、硬件故障排查
如果一个实例发生了问题,根据情况选择,要不要着急去重启。如果出现的CPU、内存飙高或者日志里出现了OOM异常
第一步是隔离,第二步是保留现场,第三步才是问题排查。
隔离
就是把你的这台机器从请求列netstat -s > $DUMP_DIR/netstat-s.dump 2>&1
它能够按照各个协议进行统计输出,对把握当时整个网络状态,有非常大的作用。
sar -n DEV 1 2 > $DUMP_DIR/sar-traffic.dump 2>&1
在一些速度非常高的模块上,比如 Redis、Kafka,就经常发生跑满网卡的情况。表现形式就是网络通信非常缓慢。
(3)进程资源
lsof -p $PID > $DUMP_DIR/lsof-$PID.dump
通过查看进程,能看到打开了哪些文件,可以以进程的维度来查看整个资源的使用情况,包括每条网络连接、每个打开的文件句柄。同时,也可以很容易的看到连接到了哪些服务器、使用了哪些资源。这个命令在资源非常多的情况下,输出稍慢,请耐心等待。
(4)CPU 资源
mpstat > $DUMP_DIR/mpstat.dump 2>&1vmstat 1 3 > $DUMP_DIR/vmstat.dump 2>&1sar -p ALL > $DUMP_DIR/sar-cpu.dump 2>&1uptime > $DUMP_DIR/uptime.dump 2>&1
主要用于输出当前系统的 CPU 和负载,便于事后排查。
(5)I/O 资源
iostat -x > $DUMP_DIR/iostat.dump 2>&1
一般,以计算为主的服务节点,I/O 资源会比较正常,但有时也会发生问题,比如日志输出过多,或者磁盘问题等。此命令可以输出每块磁盘的基本性能信息,用来排查 I/O 问题。在第 8 课时介绍的 GC 日志分磁盘问题,就可以使用这个命令去发现。
(6)内存问题
free -h > $DUMP_DIR/free.dump 2>&1
free 命令能够大体展现操作系统的内存概况,这是故障排查中一个非常重要的点,比如 SWAP 影响了 GC,SLAB 区挤占了 JVM 的内存。
(7)其他全局
ps -ef > $DUMP_DIR/ps.dump 2>&1dmesg > $DUMP_DIR/dmesg.dump 2>&1sysctl -a > $DUMP_DIR/sysctl.dump 2>&1
dmesg 是许多静悄悄死掉的服务留下的最后一点线索。当然,ps 作为执行频率最高的一个命令,由于内核的配置参数,会对系统和 JVM 产生影响,所以我们也输出了一份。
(8)进程快照,最后的遗言(jinfo)
${JDK_BIN}jinfo $PID > $DUMP_DIR/jinfo.dump 2>&1表里摘除,比如把 nginx 相关的权重设成零。
现场保留
瞬时态和历史态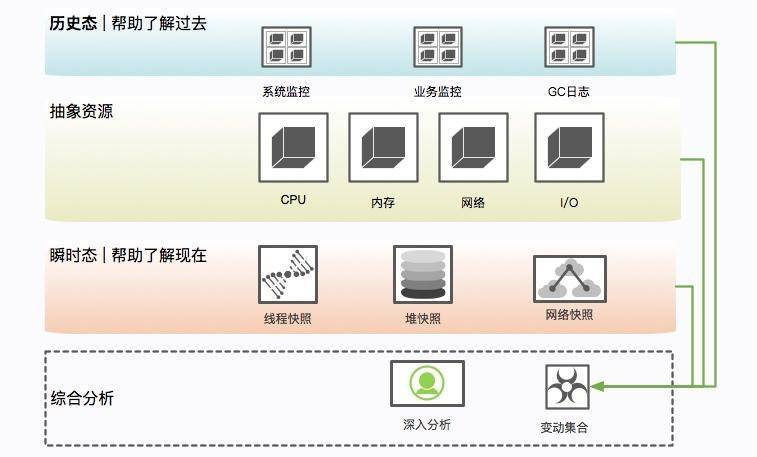
查看比如 CPU、系统内存等,通过历史状态可以体现一个趋势性问题,而这些信息的获取一般依靠监控系统的协作。
保留信息
(1)系统当前网络连接
ss -antp > $DUMP_DIR/ss.dump 2>&1
使用 ss 命令而不是 netstat 的原因,是因为 netstat 在网络连接非常多的情况下,执行非常缓慢。
后续的处理,可通过查看各种网络连接状态的梳理,来排查 TIME_WAIT 或者 CLOSE_WAIT,或者其他连接过高的问题,非常有用。
(2)网络状态统计
此命令将输出 Java 的基本进程信息,包括环境变量和参数配置,可以查看是否因为一些错误的配置造成了 JVM 问题。
(9)dump 堆信息
${JDK_BIN}jstat -gcutil $PID > $DUMP_DIR/jstat-gcutil.dump 2>&1${JDK_BIN}jstat -gccapacity $PID > $DUMP_DIR/jstat-gccapacity.dump 2>&1
jstat 将输出当前的 gc 信息。一般,基本能大体看出一个端倪,如果不能,可将借助 jmap 来进行分析。
(10)堆信息
${JDK_BIN}jmap $PID > $DUMP_DIR/jmap.dump 2>&1${JDK_BIN}jmap -heap $PID > $DUMP_DIR/jmap-heap.dump 2>&1${JDK_BIN}jmap -histo $PID > $DUMP_DIR/jmap-histo.dump 2>&1${JDK_BIN}jmap -dump:format=b,file=$DUMP_DIR/heap.bin $PID > /dev/null 2>&1
jmap 将会得到当前 Java 进程的 dump 信息。如上所示,其实最有用的就是第 4 个命令,但是前面三个能够让你初步对系统概况进行大体判断。因为,第 4 个命令产生的文件,一般都非常的大。而且,需要下载下来,导入 MAT 这样的工具进行深入分析,才能获取结果。这是分析内存泄漏一个必经的过程。
(11)JVM 执行栈
${JDK_BIN}jstack $PID > $DUMP_DIR/jstack.dump 2>&1
jstack 将会获取当时的执行栈。一般会多次取值,我们这里取一次即可。这些信息非常有用,能够还原 Java 进程中的线程情况。
top -Hp $PID -b -n 1 -c > $DUMP_DIR/top-$PID.dump 2>&1
为了能够得到更加精细的信息,我们使用 top 命令,来获取进程中所有线程的 CPU 信息,这样,就可以看到资源到底耗费在什么地方了。
(12)高级替补
kill -3 $PID
有时候,jstack 并不能够运行,有很多原因,比如 Java 进程几乎不响应了等之类的情况。我们会尝试向进程发送 kill -3 信号,这个信号将会打印 jstack 的 trace 信息到日志文件中,是 jstack 的一个替补方案。
gcore -o $DUMP_DIR/core $PID
对于 jmap 无法执行的问题,也有替补,那就是 GDB 组件中的 gcore,将会生成一个 core 文件。我们可以使用如下的命令去生成 dump:
${JDK_BIN}jhsdb jmap —exe ${JDK}java —core $DUMP_DIR/core —binaryheap
复制
- 内存泄漏的现象
稍微提一下 jmap 命令,它在 9 版本里被干掉了,取而代之的是 jhsdb,你可以像下面的命令一样使用。
jhsdb jmap —heap —pid 37340jhsdb jmap —pid 37288jhsdb jmap —histo —pid 37340jhsdb jmap —binaryheap —pid 37340
一般内存溢出,表现形式就是 Old 区的占用持续上升,即使经过了多轮 GC 也没有明显改善。比如ThreadLocal里面的GC Roots,内存泄漏的根本就是,这些对象并没有切断和 GC Roots 的关系,可通过一些工具,能够看到它们的联系。
2、报表异常 | JVM调优
有一个报表系统,频繁发生内存溢出,在高峰期间使用时,还会频繁的发生拒绝服务,由于大多数使用者是管理员角色,所以很快就反馈到研发这里。
业务场景是由于有些结果集的字段不是太全,因此需要对结果集合进行循环,并通过 HttpClient 调用其他服务的接口进行数据填充。使用 Guava 做了 JVM 内缓存,但是响应时间依然很长。
初步排查,JVM 的资源太少。接口 A 每次进行报表计算时,都要涉及几百兆的内存,而且在内存里驻留很长时间,有些计算又非常耗 CPU,特别的“吃”资源。而我们分配给 JVM 的内存只有 3 GB,在多人访问这些接口的时候,内存就不够用了,进而发生了 OOM。在这种情况下,没办法,只有升级机器。把机器配置升级到 4C8G,给 JVM 分配 6GB 的内存,这样 OOM 问题就消失了。但随之而来的是频繁的 GC 问题和超长的 GC 时间,平均 GC 时间竟然有 5 秒多。
进一步,由于报表系统和高并发系统不太一样,它的对象,存活时长大得多,并不能仅仅通过增加年轻代来解决;而且,如果增加了年轻代,那么必然减少了老年代的大小,由于 CMS 的碎片和浮动垃圾问题,我们可用的空间就更少了。虽然服务能够满足目前的需求,但还有一些不太确定的风险。
第一,了解到程序中有很多缓存数据和静态统计数据,为了减少 MinorGC 的次数,通过分析 GC 日志打印的对象年龄分布,把 MaxTenuringThreshold 参数调整到了 3(特殊场景特殊的配置)。这个参数是让年轻代的这些对象,赶紧回到老年代去,不要老呆在年轻代里。
第二,我们的 GC 时间比较长,就一块开了参数 CMSScavengeBeforeRemark,使得在 CMS remark 前,先执行一次 Minor GC 将新生代清掉。同时配合上个参数,其效果还是比较好的,一方面,对象很快晋升到了老年代,另一方面,年轻代的对象在这种情况下是有限的,在整个 MajorGC 中占的时间也有限。
第三,由于缓存的使用,有大量的弱引用,拿一次长达 10 秒的 GC 来说。我们发现在 GC 日志里,处理 weak refs 的时间较长,达到了 4.5 秒。这里可以加入参数 ParallelRefProcEnabled 来并行处理Reference,以加快处理速度,缩短耗时。
优化之后,效果不错,但并不是特别明显。经过评估,针对高峰时期的情况进行调研,我们决定再次提升机器性能,改用 8core16g 的机器。但是,这带来另外一个问题。

若有收获,就点个赞吧
0 人点赞
