2.1.1 C99中的预定义宏
C++11中与C99兼容的宏:
__STDC_HOSTED__
如果编译器的目标系统环境中包含完整的标准C,那么这个宏就定义为1,否则宏的值为0__STDC__
C编译器通常用这个宏的值来表示编译器的实现是否和C标准一致。C++11标准中这个宏是否定义以及定成什么值由编译器来决定__STDC_VERSION__
C编译器通常用这个宏来表示所支持的C标准的版本,比如1999mmL。C++11标准中这个宏是否定义以及定成什么值将由编译器来决定__STDC_ISO_10646__
这个宏通常定义为一个yyyymmL格式的整数常量,例如199712L,用来表示C++编译环境符合某个版本的ISO/IEC 10646标准
代码清单
#include <iostream>using namespace std;int main(int argc, char* argv[]){cout << "Standard Clib " << __STDC_HOSTED__ << endl;// 使用QtCreator, 以下三个宏都没有// cout << "Standard C " << __STDC__ << endl;// cout << "C Standard version " << __STDC_VERSION__ << endl;// cout << "ISO/IEC " << __STDC_ISO__10646__ << endl;return 0;}
注意
与所有预定义宏相同的,如果用户重定义(#define)或#undef了预定义的宏,那么后果是“未定义”的。 因此在代码编写中,程序员应该注意避免自定义宏与预定义宏同名的情况。
2.1.2 func预定义标识符
功能: 返回所在函数的名字
用途: func预定义标识符对于轻量级的调试代码具有十分重要的作用
using namespace std;
string hello() { return func; }
string world() { return func; }
int main() { cout << hello() << “, “ << world() << endl; // 输出 hello, world return 0; }
`hello`函数的实际定义等同于如下代码```cppstring hello(){static const string __func__ = "hello";return __func__;}
using namespace std;
struct TestStruct { TestStruct() : name(func) { } string name; };
int main() { TestStruct ts; cout << ts.name << endl; // shu输出 TestStruct return 0; }
- 将__func__标识符作为函数参数的默认值是不被允许的,例如:```cpp// 无法通过编译// 因为在参数声明时, __func__还未被定义void FuncFail(string func_name = __func__) {};
2.1.3 __Pragma
a. #parma
功能:#parma是一条预处理的指令,用来向编译器传达语言标准以外的一些信息
用途:指示编译器,该头文件应该只被编译一次
// 两种等效的方法// 方法1#pragma once// 方法2#ifndef THIS_HEADER#define THIS_HEADER// 一些头文件的定义#endif
b. __Pragma
功能:同#parma
达到与#pragma once类似效果的代码:
_Pragma("once") // 与#pragma once 效果类似
2.1.4 变长参数的宏定义以及VA_ARGS
变长参数的宏定义是指在宏定义中参数列表的最后一个参数为省略号,而预定义宏VA_args则在宏定义的实现部分替换省略号所代表的字符串。
#define PR(...) print(__VA_ARGS__)
例如:定义LOG宏用于记录代码位置中的一些信息
#include <stdio.h>#define LOG(...) \{ \fprintf(stderr, "%s: Line %d:\t", __FILE__, __LINE__); \fprintf(stderr, __VA_ARGS__); \fprintf(stderr, "\n"); \}int main(){int x = 3;LOG("x=%d", x); // 输出 ..\untitled6\main.cpp: Line 11: x=3}
2.1.5 宽窄字符串的连接
将窄字符串(char)转换成宽字符串(wchar_t)是未定义的行为。
而在C++11标准中,在将窄字符串和宽字符串进行连接时,支持C++11标准的编译器会将窄字符串转换成宽字符串,然后再与宽字符串进行连接。
2.2 long long整型
long long 整型有两种
- long long
- 使用
LL、ll后缀标识
- 使用
- unsigned long long
- 使用
ull、Ull、uLL后缀标识
- 使用
查看long long大小的方法:
- 查看
<climits> 查看
<limits.h>中的宏与 long long 整型相关的一共有3个:
LLONG_MIN最小的long long值LLONG_MAX最大 的long long值ULLONG_MIN最大的unsigned long long值。
代码示例:
#include <climits>#include <cstdio>#include <iostream>using namespace std;int main(){// min of long long: -9223372036854775808long long ll_min = LLONG_MIN;printf(" min of long long: %lld\n", ll_min);// max of long long: 9223372036854775807long long ll_max = LLONG_MAX;printf(" max of long long: %lld\n", ll_max);// max of unsigned long long: 18446744073709551615unsigned long long ull_max = ULLONG_MAX;printf(" max of unsigned long long: %llu\n", ull_max);}
2.3 扩展的整型
C++11中一共定义以下5种有符号整型
- signed char
- short int
- int
- long int
- long long int
C++标准允许编译器扩展自由的所谓扩展整型,这些扩展整型的长度(占用内存的位数)可以比最长的标准整型还长,也可以介于两个标准正数的位数之间。例如:
- 在128位的架构上,编译器可以定义一个扩展类型来对应128位的整数
- 在一些嵌入式平台上,也可能需要扩展出48位的整型
C++11标准并没有对扩展出的类型的名称有任何的规定或建议,只是对扩展整型的使用规则做出了一定的限制。 即:C++11规定,扩展的整型必须和标准类型一样,有符号类型和无符号类型占用同意大小的内存空间。
当运算、传参等类型不匹配的时候,整型间会发生隐式的转换,这种过程通常被称为整型的提升。比如(int) a + (long long) b,通常就会导致变量(int)a被提升为long long类型后才与(long long)b进行运算。而无论是扩展的整型还是标准的整型,其转化的规则会由它们的”等级”决定。而通常情况,我们认为有如下原则:
- 长度越大的整型等级越高,比如
long long int的等级会高于int。 - 长度相同的情况下,标准整型的等级高于扩展类型,比如
long long int和_int64如果都是64位长度,则long long int类型的等级更高。 - 相同大小的有符号类型和无符号类型的等级相同,
long long int和unsigned long long int的等级就相同。同C++98的转换规则,在进行隐式的整型转换的时候,一般是按照低等级整型转换为高等级整型,有符号的转换为无符号。
2.4 宏 __cplusplus
在 C 与 C++ 混合编写的代码中, 我们常常会在头文件里看到如下的声明:
#ifdef __cplusplusextern "C" {#endif// 一些代码#ifdef __cplusplus}#endif
这种类型的头文件可以被#include到C文件中进行编译,也可以被#include到C++文件中进行编译。
由于extern "C"可以抑制C++对函数名 、变量名等符号(symbol)进行名称重整(namemangling),因此编译出的C目标文件和C++目标文件中的变量、函数名称等符号都是相同的(否则不相同),链接器可以可靠地对两种类型的目标文件进行链接。这样该做法成为了C与C++混用头文件的典型做法。
cplusplus这个宏通常被定义为一个整型值,而且随着标准变化,cplusplus宏一般会是一个比以往标准中更大的值。例如:
- C++03标准:__cplusplus的值被预定为199711L
- C++11标准:__cplusplus的值被预定为201103L
这点变化可以为代码所用,比如程序员在想确定代码是使用支持C++11编译器进行编译时,那么可以按下面的方法进行检测:
#if __cplusplus < 201103L#error "shorld use C++11 implementation#endif
2.5 静态断言
2.5.1 断言:运行时与预处理时
断言是一种编程中常用的手段。在通常情况下,断言就是将一个返回值总是需要为真的判别式放在语句中,用于排除在设计的逻辑上不应该产生的情况。
比如一个函数总需要输入在一定的范围内的参数,那么程序员就可以对该参数使用断言,以迫使在该参数发生异常的时候程序退出,从而避免程序陷入逻辑的混乱。通常断言能够帮助程序开发者快速定位那些违反了某些前提条件的程序错误。
在C++中,标准在<cassert>或<assert.h>头文件中为程序员提供了assert宏,用于在运行时进行断言。
例如:
#include <cassert>using namespace std; // 一个简单的堆内存数组分配函数char* ArrayAlloc(int n){assert(n > 0); // 断言,n必须大于0return new char[n];}int main(){char* a = ArrayAlloc(0);}
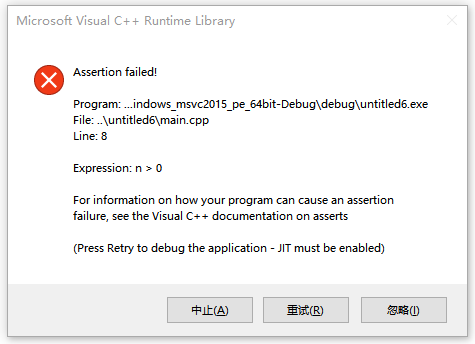
当发布程序时,使用定义宏NDEBUG来禁用assert宏
#define NDEBUG
assert宏在
#ifdef NDEBUG#define assert(expr) (static_cast<void> (0))#else// ...#endif
可以看到,一旦定义了 NDBUG 宏,assert 宏将被展开为一条无意义的 C 语句(通常会被编译器优化掉)。
#error 预处理指令
事实上, 通过预处理指令 #if 和 #error 的配合,也可以让程序员在预处理阶段进行断言。
#ifndef _COMPLEX_H#error "Never use <**.h>" directly;#endif// 通过预处理时的断言, 库发布者就可以避免一些头文件的引用问题
2.5.2 静态断言与static_assert
例一:
#include <cassert>using namespace std;// 枚举编译器对各种特性的支持,每个枚举值占一位enum FeatureSupports {C99 = 0x0001,ExtInt = 0x0002,SAssert = 0x0003,NoExcept = 0x0004,SMAX = 0x0005,};// 一个编译器类型,包括名称、特性支持等struct Compiler {const char* name;int spp;};int main(){// 检查枚举值是否完备assert((SMAX - 1) == (C99 | ExtInt | SAssert | NoExcept));Compiler a = { "abc", (C99 | SAssert) };// ...if (a.spp & C99) {// 一些代码...}}
上述代码所示的是 C 代码中常见的“按位存储属性”的例子。在该例中,我们编写了一个枚举类型FeatureSupports,用于列举编译器对各种特性的支持。而结构体Compiler则包含了一个int类型成员spp。由于由于各种特性都具有“支持”和“不支持”两种状态,所以为了节省存储空间,我们让每个FeatureSupports的枚举值占据一个特定的比特位置,并在使用时通过“或”运算压缩地存储在Compiler的spp成员中(即bitset的概念)。在使用时,则可以通过检查spp的某位来判断编译器对特性是否支持。
有的时候这样的枚举值会非常多,而且还会在代码维护中不断增加。那么代码编写者必须想出办法来对这些枚举进行校验,比如查验一下是否有重位等。在本例中程序员的做法是使用一个“最大枚举”SMAX,并通过比较SMAX-1与所有其他枚举的或运算值来验证是否有枚举值重位。可以想象,如果SAssert被误定义为0x0001,表达式(SMAX - 1) == ( C99 | ExtInt | SAssert | NoExcept )将不再成立。
在本例中我们使用了断言assert。但assert是一个运行时的断言,这意味着不运行程序我们将无法得知是否有枚举重位。在一些情况下,这是不可接受的,因为可能单次运行代码并不会调用到assert相关的代码路径。因此这样的校验最好是在编译时期就能完成。
例二:
#include <cassert>#include <cstdio>template <typename T, typename U>void bit_copy(T& a, U& b){assert(sizeof(a) == sizeof(b));memcpy(&a, &b, sizeof(b));}int main(){int a = 10;double b;bit_copy(a, b);return 0;}
上述代码的 assert 是要保证a和b两种类型的长度一致,这样bit_copy才能够保证复制操作不会遇到越界等问题。这里我们还是使用assert的这样的运行时断言,但如果bit_copy不被调用,我们将无法触发该断言。实际上,正确产生断言的时机应该在模板实例化时,即编译时期。
例一和例二 这类问题的解决方案是进行编译时期的断言,即所谓的“静态断言”。事实上,利用语言规则实现静态断言的讨论非常多,比较典型的实现是开源库Boost内置的BOOST_STATIC_ASSERT断言机制(利用sizeof操作符)。我们可以利用“除0”会导致编译器报错这个特性来实现静态断言。
#include <cstring>using namespace std;#define assert_static(e) \do { \enum { assert_ static__ = 1 / (e) }; \} while (0)template <typename T, typename U>void bit_copy(T& a, U& b){assert_static(sizeof(a) == sizeof(b)); // 该行会报错,编译前的提示memcpy(&a, &b, sizeof(b));}int main(){int a = 0x2468;double b;bit_copy(a, b);}
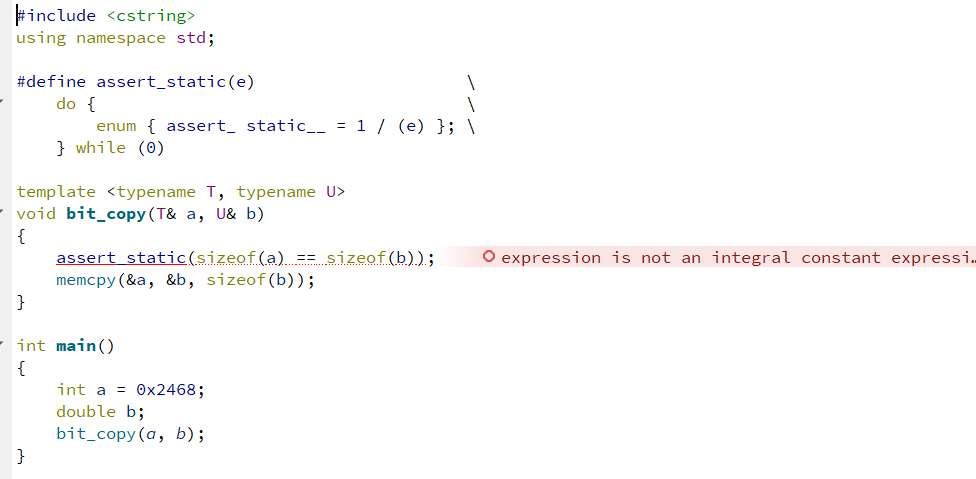
结果如我们预期的,在模板实例化时我们会得到编译器的错误报告,读者可以实验一下在自己本机运行的结果。在我们的实验机上会输出比较长的错误信息,主要信息是除零错误。当然,读者也可以尝试一下Boost库内置的BOOST_STATIC_ASSERT,输出的主要信息是sizeof错误。但无论是哪种方式的静态断言,其缺陷都是很明显的:诊断信息不够充分,不熟悉该静态断言实现的程序员可能一时无法将错误对应到断言错误上,从而难以准确定位错误的根源。(测试的时候,错误提示还是很明显的)
C++11的static_assert 编译时期的断言
在C++11标准中,引入了static_assert断言来解决这个问题。static_assert使用起来非常简单,它接收两个参数:
- 参数一:是断言表达式,这个表达式通常需要返回一个bool值
- 参数二:是警告信息,它通常也就是一段字符串
template <typename T, typename U>void bit_copy(T& a, U& b){static_assert(sizeof(a) == sizeof(b), "error: sizeof(a) != sizeof(b)");memcpy(&a, &b, sizeof(b));}
注意 static_assert的断言表达式的结果必须是在编译时期可以计算的表达式,即必须是常量表达式。如果使用了变量,则会导致错误。
2.6 noexcept修饰符与noexcept操作符
2.7 快速初始化成员变量
在C++11中,标准允许非静态成员变量的初始化有多种形式。具体而言,除了初始化列表外,在C++11中,标准还允许使用等号=或者花括号{}进行就地的非静态成员初始化。
struct init {int a = 1;double b { 1.2 };std::list<int> c = { 1, 2, 3 };};
2.8 非静态成员 sizeof
C++98中,对非静态成员使用sizeof是不能通过编译的;而在C++11中,是被允许的
#include <iostream>using namespace std;struct People {int hand;static People* all;};int main(int argc, char* argv[]){People people;cout << sizeof(people.hand) << endl; // C++98中通过, C++11中通过cout << sizeof(People::all) << endl; // C++98中通过, C++11中通过cout << sizeof(People::hand) << endl; // C++98中失败, C++11中通过}
2.9 扩展的friend语法
friend关键字用于声明类的友元,友元可以无视类中成员的属性。 无论成员是 public、 protected 或是 private 的,友元类或友元函数都可以访问,不过这就完全破坏了面向对象编程中封装性的概念。
2.10 final/override控制

若有收获,就点个赞吧
0 人点赞
