引言
Celery是进行分布式任务处理的工具,它封装了很多常用的针对任务队列的操作。- 我们可以使用它快速进行分布式任务队列的使用和管理。
- 个人觉得,有些像
Python concurrent提供的线程池工具。 - 单靠
Celery还不能够完成分布式的任务调度,还需要broker和backend。
工作流程
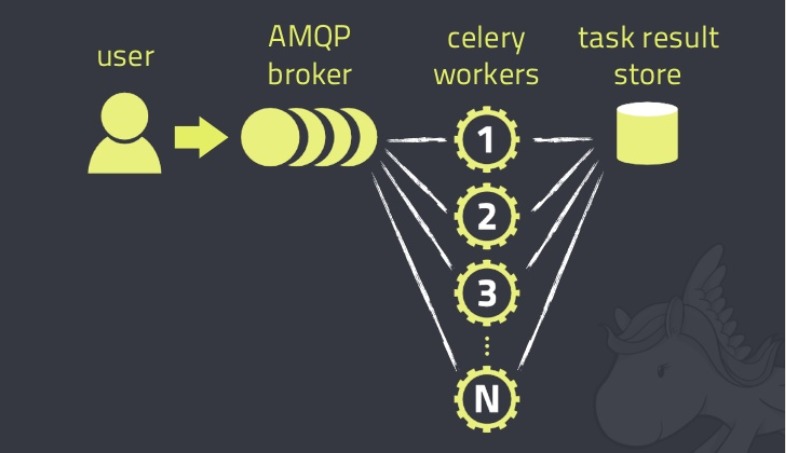
这里有一份 Slide,清晰直观地介绍了Celery
相关组件
Broker
broker可以理解为“中间人”,我们有了任务不是直接丢给Celery,而是要通过这个broker来自动调度管理,通常我们选用 RabbitMQ(本质上就是一个队列)。
Backend
Celery workers在完成相关的任务后,它没有义务将结果返回给用户,因为它得专注于当下的任务,才能让复杂任务处理地更加高效。backend是用来存放任务执行结果的,Celery workers将结果储存后就继续忙了。通常要由用户来进行结果的查询和获取,我们可以选用 Redis 作为存储介质。
使用案例
分布式环境
想要实现分布式,就需要多机环境。将一个业务模块拆分成多个子业务,然后部署在不同的服务器上,以解决高并发的问题。
这里准备使用虚拟机创建出两台Ubuntu主机作为服务器(ubuntu_0和ubuntu_1),其中一台部署RabbitMQ,另外一台部署Redis。本地的Windows则作为Celery workers和主业务逻辑的运行平台。
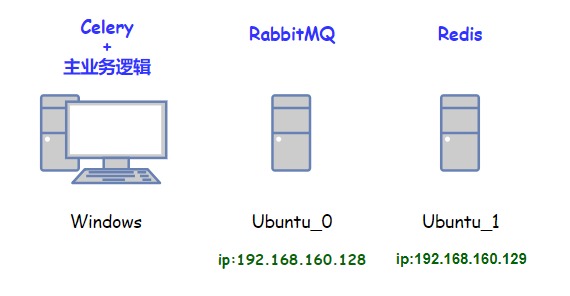
Celery + RabbitMQ
先看一个简单的例子,这里不使用Redis做后端存储,提交的任务在Celery执行完成后就直接结束,不进行结果存储等其他操作。但是我们可以采用其他方式看到执行的结果。
安装Celery
Celery就是一个Python的模块,直接使用pip进行安装,相关知识可以参考前面的Python基础——包和模块部分。
安装RabbitMQ
在ubuntu_0上进行部署。
1.安装
我已经安装过了,第一次安装要等待一会
sudo apt-get install rabbitmq-server
2.启动
sudo rabbitmq-server // 前台启动,占用 shell 资源, shell 关了也没事sudo rabbitmq-server -detached // 后台启动,不弹出界面

3.停止
sudo rabbitmqctl stop

使用RabbitMQ时,是用户制的,一般直接使用是以guest身份进行访问,这个跟Linux的访客模式差不多。也可以创建角色,赋予权限,但为了简单,这里就使用默认的guest用户。
但是,guest是不支持外网访问的,只能够接收本机服务的访问,结合前面的分布式部署,这种限制是必须要取消的。
配置
修改/etc/rabbitmq目录下的rabbitmq.config配置文件,没有就新建一个(我安装的时候是没有的),创建和修改是需要 管理员权限 的,记得命令前加上 sudo 。配置如下信息:
[{rabbit, [{loopback_users, []}]}].# 最后面的那个 '.' 别掉了
使用
然后找一个合适的位置编写一个Python脚本tasks.py。
import celery"""ampq是啥?可能你只熟悉 http,它是通信的一种协议这里我们要和 rabbitmq 打交道,所以用 ampq 这种协议"""broker = 'amqp://192.168.160.128//' # 指明 brokerapp = celery.Celery('test', broker=broker) # 'test' 是名字"""用装饰器来装饰我们需要执行的任务函数"""@app.taskdef reverse(msg):return msg[::-1]
然后再命令提示符执行celery -A tasks worker --loglevel=info,tasks就是脚本文件的名称,最好保证执命令时的路径和脚本文件所在路径是一致的。这样就根据我们所写的脚本文件,开启了一个Celery服务,会创建出和本机cpu数量相同的worker进程,每个进程会使用装饰器修饰过的函数来完成任务逻辑。它监听broker中的任务,进行自动调度。
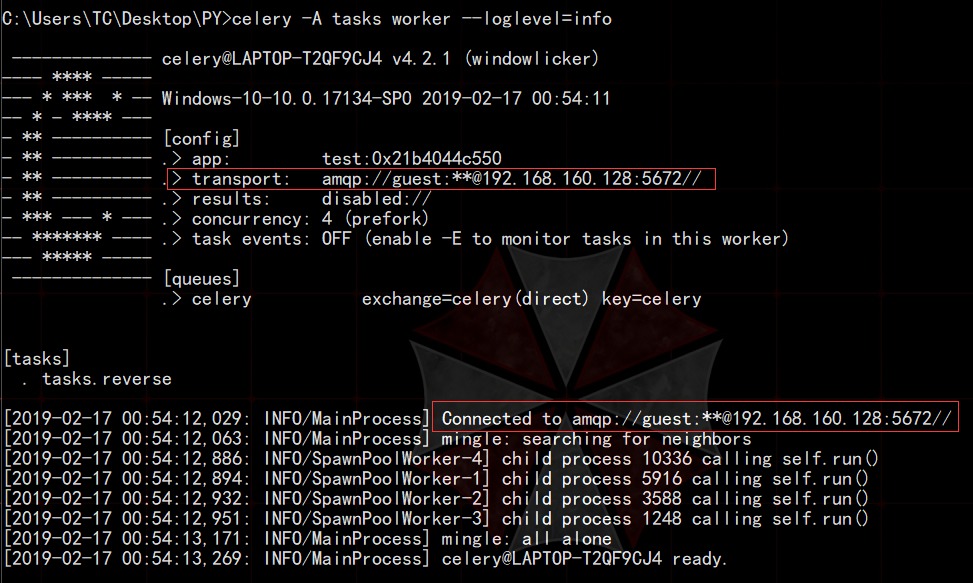
随后,我们在同一个目录下开启一个提示符窗口,将脚本文件作为资源进行导入,通过xxx.delay()向队列中提交任务参数,交给Celery服务调度。delay()方法是装饰器(@app.task)赋予的。
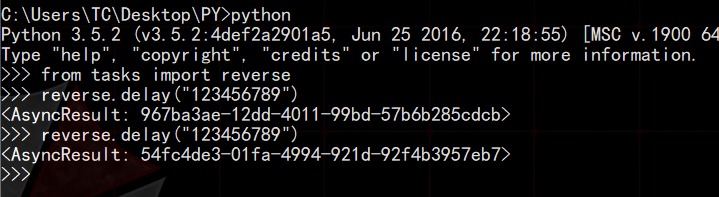
然后前面的一个窗口会出现错误信息(Windows的特色,搞开发就没省心过,Linux下是可以正常运行的):
[2019-02-17 01:07:56,505: ERROR/MainProcess] Task handler raised error: ValueError('not enough values to unpack (expected 3, got 0)',)
在 github 上看看开发者自己怎么说的吧,对Windows无爱了,不过可以换一种方式执行:
celery -A tasks worker --pool=solo -l info// -l info == --loglevel=info 两者是等价的
然后,再次刚才的任务提交:
这说明刚才提交的任务已经被调度执行了,结果是7654321,这个结果是通过--loglevel=info来控制展示在终端上的,本来这些信息是作为日志记录的。
由于没有连接backend,这个结果是不会长时间存在的,也没有返回给调用方。
Celery采用了简单灵活的构架,主进程并不关心有多少个可用的worker被创建出来了,也不需要知道worker到底运行在哪个服务器上,只需要知道队列在哪,通过什么样的方式提交任务即可。
Celery + RabbitMQ + Redis
安装
在ubuntu_1上部署redis。
1.安装
sudo apt-get install redis-server
2.运行
sudo service redis-server start //启动sudo service redis-server stop //停止sudo service redis-server restart //重启
配置
redis和rabbitmq一样,默认是不支持外网的访问的,需要对它进行配置。在/etc/redis目录下,有redis.conf配置文件。
sudo vim redis.conf
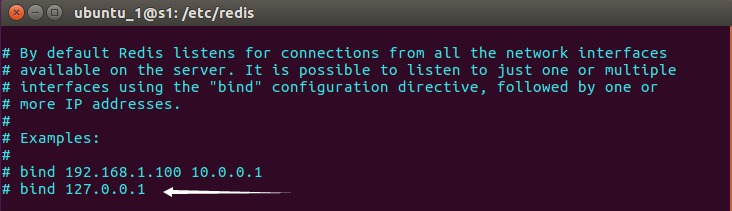
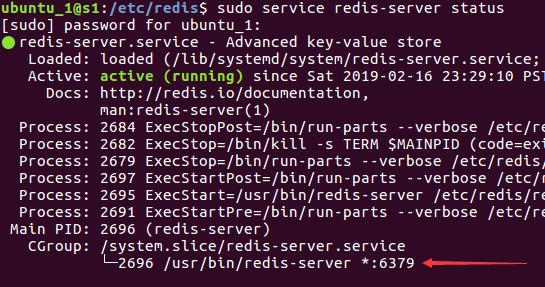
将这一行注释掉,默认是开启的,表示只接受环路网络的访问。完成后重新启动,可以查看运行状态,最后一行的*表示接受所有网段的访问,没有刚才的配置的话,是127.0.0.1
使用
在使用Celery的Window端,因为绑定了redis作为backend,所以还需要安装redis模块,才能正常使用。
然后,我们在Windows端来启动服务。
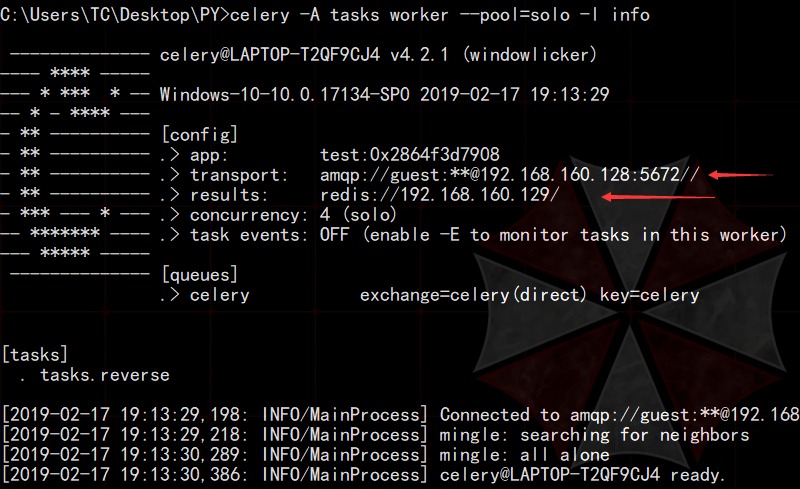
这时,刚才使用过的脚本文件要进行修改,将我们的backend信息添加进去。
import celerybroker = 'amqp://192.168.160.128/'backend = 'redis://192.168.160.129'app = celery.Celery('test', broker=broker, backend=backend)@app.taskdef reverse(msg):return msg[::-1]
现在,我们开启另外一个提示符窗口,用来执行我们的业务逻辑。任务提交之后,它会返回给我们一个AsynResult对象,利用这个对象,我们就可以知道任务执行的情况如何了。
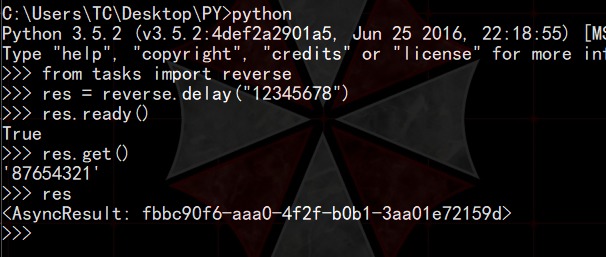
- ready():用来查询任务是否完成
- get():阻塞式调用,获取任务完成后返回的结果,若未完成,进行等待
更详细的方法参阅 这里
Celery + RabbitMQ + Redis(升级版)
背景
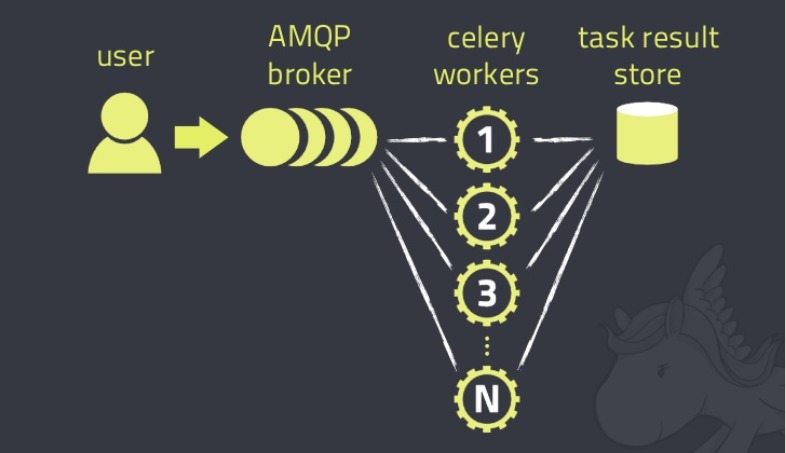
通过刚才的使用案例,我们基本熟悉了分布式计算结构中需要的不同模块,以及每个模块的部署和使用方式。但是,结合前面系统结构图,我们可以看到,这并不是严格意义上的分布式。
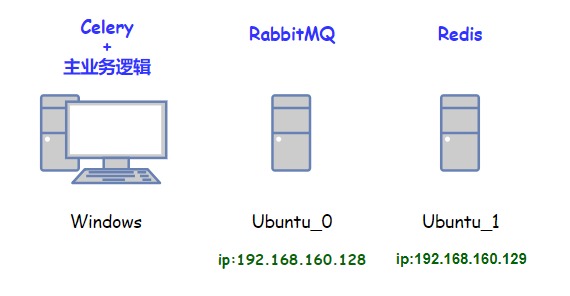
因为我自己的机器资源有限,逻辑拆分的不彻底,Celery workers和主业务的逻辑部署在一台机器上了,使用起来总觉得有些别扭。现在我们将这些逻辑拆开,实现一台机器上发布任务到队列,另一台机器从里面取出然后执行。

现在,从ubuntu_0这台机器上提交任务到RabbitMQ(虽然这个又部署在了同一台机器,但问题不大,因为他们耦合度很低),Windows上的Celery worker从RabbitMQ中获取任务进行执行,将结果保存到Redis。
具体组件的部署和运行前面已将做了介绍了,现在主要关注下Celery逻辑的拆分问题。
Windows端部署
这里是任务的执行端,只需要一个Python脚本文件tasks.py,就可以实现对队列的任务监听。
# tasks.pyimport celeryimport timebroker = 'amqp://192.168.160.128/'backend = 'redis://192.168.160.129'app = celery.Celery('Windows', broker=broker, backend=backend)def sleep():time.sleep(1)@app.taskdef echo(msg):# 这里可以调用其他函数sleep()return msg
然后就可以启动这个服务进行等待了。
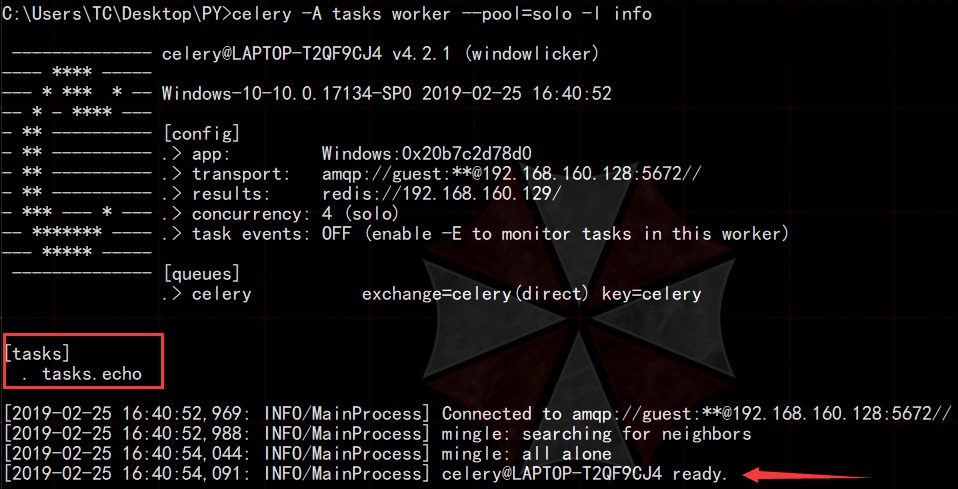
红色方框表示的是这里的worker正在等待的任务。稍后我们就会从Ubuntu_0中提交这样的任务。
Ubuntu_0部署
我们需要两个Python文件,一个和Celery任务有关—— tasks.py,一个主要负责我们的逻辑——main.py。
tasks.py是为了告诉程序要将任务提交到到哪里去执行,提交什么样的任务,所以名字要和 Windows 端的对应。这里任务函数没有任何业务逻辑在里面,因为这个任务并不是在本机执行,而是在Windows端,那里已经存放了函数主体,这里这样写只是为了发送任务时形式上能对应上。
在我们使用C语言时,我们会定义自己的头文件,将一些逻辑分离出来,头文件里写的都是关于函数的声明,函数的主体在另外的地方,差不多的道理。
# tasks.pyimport celerybroker = 'ampq:/192.168.160.128'backend = 'redis://192.168.160.129'app = celery.Celery('???', broker=broker, backend=backend) # 第一个参数写什么无所谓了,这里只负责发送任务;省略第一个参数其实也可以@app.taskdef echo(msg):pass
main.py中就是我们的主要逻辑了。
# main.pyfrom tasks import appfor i in range(3):tasks.echo.delay("asd") # celery 中写上 echo 函数的目的就在这里,否则这句调用会报错
在ubuntu_0中运行程序提交任务
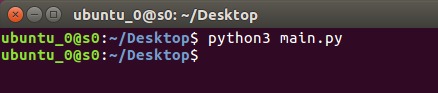
Windows端的worker收到任务开始工作

还可以采用另外一种更加直白的方式(通过 send_task() 函数)来发送任务,我们在tasks.py中甚至都不需要声明函数,文件名也不需要强制使用 tasks.py 的形式。但是任务的名字一定要写对,与Windows端服务启动界面用红框标出的名字是一致的。任务接收的参数也要放在列表或元组里面。
# 采用这种方式,文件的文件名没有强制要求# whatever.pyimport celerybroker = 'ampq:/192.168.160.128'backend = 'redis://192.168.160.129'app = celery.Celery('???', broker=broker, backend=backend)
from my_celery import appfor i in range(3):app.send_task('tasks.echo', ["asd"]) # 第一个参数一定要写对,与 windows 端的对应上
这样一来,就非常接近我们的最初目标了,再看下面的结构图,要好好体会一下各个模块间的关系。
补充
清空RabbitMQ
在使用 app.send_task() 远程提交任务的时候,可能会把任务名称输错;或者是其他的一些原因造成任务队列中的任务是有错误的,不能被 worker 消费掉,但因为任务队列的设计机制,这个任务如果没有被消费,将会很长一段时间留在队列中。这就比较尴尬了,因为任务出错—>不能消费—>留在队列等待消费—>任务出错… 我们可以手动将队列中的任务清除掉
sudo rabbimqctl list_queues # 用来查看当前所有的任务队列

可以看到,目前只有一个发往 celery 的任务队列,里面已经积攒了 9 个任务了。
sudo rabbitmqctl purge_queue <queue_name> # 将指定的队列清除

总结
这部分内容网上没有找到太多资料,特别是在多机环境中部署的情况。Celery官网教程 使用的案例也都是在一台主机环境下的,不能满足我们分机部署的需求。而 RabbitMQ 作为官方指定的队列工具,其官方教程却是用了 Pika 取代Celery来讲解 任务调度 的模型……
可能单纯使用Celery的情况并不多见,因为它已经可以与Flask和Django这样流行Web框架相结合使用。
关于多机部署的方式也是自己不断尝试琢磨出来的,按照自己的理解发现能正常运行,就写在笔记里了,如果其中有什么错误,或者有相关的官方文档,希望可以在评论区提醒我,也可以给我发邮件:yuchentianx@gmail.com

若有收获,就点个赞吧
0 人点赞
