主要摘自:浅析混淆矩阵 - 忆臻的文章 - 知乎 https://zhuanlan.zhihu.com/p/46204175
一、混淆矩阵是什么?
例子来源于:**https://www.zhihu.com/question/36883196/answer/212487033,但是答主有一处描述有误,这里重新组织一下。
我们可以对一百张图片进行学习分类,其中包含 火星(40张),地球(40张),冰激凌(20张) 三个种类;
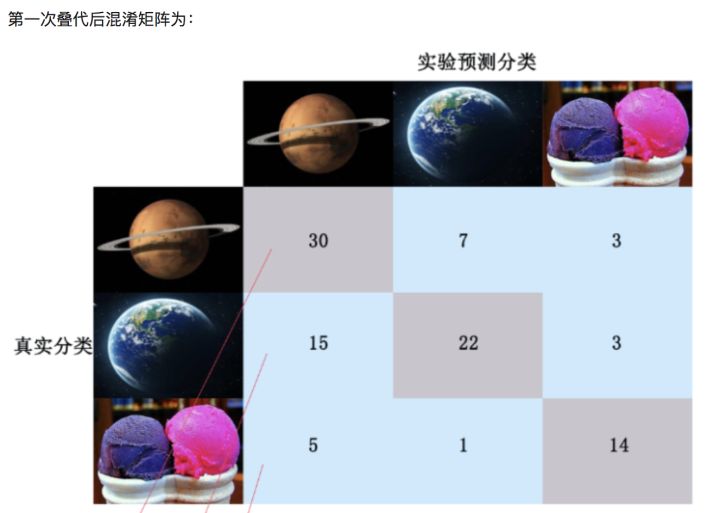
在算法学习过程中需要对每次的叠代分类结果进行精度评估,用到混淆矩阵这一工具。如下图,每次叠代后列出当前各类别分类状态的混淆矩阵。
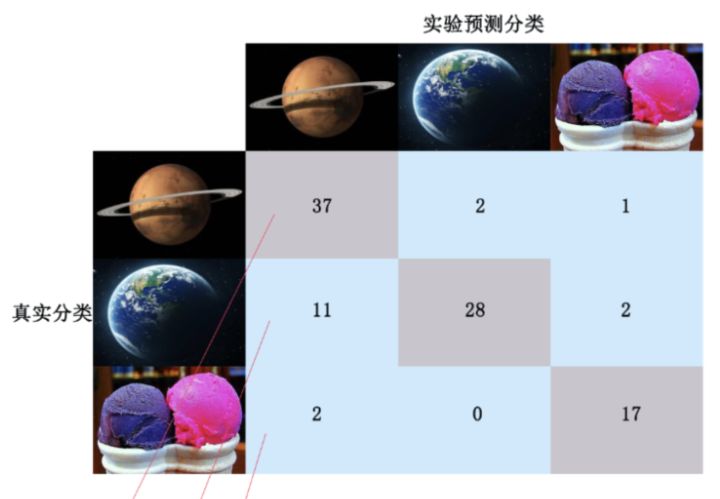
第二次叠代后混淆矩阵为:
……经过若干叠代,最终分类结果全部正确,混淆矩阵如下: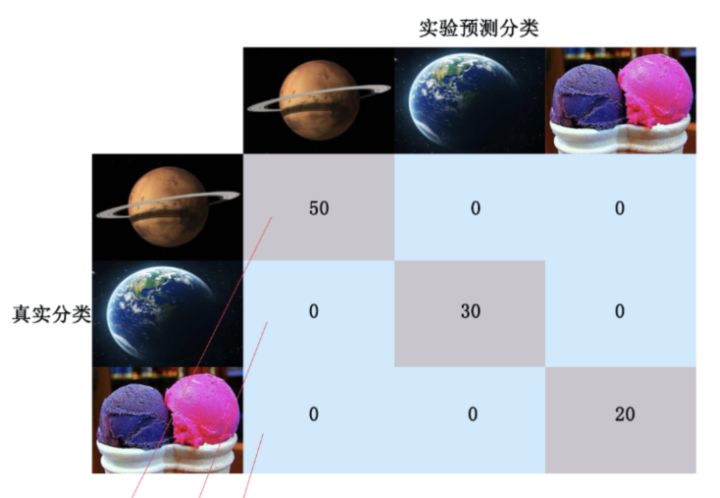
这里每一行的数目之和是该类别的真实数量,比如第一行的总和为50,代表火星真实存在50个,对角线代表模型预测正确了,而其他的位置代表预测错误,这样的一个混淆矩阵能够很快的帮助我们分析每个类别的误分类情况,从而帮助我们分析调整。
**
二、引出更多概念
下面再举一个简单的例子,引出更多关于混淆矩阵的概念。
混淆矩阵是用来总结一个分类器结果的矩阵。对于k元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果。
**
对于最常见的二元分类来说,它的混淆矩阵是2乘2的,如下
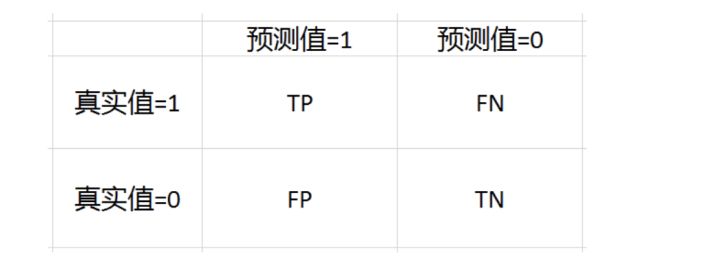
- TP = True Postive = 真阳性;
- FP = False Positive = 假阳性;
- FN = False Negative = 假阴性;
- TN = True Negative = 真阴性。
比如我们一个模型对15个样本进行预测,然后结果如下。
- 真实值:0 1 1 0 1 1 0 0 1 0 1 0 1 0 0
- 预测值:1 1 1 1 1 0 0 0 0 0 1 1 1 0 1

这个就是混淆矩阵。
精度(precision, 或者PPV, positive predictive value) = TP / (TP + FP)
在上面的例子中,精度 = 5 / (5+4) = 0.556
召回(recall, 或者敏感度,sensitivity,真阳性率,TPR,True Positive Rate) = TP / (TP + FN)
在上面的例子中,召回 = 5 / (5+2) = 0.714
特异度(specificity,或者真阴性率,TNR,True Negative Rate) = TN / (TN + FP)
在上面的例子中,特异度 = 4 / (4+2) = 0.667
F1-值(F1-score) = 2TP / (2TP+FP+FN)
在上面的例子中,F1-值 = 25 / (25+4+2) = 0.625
以上例子来自:http://sofasofa.io/forum_main_post.php?postid=1000597
三、困惑矩阵实际用途
**
这里举出我碰到的两个用途:
- 第一个是困惑矩阵能够帮助我们迅速可视化各种类别误分为其它类别的比重,这样能够帮我们调整后续模型,比如一些类别设置权重衰减!
- 在一些论文的实验分析中,可以列出困惑矩阵,行和列均为label种类,可以通过该矩阵验证自己model预测复杂label的能力强于其他model,只要自己model复杂label误判为其它类别比其他model误判的少,就可以说明自己model预测复杂label的能力强于其他model。
相关链接
- 过来,我这里有个「混淆矩阵」跟你谈一谈。
- 知乎-混淆矩阵是什么意思? https://www.zhihu.com/question/36883196/answer/212487033
- sofasofa.io-什么是混淆矩阵(confusion matrix) :http://sofasofa.io/forum_main_post.php?postid=1000597

若有收获,就点个赞吧
0 人点赞
