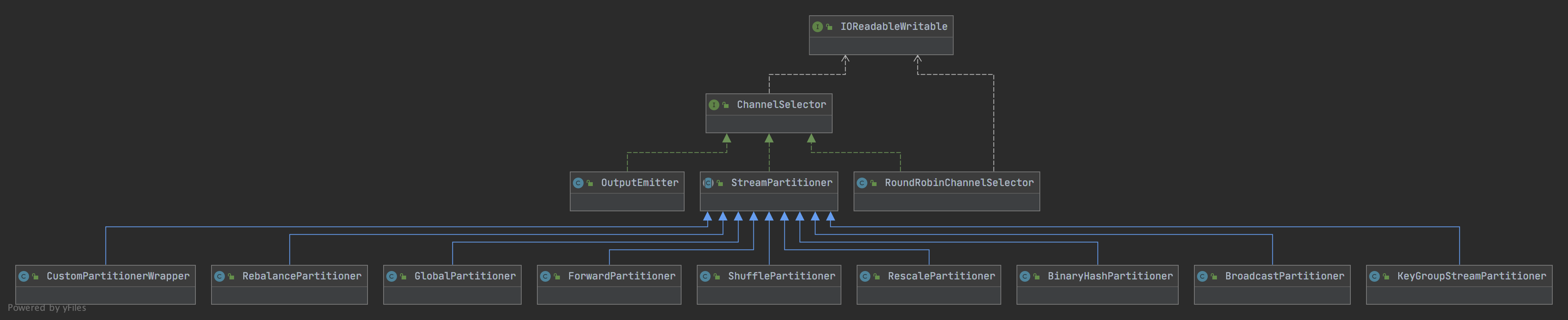
ChannelSelector
/** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.apache.flink.runtime.io.network.api.writer;import org.apache.flink.core.io.IOReadableWritable;/*** The {@link ChannelSelector} determines to which logical channels a record* should be written to.** @param <T> the type of record which is sent through the attached output gate*/public interface ChannelSelector<T extends IOReadableWritable> {/*** Initializes the channel selector with the number of output channels.** @param numberOfChannels the total number of output channels which are attached* to respective output gate.*/void setup(int numberOfChannels);/*** Returns the logical channel index, to which the given record should be written. It is* illegal to call this method for broadcast channel selectors and this method can remain* not implemented in that case (for example by throwing {@link UnsupportedOperationException}).** @param record the record to determine the output channels for.* @return an integer number which indicates the index of the output* channel through which the record shall be forwarded.*/int selectChannel(T record);/*** Returns whether the channel selector always selects all the output channels.** @return true if the selector is for broadcast mode.*/boolean isBroadcast();}
RoundRobinChannelSelector
ChannelSelector接口的默认实现,它表示一个简单的轮循策略。
@Overridepublic int selectChannel(final T record) {nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;return nextChannelToSendTo;}
OutputEmitter
主要用于之前流批api分离的时候旧的批处理的BatchTask中的RecordWriter使用的。
StreamPartitioner
在流处理任务中使用的Channel Selector.它相对于父类ChannelSelector新增了两个方法:
/*** Defines the behavior of this partitioner, when upstream rescaled during recovery of in-flight* data.*/public SubtaskStateMapper getUpstreamSubtaskStateMapper() {return SubtaskStateMapper.ARBITRARY;}/*** Defines the behavior of this partitioner, when downstream rescaled during recovery of* in-flight data.*/public abstract SubtaskStateMapper getDownstreamSubtaskStateMapper();
- getUpstreamSubtaskStateMapper()方法:对正在运行的数据进行恢复时会导致上游的重新伸缩,该方法用于定义该行为的partitioner
getDownstreamSubtaskStateMapper()方法:对正在运行的数据进行恢复时会导致下游的重新伸缩,该方法用于定义该行为的partitioner
BinaryHashPartitioner
对记录的二进制数据取hash,以hash的方式来将记录均匀分散到各个channel中。
@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<RowData>> record) {return MathUtils.murmurHash(getHashFunc().hashCode(record.getInstance().getValue()))% numberOfChannels;}
输入的是携带二进制数据的RowData,数据路由的方式是使用二进制记录值的hash来进行的。它的使用场景是在BatchExecExchange#translateToPlanInternal方法中如果RelDistribution的类型是RelDistribution.Type.HASH_DISTRIBUTED时会使用BinaryHashPartitioner来生成PartitionTransformation。
BroadcastPartitioner
```java /**
- Note: Broadcast mode could be handled directly for all the output channels in record writer,
so it is no need to select channels via this method. */ @Override public int selectChannel(SerializationDelegate
"Broadcast partitioner does not support select channels.");
}
@Override public SubtaskStateMapper getUpstreamSubtaskStateMapper() { return SubtaskStateMapper.UNSUPPORTED; }
@Override public SubtaskStateMapper getDownstreamSubtaskStateMapper() { return SubtaskStateMapper.UNSUPPORTED; }
@Override public boolean isBroadcast() { return true; }
- 广播模式可以在record writer中为所有输出channel写入数据,它不需要选择channel;- 上游stream的subtaskStateMapper为SubtaskStateMapper.DISCARD_EXTRA_STATE,只使用已经存在的subtask,丢弃多余的部分;- 下游stream的subtaskStateMapper为SubtaskStateMapper.ROUND_ROBIN,它会以轮循方式重新分配子任务state;- isBroadcast方法返回为true,copy方法返回的是当前对象应用场景:可以在DataStream的broadcast()方法来指定使用BroadcastPartitioner,在sql中会在解析得到RelNode的 RelDistribution.Type为 RelDistribution.Type.BROADCAST_DISTRIBUTED类型时使用BroadcastPartitioner,详细代码在BatchExecExchange#translateToPlanInternal方法中。<a name="DPUn1"></a>## ForwardPartitioner```java@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {return 0;}public StreamPartitioner<T> copy() {return this;}
- selectChannel方法返回的是0,它与GlobalPartitioner的slectChannel是一样的实现
在使用ForwardPartitioner时要求上下游节点的并行度相同,在没有指定partitioner且上下游的并行度相同时会默认使用ForwardPartitioner
GlobalPartitioner
@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {return 0;}@Overridepublic StreamPartitioner<T> copy() {return this;}@Overridepublic SubtaskStateMapper getDownstreamSubtaskStateMapper() {return SubtaskStateMapper.FIRST;}
- selectChannel方法返回的是0
可以通过使用DataStream的global方法来指定使用GlobalPartitioner,也会在批流处理sql任务时在转换时会在某些条件下使用GlobalPartitioner。
KeyGroupStreamPartitioner
通过KeySelector从record中获取key,然后根据key进行hash打散再按并行度分散到不同的subTask中去。
@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {K key;try {key = keySelector.getKey(record.getInstance().getValue());} catch (Exception e) {throw new RuntimeException("Could not extract key from " + record.getInstance().getValue(), e);}return KeyGroupRangeAssignment.assignKeyToParallelOperator(key, maxParallelism, numberOfChannels);}@Overridepublic SubtaskStateMapper getDownstreamSubtaskStateMapper() {return SubtaskStateMapper.RANGE;}@Overridepublic StreamPartitioner<T> copy() {return this;}
- 构造时需要传入KeySelector和maxParallelism,也可以通过configure方法配置maxParallelism的值;
- selectChannel方法中会使用keySelector去record中提取key值,然后根据key进行hash打散再按并行度分散到不同的subTask中去。大致过程为:根据key的hashCode值利用MathUtils.murmurHash方法再打散对maxParallelism取余获取keyGroupId,然后利用keyGroupId * parallelism / maxParallelism获取最终的key group index。由于keyGroupId 和parallelism 都是int值,所以maxParallelism的值必须是小于或等于 Short.MAX_VALUE,不然计算时会有精度问题。
使用场景主要是在流式任务中的KeyedStream中和sql任务CommonPhysicalSink#createSinkTransformation方法中以及StreamExecExchange#translateToPlanInternal中会使用到
RebalancePartitioner
随机开始然后循环轮询的方式来分配channel
@Overridepublic void setup(int numberOfChannels) {super.setup(numberOfChannels);nextChannelToSendTo = ThreadLocalRandom.current().nextInt(numberOfChannels);}@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;return nextChannelToSendTo;}@Overridepublic SubtaskStateMapper getDownstreamSubtaskStateMapper() {return SubtaskStateMapper.ROUND_ROBIN;}
- 初始化时会设置随机开始的位置,注意这里使用的是比较高性能的ThreadLocalRandom;
- selectChannel方法中为具体的逻辑,以循环使用0~numberOfChannels区间中的索引的方式来确定channel index;
- getDownstreamSubtaskStateMapper方法返回的是SubtaskStateMapper.ROUND_ROBIN,会以轮循方式重新分配子任务state;
- copy方法返回的是当前实例
使用场景:
•可以在DataStream中调用rebalance方法指定RebalancePartitioner;
•在StreamGraph#addEdgeInternal方法中如果没有指定partitioner且节点上下游并行度不相等时会默认使用RebalancePartitioner作为分区器;•BatchExecExchange#translateToPlanInternal中进行sql任务解析时如果RelNode的RelDistribution.Type为RANDOM_DISTRIBUTED类型时会使用RebalancePartitioner。
RescalePartitioner
通过轮询的方式平均分配数据的partitioner,具体实现如下:
private int nextChannelToSendTo = -1;@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {if (++nextChannelToSendTo >= numberOfChannels) {nextChannelToSendTo = 0;}return nextChannelToSendTo;}@Overridepublic SubtaskStateMapper getDownstreamSubtaskStateMapper() {return SubtaskStateMapper.UNSUPPORTED;}
- selectChannel方法中为核心逻辑,会以自增nextChannelToSendTo的方式来平均分配数据到每个channel中去;
- getDownstreamSubtaskStateMapper方法返回的是SubtaskStateMapper.ROUND_ROBIN。
使用场景:
•DataStream的rescale方法来指定使用;
•在StreamingJobGraphGenerator#connect方法中会将RescalePartitioner使用POINTWISE模式:
pointwise模式下,上游操作向其下游操作子集发送元素取决于上游和下游操作的并行度。例如,如果上游操作具有并行度2,而下游操作具有并行度4,那么一个上游操作将向两个下游操作分发元素,而另一个上游操作将向另外两个下游操作分发元素。另一方面,如果下游操作具有并行度2,而上游操作具有并行度4,则两个上游操作将分配给一个下游操作,而另外两个上游操作将分配给另一个下游操作。在上下游有不同的并行度而且不是彼此的倍数的情况下,一个或多个下游操作将具有不同数量的来自上游操作的输入。
ShufflePartitioner
为数据随机选择channel
private Random random = new Random();@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {return random.nextInt(numberOfChannels);}@Overridepublic SubtaskStateMapper getDownstreamSubtaskStateMapper() {return SubtaskStateMapper.ROUND_ROBIN;}
•selectChannel方法会从channel列表中随机选择一个;
•getDownstreamSubtaskStateMapper()方法返回的是SubtaskStateMapper.ROUND_ROBIN,会以轮询的方式为下游子任务分配state。
使用场景:通过DataStream的shuffle方法来指定使用ShufflePartitioner。
问题梳理
ForwardPartitioner与GlobalPartitioner的selectChannel方法实现中都是返回为0,那么它们之间的区别是什么?
区别1:如果一个节点的输出partitioner为ForwardPartitioner或RescalePartitioner,那么会在生成JobGraph建立当前节点与下游节点的连接边时指定DistributionPattern为DistributionPattern.POINTWISE,其他的partitioner对应的DistributionPattern为ALL_TO_ALL。这两种DistributionPattern的区别可以参考这篇文章[1],这里我就不再浪费时间去画图解释了。
DistributionPattern.ALL_TO_ALL 就是简单的全连接,DistributionPattern.POINTWISE会根据上下游节点的并行度来调整,当上游分区与下游ExecutionJobVertex节点的并行度相同时会一对一连接;当上游分区并行度小于下游ExecutionJobVertex节点的并行度时,下游子 task 只会连接一个上游分区;当上游分区并行度大于下游子task并行度时,子 task 会连接多个上游分区。GlobalPartitioner是all_to_all模式的,一个上游会与下游子任务全连接,所以能全局控制channel为0,而ForwardPartitioner是pointwise的。二者partition的区别代码位于ResultPartitionFactory#create方法中,由于篇幅问题,后面再专门来分析了。
区别2:getDownstreamSubtaskStateMapper()方法的实现不同,GlobalPartitioner中返回的是SubtaskStateMapper.FIRST,也就是会只恢复index为0的那个subTask;ForwardPartitioner中返回的是SubtaskStateMapper.ROUND_ROBIN,仍会考虑所有的subTask。
partitioner与DistributionPattern的区别
1.partitioner的类型会决定DistributionPattern的类型,ForwardPartitioner或RescalePartitioner对应的DistributionPattern为DistributionPattern.POINTWISE,其他的partitioner对应的DistributionPattern为ALL_TO_ALL。
2.partitioner的使用场景是在RecordWriter中决定数据往哪个partition发送时:
3.DistributionPattern的使用场景是在创建ExecutionEdge来连接上游分区和下游节点时:

若有收获,就点个赞吧
0 人点赞
