1. CTR问题
CTR(Click Throght Rate),也称点击率预测问题,尤其是在广告方面,指的是每次对广告的点击情况预测,输出就是点击或者不点击,是一个二分类问题。
1.1 CTR需要做什么
CTR是一个二分类问题,对于输入,需要产生一个概率值输出,作为对该广告的点击率预测。
1.2 与TopN推荐区别
CTR: CTR是为了得到某个用户或者某类用户对于一堆广告(商品)的点击率预测,然后结合广告(商品)的出价用于广告(商品)排序。
TopN推荐: TopN推荐是通过预测用户对一类商品的相似性(评分、感兴趣程度),然后得出包含个商品的推荐商品表。
CTR主要运用在广告推荐,聚焦于特定的推荐场景,但CTR也可以作为TopN推荐的一个步骤,通过CTR替代TopN中的相似度计算。
2. Wide&Deep
Wide&Deep是Google于2016提出的用于推荐系统的算法,可用于CTR、TopN推荐[1]。
首先提一下推荐系统中两个常见概念:Memorization和Generalization。Memorization指记忆能力,通过用户、商品交互信息矩阵学习规则的效果;Generalization指泛化能力,模型对于未学习样本的泛化能力。
Wide&Deep模型中,从名字很好看出,包括Wide和Deep两部分,其中Wide是一个广义线性模型,Deep是一个DNN模型,前者用于Memorization,后者用于Generalization。通过将两个模型的输出作为输入,通过一个Dense层处理,产生最后的输出。一个示例如下图(论文中的图):
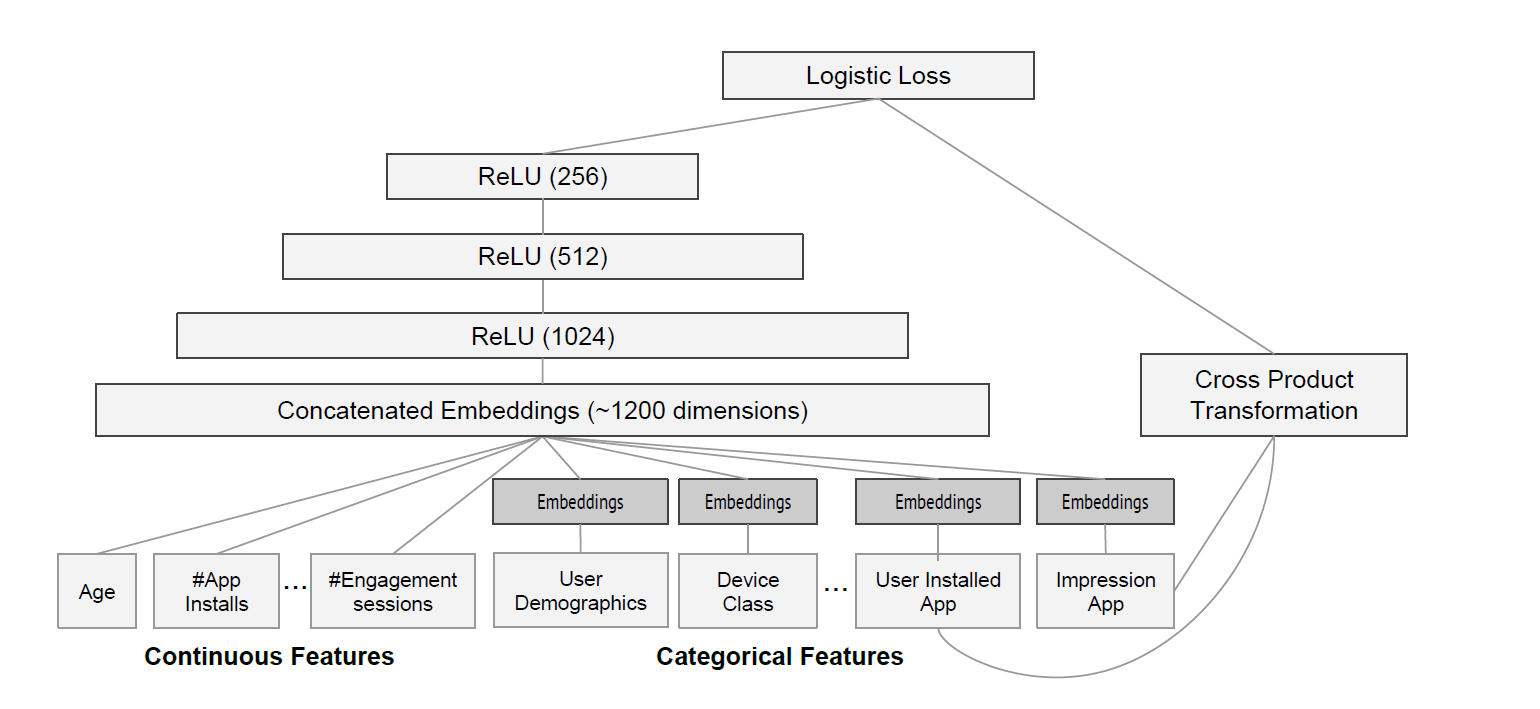
在推荐系统中,Wide&Deep用于排序层,对于召回的若干候选集,通过引入更多的特征,将候选集中的商品进行排序、筛选、推荐。
其实提供的更是一种框架和思路,比如具有Wide和Deep层的设置并不是固定的,可以使用更加高级、复杂的结构,或者更加贴合特征、业务的结构。
具体介绍见论文
Wide&Deep通过联合训练,模型最终输出为:
%20%3D%20%5Csigma(w%7Bwide%7D%5ET%5Bx%2C%20%5Cphi(x)%5D%20%2B%20w%7Bdeep%7D%5ETa%5E%7B(lf)%7D%20%2B%20b)%0A#card=math&code=P%28Y%3D1%5Cvert%20x%29%20%3D%20%5Csigma%28w%7Bwide%7D%5ET%5Bx%2C%20%5Cphi%28x%29%5D%20%2B%20w_%7Bdeep%7D%5ETa%5E%7B%28l_f%29%7D%20%2B%20b%29%0A)
解释:
%5D#card=math&code=%5Bx%2C%20%5Cphi%28x%29%5D)是原始特征和交叉特征,
分别是Wide和Deep模型(最后一层)的权重
是激活函数,
偏置,由于联合训练,Wide层不需要单独再加偏置
%7D#card=math&code=a%5E%7B%28l_f%29%7D)是Deep层最后一层的输出
3. 代码实践
见本人Github页面Deep&Wide
模型可视化图如下(上述代码中生成):
- Cheng H T, Koc L, Harmsen J, et al. Wide & deep learning for recommender systems[C]//Proceedings of the 1st workshop on deep learning for recommender systems. 2016: 7-10. ↩︎

若有收获,就点个赞吧
0 人点赞
