前言
在之前那篇讲解 Flink Timer 的文章里,我曾经用三言两语简单解释了 Key Group 和 KeyGroupRange 的概念。实际上,Key Group 是 Flink状态机制中的一个重要设计,值得专门探究一下。本文先介绍 Flink 状态的理念,再经由状态——主要是 Keyed State——的缩放(rescale)引出 KeyGroup 的细节。
再认识 Flink 状态
自从开始写关于 Flink 的东西以来,“状态” 这个词被提过不下百次,却从来没有统一的定义。Flink 官方博客中给出的一种定义如下:
When it comes to stateful stream processing, state comprises of the information that an application or stream processing engine will remember across events and streams as more realtime (unbounded) and/or offline (bounded) data flow through the system.
根据这句话,状态就是流处理过程中需要 “记住” 的那些数据的快照。而这些数据既可以包括业务数据,也可以包括元数据(例如 Kafka Consumer 的 offset)。以最常用也是最可靠的 RocksDB 状态后端为例,状态数据的流动可以抽象为 3 层,如下图所示。
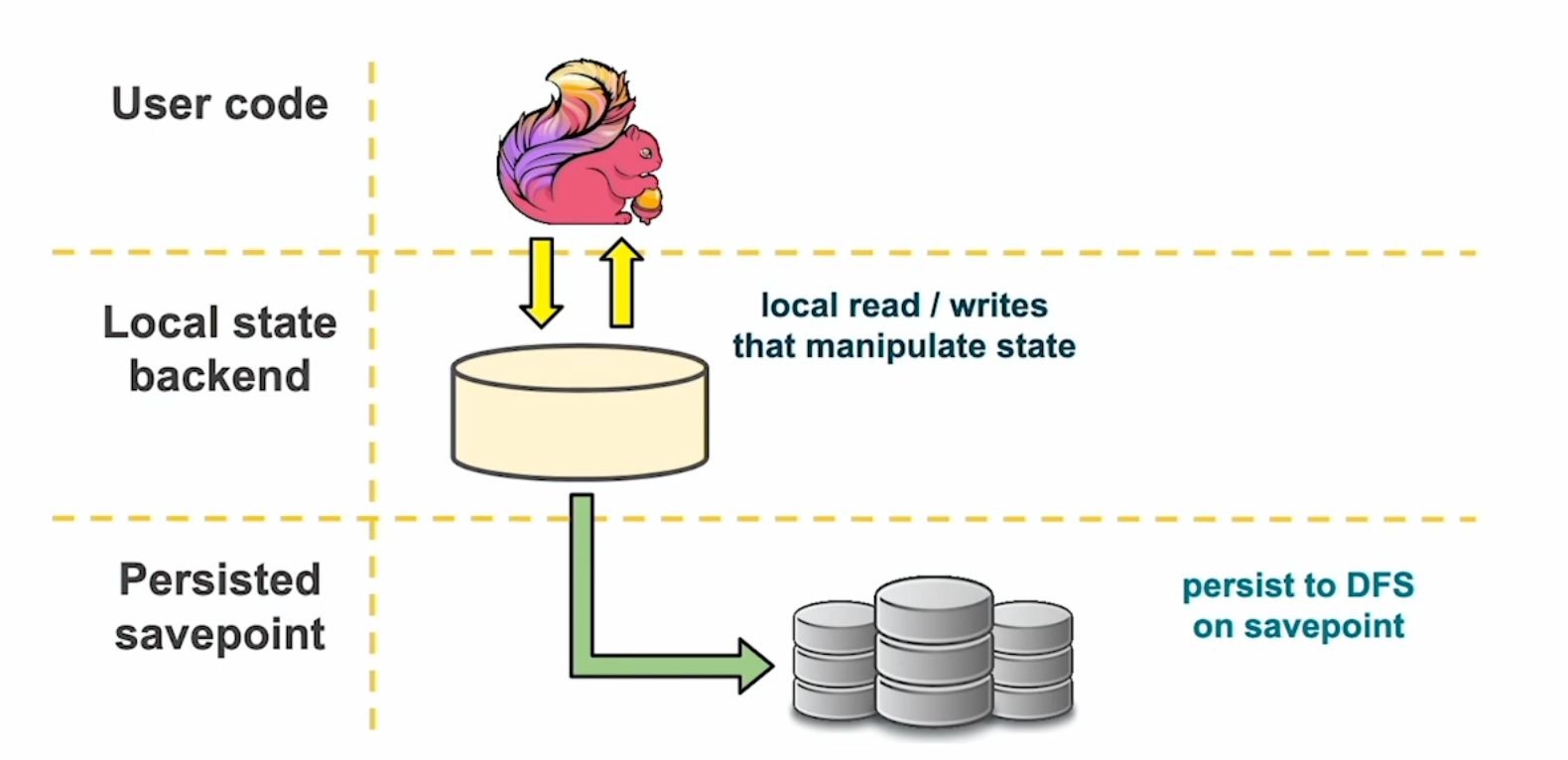
用户代码产生的状态实时地存储在本地文件中,并且随着 Checkpoint 的周期异步地同步到远端的可靠分布式文件系统(如 HDFS)。这样就保证了 100% 本地性,各个 Sub-Task 只需要负责自己所属的那部分状态,不需要通过网络互相传输状态数据,也不需要频繁地读写 HDFS,减少了开销。在 Flink 作业重启时,从 HDFS 取回状态数据到本地,即可恢复现场。
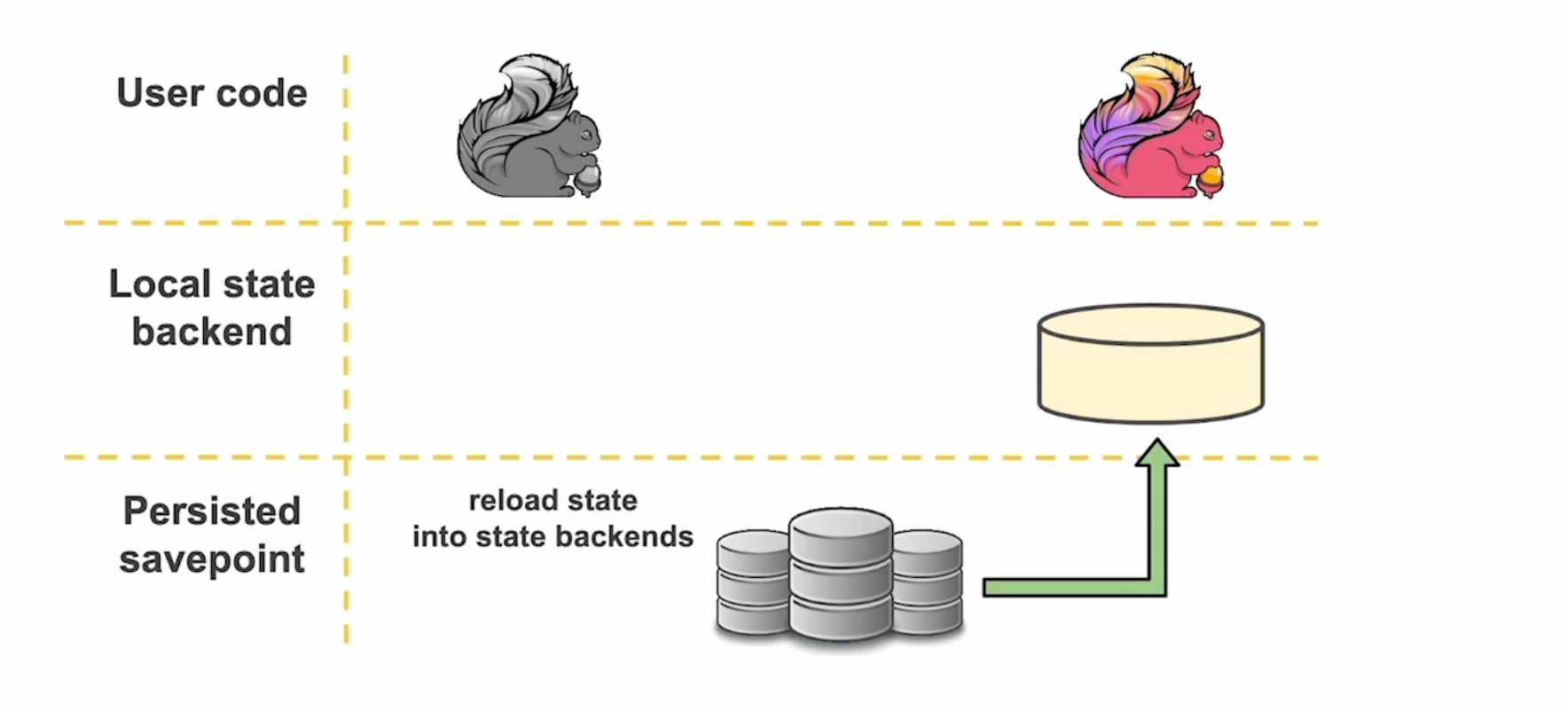
我们已经知道 Flink 的状态分为两类:Keyed State 和 Operator State。前者与每个键相关联,后者与每个算子的并行实例(即 Sub-Task)相关联。下面来看看 Keyed State 的缩放。
Keyed State 的缩放
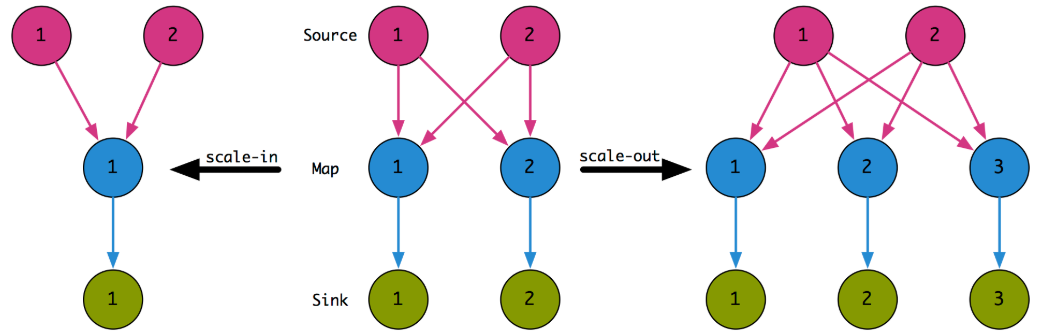
所谓缩放,在 Flink 中就是指改变算子的并行度。Flink 是不支持动态改变并行度的,必须先停止作业,修改并行度之后再从 Savepoint 恢复。如果没有状态,那么不管scale-in 还是 scale-out 都非常简单,只要做好数据流的重新分配就行,如下图的例子所示。
可是如果考虑状态的话,就没有那么简单了:并行度改变之后,HDFS 里的状态数据该按何种规则取回给新作业里的各个 Sub-Task?下图示出了这种困局。
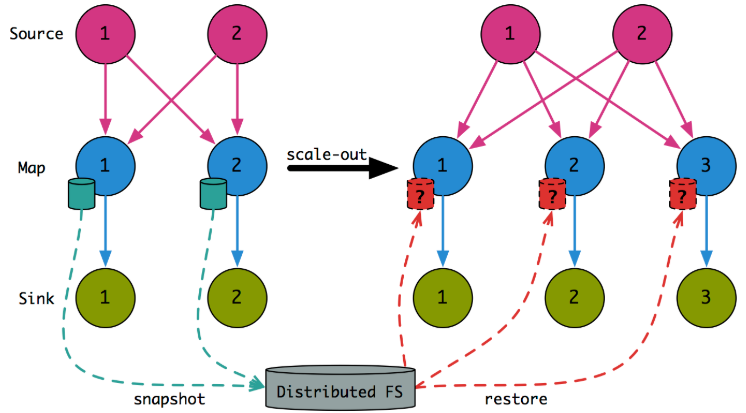
按照最 naive 的思路考虑,Flink 中的 key 是按照hash(key) % parallelism的规则分配到各个 Sub-Task 上去的,那么我们可以在缩放完成后,根据新分配的 key 集合从 HDFS 直接取回对应的 Keyed State 数据。下图示出并行度从 3 增加到 4 后,Keyed State 中各个 key 的重新分配。
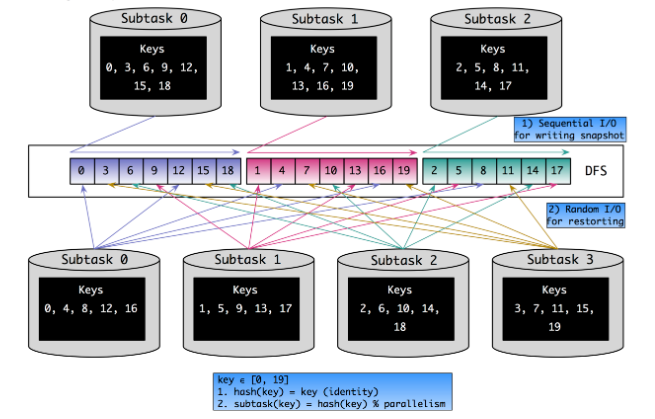
在 Checkpoint 发生时,状态数据是顺序写入文件系统的。但从上图可以看出,从状态恢复时是随机读的,效率非常低下。并且缩放之后各 Sub-Task 处理的 key 有可能大多都不是缩放之前的那些 key,无形中降低了本地性。为了解决这两个问题,在FLINK-3755对 Keyed State 专门引入了 Key Group,下面具体看看。
引入 Key Group
如果看官有仔细读 Flink 官方文档的话,可能对这个概念已经不陌生了,原话抄录如下:
Keyed State is further organized into so-called Key Groups. Key Groups are the atomic unit by which Flink can redistribute Keyed State; there are exactly as many Key Groups as the defined maximum parallelism. During execution each parallel instance of a keyed operator works with the keys for one or more Key Groups.
翻译一下,Key Group 是 Keyed State 分配的原子单位,且 Flink 作业内 Key Group 的数量与最大并行度相同,也就是说 Key Group 的索引位于[0, maxParallelism - 1]的区间内。每个 Sub-Task 都会处理一个到多个 Key Group,在源码中,以 KeyGroupRange 数据结构来表示。
KeyGroupRange 的逻辑相对简单,部分源码如下。注意 startKeyGroup 和 endKeyGroup 实际上指的是 Key Group 的索引,并且是闭区间。
public class KeyGroupRange implements KeyGroupsList, Serializable {private static final long serialVersionUID = 4869121477592070607L;public static final KeyGroupRange EMPTY_KEY_GROUP_RANGE = new KeyGroupRange();private final int startKeyGroup;private final int endKeyGroup;private KeyGroupRange() {this.startKeyGroup = 0;this.endKeyGroup = -1;}public KeyGroupRange(int startKeyGroup, int endKeyGroup) {this.startKeyGroup = startKeyGroup;this.endKeyGroup = endKeyGroup;}@Overridepublic boolean contains(int keyGroup) {return keyGroup >= startKeyGroup && keyGroup <= endKeyGroup;}public KeyGroupRange getIntersection(KeyGroupRange other) {int start = Math.max(startKeyGroup, other.startKeyGroup);int end = Math.min(endKeyGroup, other.endKeyGroup);return start <= end ? new KeyGroupRange(start, end) : EMPTY_KEY_GROUP_RANGE;}public int getNumberOfKeyGroups() {return 1 + endKeyGroup - startKeyGroup;}public int getStartKeyGroup() {return startKeyGroup;}public int getEndKeyGroup() {return endKeyGroup;}@Overridepublic int getKeyGroupId(int idx) {if (idx < 0 || idx > getNumberOfKeyGroups()) {throw new IndexOutOfBoundsException("Key group index out of bounds: " + idx);}return startKeyGroup + idx;}public static KeyGroupRange of(int startKeyGroup, int endKeyGroup) {return startKeyGroup <= endKeyGroup ? new KeyGroupRange(startKeyGroup, endKeyGroup) : EMPTY_KEY_GROUP_RANGE;}}
我们还有两个问题需要解决:
- 如何决定一个key该分配到哪个Key Group中?
- 如何决定一个Sub-Task该处理哪些Key Group(即对应的KeyGroupRange)?
第一个问题,相关方法位于KeyGroupRangeAssignment类:
public static int assignToKeyGroup(Object key, int maxParallelism) {return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism);}public static int computeKeyGroupForKeyHash(int keyHash, int maxParallelism) {return MathUtils.murmurHash(keyHash) % maxParallelism;}
可见是对key进行两重哈希(一次取hashCode,一次做MurmurHash)之后,再对最大并行度取余,得到Key Group的索引。
第二个问题,仍然在上述类中的computeKeyGroupRangeForOperatorIndex()方法,源码如下。
public static KeyGroupRange computeKeyGroupRangeForOperatorIndex(int maxParallelism,int parallelism,int operatorIndex) {checkParallelismPreconditions(parallelism);checkParallelismPreconditions(maxParallelism);Preconditions.checkArgument(maxParallelism >= parallelism,"Maximum parallelism must not be smaller than parallelism.");int start = ((operatorIndex * maxParallelism + parallelism - 1) / parallelism);int end = ((operatorIndex + 1) * maxParallelism - 1) / parallelism;return new KeyGroupRange(start, end);}
可见是由并行度、最大并行度和算子实例(即Sub-Task)的ID共同决定的。根据Key Group的逻辑,上一节中Keyed State重分配的场景就会变成下图所示(设最大并行度为10)。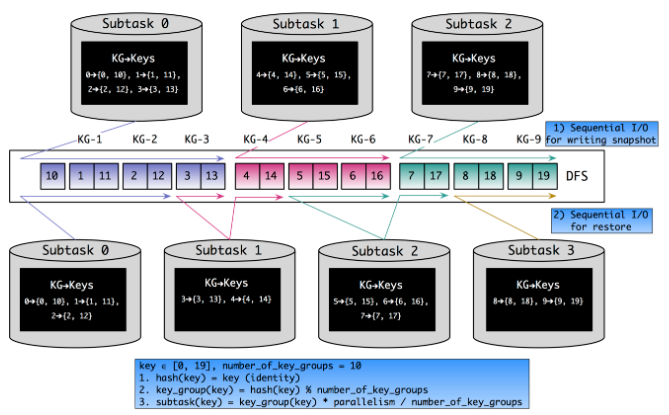
很明显,将Key Group作为Keyed State的基本分配单元之后,上文所述本地性差和随机读的问题都部分得到了解决。当然还要注意,最大并行度对Key Group分配的影响是显而易见的,因此不要随意修改最大并行度的值。Flink内部确定默认最大并行度的逻辑如下代码所示。
public static int computeDefaultMaxParallelism(int operatorParallelism) {checkParallelismPreconditions(operatorParallelism);return Math.min(Math.max(MathUtils.roundUpToPowerOfTwo(operatorParallelism + (operatorParallelism / 2)),DEFAULT_LOWER_BOUND_MAX_PARALLELISM),UPPER_BOUND_MAX_PARALLELISM);}
其中,下限值DEFAULT_LOWER_BOUND_MAX_PARALLELISM为128,上限值UPPER_BOUND_MAX_PARALLELISM为32768。

若有收获,就点个赞吧
0 人点赞
