核心组件
1、整体结构
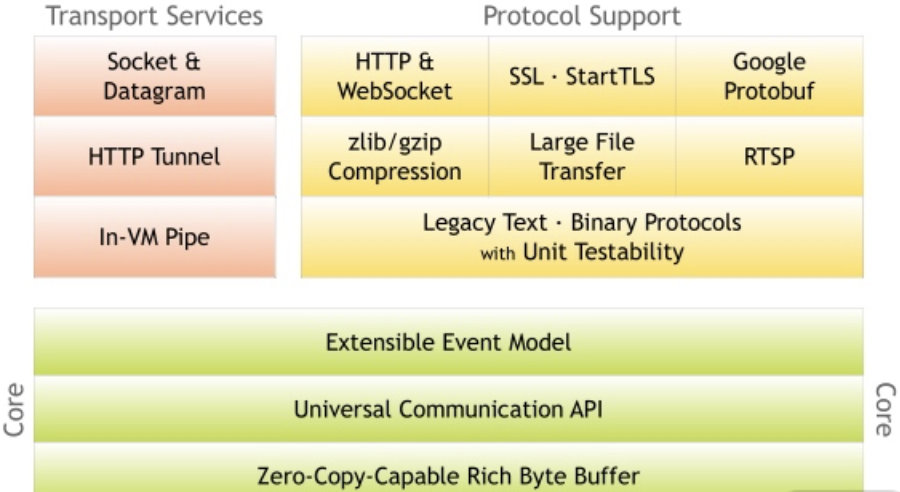
Core 核心层
Core 核心层是 Netty 最精华的内容,它提供了底层网络通信的通用抽象和实现,包括事件模型、通用API、支持零拷贝的 ByteBuf 等。
Protocol Support 协议支持层
协议支持层基本上覆盖了主流协议的编解码实现,如 HTTP、Protobuf、WebSocket、二进制等主流协议,此外 Netty 还支持自定义应用层协议。Netty 丰富的协议支持降低了用户的开发成本,基于 Netty 我们可以快速开发 HTTP、WebSocket 等服务。
Transport Service 传输服务层
传输服务层提供了网络传输能力的定义和实现方法。它支持 Socket、HTTP 隧道、虚拟机管道等传输方式。Netty 对 TCP、UDP 等数据传输做了抽象和封装,用户可以更聚焦在业务逻辑实现上,而不必关系底层数据传输的细节。
2、逻辑架构
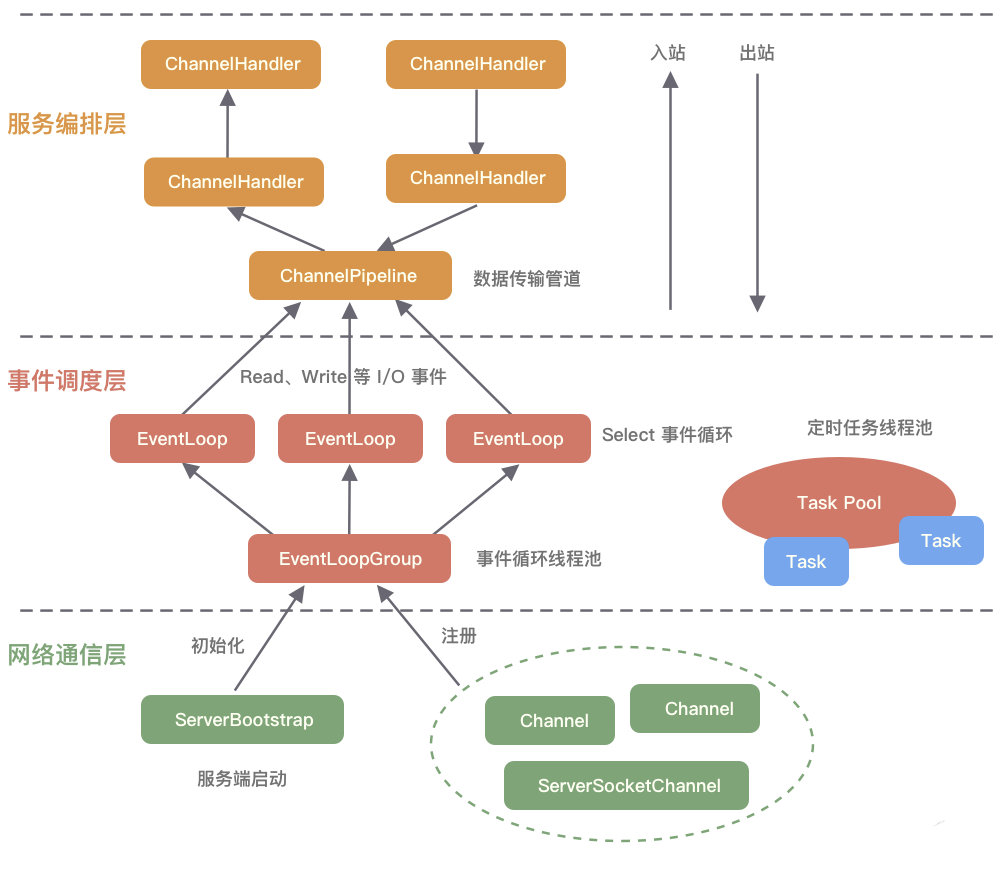
网络通信层
网络通信层的职责是执行网络 I/O 的操作。它支持多种网络协议和 I/O 模型的连接操作。当网络数据读取到内核缓冲区后,会触发各种网络事件,这些网络事件会分发给事件调度层进行处理。
网络通信层的核心组件包含BootStrap、ServerBootStrap、Channel三个组件。
Bootstrap 是“引导”的意思,负责 Netty 客户端程序的启动、初始化、服务器连接等过程,串联了 Netty 的其他核心组件。
ServerBootStrap 用于服务端启动绑定本地端口,会绑定Boss 和 Worker两个 EventLoopGroup。
Channel 的是“通道”,Netty Channel提供了基于NIO更高层次的抽象,如 register、bind、connect、read、write、flush 等。
事件调度层
事件调度层的职责是通过 Reactor 线程模型对各类事件进行聚合处理,通过 Selector 主循环线程集成多种事件( I/O 事件、信号事件、定时事件等),实际的业务处理逻辑是交由服务编排层中相关的 Handler 完成。
事件调度层的核心组件包括 EventLoopGroup、EventLoop。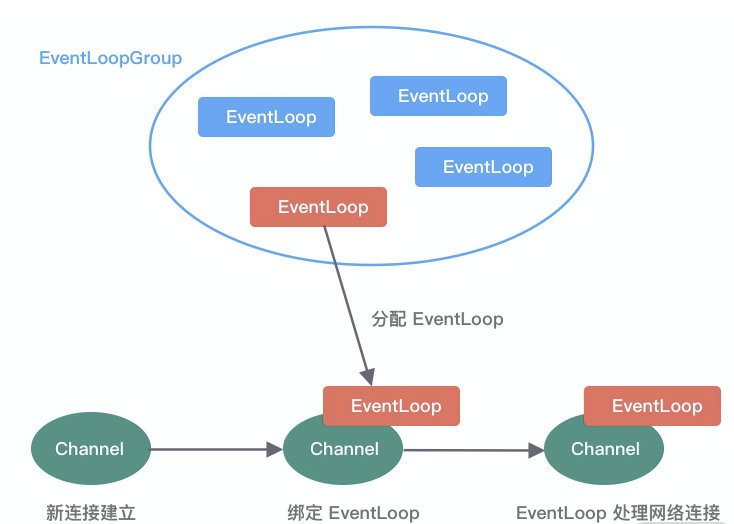
EventLoop 负责处理 Channel 生命周期内的所有 I/O 事件,如 accept、connect、read、write 等 I/O 事件
①一个 EventLoopGroup 往往包含一个或者多个 EventLoop。
②EventLoop 同一时间会与一个Channel绑定,每个 EventLoop 负责处理一种类型 Channel。
③Channel 在生命周期内可以对和多个 EventLoop 进行多次绑定和解绑。
EventLoopGroup 是Netty 的核心处理引擎,本质是一个线程池,主要负责接收 I/O 请求,并分配线程执行处理请求。通过创建不同的 EventLoopGroup 参数配置,就可以支持 Reactor 的三种线程模型:
单线程模型:EventLoopGroup 只包含一个 EventLoop,Boss 和 Worker 使用同一个EventLoopGroup;
多线程模型:EventLoopGroup 包含多个 EventLoop,Boss 和 Worker 使用同一个EventLoopGroup;
主从多线程模型:EventLoopGroup 包含多个 EventLoop,Boss 是主 Reactor,Worker 是从 Reactor,它们分别使用不同的 EventLoopGroup,主 Reactor 负责新的网络连接 Channel 创建,然后把 Channel 注册到从 Reactor。
服务编排层
服务编排层的职责是负责组装各类服务,它是 Netty 的核心处理链,用以实现网络事件的动态编排和有序传播。
服务编排层的核心组件包括 ChannelPipeline、ChannelHandler、ChannelHandlerContext。
ChannelPipeline 是 Netty 的核心编排组件,负责组装各种 ChannelHandler,ChannelPipeline 内部通过双向链表将不同的 ChannelHandler 链接在一起。当 I/O 读写事件触发时,Pipeline 会依次调用 Handler 列表对 Channel 的数据进行拦截和处理。
客户端和服务端都有各自的 ChannelPipeline。客户端和服务端一次完整的请求:客户端出站(Encoder 请求数据)、服务端入站(Decoder接收数据并执行业务逻辑)、服务端出站(Encoder响应结果)。
ChannelHandler 完成数据的编解码以及处理工作。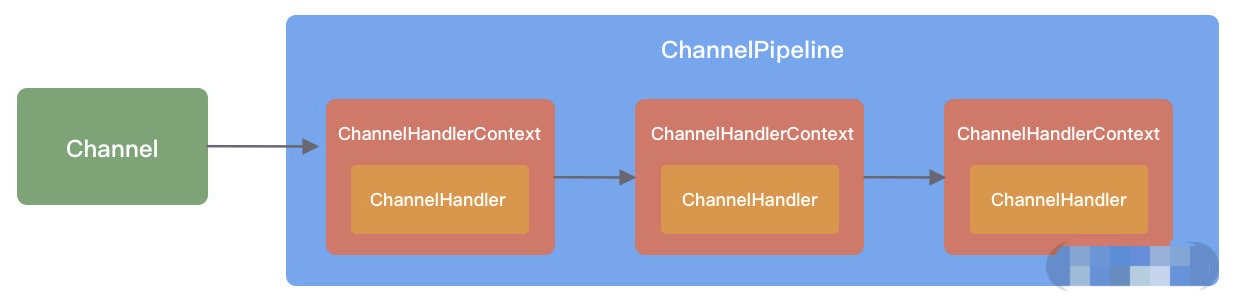
ChannelHandlerContext 用于保存Handler 上下文,通过 HandlerContext 我们可以知道 Pipeline 和 Handler 的关联关系。HandlerContext 可以实现 Handler 之间的交互,HandlerContext 包含了 Handler 生命周期的所有事件,如 connect、bind、read、flush、write、close 等。同时,HandlerContext 实现了Handler通用的逻辑的模型抽象。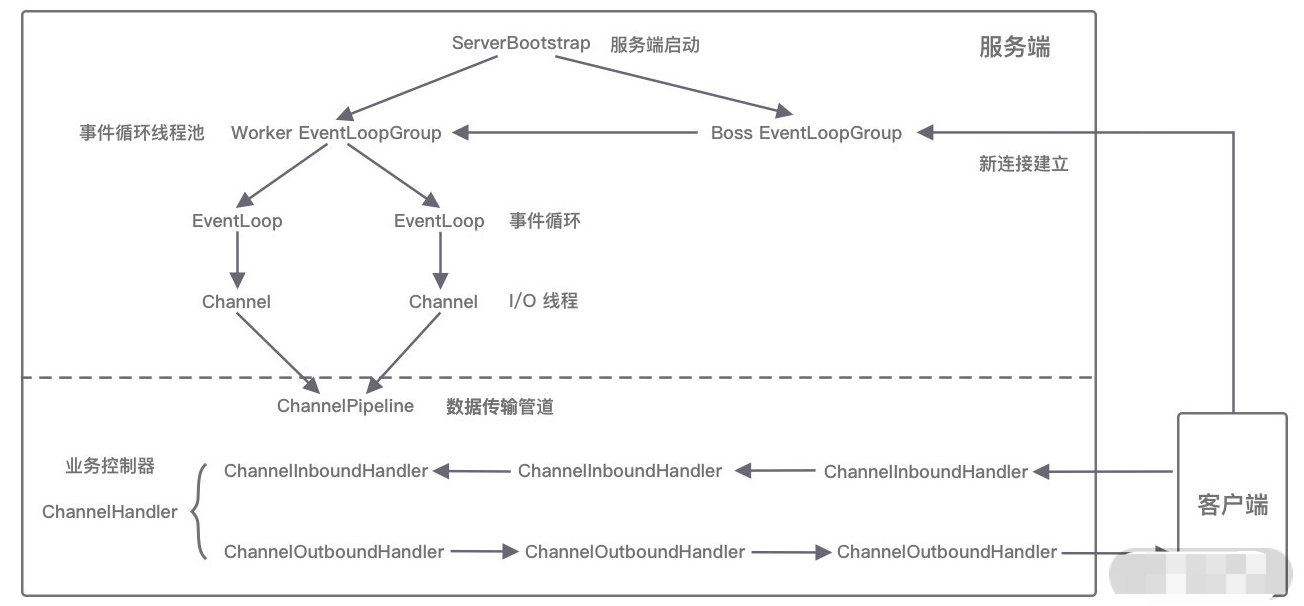
网络传输
1、五种IO模型的区别
阻塞I/O:(BIO)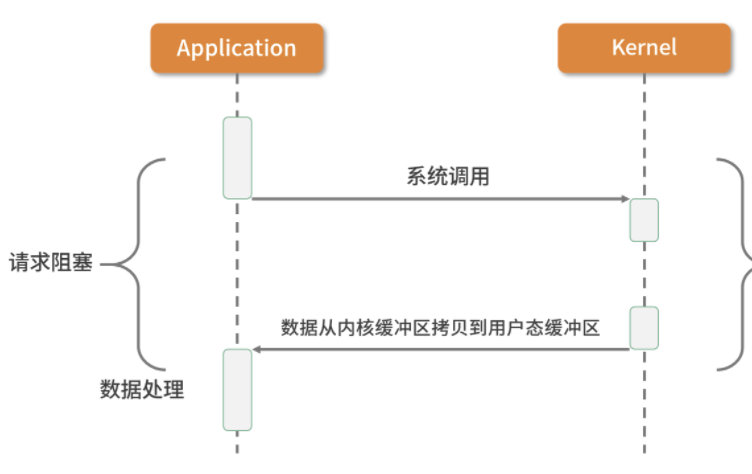
应用进程向内核发起 I/O 请求,发起调用的线程一直等待内核返回结果。一次完整的 I/O 请求称为BIO(Blocking IO,阻塞 I/O),所以 BIO 在实现异步操作时,只能使用多线程模型,一个请求对应一个线程。但是,线程的资源是有限且宝贵的,创建过多的线程会增加线程切换的开销。
同步非阻塞I/O(NIO):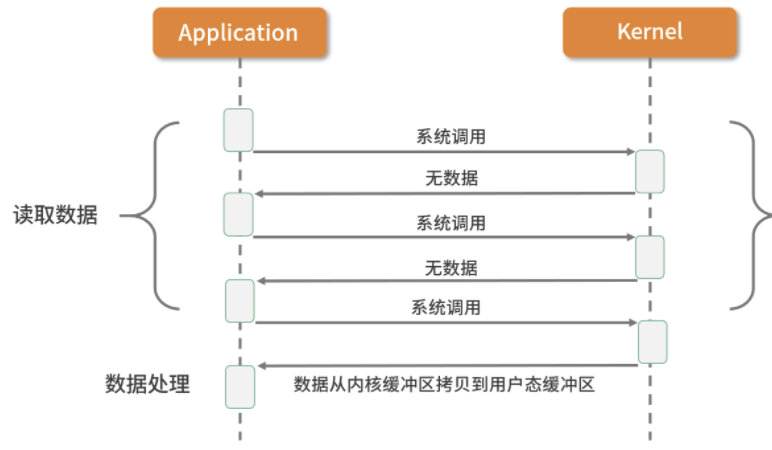
应用进程向内核发起 I/O 请求后不再会同步等待结果,而是会立即返回,通过轮询的方式获取请求结果。NIO 相比 BIO 虽然大幅提升了性能,但是轮询过程中大量的系统调用导致上下文切换开销很大。所以,单独使用非阻塞 I/O 时效率并不高,而且随着并发量的提升,非阻塞 I/O 会存在严重的性能浪费。
多路复用I/O(select和poll):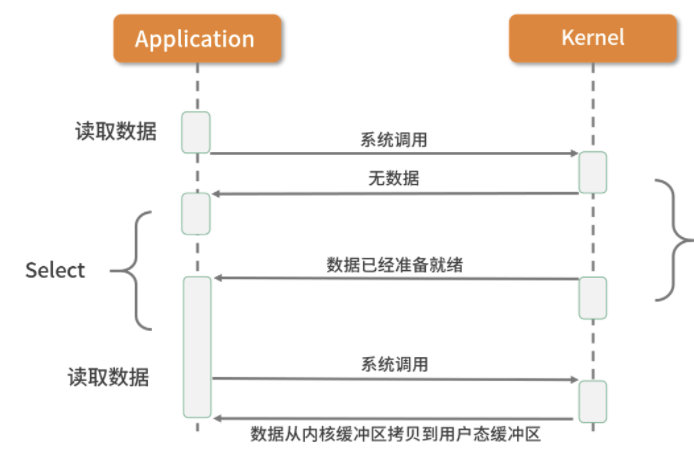
多路复用实现了一个线程处理多个 I/O 句柄的操作。多路指的是多个数据通道,复用指的是使用一个或多个固定线程来处理每一个 Socket。select、poll、epoll 都是 I/O 多路复用的具体实现,线程一次 select 调用可以获取内核态中多个数据通道的数据状态。其中,select只负责等,recvfrom只负责拷贝,阻塞IO中可以对多个文件描述符进行阻塞监听,是一种非常高效的 I/O 模型。
信号驱动I/O(SIGIO):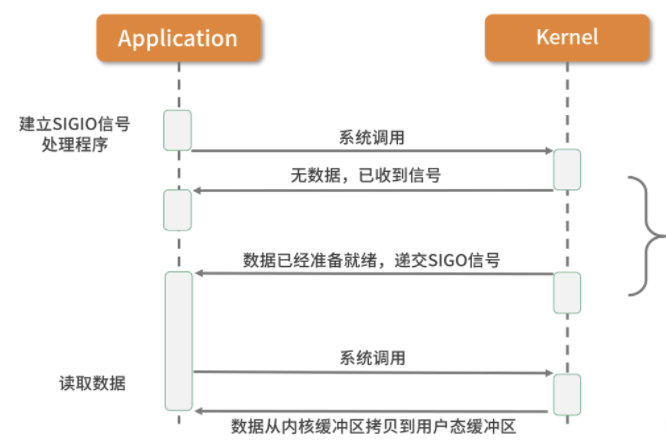
信号驱动IO模型,应用进程告诉内核:当数据报准备好的时候,给我发送一个信号,对SIGIO信号进行捕捉,并且调用我的信号处理函数来获取数据报。
异步I/O(Posix.1的aio_系列函数):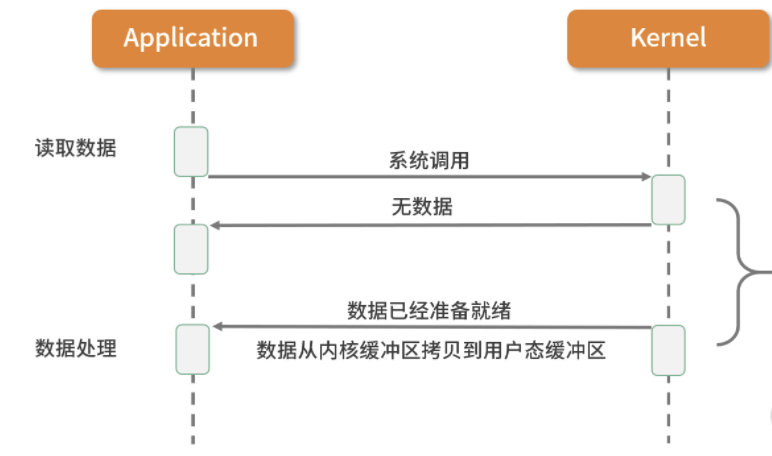
当应用程序调用aio_read时,内核一方面去取数据报内容返回,另一方面将程序控制权还给应用进程,应用进程继续处理其他事情,是一种非阻塞的状态。当内核中有数据报就绪时,由内核将数据报拷贝到应用程序中,返回aio_read中定义好的函数处理程序。
2、Reactor多线程模型
Netty 的 I/O 模型是基于非阻塞 I/O 实现的,底层依赖的是 NIO 框架的多路复用器 Selector。采用 epoll 模式后,只需要一个线程负责 Selector 的轮询。当有数据处于就绪状态后,需要一个事件分发器(Event Dispather),它负责将读写事件分发给对应的读写事件处理器(Event Handler)。事件分发器有两种设计模式:Reactor 和 Proactor,Reactor 采用同步 I/O, Proactor 采用异步 I/O。
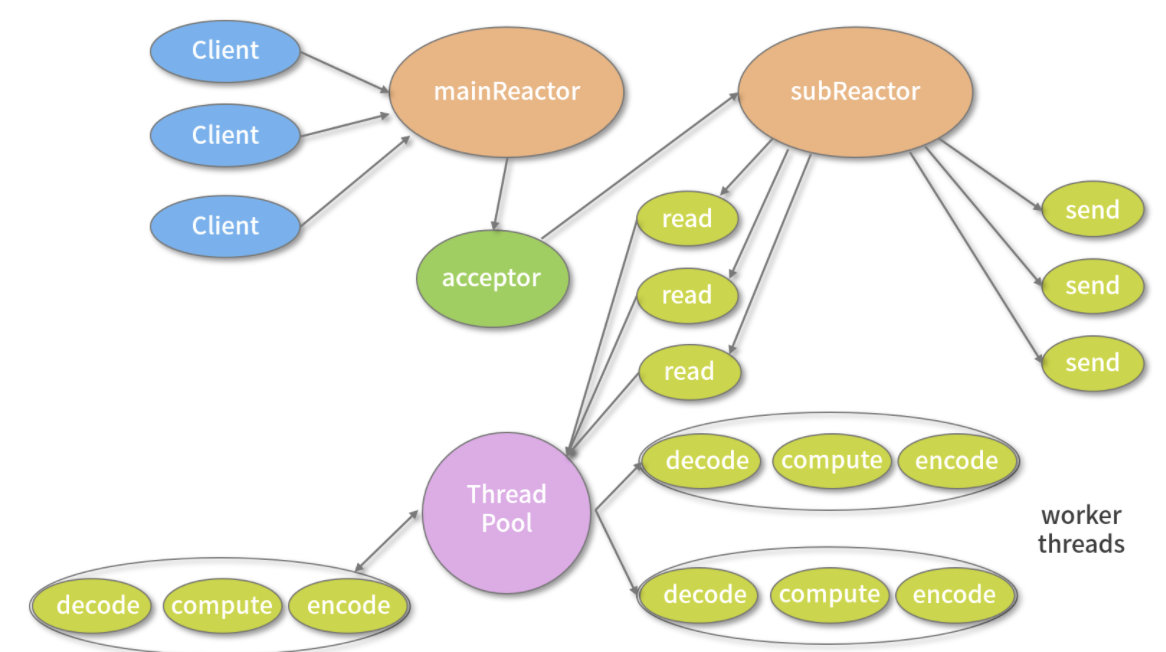
Reactor 实现相对简单,适合处理耗时短的场景,对于耗时长的 I/O 操作容易造成阻塞。Proactor 性能更高,但是实现逻辑非常复杂,适合图片或视频流分析服务器,目前主流的事件驱动模型还是依赖 select 或 epoll 来实现。
3、拆包粘包问题
拆包TCP 传输协议是面向流的,没有数据包界限。
MTU(Maxitum Transmission Unit) 是链路层一次最大传输数据的大小。MTU 一般来说大小为 1500 byte。MSS(Maximum Segement Size) 是指 TCP 最大报文段长度,它是传输层一次发送最大数据的大小。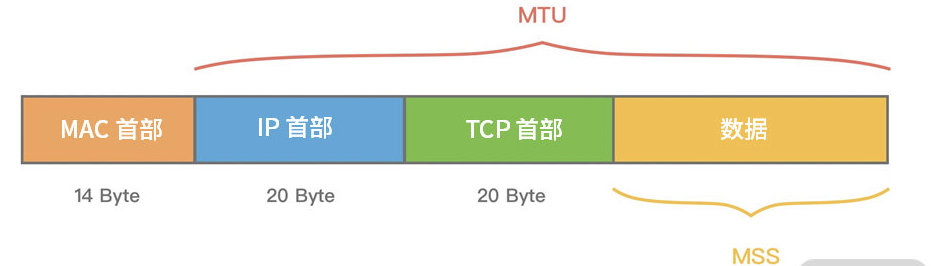
如上图所示,如果 MSS + TCP 首部 + IP 首部 > MTU,那么数据包将会被拆分为多个发送。这就是拆包现象。
Nagle 算法
Nagle 算法可以理解为批量发送,也是我们平时编程中经常用到的优化思路,它是在数据未得到确认之前先写入缓冲区,等待数据确认或者缓冲区积攒到一定大小再把数据包发送出去。Netty 中为了使数据传输延迟最小化,就默认禁用了 Nagle 算法。
拆包/粘包的解决方案
在客户端和服务端通信的过程中,服务端一次读到的数据大小是不确定的。需要确定边界:
消息长度固定
特定分隔符
消息长度 + 消息内容(Netty)
4、自定义协议
Netty 常用编码器类型:
MessageToByteEncoder //对象编码成字节流; MessageToMessageEncoder //一种消息类型编码成另外一种消息类型。
Netty 常用解码器类型:
ByteToMessageDecoder/ReplayingDecoder //将字节流解码为消息对象; MessageToMessageDecoder //将一种消息类型解码为另外一种消息类型。
编解码器可以分为一次解码器和二次解码器,一次解码器用于解决 TCP 拆包/粘包问题,按协议解析后得到的字节数据。如果你需要对解析后的字节数据做对象模型的转换,这时候便需要用到二次解码器,同理编码器的过程是反过来的。
Netty自定义协议内容:
/ +———————————————————————————————-+ | 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte | +———————————————————————————————-+ | 状态 1byte | 保留字段 4byte | 数据长度 4byte | +———————————————————————————————-+ | 数据内容 (长度不定) | +———————————————————————————————-+ /
如何判断 ByteBuf 是否存在完整的报文?最常用的做法就是通过读取消息长度 dataLength 进行判断。如果 ByteBuf 的可读数据长度小于 dataLength,说明 ByteBuf 还不够获取一个完整的报文。
5、WriteAndFlush
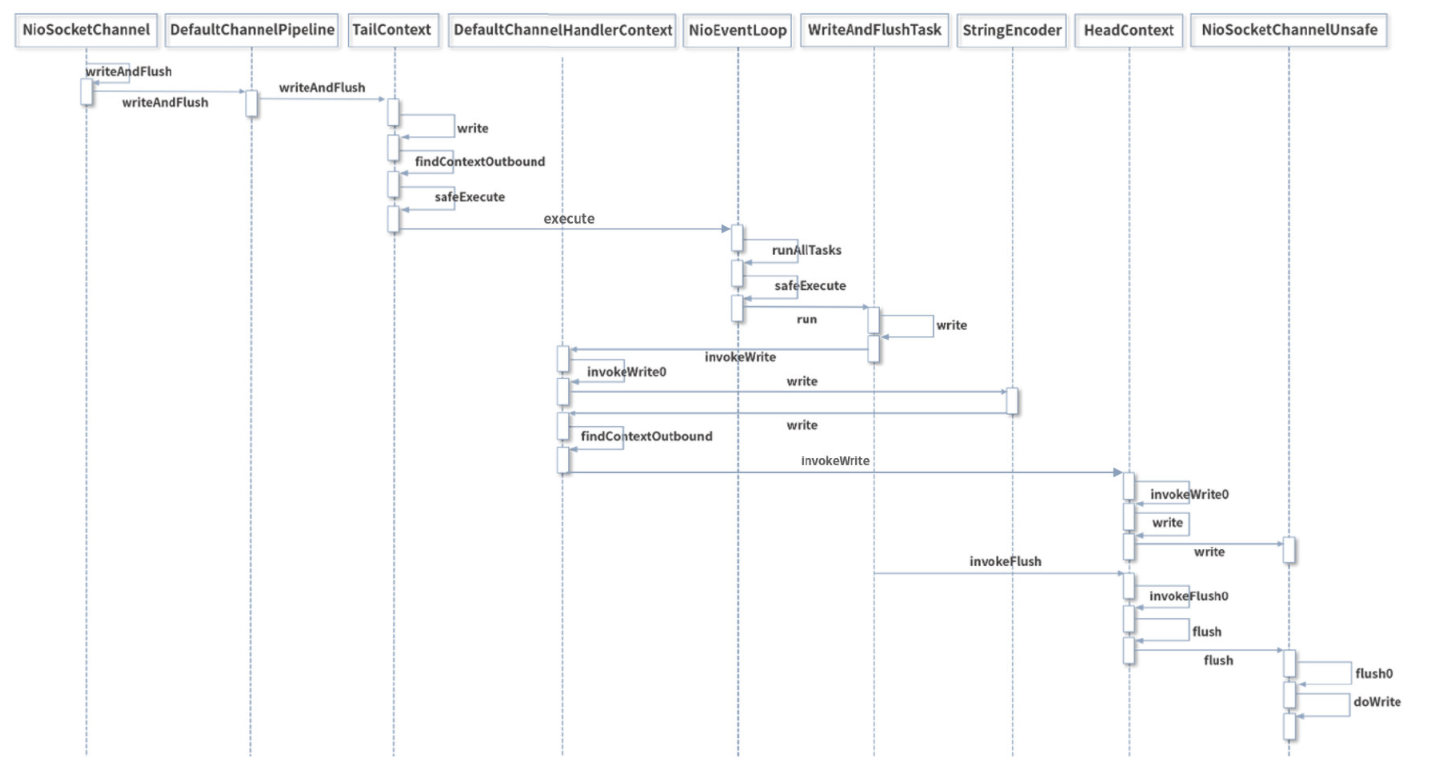
①writeAndFlush 属于出站操作,它是从 Pipeline 的 Tail 节点开始进行事件传播,一直向前传播到 Head 节点。不管在 write 还是 flush 过程,Head 节点都中扮演着重要的角色。
②write 方法并没有将数据写入 Socket 缓冲区,只是将数据写入到 ChannelOutboundBuffer 缓存中,ChannelOutboundBuffer 缓存内部是由单向链表实现的。
③flush 方法才最终将数据写入到 Socket 缓冲区。
内存管理
1、堆外内存
在 Java 中对象都是在堆内分配的,通常我们说的JVM 内存也就指的堆内内存,堆内内存完全被JVM 虚拟机所管理,JVM 有自己的垃圾回收算法,对于使用者来说不必关心对象的内存如何回收。堆外内存与堆内内存相对应,对于整个机器内存而言,除堆内内存以外部分即为堆外内存。堆外内存不受 JVM 虚拟机管理,直接由操作系统管理。使用堆外内存有如下几个优点:
- 堆内内存由 JVM GC 自动回收内存,降低了 Java 用户的使用心智,堆外内存由于不受 JVM 管理,所以在一定程度上可以降低 GC 对应用运行时带来的影响。
- 堆外内存需要手动释放,这一点跟 C/C++ 很像,稍有不慎就会造成应用程序内存泄漏,当出现内存泄漏问题时排查起来会相对困难。
- 当进行网络 I/O 操作、文件读写时,堆内内存都需要转换为堆外内存,然后再与底层设备进行交互,所以直接使用堆外内存可以减少一次内存拷贝。
- 堆外内存可以方便实现进程之间、JVM 多实例之间的数据共享。
在堆内存放的 DirectByteBuffer 对象并不大,仅仅包含堆外内存的地址、大小等属性,同时还会创建对应的 Cleaner 对象,通过 ByteBuffer 分配的堆外内存不需要手动回收,它可以被 JVM 自动回收。当堆内的 DirectByteBuffer 对象被 GC 回收时,Cleaner 就会用于回收对应的堆外内存。

若有收获,就点个赞吧
0 人点赞
