1. 推荐系统简介
1.1 概念
什么是推荐系统?
- (对于用户)是一种帮助用户快速发现有用信息(商品、资讯等)的工具
- (对于公司)是一种增加公司产品和用户接触程度、能提高购买率的工具
是一种工具。作用于公司、产品与用户之间。
由三方面构成:数据、算法、架构。
- 数据提供信息
- 算法提供逻辑
- 架构解放双手
1.2 产品类型
业务
- 内容分发:像头条、抖音、腾讯新闻
- 猜你喜欢:如电商平台的首页内容
- 电商推荐:淘宝、京东、苏宁等各大电商平台
形态
- Feeds流推荐
- 社交推荐
从业者发展路线
- 构建推荐模型
- 利用策略反哺
- 模型提高上限
- 深耕业务
- 推荐领域专家
1.3 工作内容
业务分类
- 策略
- 模型(召回、排序)
- 画像
- 数据
- …
优化指标
宏观
- DAU:每日活跃用户数量
- 用户留存:用户在某时间段开始使用产品,经过一段时间后继续使用产品
具体
- 评分预测:对用户历史物品评分记录进行建模,得到用户兴趣模型,通过该模型预测用户未接触过的商品。量化指标有均方根误差(RMSE,预测和实际结果的平均二次方根误差)和平均绝对误差(MAE,预测和实际结果的平均绝对值误差)。
- TopN推荐:简而言之就是给用户推荐一个具有
(预定义的某个固定值)个商品的列表(非集合,是具有排序顺序的)。量化指标通常为精确率(Precision,推荐商品列表中是用户真正所感兴趣的商品所占的比例)、召回率(Recall,推荐商品列表中用户真正感兴趣的商品所占用户所有感兴趣商品的比例)和F1值(精确率和召回率的调和平均)。
- 覆盖率:描述对物品中长尾效应部分的发掘能力。可以研究物品在物品推荐列表中出现的次数分布来描述。如果这个分布平缓说明推荐系统覆盖率比较高,如果比较陡说明覆盖率比较·比较低。可以用信息熵(
logp(i)#card=math&code=H%3D-%5Csum%7Bi%3D1%7D%5Enp%28i%29logp%28i%29))和基尼系数(p(ij)#card=math&code=G%3D%5Cfrac%7B1%7D%7Bn-1%7D%5Csum%5En%7Bj%3D1%7D%282j-n-1%29p%28i_j%29))来量化。
- 多样化:人的兴趣爱好通常是比较广泛的,所以一个好的推荐系统得到的推荐列表中应该尽可能多的包含用户的兴趣。通过不同的相似性函数可以衡量列表中商品的相似性。如果函数
#card=math&code=s%28i%2Cj%29)是物品
间的相似性,
#card=math&code=R%28u%29)为推荐商品列表,那么对单个推荐列表的多样性可以定义为:
)%3D1-%5Cfrac%7B%5Csum%7Bi%2Cj%5Cin%20R(u)%7Ds(i%2Cj)%7D%7B%5Cfrac%7B1%7D%7B2%7D%5Cvert%20R(u)%5Cvert(vert%20R(u)%5Cvert%20-1)%7D#card=math&code=Diversity%28R%28u%29%29%3D1-%5Cfrac%7B%5Csum%7Bi%2Cj%5Cin%20R%28u%29%7Ds%28i%2Cj%29%7D%7B%5Cfrac%7B1%7D%7B2%7D%5Cvert%20R%28u%29%5Cvert%28vert%20R%28u%29%5Cvert%20-1%29%7D)。系统整体的多样性可定义为所有推荐列表多样性的期望值:
)#card=math&code=Diversity%3D%5Cfrac%7B1%7D%7BU%7D%5Csum_%7Bu%5Cin%20U%7DDiversity%28R%28u%29%29)。
- AUC。AUC是ROC曲线(FPR,假阳性率为横轴,TPR,真阳性率为纵轴构成的曲线)的曲线下面积,是一个标量。该指标不在意具体的正样本、负样本打分,而是对系统整个能力的解释,如0.8的AUC值意味着给定一个正样本和负样本,80%概率下正样本评分更高,即AUC的意义可表示为
#card=math&code=P%28P%E6%AD%A3%3EP%E8%B4%9F%29)。
召回
召回层是推荐系统中一部分,推荐系统的核心算法层是召回层和排序层。召回层负责从数据库海量候选集中选出一定数量的数据(这个行为叫做召回)。找回层通常会采用多路召回策略,多路召回指的是采用不同的策略、特征或模型,才生多组召回的候选集(通常代表着不同方面、考虑的推荐),最终得到的候选集按某种规则进行权重排序、去重等等。召回过程分为离线和实时召回两种,通常Embedding召回是常用的一大召回方式,综合性强且计算速度满足需求。
离线召回
- 协同
- FM
- DSSM
实时召回
- 实时画像
- 实时收益计算
- 后验排序调整
Embedding召回
通过把实体表示转化为在某一个低维(相较于实体规模)空间的向量表示,然后通过计算两向量间的相似性得到两实体的相似性。
分类:
- Text Embedding。使用最为广泛,应用于文本特征,常用技术为了静态向量和动态向量,静态向量技术有word2vec, fasttext, glove;动态向量技术有ELMO, GPT, BERT。
- Image Embedding。针对有图片或视频的特征,大多是通过卷积模块和各种连接技巧搭建的深度学习模型,可以利用预训练模型提取图形或视频特征,来用召回。
- Graph Embedding。基于用户、商品间存在的复杂图(或网络)结构关系,有诸如Deep Walk, Node2vec, LINE, EGES等方法。
项目部署
待补充
数据存储
- 关系型数据库:MySQL、Oracle
- 非关系型数据库:MongoDB、Redis、Memcached、Hbase
- 数据仓库:Hive、Hbase、HDFS
2. 推荐系统架构
架构主要包括以下模块:
- 协议调度:请求发送与结果回传
- 推荐算法:为用户产生最终推荐结果的逻辑
- 消息队列:数据上报与处理
- 存储单元:根据数据的类型和用途不同存储在不同的存储单元中
推荐系统的作用定位:
- 增加销售物品数量
- 增加用户忠诚度、粘性,增强流量
- 了解用户,从而进行更多产品形态的开发或变现
与搜索的区别:
- 是否为用户主动搜索
- query
2.1 构成
首先按环境可分为在线和离线。整体流程为:请求召回
精排
展示
召回:从数百万甚至更多内容中快速、全面的选出数百个候选内容
精排:对召回结果进行精细打分,然后选出数十个
2.2 离线架构
2.2.1 内容源收集与规范化
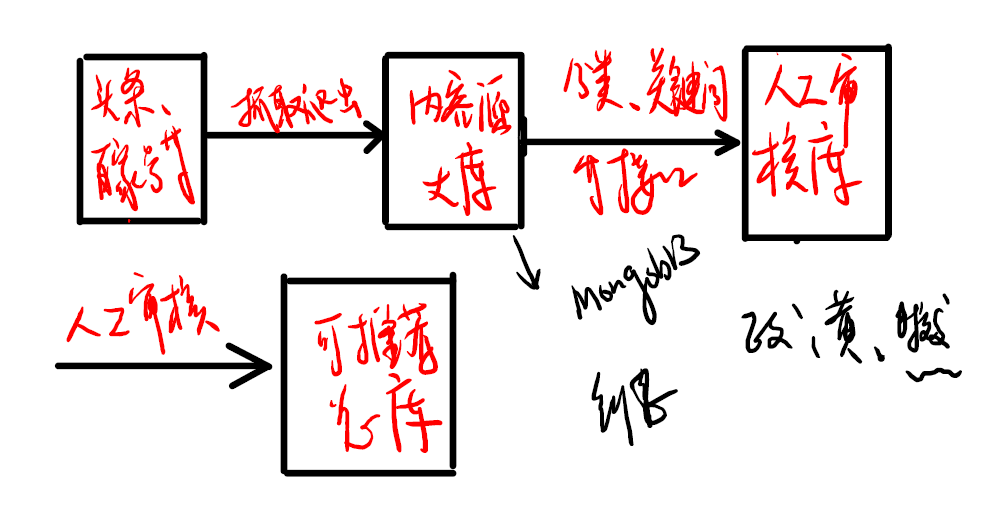
对获取数据而言,通常有4个渠道:公开数据源(政府、公司或其它公开数据)、爬虫、日志收集、传感器数据。
对于推荐系统而言,获取数据主要是通过:爬虫和日志收集。其中在日志收集中,很重要的就是埋点,即定时、定点地在目标应用/网站上采集数据,将数据以日志的形式上报至服务器的过程。埋点方式通常包括:代码埋点(Google Analytics、百度统计、友盟、TalkingData)、可视化埋点(通过点击按钮发送数据)、“无埋点”(相比可视化埋点,是先收集,后筛选,有数据回溯的优点)。
对于数据的清洗,通常按照安全合一的原则:
- 完,完整性
- 全,全面性
- 合,合法性
- 一,唯一性
数据集成:
- ELT,Extract, Transform, Load(提取、转换、加载)
- ETL,Extract, Load, Transform(提取、加载、变换)
两者区别是加载和转换的先后,ELT与ETL相比,重抽取和加载,轻转换,可以用更轻量的方案搭建一个数据集成平台。
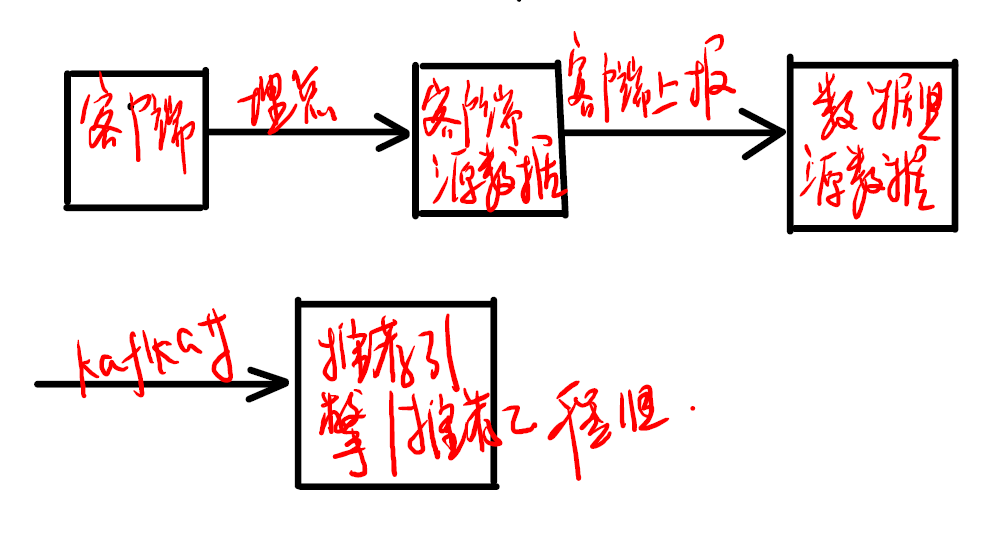
2.2.2 日志的收集与规范化
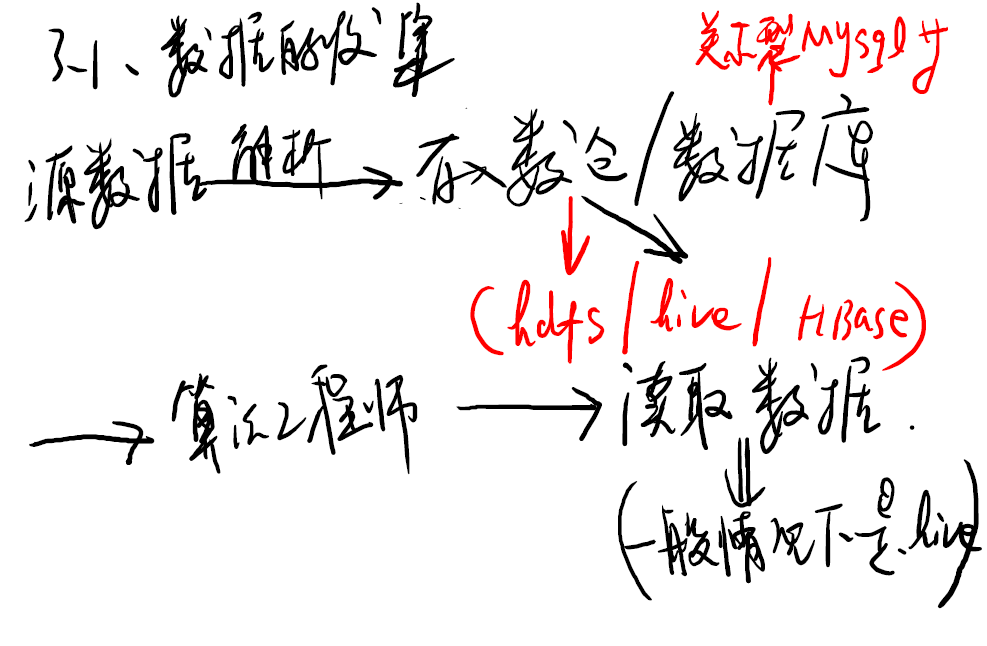
2.2.3 离线训练模型
分为两部分:
- 数据的收集
- 模型的训练与更新。业界主流的有两种方式:增量更新、全量更新。增量更新频率通常为天、小时,全量更新频率为七天、十天、半月等。

2.3 在线架构
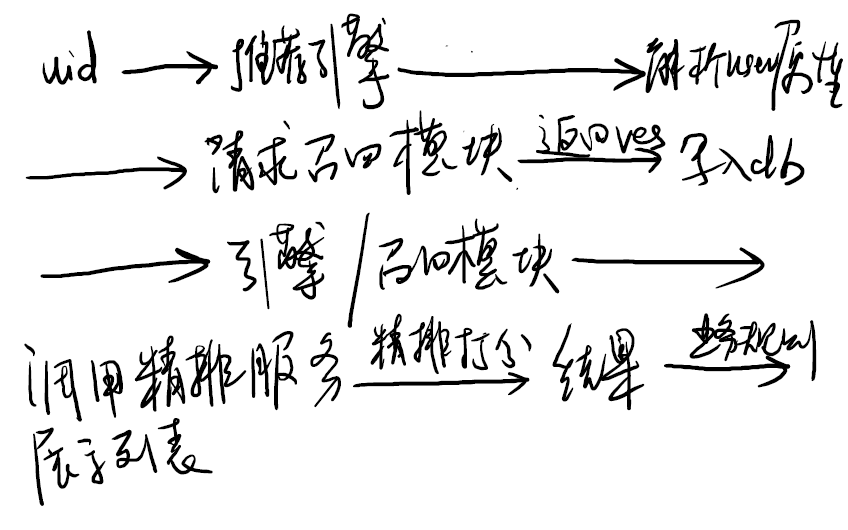
2.4 召回
2.4.1 异步召回
通常模型对召回数据的处理需要一些计算量,异步召回是指在模型在非调用时就基于自身模型,对召回结果进行计算并然后缓存DB内。
3. 发展
3.1 石器时代
人工选品排序及运营——自然排名(热全快)——机器学习预估条目转化排序
关键:通过抑制马太效应
3.2 青铜时代
构建关联和个性化推荐
此时召回模块包括两类:
- 非个性召回:最常见的就是热度召回
- 个性化召回:上下文、兴趣、行为等
关键:冲突与协调,需处理冷启动问题和兼顾召回四象限(流行、多样、新鲜、相关)
个性化落地
- i2i数据生成
- 候选商品召回
- 排序
- 打散(避免一定时间的商品集中在某几个条目)
3.3 目前基本工作流
- 召回:当用户以及内容量比较大的时候,往往先通过召回策略,将百万量级的内容先缩小到百量级。
- 过滤:对于内容不可重复消费的领域,例如实时性比较强的新闻等,在用户已经曝光和点击后不会再推送到用户面前。
- 精排:对于召回并过滤后的内容进行排序,将百量级的内容并按照顺序推送。
- 混排:为避免内容越推越窄,将精排后的推荐结果进行一定修改,例如控制某一类型的频次。
- 强规则:根据业务规则进行修改,例如在活动时将某些文章置顶。
3.4 内容
召回策略
- 召回的目的:当用户与内容的量级比较大,例如对百万量级的用户与内容计算概率,就会产生百万*百万量级的计算量。但同时,大量内容中真正的精品只是少数,对所有内容进行一次计算将非常的低效,会浪费大量的资源和时间。因此采用召回策略,例如热销召回,召回一段时间内最热门的 100 个内容,只需进行一次计算动作,就可以对所有用户应用。
- 召回的重要性:虽然精排模型一直是优化的重点,但召回模型也非常的重要,因为如果召回的内容不对,怎么精排都是错误的。
- 召回方法:召回的策略不应该是简单的策略堆砌,而应该是方法的相互补充。
- 热销召回:将一段时间内的热门内容召回。
- 协同召回:基于用户与用户行为的相似性推荐,可以很好的突破一定的限制,发现用户潜在的兴趣偏好。
- 标签召回:根据每个用户的行为,构建标签,并根据标签召回内容。
- 时间召回:将一段时间内最新的内容召回,在新闻视频等有时效性的领域常用。是常见的几种召回方法。
精排策略
精排模型的不同类别
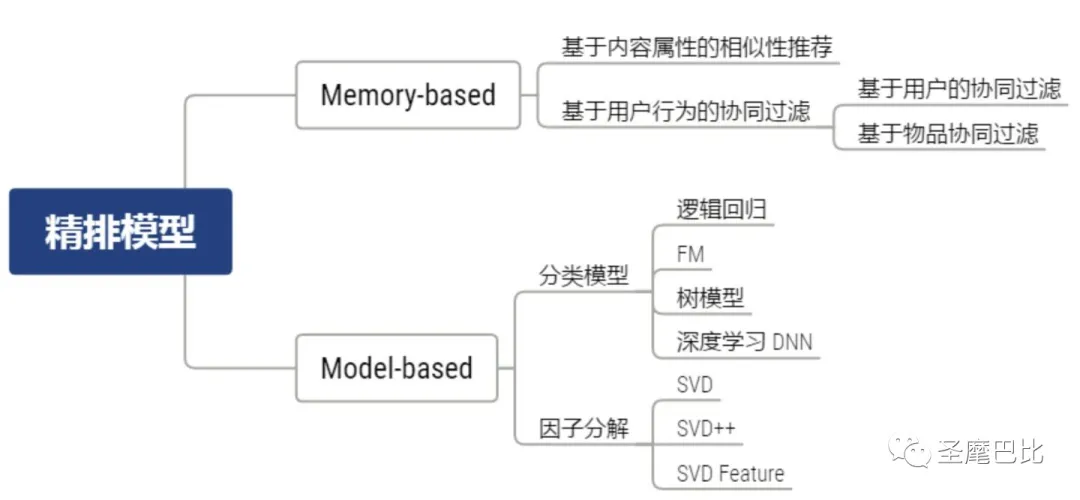
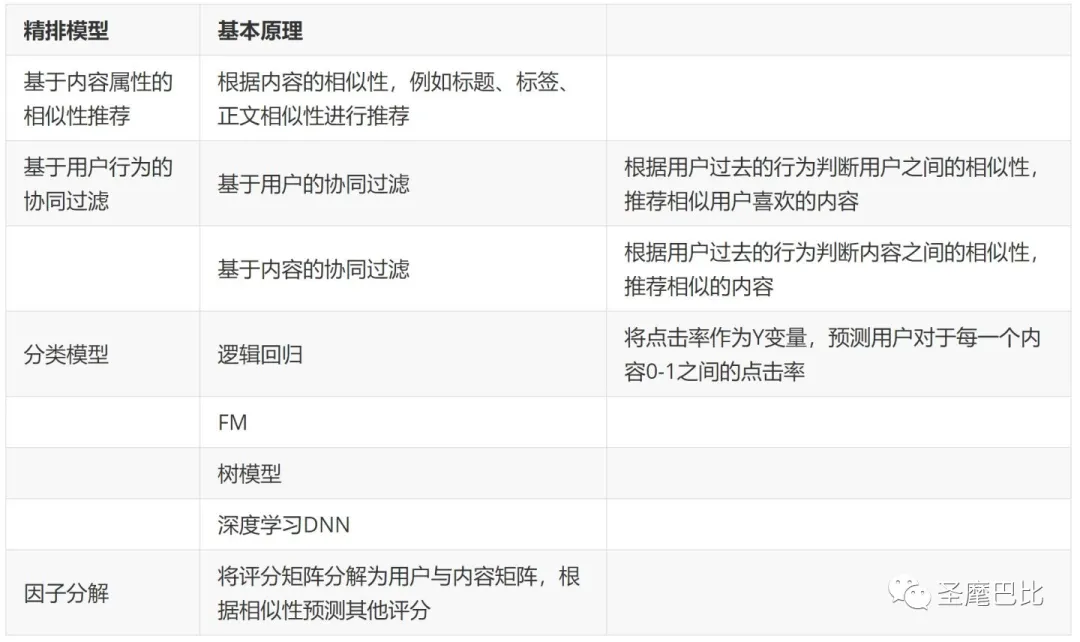
精排模型的基本原理
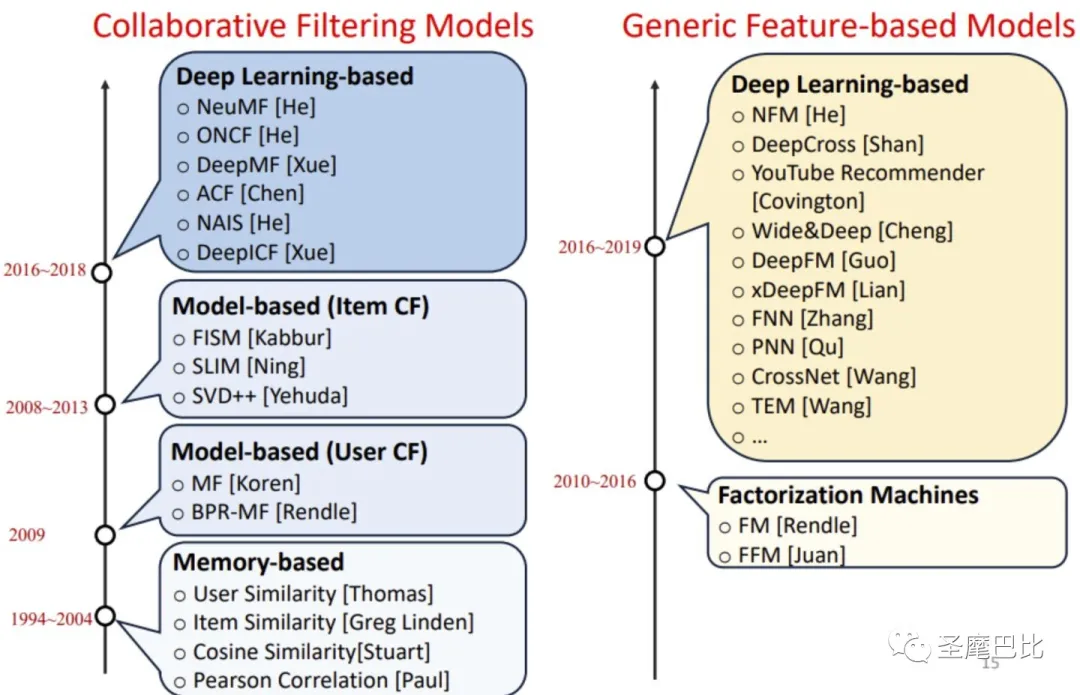
模型发展
算法衡量标准
- 硬指标:对于大多数的平台而言,推荐系统最重要的作用是提升一些“硬指标”。例如新闻推荐中的点击率,但是如果单纯以点击率提升为目标,最后容易成为一些低俗内容,“标题党”的天下。
- 软指标:除了“硬指标”,推荐系统还需要很多“软指标”以及“反向指标”来衡量除了点击等之外的价值。好的推荐系统能够扩展用户的视野,发现那些他们感兴趣,但是不会主动获取的内容。同时推荐系统还可以帮助平台挖掘被埋没的优质长尾内容,介绍给感兴趣的用户。

获得推荐效果
如何去获得推荐效果。可以分为离线实验、用户调查、在线实验三种方法。

- 离线实验: 通过反复在数据样本进行实验来获得算法的效果。通常这种方法比较简单、明确。但是由于数据是离线的,基于过去的历史数据,不能够真实的反应线上效果。同时需要通过时间窗口的滚动来保证模型的客观性和普适性。
- 用户反馈: 当在离线实验阶段得到了一个比较不错的预测结果之后,就需要将推荐的结果拿到更加真实的环境中进行测评,如果这个时候将算法直接上线,会面临较高的风险。因为推荐结果的好坏不能仅仅从离线的数字指标衡量,更要关注用户体验,所以可以通过小范围的反复白板测试,获得自己和周围的人对于推荐结果的直观反馈,进行优化。
- 在线测试(AB test): 实践是检验真理的唯一标准,在推荐系统的优化过程中,在线测试是最贴近现实、最重要的反馈方式。通过 AB 测试的方式,可以衡量算法与其他方法、算法与算法之间的效果差异。但是要注意的是,AB 测序需要一定的观察期以及科学的实验流程,才能证明得到的结论是真实可信的。


若有收获,就点个赞吧
0 人点赞
