一些概念
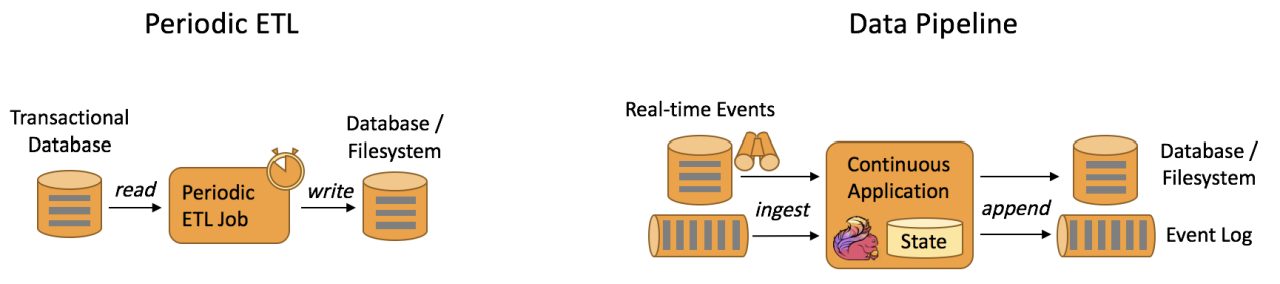
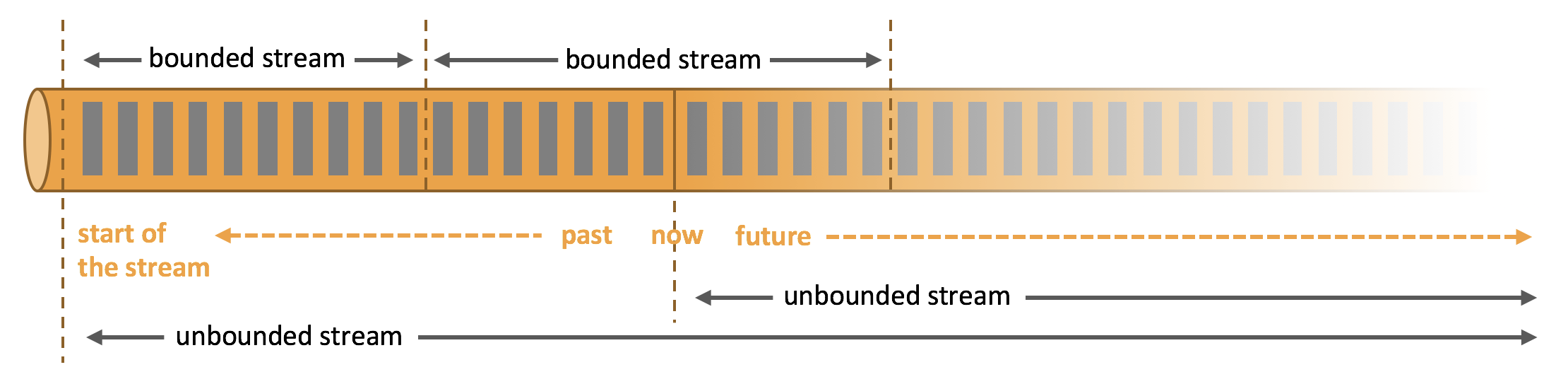
- Streams:流分为有限数据流与无限数据流,unbounded stream 是有始无终的数据流,即无限数据流;而bounded stream 是限定大小的有始有终的数据集合,即有限数据流,二者的区别在于无限数据流的数据会随时间的推演而持续增加,计算持续进行且不存在结束的状态,相对的有限数据流数据大小固定,计算最终会完成并处于结束的状态。
- State:状态是计算过程中的数据信息,在容错恢复和Checkpoint 中有重要的作用,流计算在本质上是Incremental Processing,因此需要不断查询保持状态;另外,为了确保Exactly- once 语义,需要数据能够写入到状态中;而持久化存储,能够保证在整个分布式系统运行失败或者挂掉的情况下做到Exactly- once,这是状态的另外一个价值。
- Time:分为Event time、Ingestion time、Processing time,Flink 的无限数据流是一个持续的过程,时间是我们判断业务状态是否滞后,数据处理是否及时的重要依据。

- 动态表:动态表是 Flink的支持流数据的 Table API 和 SQL 的核心概念。与表示批处理数据的静态表不同,动态表是随时间变化的。可以像查询静态批处理表一样查询它们。查询动态表将生成一个 连续查询 。一个连续查询永远不会终止,结果会生成一个动态表。查询不断更新其(动态)结果表,以反映其(动态)输入表上的更改。本质上,动态表上的连续查询非常类似于定义物化视图的查询。
实例展示
group by加count查询
配置作业
```json // clicks表 {“user”:”Mary”,”url”:”./home”} {“user”:”Bob”,”url”:”./cart”} {“user”:”Mary”,”url”:”./prod?id=1”} {“user”:”Liz”,”url”:”./home”} {“user”:”Bob”,”url”:”./prod?id=3”}
```sqlCREATE TABLE clicks(`user` VARCHAR,`url` VARCHAR) WITH ('connector' = 'kafka','topic' = 'clicks','properties.bootstrap.servers' = '172.16.48.194:9092','properties.group.id' = 'clicks','scan.startup.mode' = 'earliest-offset','format' = 'json','json.ignore-parse-errors' = 'true');CREATE TABLE user_cnt(`user` VARCHAR,`cnt` BIGINT,PRIMARY KEY (`user`) NOT ENFORCED) WITH ('connector' = 'kudu','masters' = '172.16.48.23:7051,172.16.48.24:7051','table-name' = 'user_cnt');CREATE TABLE user_cnt_print(`user` VARCHAR,`cnt` BIGINT) WITH ('connector' = 'print');INSERT INTO user_cntSELECT`user`,COUNT(`url`) AS cntFROM clicksGROUP BY `user`;INSERT INTO user_cnt_printSELECT`user`,COUNT(`url`) AS cntFROM clicksGROUP BY `user`;
# 启动kafka服务./bin/kafka-server-start.sh -daemon config/server.properties# 创建topic./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic clicks --partitions 1 --replication-factor 1# 删除topic./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic clicks --delete# 查看所有topic./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list# 向topic写入数据./bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic clicks
-- 使用presto创建kudu表CREATE TABLE kudu.default.user_cnt (user varchar WITH (primary_key = true),cnt bigint) WITH (partition_by_hash_columns = ARRAY['user'],partition_by_hash_buckets = 2);
执行分析
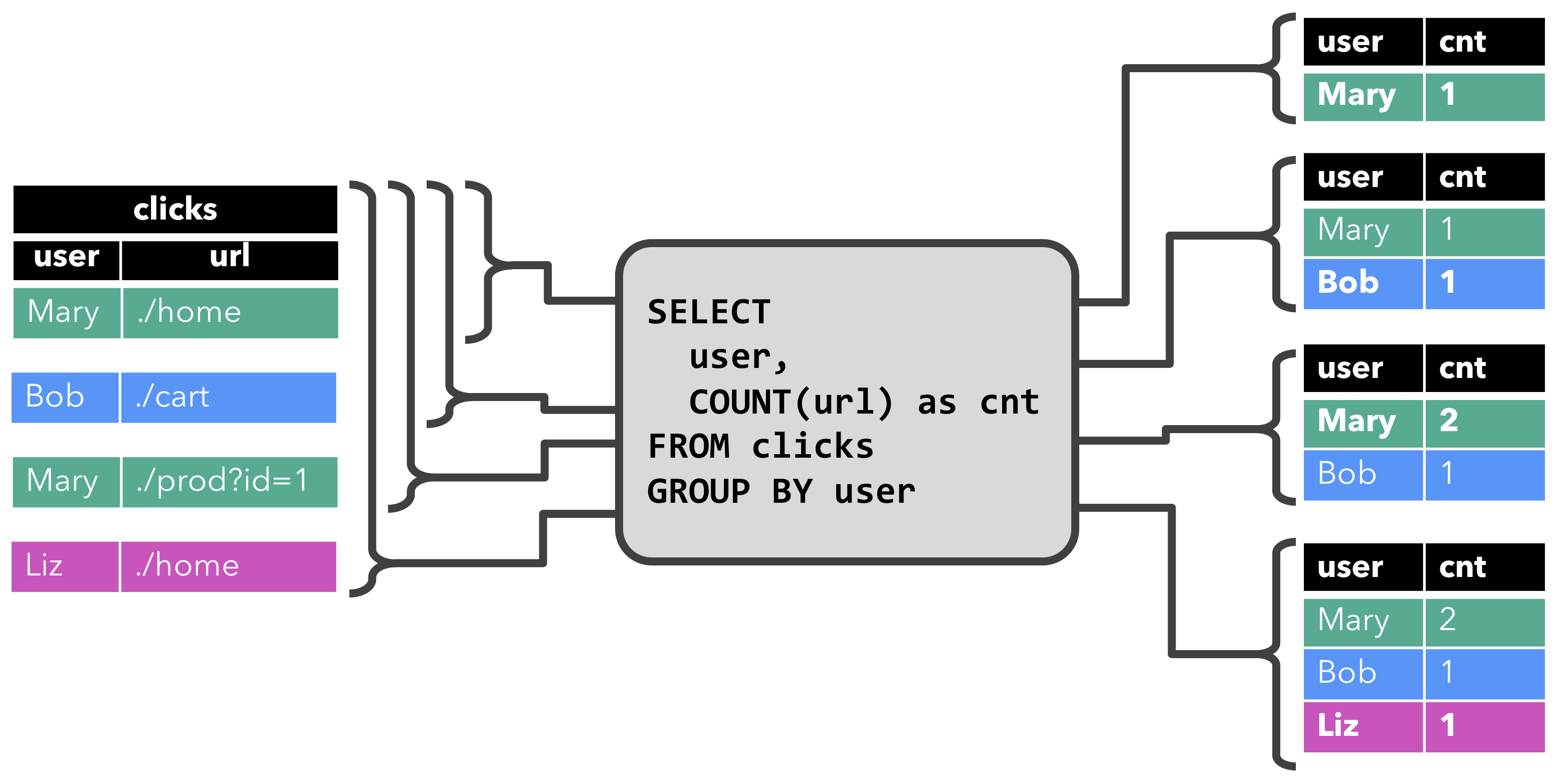
- 当查询开始,
clicks表(左侧)是空的。 - 当第一行数据被插入到
clicks表时,查询开始计算结果表。第一行数据[Mary,./home]插入后,结果表(右侧,上部)由一行[Mary, 1]组成。 - 当第二行
[Bob, ./cart]插入到clicks表时,查询会更新结果表并插入了一行新数据[Bob, 1]。 - 第三行
[Mary, ./prod?id=1]将产生已计算的结果行的更新,[Mary, 1]更新成[Mary, 2]。 - 最后,当第四行数据加入
clicks表时,查询将第三行[Liz, 1]插入到结果表中。Retract 流
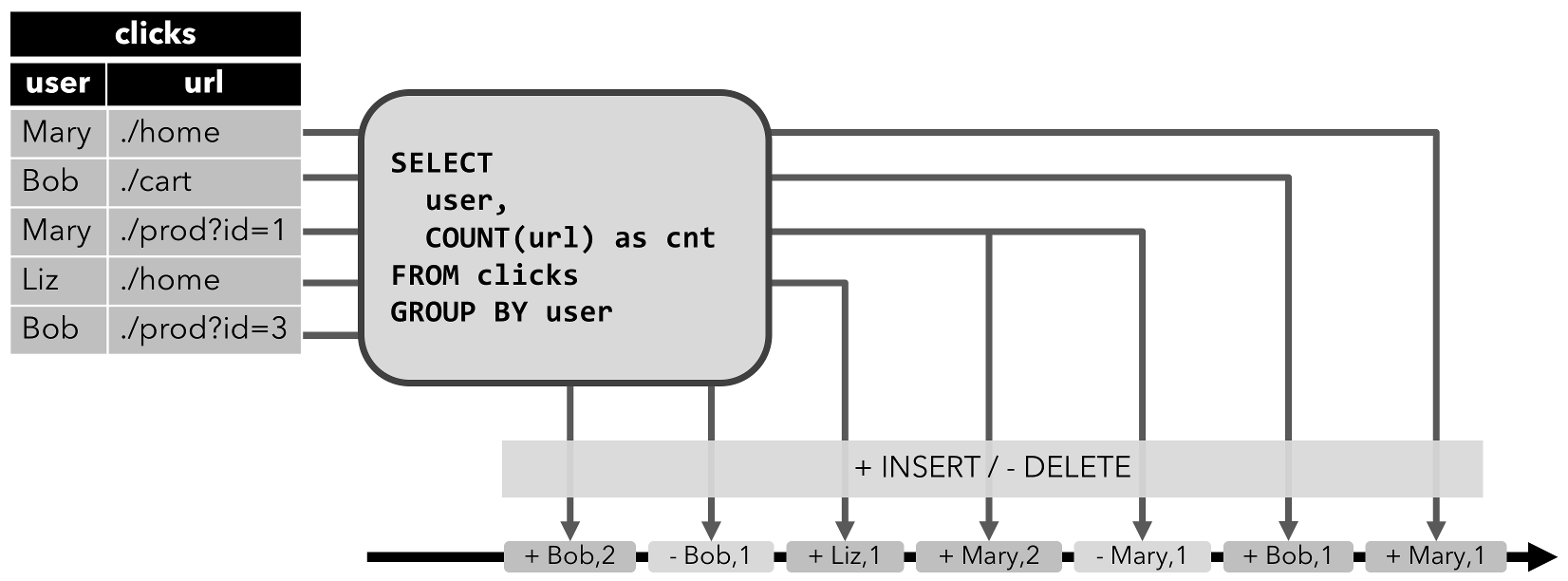
Upsert 流

窗口group by加count查询
配置作业
```json // clicks表 {“user”:”Mary”, “cTime”: “2020-12-11 12:00:00”, “url”:”./home”} {“user”:”Bob”, “cTime”: “2020-12-11 12:00:00”, “url”:”./cart”} {“user”:”Mary”, “cTime”: “2020-12-11 12:02:00”, “url”:”./prod?id=1”} {“user”:”Mary”, “cTime”: “2020-12-11 12:55:00”, “url”:”./prod?id=4”}
{“user”:”Bob”, “cTime”: “2020-12-11 13:01:00”, “url”:”./prod?id=5”} {“user”:”Liz”, “cTime”: “2020-12-11 13:30:00”, “url”:”./home”} {“user”:”Liz”, “cTime”: “2020-12-11 13:59:00”, “url”:”./prod?id=7”}
{“user”:”Mary”, “cTime”: “2020-12-11 14:00:00”, “url”:”./cart”} {“user”:”Liz”, “cTime”: “2020-12-11 14:02:00”, “url”:”./home”} {“user”:”Bob”, “cTime”: “2020-12-11 14:30:00”, “url”:”./prod?id=3”} {“user”:”Bob”, “cTime”: “2020-12-11 14:40:00”, “url”:”./home”}
{“user”:”Bob”, “cTime”: “2020-12-11 15:40:00”, “url”:”./home”}
```sqlCREATE TABLE clicks(`user` VARCHAR,`cTime` TIMESTAMP,`url` VARCHAR,WATERMARK FOR `cTime` AS `cTime` - INTERVAL '5' SECOND) WITH ('connector' = 'kafka','topic' = 'clicks','properties.bootstrap.servers' = '172.16.48.194:9092','properties.group.id' = 'clicks','scan.startup.mode' = 'earliest-offset','format' = 'json','json.ignore-parse-errors' = 'true');CREATE TABLE user_cnt(`user` VARCHAR,`end_t` TIMESTAMP,`cnt` BIGINT,PRIMARY KEY (`user`) NOT ENFORCED) WITH ('connector' = 'kudu','masters' = '172.16.48.23:7051,172.16.48.24:7051','table-name' = 'user_cnt');CREATE TABLE user_cnt_print(`user` VARCHAR,`endT` TIMESTAMP,`cnt` BIGINT) WITH ('connector' = 'print');INSERT INTO user_cntSELECT`user`,TUMBLE_END(`cTime`,INTERVAL '1' HOUR)AS `end_t`,COUNT(`url`) AS cntFROM clicksGROUP BY`user`,TUMBLE(`cTime`,INTERVAL '1' HOUR);INSERT INTO user_cnt_printSELECT`user`,TUMBLE_END(`cTime`,INTERVAL '1' HOUR)AS `endT`,COUNT(`url`) AS cntFROM clicksGROUP BY`user`,TUMBLE(`cTime`,INTERVAL '1' HOUR);
# 启动kafka服务./bin/kafka-server-start.sh -daemon config/server.properties# 创建topic./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic clicks --partitions 1 --replication-factor 1# 删除topic./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic clicks --delete# 查看所有topic./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list# 向topic写入数据./bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic clicks
-- 使用presto创建kudu表CREATE TABLE kudu.default.user_cnt (user varchar WITH (primary_key = true),end_t TIMESTAMP WITH (primary_key = true),cnt bigint) WITH (partition_by_hash_columns = ARRAY['user', 'end_t'],partition_by_hash_buckets = 2);
执行分析
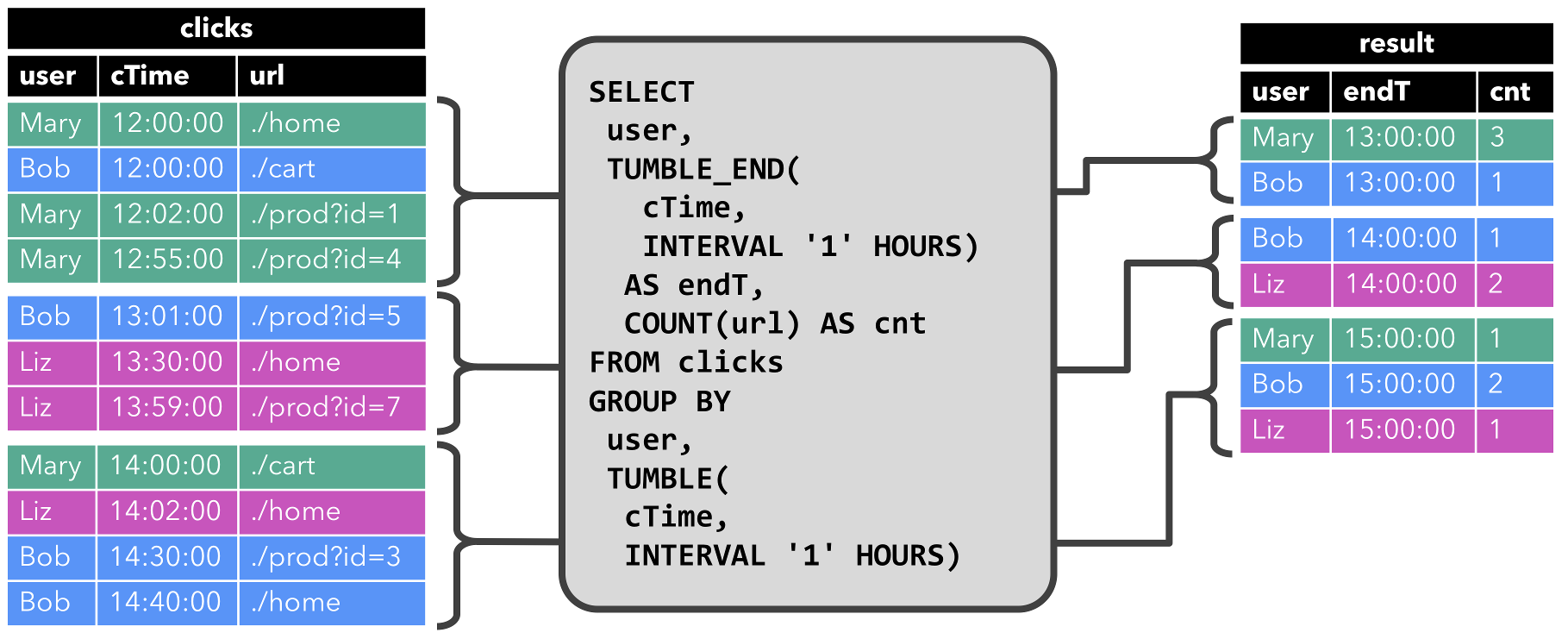
- 当查询开始,
clicks表(左侧)是空的。查询每小时持续计算结果并更新结果表。 - clicks表包含四行带有时间戳(
cTime)的数据,时间戳在12:00:00和12:59:59之间。查询从这个输入计算出两个结果行(每个user一个),并将它们附加到结果表中 - 对于
13:00:00和13:59:59之间的窗口,clicks表包含三行,这将导致另外两行被追加到结果表。 对于
14:00:00和14:59:59之间的窗口,clicks表包含四行,这将导致另外三行被追加到结果表。Append-only 流
仅通过
INSERT操作修改的动态表可以通过输出插入的行转换为流。两个查询比较
虽然这两个示例查询看起来非常相似(都计算分组计数聚合),但它们在一个重要方面不同:
第一个查询更新先前输出的结果,即定义结果表的 changelog 流包含
INSERT和UPDATE操作。第二个查询只附加到结果表,即结果表的 changelog 流只包含
INSERT操作。架构
集群剖析
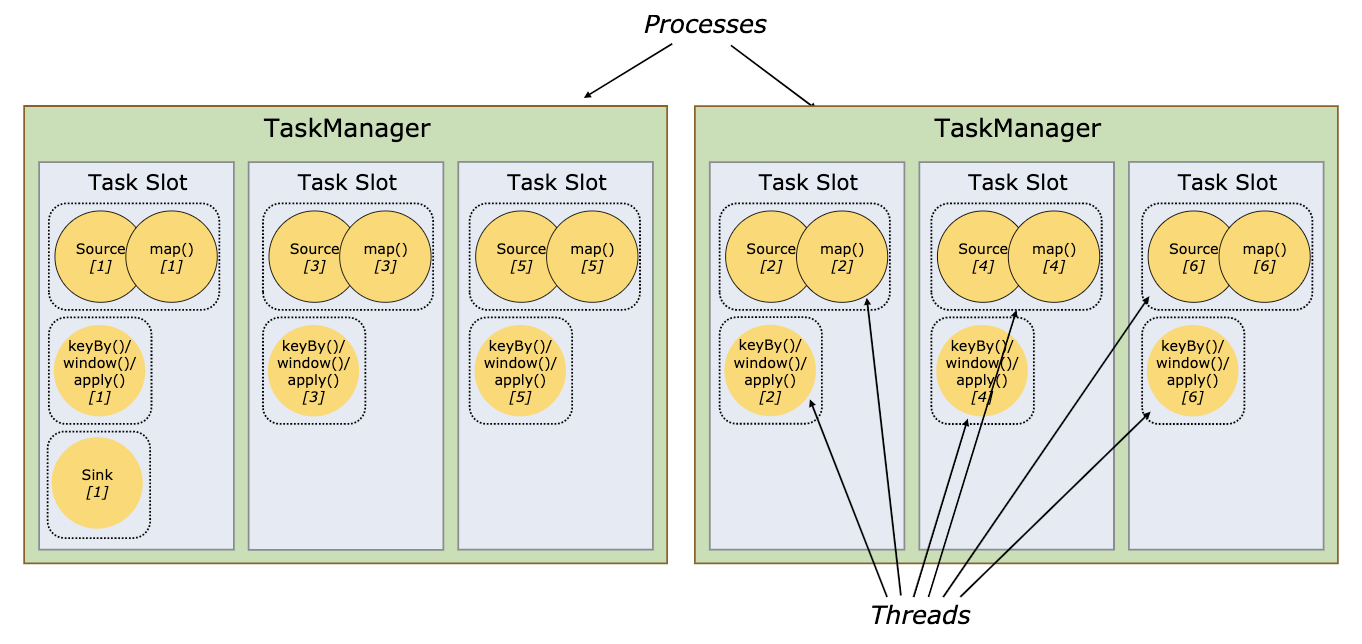
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。
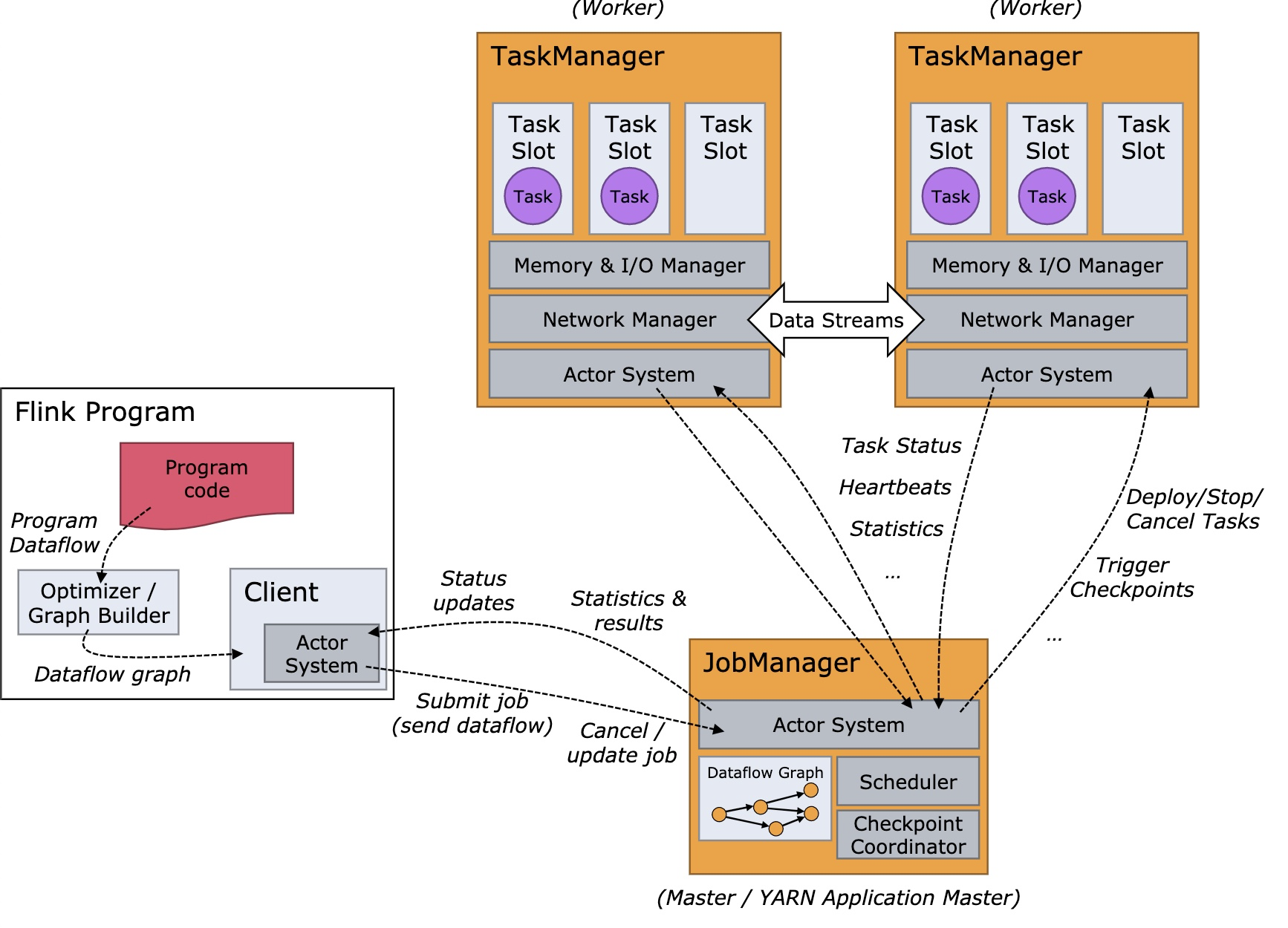
Client: 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。之后,客户端可以断开连接(分离模式),或保持连接来接收进程报告(附加模式)。客户端可以作为触发执行 Java/Scala 程序的一部分运行,也可以在命令行进程
./bin/flink run ...中运行。- JobManager: 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。始终至少有一个 JobManager。高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby。这个进程由三个不同的组件组成:
- ResourceManager: 负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的单位。Flink 为不同的环境和资源提供者(例如 YARN、Mesos、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
- Dispatcher: 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster: 负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
- TaskManagers: TaskManager(也称为 worker)执行作业流的 task,并且缓存和交换数据流。必须始终至少有一个 TaskManager。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量。请注意一个 task slot 中可以执行多个算子。
Tasks和算子链
Flink将算子链接成tasks, 将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。一个task由一个或多个subtask组成,每个subtask由一个线程执行。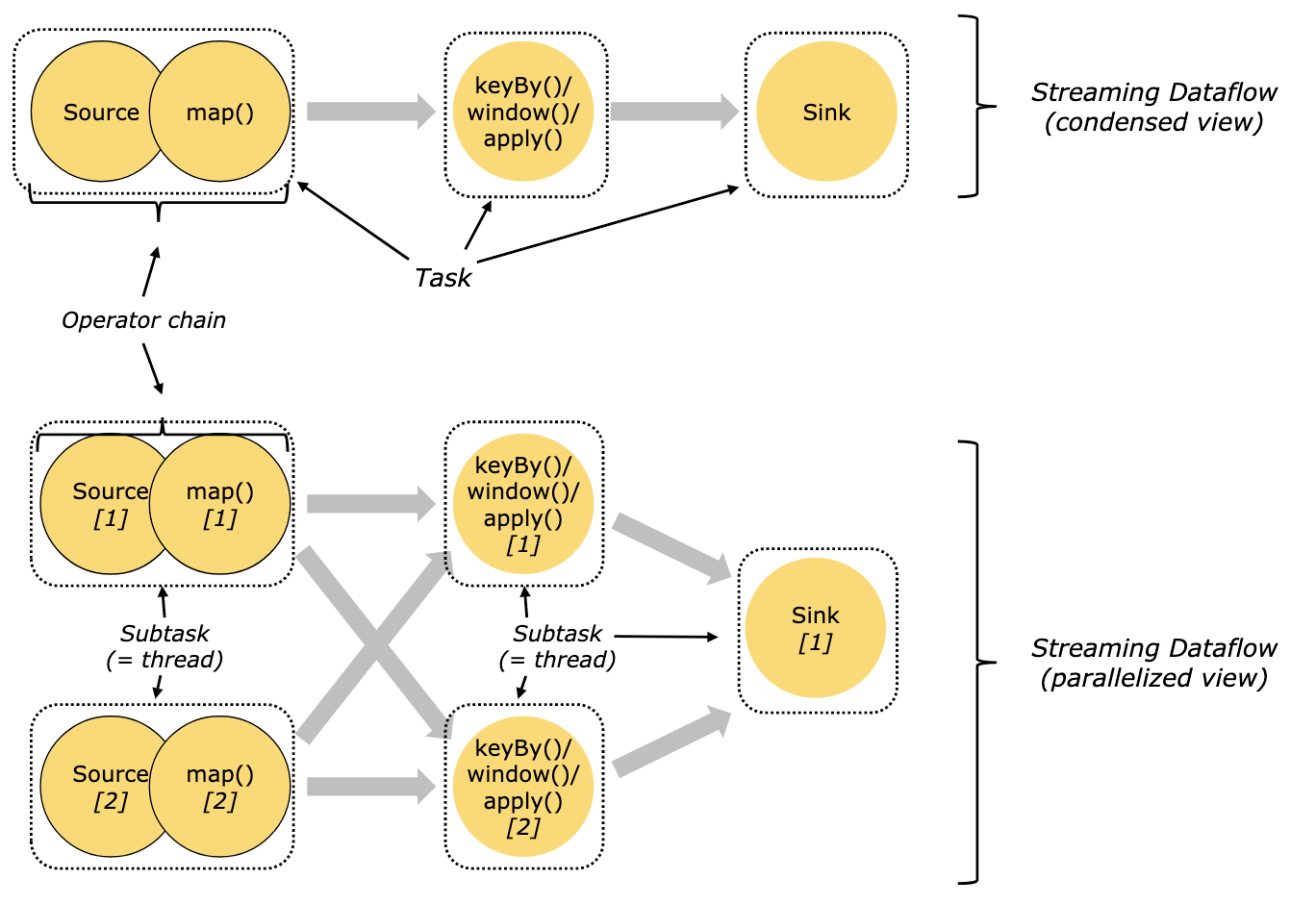
Task Slots和资源
每个 worker(TaskManager)都是一个 JVM 进程,可以在单独的线程中执行一个或多个 subtask。为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)。
每个 task slot 代表 TaskManager 中资源的固定子集。例如,具有 3 个 slot 的 TaskManager,会将其托管内存 1/3 用于每个 slot。分配资源意味着 subtask 不会与其他作业的 subtask 竞争托管内存,而是具有一定数量的保留托管内存。注意此处没有 CPU 隔离;当前 slot 仅分离 task 的托管内存。
通过调整 task slot 的数量,用户可以定义 subtask 如何互相隔离。每个 TaskManager 有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。具有多个 slot 意味着更多 subtask 共享同一 JVM。同一 JVM 中的 task 共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个 task 的开销。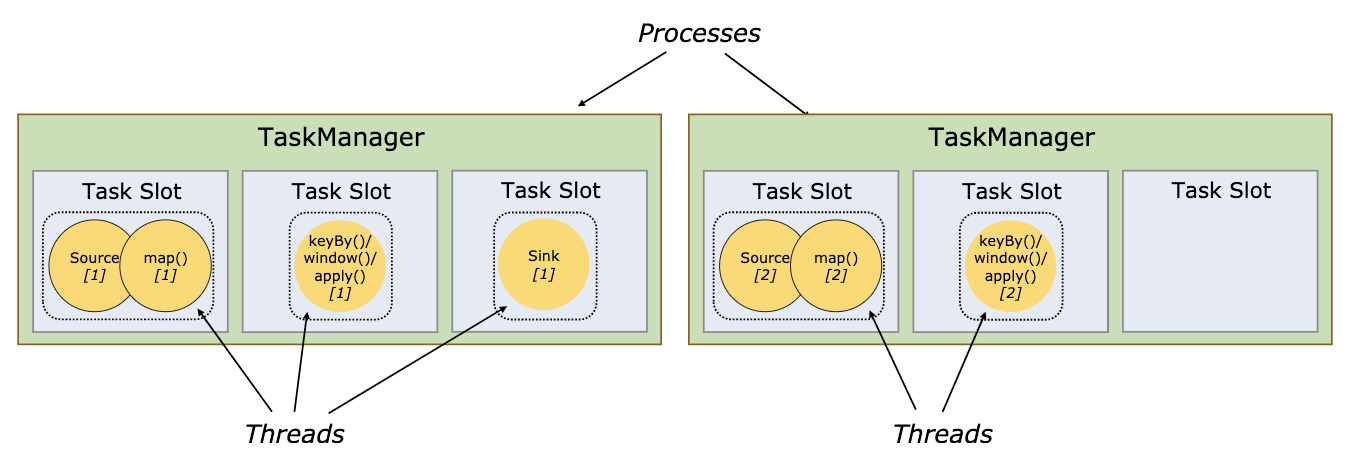
默认情况下,Flink 允许 subtask 共享 slot,即便它们是不同的 task 的 subtask,只要是来自于同一作业即可。结果就是一个 slot 可以持有整个作业管道。允许 slot 共享有两个主要优点:
- Flink 集群所需的 task slot 和作业中使用的最大并行度恰好一样。无需计算程序总共包含多少个 task(具有不同并行度)。
- 容易获得更好的资源利用。
应用场景
数据管道 & ETL
流式分析, CEP, 监控

若有收获,就点个赞吧
0 人点赞
