类和对象的创建
类
# 经典类 没有继承 object的类# 新式类 继承了 object的类class Money: # 2.x中默认是经典类,3.x中是新式类passclass Money(object): # 兼容的一种写法pass# Money既是类的__name__属性名,又是一个引用该类的变量print(Money.__name__) # Moneyxxx = Moneyprint(xxx.__name__) # Money
对象
one = Money()print(one) # <__main__.Money object at 0x000001555E9534A8>print(one.__class__) # <class '__main__.Money'>
属性相关
对象属性
class Person:passp = Person()# 给 p对象增加属性, 所有的属性是以字典的形式组织的p.age = 18print(p.age) # 18print(p.__dict__) # {'age': 18}print(p.sex) # AttributeError: 'Person' object has no attribute 'sex'# 删除p对象的属性del p.ageprint(p.age) # AttributeError: 'Person' object has no attribute 'age'
类属性
class Money:num = 666count = 1type = "rmb"print(Money.num) # 666# 对象查找属性,先到对象自身去找,若未找到,根据 __class__找到对应的类,然后去类中查找one = Money()print(one.count) # 1# 不能通过对象去 修改/删除 对应类的属性one.num = 555 # 实际上是给 one 对象增加了一个属性print(Money.num) # 666print(one.num) # 555# 类属性会被各个对象共享two = Money()print(one.num, two.num) # 666 666Money.num = 555print(one.num, two.num) # 555 555
限制对象的属性添加
# 类中的 __slots__属性定义了对象可以添加的所有属性class Person:__slots__ = ["age"] # 只允许添加一个 age属性p1 = Person()p1.age = 1p1.num = 2 # AttributeError: 'Person' object has no attribute 'num'
私有化属性
- Python没有真正的私有化支持,只能用给变量添加下划线来实现伪私有;通过名字重整机制
属性的访问范围:类的内部—>子类内部—>模块内的其他位置—>其他模块
公有属性 x 的访问范围
[x] 类的内部
- 子类内部
- 模块内的其他位置
-
受保护属性 _x 的访问范围
[x] 类的内部
- 子类内部
- 模块内的其他位置(但不推荐)
[x] 子类内部(from … import xxx 不可以访问,要指明all变量)
私有属性 __x 的访问范围
[x] 类的内部
- 子类内部
- 模块内的其他位置
-
保护数据案例
```python class Person: def init(self):
self.__age = 18
def set_age(self, age): # 错误数据的过滤
if isinstance(age, int) and 0 < age < 150:self.__age = ageelse:print("Wrong age value")
def get_age():
return self.__age
p = Person()
print(p.get_age()) # 18
p.set_age(22)
print(p.get_age()) # 22
<a name="c17fa77c"></a>### 只读属性```python# 1. 属性私有化 + 属性化 get()方法class Person(object):def __init__(self):self.__age = 18# 可以以使用属性的方式来使用方法@propertydef age(self):return self.__agep = Person()print(p.age) # 18p.age = 666 # Attribute Error: can't set attribute# 2. 通过底层的一些函数class Person:# 通过 属性 = 值 的方式来给一个对象增加属性时,底层都会调用这个方法,构成键值对,存储在 __dict__字典中# 可以考虑重写底层的这个函数,达到只读属性的目的def __setattr__(self, key, value):if key == "age" and key in __dict__:print("read only attribute")else:self.__dict__[key] = value
方法相关
方法的划分
- 实例方法
- 类方法
静态方法
class Person:def instance_fun(self): # self: 调用对象的本身,调用时不用写,解释器会传参print("instance method", self)@classmethoddef class_fun(cls): # cls: 类本身print("class method", cls)@staticmethoddef static_fun():print("static method")
所有的方法都存储在类中,实例中不存储方法
-
方法的私有化
和变量的私有化思想差不多
class Person:__age = 18def __run(self): # 只能在该类中被调用print("running...")
元类
创建类对象的类(类也是一个对象)
a, s = 8, "123"print(a.__class__, s.__class__) # <class 'int'> <class 'str'>print(int.__class__, str.__class__) # <class 'type'> <class 'type'>
type是元类。
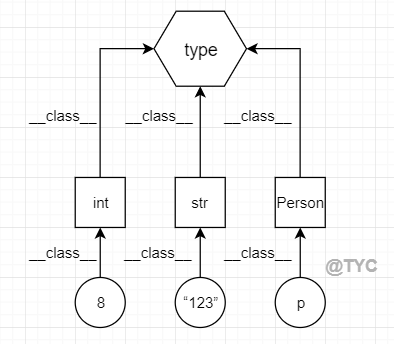
- 通过
type元类来创建类,动态创建。也可以用__metaclass__来指明元类,进行类的创建。- 检测类对象中是否有 metaclass属性
- 检测父类中是否有 metaclass属性
- 检测模块中是否有 metaclass属性
- 通过内置的
type来创建类 ```python def run(self): print(“run…”)
Dog = type(“Dog”, (), {“count”: 0, “run”: run}) print(Dog) # d = Dog() print(d.count) # 0 print(d.run()) # run…
更加详细的内容,在进**高级部分**的元类编程讲解<a name="6a438b49"></a># 内置的特殊属性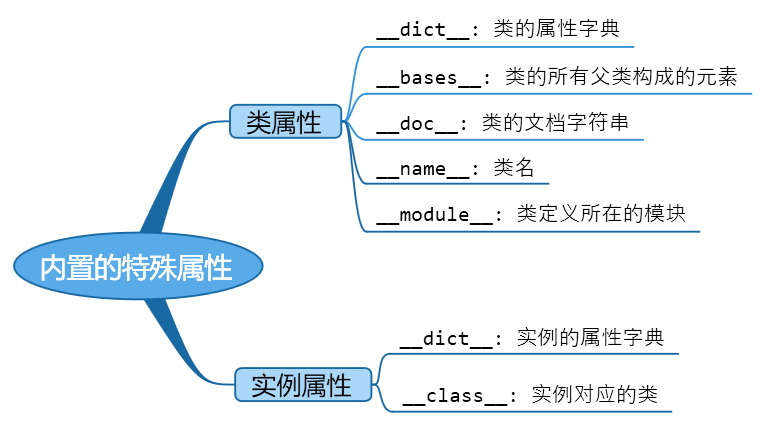<a name="a9a9c5cb"></a># 内置的特殊方法(魔法函数)这里只做一个了解,高级部分会详细地讲解魔法函数。可以理解为在类中实现了这些特殊的函数,类产生的对象可以具有**神奇**的语法效果。<a name="ba7964b8"></a>## 信息格式化操作```pythoncalss Person:def __init__(self, n, a):self.name = nself.age = a# 面向用户def __str__(self):return "name: %s, age: %d" % (self.name, self.age)# 面向开发人员def __repr__(self):# todo# 一般默认给出对象的类型及地址信息等# 打印或进行格式转换时,先调用 __str__()函数,若未实现,再调用 __repr__()函数p = Person("Rity", 18)print(p) # name: Rity, age: 18res = str(p)print(res) # name: Rity, age: 18print(repr(p)) # <__main__.Person object at 0x000001A869BEB470>
调用操作
# 使得一个对象可以像函数一样被调用class PenFactory:def __init__(self, type):self.type = typedef __call__(self, color):print("get a new %s, its color is %s" % (self.type, color))pencil = PenFactory("pencil")pen = PenFactory("pen")# 一下两种使用方式会调用 __call__()函数pencil("red") # get a new pencil, its color is redpencil("blue") # get a new pencil, its color is bluepen("black") # get a new pen, its color is black
索引操作
class Person:def __init__(self):self.cache = {}def __setitem__(self, key, value):self.cache[key] = valuedef __getitem__(self, key):return self.cache[key]def __delitem__(self, key):del self.cache[key]p = Person()p["name"] = "MetaTian"...
比较操作
# 使得自己定义的类可以按照一定的规则进行比较import functools@functools.total_orderingclass A:def __init__(self, age, height):self.age = ageself.height = heightdef __eq__(self, other): # ==return self.age == other.agedef __lt__(self, ohter): # <return self.age < other.agea1, a2 = A(18, 170), A(19, 178)# 因为逻辑具有相反性,当使用 > 时,首先会查找 __gt__()函数,若未定义,将参数交换后调用 __lt()__方法# 由 == 和 < 可以组合出其他的所有比价逻辑,使用装饰器可以自动生成其他逻辑对应的函数,简化代码print(a1 < a2) # Trueprint(a2 > a1) # Trueprint(a1 >= a2) # False
描述器
- 描述器是一个对象,用来描述其他对象属性的操作;作用是对属性的操作做验证和过滤。
- 前面只读属性案例中就是用到了描述器。
在对象的内部增加一个描述器,可以接管对象属性的增删改查操作。 ```python class Age: def get(self, instance, owner): # instance是拥有 age 属性的对象
pass
def set(self, instance, value):
instance.v = value # 将变量的值绑定在 Person 的实例中
def delete(self, instance):
pass
class Person: age = Age()
age实例是 p1和 p2两个对象所共享的,所以 Age 对象及实例不应该具有属性,只单纯地提供方法即可
p1 = Person() p1.age = 19 # 调用 set() print(p1.age) # 调用 get()
p2 = Person() p2.age = 20 print(p2.age) # 20
<a name="b9711afe"></a>## 资料描述器和非资料描述器- 也可以称为**数据描述器**和**非数据描述器**- 资料描述器:实现了`__get__()` 和 `__set__()`- 非资料描述器:仅仅实现了`__get__()`- 实例属性和描述器重名时,**操作的优先级**关系:资料描述器 > 实例属性 > 非资料描述器<a name="176808a1"></a># 生命周期- 用来表示一个对象从创建到释放的过程```pythonclass Person:__count = 0def __init__(self):Person.__count += 1def __del__(self):Person.__count -= 1@classmethoddef log(cls):print("we have %d people" % cls.__count)p1 = Person()Person.log() # we have 1 peoplep2 = Person()Person.log() # we have 2 people
内存管理机制
引言
- 万物皆对象,不存在基本数据类型
在 [-5, 正无穷) 范围内相等的整数和短小的字符串,Python会进行缓存,不会创建多个对象
n1 = 1n2 = 1print(id(n1), id(n2)) # 1708655056 1708655056
-
内存回收
引用计数
- 一个对象会记录着自身被引用的个数
- 每增加一个引用,引用数+1,减少一个引用,引用数-1
- 引用数为0的时候,会被当做垃圾进行回收
- 会出现两个对象循环引用的问题
- 垃圾回收
- 从经历过引用计数机制但仍然未被释放的对象中,进行内存释放
- 新增的对象个数 - 消亡对象的个数达到一定阈值时才进行垃圾检测
- 分代回收
- 分代回收是垃圾回收的高效解决方案,不需频繁地进行垃圾检测
- 存活时间越久的对象,越不可能在后面的过程中变成垃圾
- 设立0, 1, 2三代对象集合,对其中的对象进行不同频率的检测
- 第一次检测存活下来的,从0代纳入1代,0代检测一定次数后开始检测1代,以此类推
深拷贝和浅拷贝
浅拷贝
a = [1, 2, 3]b = aprint(id(a), id(b)) # 2229855665608 2229855665608
深拷贝
import copya = [1, 2, 3]c = copy.deepcopy(a)print(id(a), id(c)) # 2229855665608 2229861709896
copy和deepcopy的区别
import copya = [1, 2, 3]b = [4, 5, 6]c = [a, b]d = copy.deepcopy(c)e = copy.copy(c)
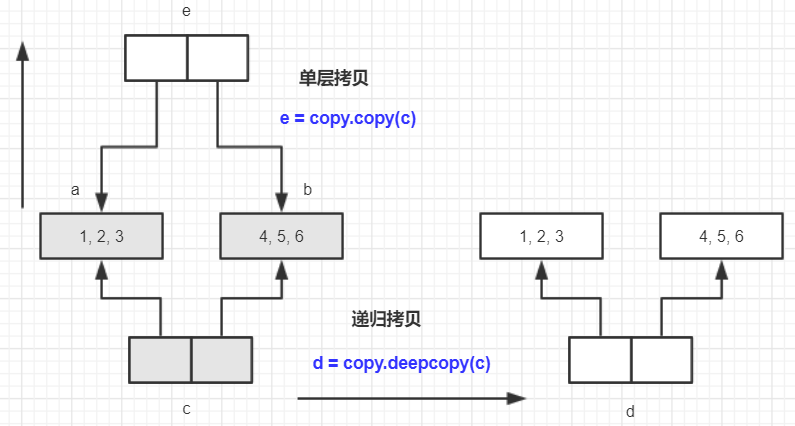
使用copy拷贝可变类型时,进行单层次的深拷贝,若拷贝的是不可变类型,则进行浅拷贝。
面向对象三大特性
封装
继承
- 非私有的属性和方法可以被继承,继承不是拷贝了资源,而是具有了资源的访问权,资源的存储位置在父类中,实现资源重用。
Python中可以使用多继承。 ```python所有的类都继承了 object 类
所有的类对象都由 type 实例化出来
class A: pass
class B: pass
class C(A, B): # C 类继承了 A和 B类 pass
print(C.bases) # (
- 几种继承的形式<br />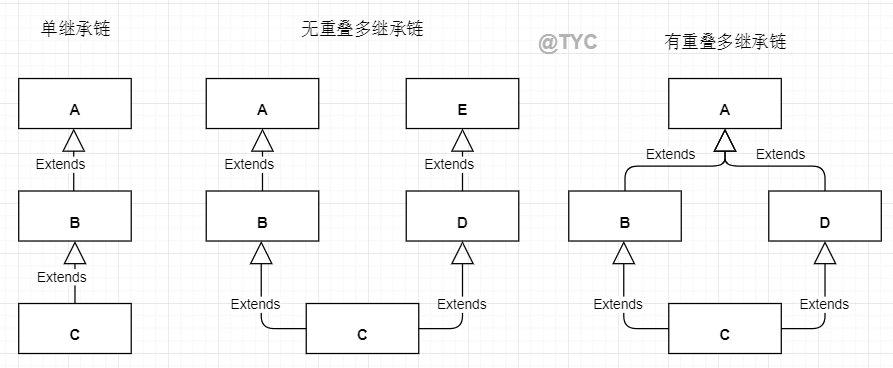<br />- 资源查找顺序- 单继承链:C-->B-->A- 无重叠多继承链:按照单继承链**深度优先**查找(C-->B-->A-->D-->E)- 有重叠多继承链:广度优先查找(C-->B-->D-->A)- 资源覆盖- 在优先级较高的类中重新定义了**同名的属性和方法**,再次调用时,会调用到优先级较高类中的资源,并不是相关的资源在内存上被**覆盖**了,而是调用优先级出现了变化- `self` 和 `cls`<br />```python# 谁调用方法,self 和 cls 就是谁# 带着参数去找方法class A:def show(self):print(self)@classmethoddef tell(cls):print(cls)class B(A):passB.tell() # <class '__main__.B'>B().show() # <__main__.B object at 0x027674D0>
- 资源的累加
```python
class A:
def init(self):
class B(A): pass class C(A): def init(self):self.x = 2
class D(A): def init(self):self.y = 1
self.y = 1
class E(A): def init(self): super().init() # 会调用 A的构造函数,参数可以省略
# A.__init__(self) //和上面等价,要传参self.y = 1
b = B() print(b.x) # 2, 调用了父类的构造函数,b 调用,x就是 b的 c = C() print(c.y) # 1, C有了构造函数,就调用 C的,A的构造函数不会被调用 print(c.x) # 报错,没有这个属性 e = E() print(e.x, e.y) # 2, 1
<a name="154ae683"></a>## 多态- Python是动态类型的语言,不需要严格意义上的多态```pythondef test(obj):obj.func()# 只要传入的参数有 func()这个方法,就可以传入进行执行,不用进行类型检测。# 不需要按照其他静态语言那样沿着继承链进行方法调用形成多态
类的设计原则
- 单一职责原则:一个类只负责一项职责
- 开放封闭原则:对外扩展开放,对内修改关闭
- 里式替换原则:子类所继承下来的属性和方法都需能够合理地使用
- 接口分离原则:功能一致的方法应该重新组成新的接口/类,进行细分
- 依赖倒置原则:高层模块不应该直接依赖低层模块,核心是面向接口编程

若有收获,就点个赞吧
0 人点赞
