业务中经常有需要用到树状结构的地方,比如部门树、文件夹等等。本文总结集中经典设计,针对不同场景按需使用。(参考 SQL Anti-patterns 一书)
邻接表(Adjacency List)和 递归查询(Recursive query)
每条记录存 parent_id ,这也是 树 最常见的设计方案。
- 优点是结构非常简单直接,增删改很方便,修改 parentId 即可
- 缺点是查询困难,尤其是要把整个树从根节点开始构建起来(需要不断递归)。随着层级增加,查询效率不断下降
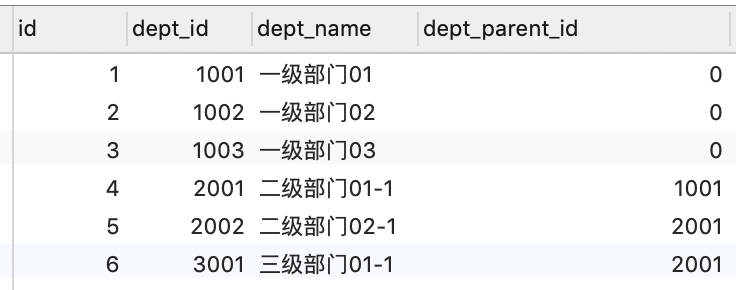
查某个节点的子节点:
SELECT * FROM dept_info WHERE dept_parent_id =1001
节点移动:
UPDATE dept_info SET dept_parent_id=1001 WHERE dept_id=3001;
路径枚举(Path Enumerations)
在邻接表的基础上增加节点路径,里面存从根节点开始到自己的完整路径
- 优点是查询方便。可以通过 like 语句快速查询子节点,同时通过长度即可知道节点所在层级
- 缺点是节点移动变更困难。需要同时变更所有子节点的路径数据,同时路径字段的长度不好缺点
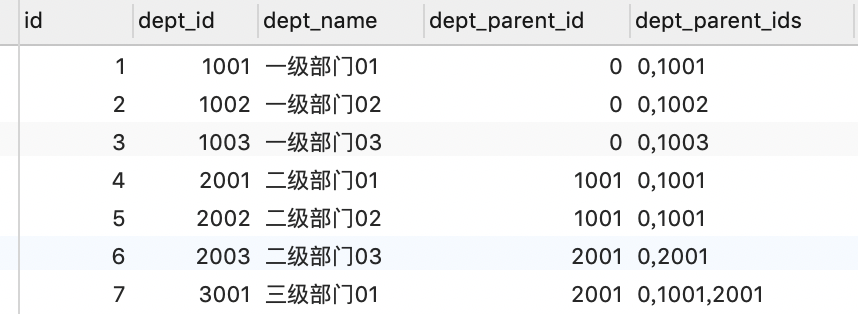
查询部门 1001 的下级部门:
SELECT * FROM dept_info WHERE dept_parent_ids like '%1001%'
左右值编码(Nested Sets)
左右值编码的思路是基于树的前序遍历算法。这种设计方案会记录一个 左值(lft)和一个右值,分别代表树前序遍历过程的顺序。计算过程如图2
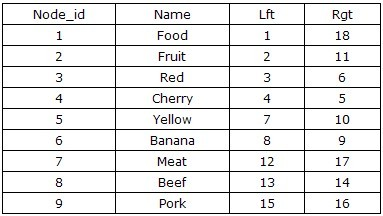
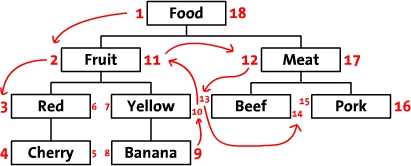
左右值设计方案特别适用于类似「文件夹」的场景。前两种设计方案,随着树层级增加,性能都会逐步下降,不适合无限层级的场景。而左右值方案查询效率不受层级影响(不用递归)
但弊端是随着层级增加,修改更新变得困难
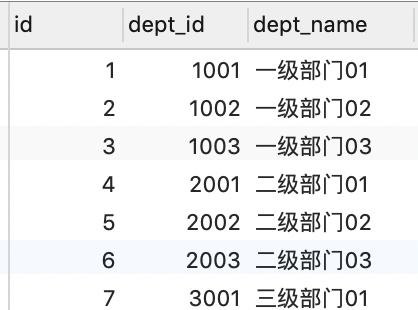
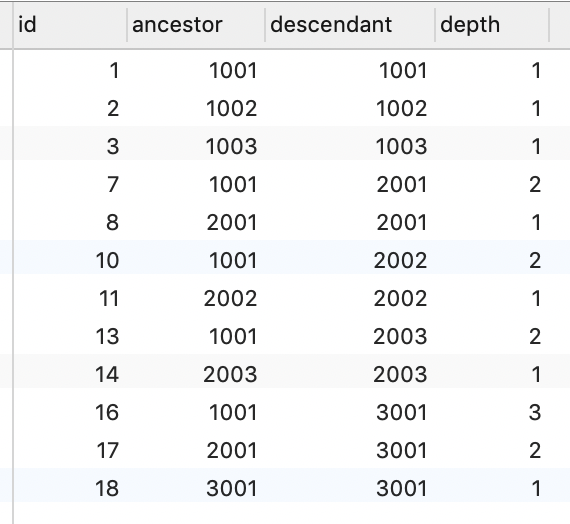
闭包表(Closure Table)
闭包表的思路是空间换时间。用一张单独的表存储节点关系,数据表只存储业务数据。
第二种表的设计可以比较灵活,只要能描述节点关系即可。实例的表结构是记录了祖先节点和自己所在的层级。
查节点关系的时候查节点表即可,相比前面的方案,表会稍微小一点。代价是要多一张表
总结对比
最后用一张图总结对比一下每一种设计方式的优劣: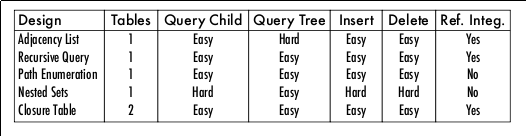

若有收获,就点个赞吧
0 人点赞
