几个概念
- 并发:指一个时间段内,有几个程序在同一个
cpu上运行,但是任意时刻只有一个程序在cpu上运行(Python的多线程编程)。 - 并行:指任意时刻点上,有多个程序同时运行在多个
cpu上(Python的多进程编程)。 - 同步:代码调用 I/O操作 时,必须等待该操作完成才返回的调用方式(
Python socket中的recv()、accept())。 - 异步:代码调用 I/O操作 时,不必等待 I/O 操作返回就返回的调用方式(
Python concurrent线程池中submit())。 - 阻塞:调用一个函数时,当前线程被挂起。
-
C10K问题和I/O多路复用
C10K
什么是C10K
1999年提出的技术挑战
- 如何在一颗
1GHz CPU,2G内存,1gbps的网络环境下,让一台服务器同时为一万个客户端提供FTP服务?问题分析
这其实就是一个高并发的问题,前面讲的多线程和多进程给我们了提供了一个不错的思路,但是单个线程只能给一个客户端提供服务,如果给1万个客户提供服务,那就需要1万个线程,这在给定的硬件环境下是不太现实的。
I/O多路复用
5种I/O模型
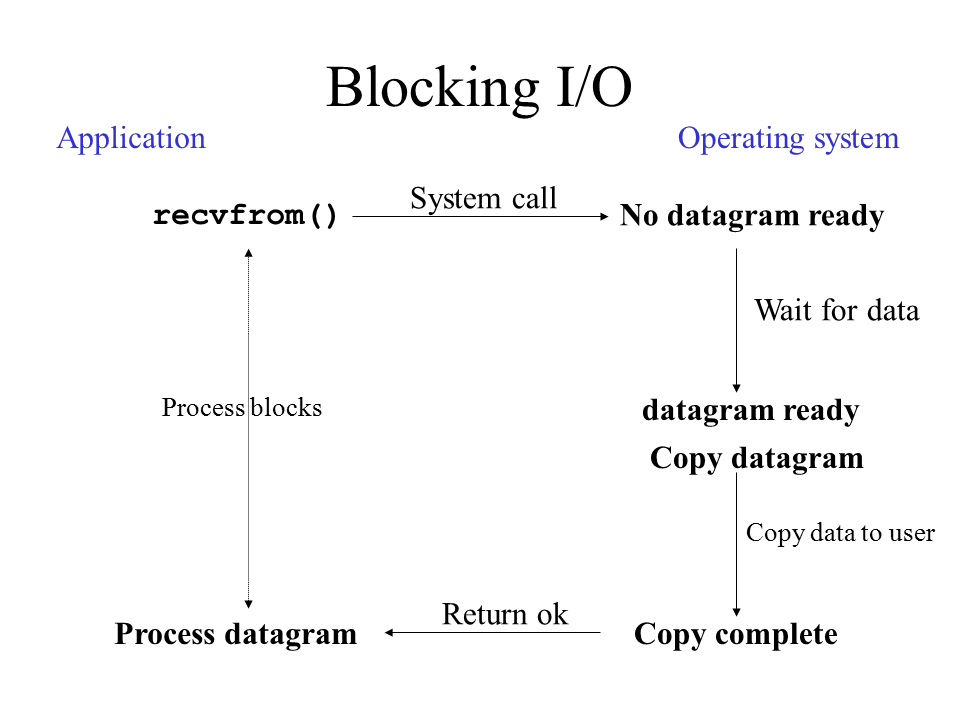
阻塞式I/O(同步)
当涉及I/O的操作被调用后,程序会一直等待,直到数据的返回,期间程序不能处理其他逻辑。数据准备好后,还要将它从内核区拷贝到用户区。
What is the difference between the kernel space and the user space?
非阻塞式I/O(同步)
在前面的socket编程中,通过setblocking(False)将相关调用设置成了非阻塞方式,调用之后,立即返回,但是并不能保证调用中的逻辑都已经完成。所以需要后续不断地去查询相关逻辑是否完成。如果后续紧接着调用了需要上面逻辑结果的函数,可能会产生异常。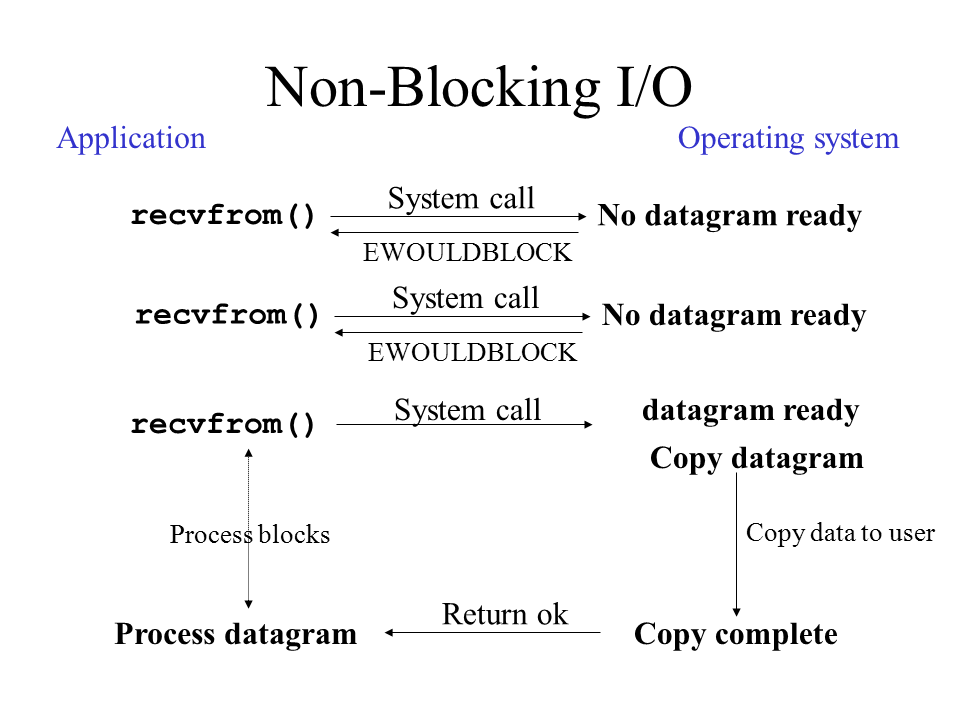
I/O复用
前面的方式中,要不断的主动查询完成情况,可不可以当需要的逻辑完成后,由系统自动通知程序呢?这就需要另外的三种技术(select,poll,epoll),也是本章讲解的重点。
系统本质上也是通过不断查询来判断状态的,但这种方式可以监听多个调用的完成状态。如果有 100个socket 对象,每个都要由我们来负责状态的不断查询,那会是相当复杂的。通过select(),我们就可以监听这100个socket对象,哪一个准备好了数据或者完成了必要的逻辑就可以由select() 挑选 出来,返回给程序。这也是在前面socket编程中使用的主要逻辑。
数据从内核到用户区的时间开销还是存在

信号驱动式I/O
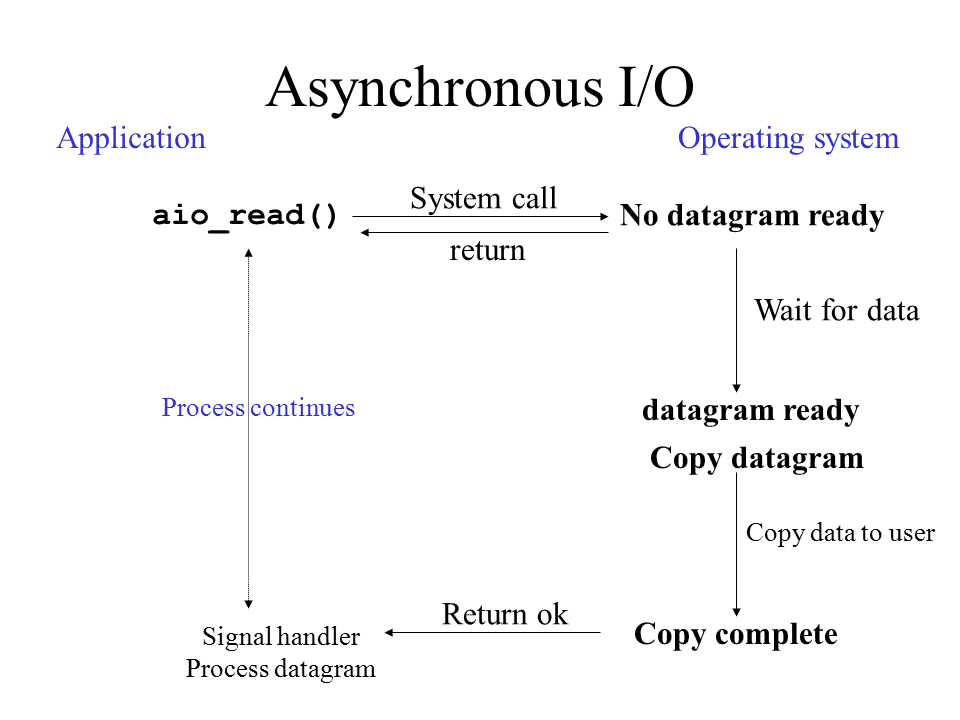
异步I/O
这个可以算是真正意义上的的异步I/O。但是很多实现高并发的框架都没有用这种技术,而是采用I/O多路复用的技术,因为后者技术更加成熟、稳定、性能较好。
数据拷贝的时间开销也封装起来了,调用返回后程序是直接可以使用的。
select, poll, epoll
引言
select, poll, epoll都是I/O多路复用的机制,他们通过一个进程来监视多个描述符,一旦某个描述符就绪(一般是读就绪或者是写就绪),就可以通知程序进行相应的读写操作。他们本质上都是同步I/O,在事件就绪后还要由程序来完成数据的拷贝。真正的异步I/O不需要负责数据拷贝,调用完成后数据也准备好了。
select
select是通过系统调用来监视一个由多个文件描述符组成的数组,当监听到满足的条件后,数据中对应的文件描述符的标志位就会被内核修改。- 然后
select会返回,程序获得这些文件描述符后可以进行后续的读写操作。 - 单个进程能够监视的文件描述符数量存在最大限制,
linux上是 1024 。 select的文件描述符是放在数组中的,每次要进行遍历操作,如果监视的文件描述符太多,比较影响性能。poll
本质上和
select没有区别,不过没有最大监听数量的限制,内部采用了链表进行管理。epoll
内部采用了高效的查询结构,不用再像前面的两种方式那样遍历查询。
- 只在
linux下支持selector
对于上面的三种机制,Python3.4版本中引进了一个selectors模块,它封装了 I/O 多路复用中的select和epoll(Windows平台下使用select,Linux平台下使用epoll),使我们能够更快更方便的实现并发效果。
关于selector的使用,在socket编程中讲解了一个详细的例子,官方文档里也给出了 一个例子。它在register的data参数部分放入了一个函数,最后采用回调的方式完成了相关逻辑。
通过回调函数的方式,有下面这几个问题:
- 可读性差
- 共享状态很难管理
-
什么是协程
背景
前面的问题主要是解决高并发,以
socket编程为例,其中的部分调用是阻塞式的。 如果按照操作逻辑,采用顺序编程的方式。先创建
socket对象,再监听client连接,再调用recv()获得数据。编写逻辑非常清晰,但是无法实现高并发,cpu的资源在大量的等待时间中浪费掉了。- 如果使用
selector模块,通过事件循环和回调的方式来完成操作,可以充分利用cpu的资源,减少了等待时间。但是编写逻辑比较复杂,没有前一种方式容易理解。 如果采用前面讲过的多线程或多进程编程,并发性可以得到保证,而且通过线程池或进程池工具,编写逻辑会很容易理解。但是线程和进程的调度会非常消耗
cpu资源,同时对一些共享的资源,要用一些工具保证它的访问安全性(Lock)。需求
我们希望采用顺序编程的方式去编写异步I/O的代码,这样更容易理解和维护。
- 只通过一个线程去切换不同的任务,减少调度时间。
def task_one():preperation() # 一些数据准备之类的result = wait_task() # 这个调用需要等待 I/O,消耗时间do_task(result) # 根据上面的结果,进一步处理,需要 cpudef task_two():preperation()result = wait_something() # I/Odo_something() # cpu...
要在这些任务函数中进行调度,也就是说当执行到一个函数的I/O操作时,能够跳出这个函数,去别的函数中执行一些需要cpu的操作,在适当的时间再跳转回来,处理I/O操作后获得的数据。
在传统的函数调用中,函数也是顺序执行的,根据调用顺序生成一个调用栈,依次调用即可。在每个函数的执行过程中,是从头执行到尾的,随后函数结束。如果要满足我们的需求,就应该让函数在适当的地方可以暂停,随后恢复运行。
于是,根据这样的需求,就出现了协程,如果你觉得这种需求有些熟悉,那说明你对前面的内容理解的很透彻。没错,协程的本质就是生成器。
生成器进阶
如果对生成器还不熟悉,可以看一些这篇 博客(科学上网)
send、close和throw
send
生成器不仅可以产生值,还可以接收值。yield关键字的右边是产生的值,左边是外部通过send()传进来的值。
send()将值传入生成器内部后,同时使生成器继续执行,直到遇见下一个yield,这和next()逻辑是一样的。
启动生成器的方式有两种:
- 直接使用
next() - 通过
send()方法,初次启动需要使用send(None)
def numbers():result = yield 1print(result)yield 2gen_numbers = numbers()num = next(gen_numbers) # 生成器启动,将 1 产出后,在 yield 关键字处暂停# num = gen_numbers.send(None) # 同上print(num)num = gen_numbers.send("OK") # 将参数传入,赋值给 yield 左边,恢复生成器,执行到 yield 2print(num)# result:# 1# OK# 2
close
close()用来关闭一个生成器,关闭之后,不能再使用next()或send(),否则抛出StopIteration的异常。
def numbers():yield 1yield 2yield 3gen_numbers = numbers()next(gen_numbers)gen_numbers.close() # 生成器在这里就关闭了num = next(gen_numbers)# result:# StopIteration
throw
send()可以向生成器中出入数据,throw()可以向里面传入一个异常。
def numbers():try:yield 1except Exception as e:print(e)yield 2gen_numbers = numbers()print(next(gen_numbers))gen_numbers.throw(Exception, "Number Error")# result:# 1# Number Error
yield from
引言
itertools中为我们提供给了一个工具,它可以将多种可迭代类型连接起来,进行一次性遍历等操作。
from itertools import chainmy_list = [1, 2]my_tuple = ("MetaTian",)my_dict = {'age':22}for value in chain(my_list, my_tuple, my_dict):print(value, end=' ')# result:# 1 2 MetaTian age
这个逻辑其实并不难实现,我们也可以自己实现一个chain工具。
def my_chain(*args, **kwargs): # 不确定参数的个数,采用通用的写法for iterable_obj in args:for value in iterable_obj:yield valuemy_list = [1, 2]my_tuple = ("MetaTian",)my_dict = {'age':22}for value in my_chain(my_list, my_tuple, my_dict):print(value, end=' ')# result:# 1 2 MetaTian age
两层for循环看起来总觉得别扭,不符合Python的简洁语法特性,我们可以用yield from来简化my_chain的函数逻辑,可以达到同样的目的,除了可以将可迭代类型进行连接,它还有更重要的功能。
def my_chain(*args, **kwargs):for iterable_obj in args:yield from iterable_obj
使用案例
yield from后面紧跟一个可迭代对象,可以理解为将这个对象里的值再迭代取出。
"""gen: 委托生成器sub_gen: 子生成器main: 调用方"""# 这是个生成器,接收另外一个生成器作为参数def gen(sub_gen):yield from sub_gen # 生成器也是迭代器,迭代器也是可迭代对象# 调用方,用来使用 gen 这个生成器def main():g = gen(g2) # 假如 g2 是一个已经存在的生成器g.send(None)
yield from会在调用方和子生成器之间建立一个通道,sub_gen里面的值直接返回给main,这似乎有点多余,先别慌,看一个例子。
def score_sum():total_score = 0while True:score = yield # yield 后面没有内容,表示返回 None,这么写表示这行代码主要用来接收外界值if not score:breakelse:total_score += scorereturn total_scoreif __name__ == '__main__':scores = [98, 94, 60, 97, 85]gen = score_sum()gen.send(None) # 启动生成器for score in scores:gen.send(score)gen.send(None) # 退出 while 循环,引发 StopIteratiaon 异常# StopIteration: 434
用生成器来统计总分,虽然有些小题大做,但涉及到很多细节。首先,这个生成器是不通过yield往外传送数据的,只通过send()从外部获取数据,其次,迭代结束引发了异常,导致返回值不能正常返回,但是在异常提示的后面跟了个数字434,这不就是总分数吗?其实,StopIteration会把返回值给带出来,于是,我们可以手动处理一下:
try:gen.send(None) # 退出 while 循环,引发 StopIteratiaon 异常except StopIteration as e:res = e.value # 接收一下异常带出来的 return 值print("The total_score is {0}".format(res))# result:# The total_score is 434
挺麻烦的,又要写生成器逻辑又要处理迭代结束异常问题,使用yield from试试,顺便增加一些需求。
def score_analysis():total_score, n = 0, 0while True:score = yieldif not score:breakelse:total_score += scoren += 1return total_score, total_score / n # sum, avgdef gen_agent(res):while True:result = yield from score_analysis() # 子生成器结束后,这句赋值语句才生效res.append(result)if __name__ == '__main__':scores_list_1 = [98, 94, 60, 97, 85]scores_list_2 = [89, 86, 90, 92, 79]res = []gen = gen_agent(res)gen.send(None) # 启动生成器for score in scores_list_1:gen.send(score)gen.send(None) # 退出 while 循环,引发 StopIteratiaon 异常for score in scores_list_2:gen.send(score)gen.send(None)print("scores_list_1 is {0} \nscores_list_2 is {1}".format(res[0], res[1]))# result:# scores_list_1 is (434, 86.8)# scores_list_2 is (436, 87.2)
还可以看一个更加复杂的例子,它是 Python Cookbook 3 中给出的一个例子,它用到了yield from的嵌套。
现在我们就不用自己处理迭代结束的异常了,我们更能专注于业务代码的实现。yield from的内部其实做了更多的事情,详细内容可以参考 PEP380
为什么委托生成器里面要写while True,暂时还没弄清楚。
补充
- 子生成器产出的值会直接传递给调用方。
- 使用
send()发送给委托生成器的值都会直接传递给子生成器。如果发送的值为None,那么就调用自生成器的__next__()方法,启动子生成器,如果发送值非None,就调用子生成器的send()方法。 - 生成器退出时,
return expr会引出一个StopIteration的异常,具体的返回结果会作为异常中的第一个参数被一起带出来。 如果子生成器产生一个
StopIteration异常,委托生成器会处理掉它,然后继续向下执行,如果是其他类型的异常,则将它抛给委托生成器。协程
引言
生成器是可以暂停的函数
- 我们希望用同步的方式来编写异步的代码,在适当的时候暂停函数,然后在适当的时候启动它
协程是在一个线程内进行调度执行的,避免了使用各种复杂的锁机制,同时线程内的调度更加高效。
使用案例
yield from实现协程
```python def consumer(): while True:
data = yieldif not data:breakelse:print("Processing data [{0}]...".format(data))
return “All Done”
def producer(): status = yield from consumer() print(status) yield # 处理 StopIteration, 可行,但目前不知道为啥,或者在外面加 while True
if name == ‘main‘: data_list = [1, “MetaTian”, 3.456, None]
p = producer()p.send(None)for data in data_list:print("Sending data [{0}]...".format(data))p.send(data)
result:
Sending data [1]…
Processing data [1]…
Sending data [MetaTian]…
Processing data [MetaTian]…
Sending data [3.456]…
Processing data [3.456]…
Sending data [None]…
All Done
<a name="16ff4381"></a>### async 和 await(Python 3.5+)- 使用`yield from`也可以很好的实现协程的功能- 但有时候我们使用`yield`,只是为了纯粹使用生成器,有时又是为了实现协程- 在`Python 3.5`以后,为了将语义更加明确,就引入了这两个关键词,用来表示原生协程,但是内部还是用生成器的原理来实现的```pythonasync def first():return "Done"async def second():status = await first()print(status)coro = second()print(coro)try:coro.send(None)except StopIteration as e:pass# result:# <coroutine object second at 0x0000023BEFEDDF68># Done
使用async可以定义协程对象,await用来对相关操作进行挂起,就像生成器里的yield一样,函数这时会让出控制权,切换到别的协程中去,直到其他的协程也挂起或执行完毕。
await后面跟着的必须是一个Awaitable对象,或者是实现了相关的魔法函数——__await__(),Coroutine类就是继承了Awaitable。
协程具体要怎样协调起来完成我们的工作?这个放在下一个主题来讲吧,这里的内容已经很多了。

若有收获,就点个赞吧
0 人点赞
