屏障对齐的风险
在Flink的检查点机制中,屏障(barrier)是划分快照(状态)的边界。在启用exactly once语义的条件下,当一个算子有多个输入流时,需要等待所有输入流中当前检查点N的屏障都到达其输入缓冲区,才能安全地触发检查点,否则检查点N的快照数据和检查点N + 1的快照数据就会混在一起。图示如下。
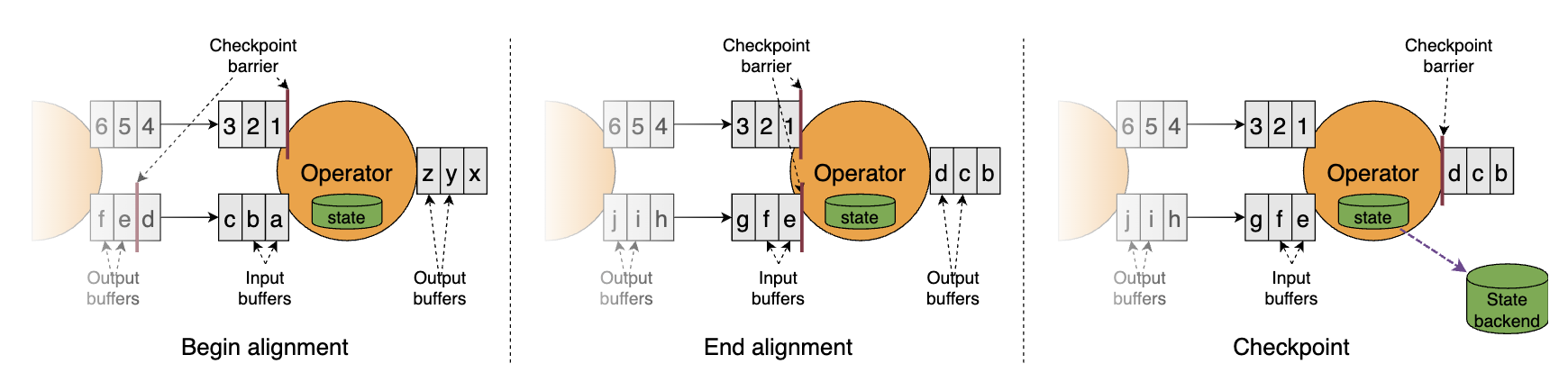
屏障对齐不仅保证了状态的准确性,还巧妙地消去了原生C-L算法中记录输入流状态的步骤(之前说过,即使作业执行计划是有环图,也只需要记录回边流的状态),十分轻量级。
但是,屏障对齐是阻塞式的,在作业出现反压时可能会成为不定时炸弹。我们知道,检查点屏障是从Source端产生并源源不断地向下游流动的。如果作业出现反压(哪怕整个DAG中的一条链路反压),数据流动的速度减慢,屏障到达下游算子的延迟就会变大,进而影响到检查点完成的延时(变大甚至超时失败)。如果反压长久不能得到解决,快照数据与实际数据之间的差距就越来越明显,一旦作业failover,势必丢失较多的处理进度。另一方面,作业恢复后需要重新处理的数据又会积压,加重反压,造成恶性循环。
非对齐检查点
顾名思义,非对齐检查点取消了屏障对齐操作。其流程图示如下。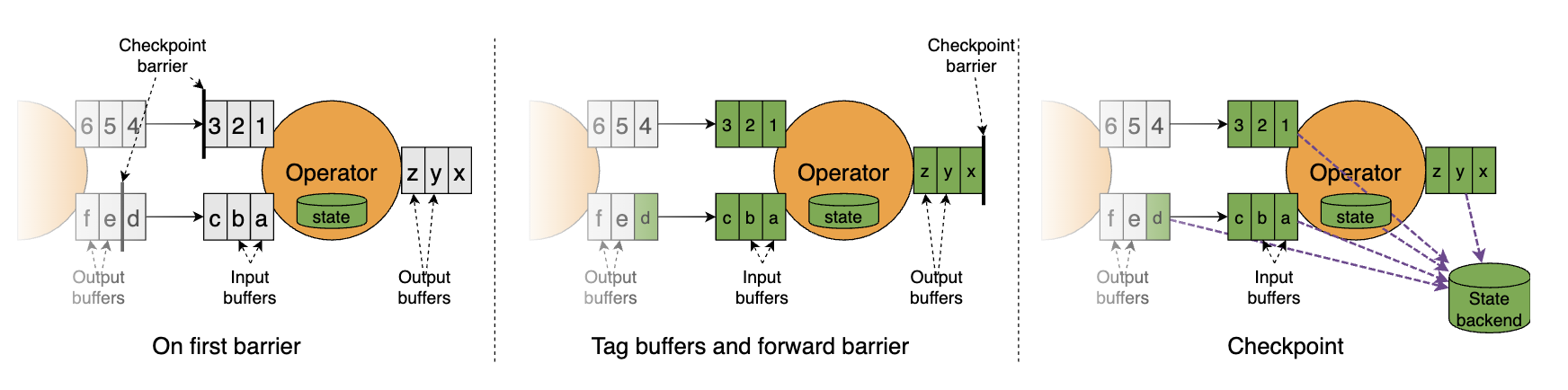
简单解说:
a) 当算子的所有输入流中的第一个屏障到达算子的输入缓冲区时,立即将这个屏障发往下游(输出缓冲区)。
b) 由于第一个屏障没有被阻塞,它的步调会比较快,超过一部分缓冲区中的数据。算子会标记两部分数据:一是屏障首先到达的那条流中被超过的数据,二是其他流中位于当前检查点屏障之前的所有数据(当然也包括进入了输入缓冲区的数据),如下图中标黄的部分所示。
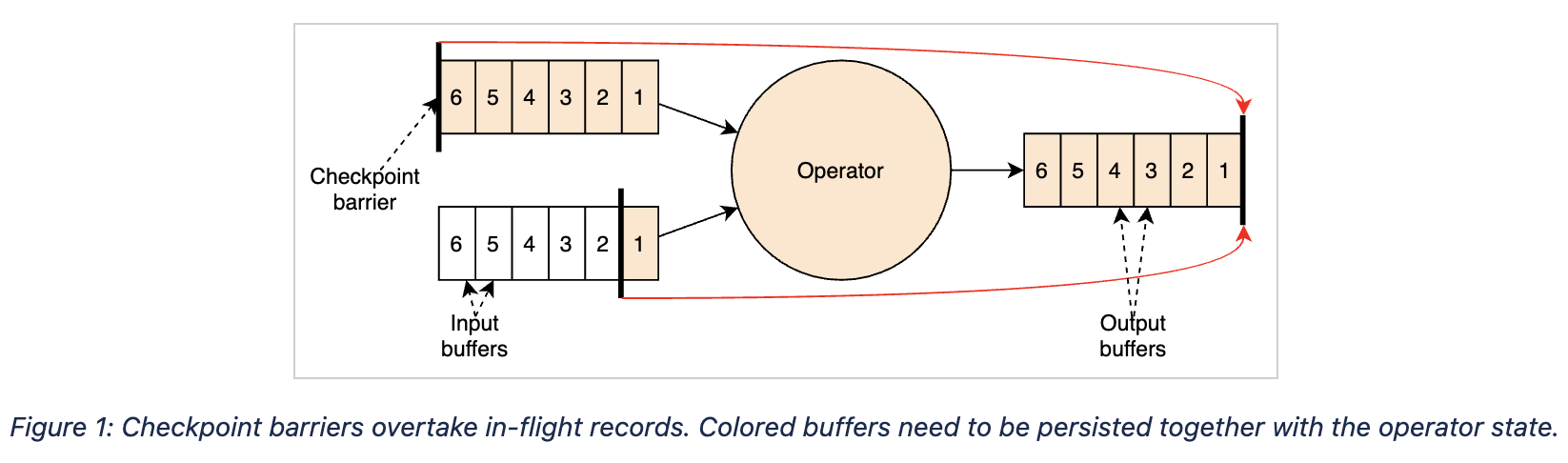
c) 将上述两部分数据连同算子的状态一起做异步快照。
由此可见,非对齐检查点的机制与原生C-L算法更为相似一些(即需要由算子来记录输入流的状态)。它与对齐检查点的区别主要有三:
对齐检查点在最后一个屏障到达算子时触发,非对齐检查点在第一个屏障到达算子时就触发。
对齐检查点在第一个屏障到最后一个屏障到达的区间内是阻塞的,而非对齐检查点不需要阻塞。
显然,即使再考虑反压的情况,屏障也不会因为输入流速度变慢而堵在各个算子的入口处,而是能比较顺畅地由Source端直达Sink端,从而缓解检查点失败超时的现象。
- 对齐检查点能够保持快照N~N + 1之间的边界,但非对齐检查点模糊了这个边界。
既然不同检查点的数据都混在一起了,非对齐检查点还能保证exactly once语义吗?答案是肯定的。当任务从非对齐检查点恢复时,除了对齐检查点也会涉及到的Source端重放和算子的计算状态恢复之外,未对齐的流数据也会被恢复到各个链路,三者合并起来就是能够保证exactly once的完整现场了。
非对齐检查点目前仍然作为试验性的功能存在,并且它也不是十全十美的(所谓优秀的implementation往往都要考虑trade-off),主要缺点有二:
- 需要额外保存数据流的现场,总的状态大小可能会有比较明显的膨胀(文档中说可能会达到a couple of GB per task),磁盘压力大。当集群本身就具有I/O bound的特点时,该缺点的影响更明显。
- 从状态恢复时也需要额外恢复数据流的现场,作业重新拉起的耗时可能会很长。特别地,如果第一次恢复失败,有可能触发death spiral(死亡螺旋)使得作业永远无法恢复。
所以,官方当前推荐仅将它应用于那些容易产生反压且I/O压力较小(比如原始状态不太大)的作业中。随着后续版本的打磨,非对齐检查点肯定会更加好用。

若有收获,就点个赞吧
0 人点赞
