(0).sum(1)//输出ds.print()// 由于是Batch操作,当DataSet调用print方法时,源码内部已经调用Excute方法,所以此处不再调用//如果调用反而会出现上下文不匹配的执行错误//env.execute("Flink Batch Word Count By Scala")}}
四、Scala版flink-wordcount实时计算版
1、构建maven环境
scala离线版的开发已将实时依赖加入,不用再做增加或是改变
2、代码编写
```scala object FlinkWordCount4DataStream4Scala { def main(args: Array[String]): Unit = { //获取上下文环境 var env = StreamExecutionEnvironment.getExecutionEnvironment //加载数据源 var source = env.socketTextStream(“localhost”,9999,’ ‘) //进行transformation var ds = source.flatMap(x => x.split(‘ ‘)).map(t => (t,1)).keyBy(0).sum(1) //输出 ds.print() //执行操作 env.execute(“FlinkWordCount4DataStream4Scala”) }
3、使用nc测试

若有收获,就点个赞吧
0 人点赞
